【ICCV2023】Robustifying Token Attention for Vision Transformers
Robustifying Token Attention for Vision Transformers
论文:https://arxiv.org/abs/2303.11126
代码:暂未开源
解读:ICCV 2023 | Token过度聚焦暴露注意力机制弱点,两种模块设计增强视觉Transformer鲁棒性 - 知乎 (zhihu.com)
摘要
Vision Transformer在图像分类等任务中表现出色,但在面对常见的图像扰动(如噪声或模糊)时,其性能会显著下降。为此,论文对ViT的关键组成部分——自注意力机制进行研究分析,发现当前的视觉transformer模型在自注意力机制中存在"token overfocusing"的问题,即注意力机制过度依赖于少数重要token。然而这些token对图像扰动非常敏感。为避免overfocusing问题,提高模型的鲁棒性,论文提出两种通用技术:Token-aware Average Pooling(TAP)和Attention Diversification Loss(ADL)。
- Token-aware Average Pooling(TAP),模块鼓励每个token的局部邻域参与注意力机制。具体来说,TAP学习每个token的平均池化方案,以便可以自适应地考虑邻域中潜在重要token的信息。
- Attention Diversification Loss(ADL),迫使输出token聚合来自不同输入token集的信息,而不是只关注少数token。通过惩罚不同标记的注意力向量之间的高余弦相似性来实现。
这些方法可应用于大多数Vit架构,几乎不增加训练开销,能大大提升分类精度和鲁棒性。
注意力机制中的Token Overfocusing现象
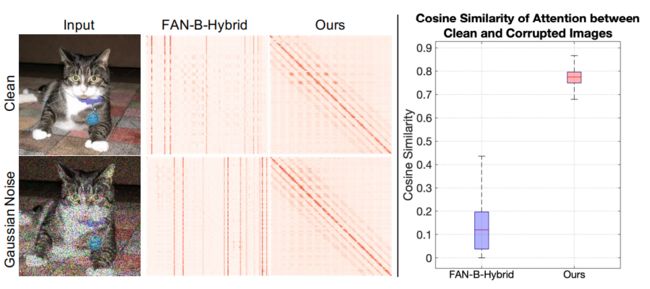

以FAN架构为例,本文将FAN最后一层的注意力可视化为注意力矩阵。第i行表示第i个输出token“关注”哪些输入token (列)——红色越深表示注意力得分越高。对于多头自注意力则通过对注意力头进行平均来可视化该矩阵。
由图1可观察到,列方向上的注意力通常非常稀疏,这意味着大多数输入token没有被关注到,并且每个输出token只关注相同的少数重要输入token。本文将这种现象称为Token Overfocusing。然而,当面对高斯噪声等干扰时,会导致模型注意力完全转移到其他不同的token(图1,第二列)。这可以理解为原始token没有捕捉到稳定的信息。进一步定量分析发现,同一幅图像的干净版本和加入高斯噪声的版本之间的注意力图的余弦相似度非常低,即同一图像输入,注意力变化非常剧烈。这说明标准的自注意力机制对输入扰动极为不稳定。作者发现这种现象存在于各种架构中,包括DeiT和RVT,并且还出现在语义分割等模型中。
方法
为解决Token Overfocusing问题,本文提出了两个通用技术用于提高注意力机制的稳定性和鲁棒性:(1)提出Token-aware Average Pooling (TAP),通过学习每个token的pooling区域,让更多token参与注意力计算。(2)提出Attention Diversification Loss (ADL),最大化不同token间的注意力向量差异,提高多样性。
Token-aware Average Pooling
该方法试图鼓励更多的输入token参与自注意力机制,即在注意力图中获得更多具有高得分的列。为此,本文鼓励每个输入token从其局部邻域显式地聚合有用的信息,以防该token本身不包含重要信息。表1也展示了,在自注意力前引入任何局部聚合都能提高鲁棒性。这些方法对所有token应用固定的卷积核或池化区域。然而,token通常彼此不同,每个token都应该需要一个特定的局部聚合策略。本文采用自适应方式选择正确的邻域大小和聚合策略。


基于上述想法,本文提出Token-aware Average Pooling(TAP)模块,使每个token能够选择适当的区域进行局部聚合。具体而言,TAP对每个token进行平均池化,并自适应地调整池化区域。如图2所示,TAP利用多分支结构,在多个分支上进行加权求和,每个分支具有特定的池化区域。与简单地改变卷积核大小类似,TAP通过改变扩张率来调整池化区域。主要观察是,没有扩张的大卷积核的平均池化将导致相邻池化区域之间的重叠非常大,从而导致输出token中的严重冗余。例如,在表1中,AvgPool5x5会导致准确率约1.2%的大幅下降。
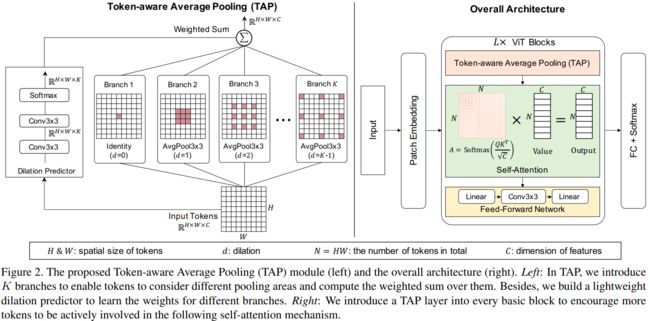
基于这些观察,本文基于具有不同扩张率的平均池化构建了TAP:给定K个分支,考虑范围 d∈[0,K−1] 内的扩张率。其中, d=0 表示恒等映射,即没有任何计算,即没有局部聚合。由确定的最大扩张率为超参数。TAP包含一个轻量级的扩张率预测器,用于预测在允许的扩张率范围内要使用哪种扩张率(即图2中的哪个分支)。该预测器非常高效,由于它将特征维度从C降低到图2中的K,因此只增加了最小的计算开销和模型参数。
Attention Diversification Loss
该方法旨在改善输出token之间的注意力多样性,即鼓励图1中的不同行对应不同的输入token。基于该目标,本文提出了一种注意力多样化损失(ADL),以减小不同输出token(行)之间的注意力的余弦相似度。
实现该目标面临两个问题:
(1)直接计算的余弦相似度无法准确反映注意力差异
例如,当两行(即输出token)具有非常不相交的注意力模式时,期望其余弦相似度接近0,即较低的相似度。然而,即使对于没有被关注的token,注意力得分也不会为零。对于较大的N,计算点积并将这些值相加往往会导致余弦相似度显著大于零。
(2)两两计算余弦相似度复杂度高
为缓解上述问题,ADL采取以下策略:
设置阈值过滤注意力小值,关注最重要的值,使相似度计算更准确:设1(∙)为指示函数, ![]() 为第l层中第i个token(行)的注意力向量。引入一个依赖于token数量N的阈值
为第l层中第i个token(行)的注意力向量。引入一个依赖于token数量N的阈值  ,即
,即 ![]() 。因此,经阈值处理后的注意力变为
。因此,经阈值处理后的注意力变为
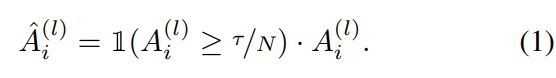
通过近似计算相似度来降低计算量:为避免计算N个行之间的配对余弦相似度的二次复杂度,本文通过计算每个单独的注意力向量![]() 与平均注意力
与平均注意力![]() 之间的余弦相似度来近似计算。
之间的余弦相似度来近似计算。
在考虑具有层的模型时,本文通过以下方式对所有层的ADL损失进行平均:
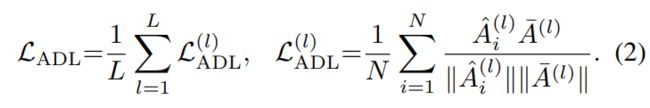
本文将ADL与标准的交叉熵损失相结合,并引入一个超参数来控制ADL的重要性:

实验
论文在图像分类和语义分割任务上进行实验验证。
图像分类
本文基于两个架构RVT和FAN(使用‘’Base‘’模型大小,即RVT-B和FAN-B-Hybrid)构建了本文的方法,与多个鲁棒性baseline在ImageNet图像分类任务上进行了评估。实验证明,无论是单独使用TAP或ADL还是联合使用两者,本文方法都能有效提高模型的鲁棒性,增强模型对各类扰动的对抗能力,联合使用两者则可以产生更佳效果。
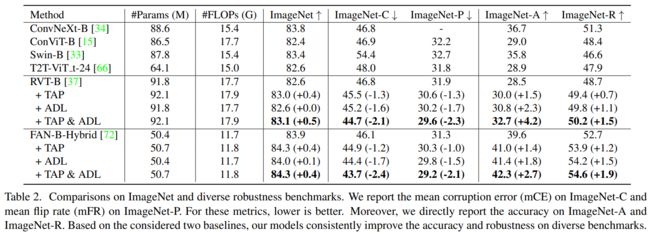 表2. ImageNet上的模型对比结果
表2. ImageNet上的模型对比结果  表3. 基于FAN-B-Hybrid模型在ImageNet-C各个corruption类型上的corruption error比较
表3. 基于FAN-B-Hybrid模型在ImageNet-C各个corruption类型上的corruption error比较
注意力稳定性和可视化
注意力稳定性分析:下图可视化了当面临图像扰动(例如高斯噪声)时注意力的变化。在各示例中,基准模型存在严重的token overfocusing问题,并且在面临扰动时产生了明显的注意力转移。应用TAP后,模型将注意力分配给了周围更多的token,在一定程度上缓解了token过度聚焦问题。然而,仍然可观察到干净示例和扰动示例之间的注意力转移。应用ADL训练模型时,注意力呈现对角线模式,类似残差结构,令token既保留自身信息又聚合周围信息,大幅提升了相似图像间注意力图的稳定性。当将TAP和ADL结合在一起时,模型进一步鼓励对角线模式在局部区域内扩展,使得token将更多地关注自身之外的邻域,从而获得更强的特征。本文通过计算整个ImageNet上干净示例和扰动示例之间的注意力余弦相似度来定量评估注意力的稳定性。结果显示,加入本文方法的模型大幅提升了相似度分数,表明本文方法可有效提高注意力的稳定性。
 图3. 不同模型的注意力图比较
图3. 不同模型的注意力图比较


每个head的注意力和注意力多样性分析:下图展示了每个head的注意力图,可见,基准模型各head之间注意力高度相似,多样性极低。相比之下,本文方法各head可以产生明显不同的注意力模式,只有2个head呈现对角线模式,其他head则具有全局范围的注意力。这种结合局部和全局过滤器的设计提高了head间的注意力多样性。定量结果也证实,本文方法可以大幅降低不同head间的相似度,即增加多样性。
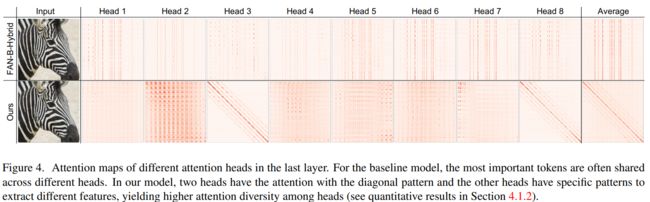 图4. 最后一层不同head的注意力图
图4. 最后一层不同head的注意力图
语义分割
本文接着验证了提出的方法在语义分割上的泛化能力。在Cityscapes数据集上训练模型,并在包含不同扰动类型的Cityscapes-C和包含多种不利条件下街景图像的ACDC上评估鲁棒性。实验采用与SegFormer相似的设置。结果表明,本文的TAP和ADL技术可以很好的泛化至分割任务,并显著提升了鲁棒性。
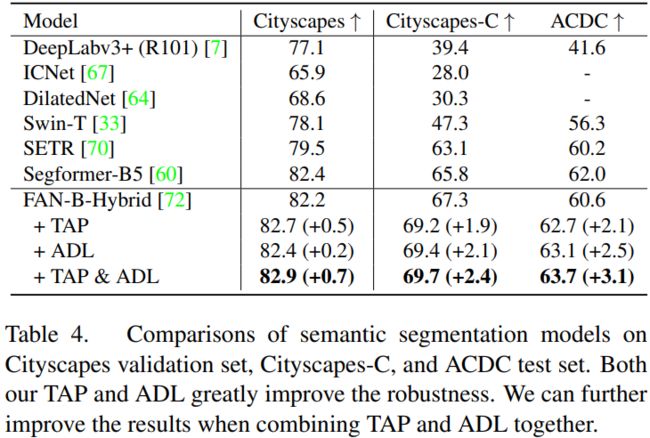 表4. 各语义分割模型在Cityscapes验证集、Cityscapes-C和ACDC测试集上的分割mIoU对比
表4. 各语义分割模型在Cityscapes验证集、Cityscapes-C和ACDC测试集上的分割mIoU对比
视觉对比:在存在雪天扰动时,基准模型无法检测到部分道路区域。而在夜间条件下,基准模型将汽车的一部分识别为骑车者,并且预测结果存在许多伪影。相比之下,本文方法在这些情况下都展现出更强的鲁棒性,可准确检测关键目标。
 图5. 分割结果的视觉对比
图5. 分割结果的视觉对比
消融实验
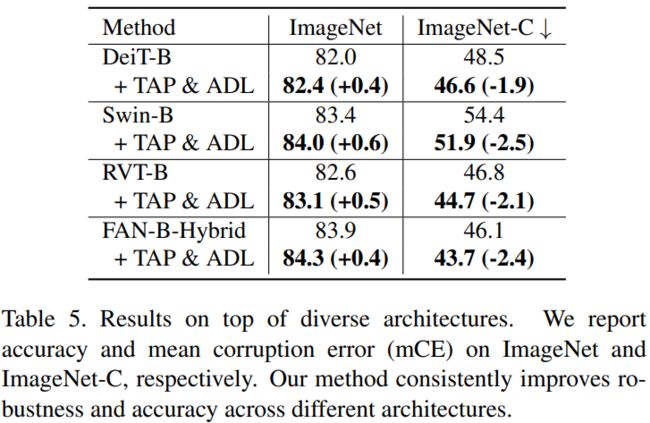
应用于不同网络架构,也能获得鲁棒性提升和准确率改进。
超参数K和λ的影响:TAP模块中的分支数K决定了每个token可以融合信息的池化区域大小种类,值越大则可以融合更多样化的局部信息来提高鲁棒性,但过大会增加模型负担。较大的权重可以增强ADL的作用,即更强力地鼓励模型进一步提高注意力多样化,但是λ太大会抑制标准训练损失,导致模型训练效果下降。如下图所示,当只引入TAP时,随着值的增加,本文模型始终优于基准模型,并在时取得最佳结果;当只使用ADL时,可以观察到太小或太大的会降低本文方法的效果。经验证明,设置K=4和λ=1可以在保证鲁棒性的同时,使额外计算和内存成本最小。
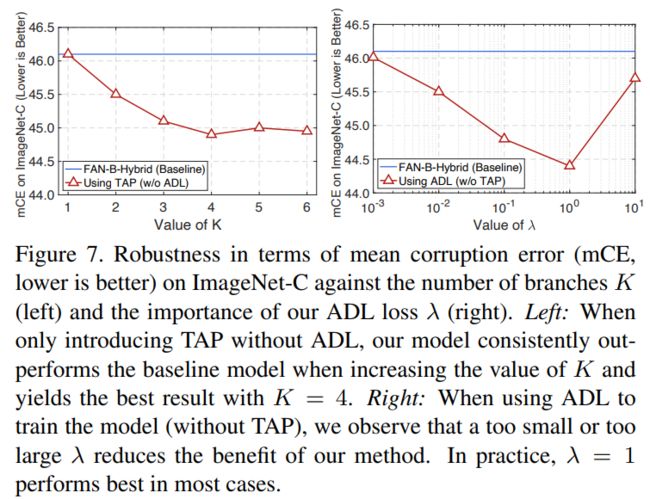 图6. 不同K和λ设置对模型鲁棒性的影响
图6. 不同K和λ设置对模型鲁棒性的影响