十三、函数式编程(1)
本章概要
- 新旧对比
- Lambda 表达式
- 递归
函数式编程语言操纵代码片段就像操作数据一样容易。 虽然 Java 不是函数式语言,但 Java 8 Lambda 表达式和方法引用 (Method References) 允许你以函数式编程。
在计算机时代早期,内存是稀缺和昂贵的。几乎每个人都用汇编语言编程。人们虽然知道编译器,但编译器生成的代码很低效,比手工编码的汇编程序多很多字节,仅仅想到这一点,人们还是选择汇编语言。
通常,为了使程序能在有限的内存上运行,在程序运行时,程序员通过修改内存中的代码,使程序可以执行不同的操作,用这种方式来节省代码空间。这种技术被称为自修改代码 (self-modifying code)。只要程序小到几个人就能够维护所有棘手和难懂的汇编代码,你就能让程序运行起来。
随着内存和处理器变得更便宜、更快。C 语言出现并被大多数汇编程序员认为更“高级”。人们发现使用 C 可以显著提高生产力。同时,使用 C 创建自修改代码仍然不难。
随着硬件越来越便宜,程序的规模和复杂性都在增长。这一切只是让程序工作变得困难。我们想方设法使代码更加一致和易懂。使用纯粹的自修改代码造成的结果就是:我们很难确定程序在做什么。它也难以测试:除非你想一点点测试输出,代码转换和修改等等过程?
然而,使用代码以某种方式操纵其他代码的想法也很有趣,只要能保证它更安全。从代码创建,维护和可靠性的角度来看,这个想法非常吸引人。我们不用从头开始编写大量代码,而是从易于理解、充分测试及可靠的现有小块开始,最后将它们组合在一起以创建新代码。难道这不会让我们更有效率,同时创造更健壮的代码吗?
这就是函数式编程(FP)的意义所在。通过合并现有代码来生成新功能而不是从头开始编写所有内容,我们可以更快地获得更可靠的代码。至少在某些情况下,这套理论似乎很有用。在这一过程中,函数式语言已经产生了优雅的语法,这些语法对于非函数式语言也适用。
你也可以这样想:
OO(object oriented,面向对象)是抽象数据,FP(functional programming,函数式编程)是抽象行为。
纯粹的函数式语言在安全性方面更进一步。它强加了额外的约束,即所有数据必须是不可变的:设置一次,永不改变。将值传递给函数,该函数然后生成新值但从不修改自身外部的任何东西(包括其参数或该函数范围之外的元素)。当强制执行此操作时,你知道任何错误都不是由所谓的副作用引起的,因为该函数仅创建并返回结果,而不是其他任何错误。
更好的是,“不可变对象和无副作用”范式解决了并发编程中最基本和最棘手的问题之一(当程序的某些部分同时在多个处理器上运行时)。这是可变共享状态的问题,这意味着代码的不同部分(在不同的处理器上运行)可以尝试同时修改同一块内存(谁赢了?没人知道)。如果函数永远不会修改现有值但只生成新值,则不会对内存产生争用,这是纯函数式语言的定义。 因此,经常提出纯函数式语言作为并行编程的解决方案(还有其他可行的解决方案)。
需要提醒大家的是,函数式语言背后有很多动机,这意味着描述它们可能会有些混淆。它通常取决于各种观点:为“并行编程”,“代码可靠性”和“代码创建和库复用”。 关于函数式编程能高效创建更健壮的代码这一观点仍存在部分争议。虽然已有一些好的范例,但还不足以证明纯函数式语言就是解决编程问题的最佳方法。
FP 思想值得融入非 FP 语言,如 Python。Java 8 也从中吸收并支持了 FP。我们将在此章探讨。
新旧对比
通常,传递给方法的数据不同,结果不同。如果我们希望方法在调用时行为不同,该怎么做呢?结论是:只要能将代码传递给方法,我们就可以控制它的行为。此前,我们通过在方法中创建包含所需行为的对象,然后将该对象传递给我们想要控制的方法来完成此操作。下面我们用传统形式和 Java 8 的方法引用、Lambda 表达式分别演示。代码示例:
interface Strategy {
String approach(String msg);
}
class Soft implements Strategy {
@Override
public String approach(String msg) {
return msg.toLowerCase() + "?";
}
}
class Unrelated {
static String twice(String msg) {
return msg + " " + msg;
}
}
public class Strategize {
Strategy strategy;
String msg;
Strategize(String msg) {
strategy = new Soft(); // [1]
this.msg = msg;
}
void communicate() {
System.out.println(strategy.approach(msg));
}
void changeStrategy(Strategy strategy) {
this.strategy = strategy;
}
public static void main(String[] args) {
Strategy[] strategies = {
new Strategy() { // [2]
@Override
public String approach(String msg) {
return msg.toUpperCase() + "!";
}
},
msg -> msg.substring(0, 5), // [3]
Unrelated::twice // [4]
};
Strategize s = new Strategize("Hello there");
s.communicate();
for (Strategy newStrategy : strategies) {
s.changeStrategy(newStrategy); // [5]
s.communicate(); // [6]
}
}
}
输出结果:
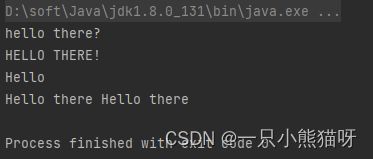
Strategy 接口提供了单一的 approach() 方法来承载函数式功能。通过创建不同的 Strategy 对象,我们可以创建不同的行为。
我们一般通过创建一个实现Strategy接口的类来实现这种行为,正如在Soft里所做的。
- [1] 在 Strategize 中,你可以看到 Soft 作为默认策略,在构造函数中赋值。
- [2] 一种较为简洁且更加自然的方法是创建一个匿名内部类。即便如此,仍有相当数量的冗余代码。你总需要仔细观察后才会发现:“哦,我明白了,原来这里使用了匿名内部类。”
- [3] Java 8 的 Lambda 表达式,其参数和函数体被箭头
->分隔开。箭头右侧是从 Lambda 返回的表达式。它与单独定义类和采用匿名内部类是等价的,但代码少得多。 - [4] Java 8 的方法引用,它以
::为特征。::的左边是类或对象的名称,::的右边是方法的名称,但是没有参数列表。 - [5] 在使用默认的 Soft 策略之后,我们逐步遍历数组中的所有 Strategy,并通过调用
changeStrategy()方法将每个 Strategy 传入变量s中。 - [6] 现在,每次调用
communicate()都会产生不同的行为,具体取决于此刻正在使用的策略代码对象。我们传递的是行为,而并不仅仅是数据。
在 Java 8 之前,我们能够通过 [1] 和 [2] 的方式传递功能。然而,这种语法的读写非常笨拙,并且我们别无选择。方法引用和 Lambda 表达式的出现让我们可以在需要时传递功能,而不是仅在必要时才这么做。
Lambda表达式
Lambda 表达式是使用最小可能语法编写的函数定义:
- Lambda 表达式产生函数,而不是类。 虽然在 JVM(Java Virtual Machine,Java 虚拟机)上,一切都是类,但是幕后有各种操作执行让 Lambda 看起来像函数 —— 作为程序员,你可以高兴地假装它们“就是函数”。
- Lambda 语法尽可能少,这正是为了使 Lambda 易于编写和使用。
我们在 Strategize.java 中看到了一个 Lambda 表达式,但还有其他语法变体:
interface Description {
String brief();
}
interface Body {
String detailed(String head);
}
interface Multi {
String twoArg(String head, Double d);
}
public class LambdaExpressions {
static Body bod = h -> h + " No Parens!"; // [1]
static Body bod2 = (h) -> h + " More details"; // [2]
static Description desc = () -> "Short info"; // [3]
static Multi mult = (h, n) -> h + n; // [4]
static Description moreLines = () -> { // [5]
System.out.println("moreLines()");
return "from moreLines()";
};
public static void main(String[] args) {
System.out.println(bod.detailed("Oh!"));
System.out.println(bod2.detailed("Hi!"));
System.out.println(desc.brief());
System.out.println(mult.twoArg("Pi! ", 3.14159));
System.out.println(moreLines.brief());
}
}
输出结果:
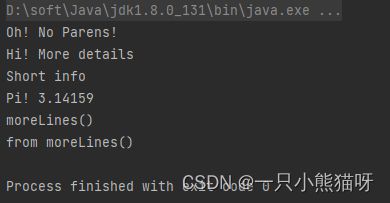
我们从三个接口开始,每个接口都有一个单独的方法(很快就会理解它的重要性)。但是,每个方法都有不同数量的参数,以便演示 Lambda 表达式语法。
任何 Lambda 表达式的基本语法是:
- 参数。
- 接着
->,可视为“产出”。 ->之后的内容都是方法体。
- [1] 当只用一个参数,可以不需要括号
()。 然而,这是一个特例。 - [2] 正常情况使用括号
()包裹参数。 为了保持一致性,也可以使用括号()包裹单个参数,虽然这种情况并不常见。 - [3] 如果没有参数,则必须使用括号
()表示空参数列表。 - [4] 对于多个参数,将参数列表放在括号
()中。
到目前为止,所有 Lambda 表达式方法体都是单行。 该表达式的结果自动成为 Lambda 表达式的返回值,在此处使用 return 关键字是非法的。 这是 Lambda 表达式简化相应语法的另一种方式。
[5] 如果在 Lambda 表达式中确实需要多行,则必须将这些行放在花括号中。 在这种情况下,就需要使用 return。
Lambda 表达式通常比匿名内部类产生更易读的代码,因此我们将在本书中尽可能使用它们。
递归
递归函数是一个自我调用的函数。可以编写递归的 Lambda 表达式,但需要注意:递归方法必须是实例变量或静态变量,否则会出现编译时错误。 我们将为每个案例创建一个示例。
这两个示例都需要一个接受 int 型参数并生成 int 的接口:
interface IntCall {
int call(int arg);
}
整数 n 的阶乘将所有小于或等于 n 的正整数相乘。 阶乘函数是一个常见的递归示例:
public class RecursiveFactorial {
static IntCall fact;
public static void main(String[] args) {
fact = n -> n == 0 ? 1 : n * fact.call(n - 1);
for (int i = 0; i <= 10; i++) {
System.out.println(fact.call(i));
}
}
}
输出结果:
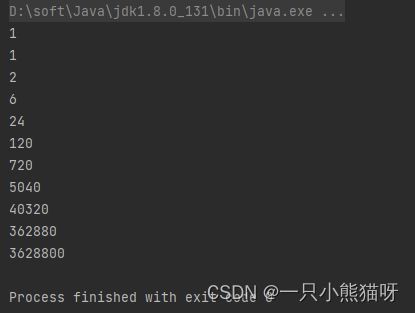
这里,fact 是一个静态变量。 注意使用三元 if-else。 递归函数将一直调用自己,直到 i == 0。所有递归函数都有“停止条件”,否则将无限递归并产生异常。
我们可以将 Fibonacci 序列用递归的 Lambda 表达式来实现,这次使用实例变量:
public class RecursiveFibonacci {
IntCall fib;
RecursiveFibonacci() {
fib = n -> n == 0 ? 0 :
n == 1 ? 1 :
fib.call(n - 1) + fib.call(n - 2);
}
int fibonacci(int n) {
return fib.call(n);
}
public static void main(String[] args) {
RecursiveFibonacci rf = new RecursiveFibonacci();
for (int i = 0; i <= 10; i++) {
System.out.println(rf.fibonacci(i));
}
}
}
输出结果:

将 Fibonacci 序列中的最后两个元素求和来产生下一个元素。