Flink
一、Flink简介
什么是flink
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0dpviAtO-1612775779483)(/Users/bytedance/Desktop/WI7lRD.jpg)]](http://img.e-com-net.com/image/info8/9cc8b27d27864b2782fa787f6ad9c231.jpg)
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
Apache Flink 功能强大,支持开发和运行多种不同种类的应用程序。它的主要特性包括:批流一体化、精密的状态管理、事件时间支持以及精确一次的状态一致性保障等。Flink 不仅可以运行在包括 YARN、 Mesos、Kubernetes 在内的多种资源管理框架上,还支持在裸机集群上独立部署。在启用高可用选项的情况下,它不存在单点失效问题。事实证明,Flink 已经可以扩展到数千核心,其状态可以达到 TB 级别,且仍能保持高吞吐、低延迟的特性。世界各地有很多要求严苛的流处理应用都运行在 Flink 之上。
接下来,是Flink中的几个重要概念。
批与流
-
批处理的特点是有界、持久、大量,非常适合需要访问全套记录才能完成的计算工作,一般用于离线统计。
-
流处理的特点是无界、实时, 无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作,一般用于实时统计。
在Spark的世界观中,一切都是由批次组成的,离线数据是一个大批次,而实时数据是由一个一个无限的小批次组成的。而在Flink的世界观中,一切都是由流组成的,离线数据是有界限的流,实时数据是一个没有界限的流,这就是所谓的有界流和无界流。
- 无界流:有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。
- 有界流:有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理。
有界流与无界流图示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iZp0cd1v-1612775779484)(/Users/bytedance/Desktop/bounded-unbounded.png)]](http://img.e-com-net.com/image/info8/3fc2cd35706a4adca9d6e8cf8335227b.jpg)
Flink 擅长处理无界和有界数据集 精确的时间控制和状态化使得Flink的运行时(runtime)能够运行任何处理无界流的应用。有界流则由一些专为固定大小数据集特殊设计的算法和数据结构进行内部处理,产生了出色的性能。
Flink可适用强
可将flink部署到任何地方
- Apache Flink 是一个分布式系统,它需要计算资源来执行应用程序。Flink 集成了所有常见的集群资源管理器,例如Hadoop YARN、 Apache Mesos和 Kubernetes,但同时也可以作为独立集群运行。
- Flink 被设计为能够很好地工作在上述每个资源管理器中,这是通过资源管理器特定(resource-manager-specific)的部署模式实现的。Flink 可以采用与当前资源管理器相适应的方式进行交互。
- 部署 Flink 应用程序时,Flink 会根据应用程序配置的并行性自动标识所需的资源,并从资源管理器请求这些资源。在发生故障的情况下,Flink 通过请求新资源来替换发生故障的容器。提交或控制应用程序的所有通信都是通过 REST 调用进行的,这可以简化 Flink 与各种环境中的集成。
利用内存性能
有状态的 Flink 程序针对本地状态访问进行了优化。任务的状态始终保留在内存中,如果状态大小超过可用内存,则会保存在能高效访问的磁盘数据结构中。任务通过访问本地(通常在内存中)状态来进行所有的计算,从而产生非常低的处理延迟。Flink 通过定期和异步地对本地状态进行持久化存储来保证故障场景下精确一次的状态一致性。![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KK7q5nfK-1612775779485)(/Users/bytedance/Desktop/local-state.png)]](http://img.e-com-net.com/image/info8/3b8a4cf94ddf4dbab8967833d9e327c9.jpg)
分层API
Flink 根据抽象程度分层,提供了三种不同的 API。每一种 API 在简洁性和表达力上有着不同的侧重,并且针对不同的应用场景。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sD2aHoNE-1612775779487)(/Users/bytedance/Desktop/nJou61.jpg)]](http://img.e-com-net.com/image/info8/e89ffdb68e9843b19585b8109cf7dcf3.jpg)
- ProcessFunction:可以处理一或两条输入数据流中的单个事件或者归入一个特定窗口内的多个事件。它提供了对于时间和状态的细粒度控制。开发者可以在其中任意地修改状态,也能够注册定时器用以在未来的某一时刻触发回调函数。因此,你可以利用ProcessFunction实现许多有状态的事件驱动应用所需要的基于单个事件的复杂业务逻辑。
- DataStream API:为许多通用的流处理操作提供了处理原语。这些操作包括窗口、逐条记录的转换操作,在处理事件时进行外部数据库查询等。DataStream API 支持 Java 和 Scala 语言,预先定义了例如map()、reduce()、aggregate() 等函数。你可以通过扩展实现预定义接口或使用 Java、Scala 的 lambda 表达式实现自定义的函数。
- SQL & Table API:Flink 支持两种关系型的 API,Table API 和 SQL。这两个 API 都是批处理和流处理统一的 API,这意味着在无边界的实时数据流和有边界的历史记录数据流上,关系型 API 会以相同的语义执行查询,并产生相同的结果。Table API和SQL借助了 Apache Calcite来进行查询的解析,校验以及优化。它们可以与DataStream和DataSet API无缝集成,并支持用户自定义的标量函数,聚合函数以及表值函数。Flink 的关系型 API 旨在简化数据分析、数据流水线和 ETL 应用的定义。
Flink特点
Apache Flink是一个集合众多具有竞争力特性于一身的第三代流处理引擎,它的以下特点使得它能够在同类系统中脱颖而出。
- 同时支持高吞吐、低延迟、高性能。
- Flink是目前开源社区中唯一一套集高吞吐、低延迟、高性能三者于一身的分布式流式处理框架。像Apache Spark也只能兼顾高吞吐和高性能特性,主要因为在Spark Streaming流式计算中无法做到低延迟保障;而流式计算框架Apache Storm只能支持低延迟和高性能特性,但是无法满足高吞吐的要求。
- 同时支持事件时间和处理时间语义。
- 在流式计算领域中,窗口计算的地位举足轻重,但目前大多数框架窗口计算采用的都是处理时间,也就是事件传输到计算框架处理时系统主机的当前时间。Flink能够支持基于事件时间语义进行窗口计算,也就是使用事件产生的时间,这种基于事件驱动的机制使得事件即使乱序到达,流系统也能够计算出精确的结果,保证了事件原本的时序性。
- 支持有状态计算,并提供精确一次的状态一致性保障。
- 所谓状态就是在流式计算过程中将算子的中间结果数据保存着内存或者文件系统中,等下一个事件进入算子后可以从之前的状态中获取中间结果中计算当前的结果,从而不须每次都基于全部的原始数据来统计结果,这种方式极大地提升了系统的性能,并降低了数据计算过程的资源消耗。
- 基于轻量级分布式快照实现的容错机制。
- Flink能够分布式运行在上千个节点上,将一个大型计算任务的流程拆解成小的计算过程,然后将Task分布到并行节点上进行处理。在任务执行过程中,能够自动发现事件处理过程中的错误而导致的数据不一致问题,在这种情况下,通过基于分布式快照技术的Checkpoints,将执行过程中的状态信息进行持久化存储,一旦任务出现异常终止,Flink就能够从Checkpoints中进行任务的自动恢复,以确保数据中处理过程中的一致性。
- 保证了高可用,动态扩展,实现7 * 24小时全天候运行。
- 支持高可用性配置(无单点失效),和Kubernetes、YARN、Apache Mesos紧密集成,快速故障恢复,动态扩缩容作业等。基于上述特点,它可以7 X 24小时运行流式应用,几乎无须停机。当需要动态更新或者快速恢复时,Flink通过Savepoints技术将任务执行的快照保存在存储介质上,当任务重启的时候可以直接从事先保存的Savepoints恢复原有的计算状态,使得任务继续按照停机之前的状态运行。
- 支持高度灵活的窗口操作。
- Flink将窗口划分为基于Time、Count、Session,以及Data-driven等类型的窗口操作,窗口可以用灵活的触发条件定制化来达到对复杂流传输模式的支持,用户可以定义不同的窗口触发机制来满足不同的需求。
Flink应用场景
在实际生产的过程中,大量数据在不断地产生,例如金融交易数据、互联网订单数据、GPS定位数据、传感器信号、移动终端产生的数据、通信信号数据等,以及我们熟悉的网络流量监控、服务器产生的日志数据,这些数据最大的共同点就是实时从不同的数据源中产生,然后再传输到下游的分析系统。
针对这些数据类型主要包括以下场景,Flink对这些场景都有非常好的支持。
- 实时智能推荐
- 利用Flink流计算帮助用户构建更加实时的智能推荐系统,对用户行为指标进行实时计算,对模型进行实时更新,对用户指标进行实时预测,并将预测的信息推送给Web/App端,帮助用户获取想要的商品信息,另一方面也帮助企业提高销售额,创造更大的商业价值。
- 复杂事件处理
- 例如工业领域的复杂事件处理,这些业务类型的数据量非常大,且对数据的时效性要求较高。我们可以使用Flink提供的CEP(复杂事件处理)进行事件模式的抽取,同时应用Flink的SQL进行事件数据的转换,在流式系统中构建实时规则引擎。
- 实时欺诈检测
- 在金融领域的业务中,常常出现各种类型的欺诈行为。运用Flink流式计算技术能够在毫秒内就完成对欺诈判断行为指标的计算,然后实时对交易流水进行规则判断或者模型预测,这样一旦检测出交易中存在欺诈嫌疑,则直接对交易进行实时拦截,避免因为处理不及时而导致的经济损失
- 实时数仓与ETL
- 结合离线数仓,通过利用流计算等诸多优势和SQL灵活的加工能力,对流式数据进行实时清洗、归并、结构化处理,为离线数仓进行补充和优化。另一方面结合实时数据ETL处理能力,利用有状态流式计算技术,可以尽可能降低企业由于在离线数据计算过程中调度逻辑的复杂度,高效快速地处理企业需要的统计结果,帮助企业更好的应用实时数据所分析出来的结果。
- 流数据分析
- 实时计算各类数据指标,并利用实时结果及时调整在线系统相关策略,在各类投放、无线智能推送领域有大量的应用。流式计算技术将数据分析场景实时化,帮助企业做到实时化分析Web应用或者App应用的各种指标。
- 实时报表分析
- 实时报表分析是近年来很多公司采用的报表统计方案之一,其中最主要的应用便是实时大屏展示。利用流式计算实时得出的结果直接被推送到前段应用,实时显示出重要的指标变换,最典型的案例就是淘宝的双十一实时战报。
Flink VS Spark Streaming
- 数据模型
- Flink基本数据模型是数据流,以及事件序列。
- Spark采用RDD模型,Spark Streaming的DStream实际上也就是一组组小批数据RDD的集合。
- 运行时架构
- Flink是标准的流执行模式,一个事件在一个节点处理完后可以直接发往下一个节点进行处理。
- Spark是批计算,将DAG划分为不同的Stage,一个完成后才可以计算下一个。
二、Flink安装搭建
准备工作
下载安装包:Apache Flink: Downloads

本文以https://dlcdn.apache.org/flink/flink-1.15.2/flink-1.15.2-bin-scala_2.12.tgz为例
上传安装包至node001节点
解压:tar -zxvf flink-1.15.2-bin-scala_2.12.tgz -C /opt/
改名:mv /opt/flink-1.15.2/ /opt/flink
flink的重要文件简述
# bin/ ================================================
bash-java-utils.jar
config.sh
find-flink-home.sh
flink #flink shell
flink-console.sh
flink-daemon.sh
historyserver.sh
jobmanager.sh #作业管理者,最作业进行启动,分发,调度
taskmanager.sh #任务管理者(干活的)
kubernetes-jobmanager.sh
kubernetes-session.sh
kubernetes-taskmanager.sh
mesos-appmaster-job.sh
mesos-appmaster.sh
mesos-jobmanager.sh
mesos-taskmanager.sh
pyflink-shell.sh #
sql-client.sh
standalone-job.sh
start-cluster.sh #启动flink集群
stop-cluster.sh #停止flink集群
start-zookeeper-quorum.sh
stop-zookeeper-quorum.sh
yarn-session.sh #
zookeeper.sh
# ./conf [配置目录] ============================================
# ./conf/flink-conf.yaml -------------------------------------
jobmanager.memory.process.size: 1600m #这个是jobmanager的堆内存设定
taskmanager.memory.process.size: 1728m #这个是taskmanager的堆内存设定
#在生产过程中,taskmanager的堆内存会配置的大一些,因为他是干活的。然而jobmanager只是用来调度的,这个可以稍微略小些。生产中 taskmanager比jobmanager大很多。
taskmanager.numberOfTaskSlots: 1 #taskmanager对资源进行划分为多个“槽位”,有多少个slot就可以同时奔跑多少个线程。 这里配置1,表示只有一个槽位,那么一个taskmanager就只能跑一个线程。
parallelism.default: 1 #默认并行度。(默认一个线程执行)
#问题: taskmanager.numberOfTaskSlots和parallelism.default 有什么区别? 这两个不是一回事。前者表示 当前这台taskmanage 最大可以执行的线程数量;后者表示真正执行的时候多个taskmanager并行个数总和默认值。不好理解,可以理解为:前者表示最大的能力,后者表示当前用多少能力。 前者指的是一台taskmanage最大能力, 后者指的是集群中所有taskmanage 默认的并行度总和的默认值, 默认值只有在不设置的时候才使用,一般情况会在代码中直接设置
# ./conf/master ----------------------------------------------
localhost:8081 #里面默认写着localhost:8081, 这个也是web端口。
# ./conf/workers 或者 ./conf/slaves[之前版本] ------------------
localhost #默认值是localhost
#如上的masters和workers 表示单机模式
修改配置文件
1.flink-conf.yaml
终端输入:vim /opt/flink/conf/flink-conf.yaml
将jobmanager.rpc.address:修改为主节点

2.masters
终端输入:vim /opt/flink/conf/masters
将localhost修改为主节点

3.workers
终端输入:vim /opt/flink/conf/workers
将localhost修改为从节点

配置环境变量
终端输入:vim /etc/profile
末行加入:
export FLINK_HOME=/opt/flink
export PATH=$PATH:$FLINK_HOME/bin重新加载配置文件:source /etc/profile
分发文件
分发flink文件
scp -r /opt/flink/ node002:/opt/
scp -r /opt/flink/ node003:/opt/
分发profile文件
scp /etc/profile node002:/etc/
scp /etc/profile node003:/etc/
然后重新加载node002与node003的配置文件:source /etc/profile
测试访问web页面
启动flink,在zookeeper的leader节点启动flink
输入:start-cluster.sh

访问web页面:leader节点:8081
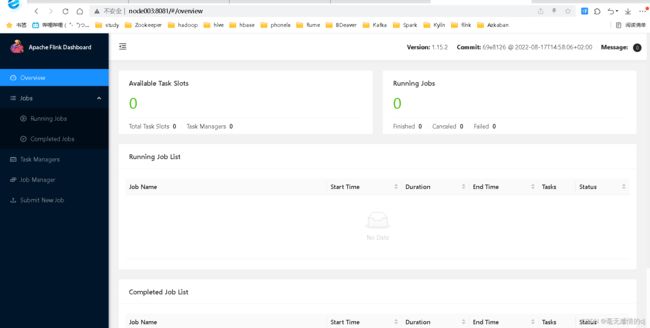
执行官方示例
首先创建一个words.txt
随便写入一些数据
然后执行命令:
flink run /opt/flink/examples/batch/WordCount.jar --input /root/words.txt --output /root/test/out
flink run /software/flink/examples/batch/WordCount.jar --input /root/test/words.txt --output /root/test/out
如果想要flink 连接hadoop ,需要去官网下载flink-share-hadoop-xxxxxxxx.jar包放在 flink/lib/下面的。
然后才可以搭建 flink的yarn模式。
从 maven仓库(https://mvnrepository.com/search?q=flink-shaded-hadoop-3)中找到对应的jar版本。
依照自己的Hadoop版本下载



然后jar包上传至flink/lib/目录
flink运行模式介绍
Flink 提供了两种在 yarn 上运行的模式,分别为 Session-Cluster 和 Per-Job-Cluster 模式。
Session-cluster模式
Session-cluster 和 standalone模式有些类似。

使用:
#step1: 启动hadoop
#step2:启动yarn-session
./yarn-session.sh -n 10 -s 2 -jm 1024 -tm 4096 -nm test -d
-n(--container):TaskManager 的数量。(现在的版本都不需要指定了,如果指定就相当于限定死了,和standalone一样。 现在不指 定 就是动态分配了)
-s(--slots): 每个 TaskManager 的 slot 数量,默认一个 slot 一个 core,默认每个 taskmanager 的 slot 的个数为 1,
有时可以多一些 taskmanager,做冗余。
-jm:JobManager 的内存(单位 MB)。
-tm:每个 taskmanager 的内存(单位 MB)。
-nm:yarn 的 appName(现在 yarn 的 ui 上的名字)。
-d:后台执行。
#step3 : 执行。 直接用命令行提交即可。(这时候不要运行start-cluster.sh 。 如果运行就到 standalone模式了)
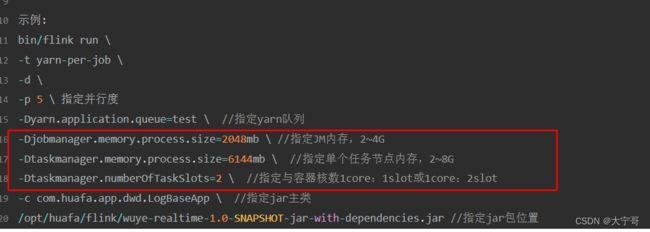
flink/bin/flink run \
-c com.lining.wc.StreamWordCount \
-p 2 \
/root/scala_maven-1.0-SNAPSHOT-jar-with-dependencies.jar --host 192.168.0.102 --port 7777
#step4 : 去yarn的控制台看任务状态
ip:8088
#step5 : 取消yarn-session
yarn application --kill [该任务的yarn的id]

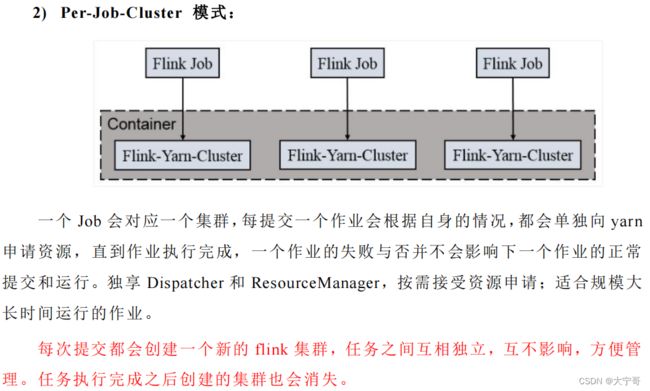
Per-Job-Cluster模式
使用:
#step1: 启动hadoop
#step2: 不要启动yarn-session,直接执行job
#在job执行命令中添加 -m yarn-cluster
./flink run -m yarn-cluster -yjm 1024m -ytm 2048m -c jobReq -p 1 /root/jobRequire-1.0-SNAPSHOT-jar-with-dependencies.jar
#step3 : 去yarn的控制台看任务状态
ip:8088
#step4 : 取消yarn-session
yarn application --kill [该任务的yarn的id]
参考资料
什么是Flink?Flink能用来做什么?
flink安装部署