LORA项目源码解读
大模型fineturn技术中类似于核武器的LORA,简单而又高效。其理论基础为:在将通用大模型迁移到具体专业领域时,仅需要对其高维参数的低秩子空间进行更新。基于该朴素的逻辑,LORA降低大模型的fineturn门槛,模型训练时不需要保存原始参数的梯度,仅需对低秩子空间参数进行优化即可。且其低秩子空间在训练完成后,可以叠加到原始参数中,从而实现模型能力的专业领域迁移。为了解这种高维参数空间=》低秩子空间投影实现研究其项目源码。
项目地址:https://github.com/microsoft/LoRA LORA提出至今已经2年了,但现在任然在更新项目代码
论文地址:https://arxiv.org/pdf/2106.09685.pdf
简读地址:https://blog.csdn.net/a486259/article/details/132767182?spm=1001.2014.3001.5501
1、基本介绍
1.1 实施效果
LORA技术使用RoBERTa(Liu et al.,2019)base和large以及DeBERTa(He et al.,2020)XXL 1.5B在GLUE基准上获得了与完全微调相当或优于完全微调的结果,而只训练和存储了一小部分参数。 LORA技术展现了与全参数迁移学习相同甚至更优的效果

在GPT-2上,LoRA与完全微调和其他大模型微调的方法(如Adapter(Houlsby et al.,2019)和Prefix(Li和Liang,2021))相比都要好。
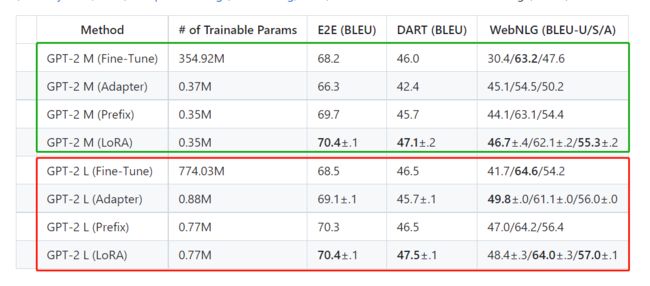
以上两图不仅展示了LORA在大模型上的微调效果,同时也透露了大模型性能提升的困难。DeBERTa
XXL的参数量是RoBERTa base的一百倍以上,而平均精度仅高4.6%;GPT2 L的参数量是GPT M的两倍以上,而平均精度仅高0.5%左右。这种参数增长与精度增长的差异在图像领域是少见的,尤其是目标检测|语义分割|图像分类中。
1.2 安装使用
这里仅限于官网给出的使用案例。LORA的实际使用应该是基于其他框架展开的
安装命令
pip install loralib
# Alternatively
# pip install git+https://github.com/microsoft/LoRA
构建可低秩训练层
LORA目前除了Linear层外,还支持其他layer。基于lora创建的layer是lora的子类,同时也是torch.nn.module的子类。
# ===== Before =====
# layer = nn.Linear(in_features, out_features)
# ===== After ======
import loralib as lora
# Add a pair of low-rank adaptation matrices with rank r=16
layer = lora.Linear(in_features, out_features, r=16)
设置仅LORA层可训练
这里要求model对象中的一些层是lora的子类,mark_only_lora_as_trainable函数会将参数name中不包含lora_的部分都设置为不可训练
import loralib as lora
model = BigModel()
# This sets requires_grad to False for all parameters without the string "lora_" in their names
lora.mark_only_lora_as_trainable(model)
# Training loop
for batch in dataloader:
...
保存模型参数
包含LORA层的模型,参数保存分两步完成,第一步保存原始模型的参数(通常可以忽略),第二步才是保存lora层的参数,对应代码为:torch.save(lora.lora_state_dict(model), checkpoint_path)
# ===== Before =====
torch.save(model.state_dict(), checkpoint_path)
# ===== After =====
torch.save(lora.lora_state_dict(model), checkpoint_path)
加载模型参数
包含lora层的模型参数加载也是分两步完成,第一步加载原始参数,第二步为加载lora层参数。
# Load the pretrained checkpoint first
model.load_state_dict(torch.load('ckpt_pretrained.pt'), strict=False)
# Then load the LoRA checkpoint
model.load_state_dict(torch.load('ckpt_lora.pt'), strict=False)
额外说明
某些Transformer实现使用单个nn.Linear。查询、键和值的投影矩阵为nn.Linear。如果希望将更新的秩约束到单个矩阵,则必须将其分解为三个单独的矩阵或使用lora.MergedLinear。如果选择分解层,请确保相应地修改checkpoint 。
# ===== Before =====
# qkv_proj = nn.Linear(d_model, 3*d_model)
# ===== After =====
# Break it up (remember to modify the pretrained checkpoint accordingly)
q_proj = lora.Linear(d_model, d_model, r=8)
k_proj = nn.Linear(d_model, d_model)
v_proj = lora.Linear(d_model, d_model, r=8)
# Alternatively, use lora.MergedLinear (recommended)
qkv_proj = lora.MergedLinear(d_model, 3*d_model, r=8, enable_lora=[True, False, True])
2、代码解读
lora项目的源码如下所示,其核心代码仅有layers.py和utils.py两个文件。
examples是两个使用案例,为第三方代码,这里不深入探讨。

2.1 Layer.py
在lora源码中,共有Embedding、Linear、MergedLinear、ConvLoRA 四种layer对象,均为nn.Module与 LoRALayer的子类。
样板layer解析
lora源码中layer对象比较多,这里只对Linear和·ConvLoRA 进行详细描述
Linear
在lora中,对于Linear的低秩分解由矩阵A、B的乘法所实现,其在forward时,lora分支BAlora_dropout操作,并对BA的输出结果进行scale操作。当调用layer.train(True)时,会根据self.merged参数将weight中的BA参数累加进行移除,当调用layer.train(False)时,则会将将BA参数累加到weight中。
这里需要注意,LoRA.Linear是nn.Linear的子类,在使用时直接参考nn.Linear的用法即可。
class Linear(nn.Linear, LoRALayer):
# LoRA implemented in a dense layer
def __init__(
self,
in_features: int,
out_features: int,
r: int = 0,
lora_alpha: int = 1,
lora_dropout: float = 0.,
fan_in_fan_out: bool = False, # Set this to True if the layer to replace stores weight like (fan_in, fan_out)
merge_weights: bool = True,
**kwargs
):
nn.Linear.__init__(self, in_features, out_features, **kwargs)
LoRALayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout,
merge_weights=merge_weights)
self.fan_in_fan_out = fan_in_fan_out
# Actual trainable parameters
if r > 0:
self.lora_A = nn.Parameter(self.weight.new_zeros((r, in_features)))
self.lora_B = nn.Parameter(self.weight.new_zeros((out_features, r)))
self.scaling = self.lora_alpha / self.r
# Freezing the pre-trained weight matrix
self.weight.requires_grad = False
self.reset_parameters()
if fan_in_fan_out:
self.weight.data = self.weight.data.transpose(0, 1)
def reset_parameters(self):
nn.Linear.reset_parameters(self)
if hasattr(self, 'lora_A'):
# initialize A the same way as the default for nn.Linear and B to zero
nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))
nn.init.zeros_(self.lora_B)
def train(self, mode: bool = True):
def T(w):
return w.transpose(0, 1) if self.fan_in_fan_out else w
nn.Linear.train(self, mode)
if mode:
if self.merge_weights and self.merged:
# Make sure that the weights are not merged
if self.r > 0:
self.weight.data -= T(self.lora_B @ self.lora_A) * self.scaling
self.merged = False
else:
if self.merge_weights and not self.merged:
# Merge the weights and mark it
if self.r > 0:
self.weight.data += T(self.lora_B @ self.lora_A) * self.scaling
self.merged = True
def forward(self, x: torch.Tensor):
def T(w):
return w.transpose(0, 1) if self.fan_in_fan_out else w
if self.r > 0 and not self.merged:
result = F.linear(x, T(self.weight), bias=self.bias)
result += (self.lora_dropout(x) @ self.lora_A.transpose(0, 1) @ self.lora_B.transpose(0, 1)) * self.scaling
return result
else:
return F.linear(x, T(self.weight), bias=self.bias)
ConvLoRA
LORA能对conv进行低秩分解,是博主意料之外的。该操作完整的将LoRALinear的思想应用到conv kernel中,有self.lora_B 和 self.lora_A两个可训练参数表述conv的kernel参数,将self.lora_B @ self.lora_A的结果直接作用到conv.weight中,然后调用self.conv._conv_forward完成卷积操作。
这里需要注意的是,使用ConvLoRA跟使用torch.nn.Conv是没有任何区别。这里只有一个问题,我们不能直接将conv对象转换为ConvLoRA对象。需要在构建网络时就使用ConvLoRA layer
class Conv2d(ConvLoRA):
def __init__(self, *args, **kwargs):
super(Conv2d, self).__init__(nn.Conv2d, *args, **kwargs)
class Conv1d(ConvLoRA):
def __init__(self, *args, **kwargs):
super(Conv1d, self).__init__(nn.Conv1d, *args, **kwargs)
class Conv3d(ConvLoRA):
def __init__(self, *args, **kwargs):
super(Conv3d, self).__init__(nn.Conv3d, *args, **kwargs)
class ConvLoRA(nn.Module, LoRALayer):
def __init__(self, conv_module, in_channels, out_channels, kernel_size, r=0, lora_alpha=1, lora_dropout=0., merge_weights=True, **kwargs):
super(ConvLoRA, self).__init__()
self.conv = conv_module(in_channels, out_channels, kernel_size, **kwargs)
LoRALayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout, merge_weights=merge_weights)
assert isinstance(kernel_size, int)
# Actual trainable parameters
if r > 0:
self.lora_A = nn.Parameter(
self.conv.weight.new_zeros((r * kernel_size, in_channels * kernel_size))
)
self.lora_B = nn.Parameter(
self.conv.weight.new_zeros((out_channels//self.conv.groups*kernel_size, r*kernel_size))
)
self.scaling = self.lora_alpha / self.r
# Freezing the pre-trained weight matrix
self.conv.weight.requires_grad = False
self.reset_parameters()
self.merged = False
def reset_parameters(self):
self.conv.reset_parameters()
if hasattr(self, 'lora_A'):
# initialize A the same way as the default for nn.Linear and B to zero
nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))
nn.init.zeros_(self.lora_B)
def train(self, mode=True):
super(ConvLoRA, self).train(mode)
if mode:
if self.merge_weights and self.merged:
if self.r > 0:
# Make sure that the weights are not merged
self.conv.weight.data -= (self.lora_B @ self.lora_A).view(self.conv.weight.shape) * self.scaling
self.merged = False
else:
if self.merge_weights and not self.merged:
if self.r > 0:
# Merge the weights and mark it
self.conv.weight.data += (self.lora_B @ self.lora_A).view(self.conv.weight.shape) * self.scaling
self.merged = True
def forward(self, x):
if self.r > 0 and not self.merged:
return self.conv._conv_forward(
x,
self.conv.weight + (self.lora_B @ self.lora_A).view(self.conv.weight.shape) * self.scaling,
self.conv.bias
)
return self.conv(x)
完整代码
# ------------------------------------------------------------------------------------------
# Copyright (c) Microsoft Corporation. All rights reserved.
# Licensed under the MIT License (MIT). See LICENSE in the repo root for license information.
# ------------------------------------------------------------------------------------------
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
from typing import Optional, List
class LoRALayer():
def __init__(
self,
r: int,
lora_alpha: int,
lora_dropout: float,
merge_weights: bool,
):
self.r = r
self.lora_alpha = lora_alpha
# Optional dropout
if lora_dropout > 0.:
self.lora_dropout = nn.Dropout(p=lora_dropout)
else:
self.lora_dropout = lambda x: x
# Mark the weight as unmerged
self.merged = False
self.merge_weights = merge_weights
class Embedding(nn.Embedding, LoRALayer):
# LoRA implemented in a dense layer
def __init__(
self,
num_embeddings: int,
embedding_dim: int,
r: int = 0,
lora_alpha: int = 1,
merge_weights: bool = True,
**kwargs
):
nn.Embedding.__init__(self, num_embeddings, embedding_dim, **kwargs)
LoRALayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=0,
merge_weights=merge_weights)
# Actual trainable parameters
if r > 0:
self.lora_A = nn.Parameter(self.weight.new_zeros((r, num_embeddings)))
self.lora_B = nn.Parameter(self.weight.new_zeros((embedding_dim, r)))
self.scaling = self.lora_alpha / self.r
# Freezing the pre-trained weight matrix
self.weight.requires_grad = False
self.reset_parameters()
def reset_parameters(self):
nn.Embedding.reset_parameters(self)
if hasattr(self, 'lora_A'):
# initialize A the same way as the default for nn.Linear and B to zero
nn.init.zeros_(self.lora_A)
nn.init.normal_(self.lora_B)
def train(self, mode: bool = True):
nn.Embedding.train(self, mode)
if mode:
if self.merge_weights and self.merged:
# Make sure that the weights are not merged
if self.r > 0:
self.weight.data -= (self.lora_B @ self.lora_A).transpose(0, 1) * self.scaling
self.merged = False
else:
if self.merge_weights and not self.merged:
# Merge the weights and mark it
if self.r > 0:
self.weight.data += (self.lora_B @ self.lora_A).transpose(0, 1) * self.scaling
self.merged = True
def forward(self, x: torch.Tensor):
if self.r > 0 and not self.merged:
result = nn.Embedding.forward(self, x)
after_A = F.embedding(
x, self.lora_A.transpose(0, 1), self.padding_idx, self.max_norm,
self.norm_type, self.scale_grad_by_freq, self.sparse
)
result += (after_A @ self.lora_B.transpose(0, 1)) * self.scaling
return result
else:
return nn.Embedding.forward(self, x)
class Linear(nn.Linear, LoRALayer):
# LoRA implemented in a dense layer
def __init__(
self,
in_features: int,
out_features: int,
r: int = 0,
lora_alpha: int = 1,
lora_dropout: float = 0.,
fan_in_fan_out: bool = False, # Set this to True if the layer to replace stores weight like (fan_in, fan_out)
merge_weights: bool = True,
**kwargs
):
nn.Linear.__init__(self, in_features, out_features, **kwargs)
LoRALayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout,
merge_weights=merge_weights)
self.fan_in_fan_out = fan_in_fan_out
# Actual trainable parameters
if r > 0:
self.lora_A = nn.Parameter(self.weight.new_zeros((r, in_features)))
self.lora_B = nn.Parameter(self.weight.new_zeros((out_features, r)))
self.scaling = self.lora_alpha / self.r
# Freezing the pre-trained weight matrix
self.weight.requires_grad = False
self.reset_parameters()
if fan_in_fan_out:
self.weight.data = self.weight.data.transpose(0, 1)
def reset_parameters(self):
nn.Linear.reset_parameters(self)
if hasattr(self, 'lora_A'):
# initialize A the same way as the default for nn.Linear and B to zero
nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))
nn.init.zeros_(self.lora_B)
def train(self, mode: bool = True):
def T(w):
return w.transpose(0, 1) if self.fan_in_fan_out else w
nn.Linear.train(self, mode)
if mode:
if self.merge_weights and self.merged:
# Make sure that the weights are not merged
if self.r > 0:
self.weight.data -= T(self.lora_B @ self.lora_A) * self.scaling
self.merged = False
else:
if self.merge_weights and not self.merged:
# Merge the weights and mark it
if self.r > 0:
self.weight.data += T(self.lora_B @ self.lora_A) * self.scaling
self.merged = True
def forward(self, x: torch.Tensor):
def T(w):
return w.transpose(0, 1) if self.fan_in_fan_out else w
if self.r > 0 and not self.merged:
result = F.linear(x, T(self.weight), bias=self.bias)
result += (self.lora_dropout(x) @ self.lora_A.transpose(0, 1) @ self.lora_B.transpose(0, 1)) * self.scaling
return result
else:
return F.linear(x, T(self.weight), bias=self.bias)
class MergedLinear(nn.Linear, LoRALayer):
# LoRA implemented in a dense layer
def __init__(
self,
in_features: int,
out_features: int,
r: int = 0,
lora_alpha: int = 1,
lora_dropout: float = 0.,
enable_lora: List[bool] = [False],
fan_in_fan_out: bool = False,
merge_weights: bool = True,
**kwargs
):
nn.Linear.__init__(self, in_features, out_features, **kwargs)
LoRALayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout,
merge_weights=merge_weights)
assert out_features % len(enable_lora) == 0, \
'The length of enable_lora must divide out_features'
self.enable_lora = enable_lora
self.fan_in_fan_out = fan_in_fan_out
# Actual trainable parameters
if r > 0 and any(enable_lora):
self.lora_A = nn.Parameter(
self.weight.new_zeros((r * sum(enable_lora), in_features)))
self.lora_B = nn.Parameter(
self.weight.new_zeros((out_features // len(enable_lora) * sum(enable_lora), r))
) # weights for Conv1D with groups=sum(enable_lora)
self.scaling = self.lora_alpha / self.r
# Freezing the pre-trained weight matrix
self.weight.requires_grad = False
# Compute the indices
self.lora_ind = self.weight.new_zeros(
(out_features, ), dtype=torch.bool
).view(len(enable_lora), -1)
self.lora_ind[enable_lora, :] = True
self.lora_ind = self.lora_ind.view(-1)
self.reset_parameters()
if fan_in_fan_out:
self.weight.data = self.weight.data.transpose(0, 1)
def reset_parameters(self):
nn.Linear.reset_parameters(self)
if hasattr(self, 'lora_A'):
# initialize A the same way as the default for nn.Linear and B to zero
nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))
nn.init.zeros_(self.lora_B)
def zero_pad(self, x):
result = x.new_zeros((len(self.lora_ind), *x.shape[1:]))
result[self.lora_ind] = x
return result
def merge_AB(self):
def T(w):
return w.transpose(0, 1) if self.fan_in_fan_out else w
delta_w = F.conv1d(
self.lora_A.unsqueeze(0),
self.lora_B.unsqueeze(-1),
groups=sum(self.enable_lora)
).squeeze(0)
return T(self.zero_pad(delta_w))
def train(self, mode: bool = True):
def T(w):
return w.transpose(0, 1) if self.fan_in_fan_out else w
nn.Linear.train(self, mode)
if mode:
if self.merge_weights and self.merged:
# Make sure that the weights are not merged
if self.r > 0 and any(self.enable_lora):
self.weight.data -= self.merge_AB() * self.scaling
self.merged = False
else:
if self.merge_weights and not self.merged:
# Merge the weights and mark it
if self.r > 0 and any(self.enable_lora):
self.weight.data += self.merge_AB() * self.scaling
self.merged = True
def forward(self, x: torch.Tensor):
def T(w):
return w.transpose(0, 1) if self.fan_in_fan_out else w
if self.merged:
return F.linear(x, T(self.weight), bias=self.bias)
else:
result = F.linear(x, T(self.weight), bias=self.bias)
if self.r > 0:
result += self.lora_dropout(x) @ T(self.merge_AB().T) * self.scaling
return result
class ConvLoRA(nn.Module, LoRALayer):
def __init__(self, conv_module, in_channels, out_channels, kernel_size, r=0, lora_alpha=1, lora_dropout=0., merge_weights=True, **kwargs):
super(ConvLoRA, self).__init__()
self.conv = conv_module(in_channels, out_channels, kernel_size, **kwargs)
LoRALayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout, merge_weights=merge_weights)
assert isinstance(kernel_size, int)
# Actual trainable parameters
if r > 0:
self.lora_A = nn.Parameter(
self.conv.weight.new_zeros((r * kernel_size, in_channels * kernel_size))
)
self.lora_B = nn.Parameter(
self.conv.weight.new_zeros((out_channels//self.conv.groups*kernel_size, r*kernel_size))
)
self.scaling = self.lora_alpha / self.r
# Freezing the pre-trained weight matrix
self.conv.weight.requires_grad = False
self.reset_parameters()
self.merged = False
def reset_parameters(self):
self.conv.reset_parameters()
if hasattr(self, 'lora_A'):
# initialize A the same way as the default for nn.Linear and B to zero
nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))
nn.init.zeros_(self.lora_B)
def train(self, mode=True):
super(ConvLoRA, self).train(mode)
if mode:
if self.merge_weights and self.merged:
if self.r > 0:
# Make sure that the weights are not merged
self.conv.weight.data -= (self.lora_B @ self.lora_A).view(self.conv.weight.shape) * self.scaling
self.merged = False
else:
if self.merge_weights and not self.merged:
if self.r > 0:
# Merge the weights and mark it
self.conv.weight.data += (self.lora_B @ self.lora_A).view(self.conv.weight.shape) * self.scaling
self.merged = True
def forward(self, x):
if self.r > 0 and not self.merged:
return self.conv._conv_forward(
x,
self.conv.weight + (self.lora_B @ self.lora_A).view(self.conv.weight.shape) * self.scaling,
self.conv.bias
)
return self.conv(x)
class Conv2d(ConvLoRA):
def __init__(self, *args, **kwargs):
super(Conv2d, self).__init__(nn.Conv2d, *args, **kwargs)
class Conv1d(ConvLoRA):
def __init__(self, *args, **kwargs):
super(Conv1d, self).__init__(nn.Conv1d, *args, **kwargs)
# Can Extend to other ones like this
class Conv3d(ConvLoRA):
def __init__(self, *args, **kwargs):
super(Conv3d, self).__init__(nn.Conv3d, *args, **kwargs)
2.2 utils.py
期内有mark_only_lora_as_trainable、lora_state_dict两个函数。mark_only_lora_as_trainable函数用于冻结模型的非lora layer参数,该函数基于name区分lora layer 层name中包含lora_。其参数bias设置用于设model中的bias是否可训练,bias == 'none'表示忽略bias,bias == 'all'表示所有偏置都可以训练,bias == 'lora_only'表示仅有lora layer的bias可以训练
lora_state_dict函数用于加载lora保存的参数,参数bias == 'none'表明只加载lora参数,参数bias == 'all'表明加载lora参数和所有bias参数,
import torch
import torch.nn as nn
from typing import Dict
from .layers import LoRALayer
def mark_only_lora_as_trainable(model: nn.Module, bias: str = 'none') -> None:
for n, p in model.named_parameters():
if 'lora_' not in n:
p.requires_grad = False
if bias == 'none':
return
elif bias == 'all':
for n, p in model.named_parameters():
if 'bias' in n:
p.requires_grad = True
elif bias == 'lora_only':
for m in model.modules():
if isinstance(m, LoRALayer) and \
hasattr(m, 'bias') and \
m.bias is not None:
m.bias.requires_grad = True
else:
raise NotImplementedError
def lora_state_dict(model: nn.Module, bias: str = 'none') -> Dict[str, torch.Tensor]:
my_state_dict = model.state_dict()
if bias == 'none':
return {k: my_state_dict[k] for k in my_state_dict if 'lora_' in k}
elif bias == 'all':
return {k: my_state_dict[k] for k in my_state_dict if 'lora_' in k or 'bias' in k}
elif bias == 'lora_only':
to_return = {}
for k in my_state_dict:
if 'lora_' in k:
to_return[k] = my_state_dict[k]
bias_name = k.split('lora_')[0]+'bias'
if bias_name in my_state_dict:
to_return[bias_name] = my_state_dict[bias_name]
return to_return
else:
raise NotImplementedError