ClickHouse MergeTree副本表和分布式表(切片)
在前面的文章中我们详细介绍了 MergeTree 表引擎、MergeTree 家族其他表引擎、MergeTree 二级索引等内容,clickhouse数据库都是在单节点上运行的,作为OLAP处理的大数据利器,clickhouse 显然少了两个功能——数据高可用(HA)和横向扩展。HA的目的是为了如果有一个数据副本丢失或者损坏不至于完全丢失数据,至于横向扩展自然是为了提高数据存储能力了。
1. MergeTree副本表
ClickHouse MergeTree 副本表的数据一致性同步是通过Zookeeper实现的,和Hdfs主备namenode之间的数据同步原理一样,所以如果需要使用副本表必须在clickhouse配置文件中配置Zookeeper(Zookeeper 版本 >= 3.4.5)。
(1) Zookeeper配置
可以直接在config.d/config.xml 中配置Zookeeper信息,也可以在一个单独的文件中配置,然后在config.xml中引用,为了便于管理,我们在单独文件中配置。在config.xml相同目录下新建 metrika.xml 文件,首先写入 Zookeeper 地址:
<yandex>
<zookeeper-servers>
<node index="1">
<host>example1host>
<port>2181port>
node>
<node index="2">
<host>example2host>
<port>2181port>
node>
<node index="3">
<host>example3host>
<port>2181port>
node>
zookeeper-servers>
yandex>
ClickHouse除了使用Apache ZooKeeper来同步数据和DDL语句外,还用来存储副本的元数据信息(相当于clickhouse的namenode,保存副本位置、操作日志、校验值、选主信息等)、分布式协调等。ClickHouse还支持在辅助ZooKeeper集群中备份副本元数据信息,但是一般使用不多,因为ZooKeeper本身就是多节点的,如果需要配置辅助ZooKeeper集群信息,可参考如下设置,这也就意味着可以把同一个clickhouse数据库的不同表的元数据信息保存在不同的ZooKeeper集群中,当集群规模非常大时(建议至少大于300个节点)这样可以提高处理效率:
<auxiliary_zookeepers>
<zookeeper2>
<node>
<host>example_2_1host>
<port>2181port>
node>
<node>
<host>example_2_2host>
<port>2181port>
node>
<node>
<host>example_2_3host>
<port>2181port>
node>
zookeeper2>
<zookeeper3>
<node>
<host>example_3_1host>
<port>2181port>
node>
zookeeper3>
auxiliary_zookeepers>
然后在config.xml中添加如下配置,并同步配置文件到其他节点:
<zookeeper incl="zookeeper-servers" optional="true" />
<include_from>/etc/clickhouse-server/config.d/metrika.xmlinclude_from>
(2)建表语句
在需要存储副本的节点上创建相同的副本表(注意副本表只能同步数据,不能同步DDL语句,所以需要分别在副本节点上执行建表语句):
第一个节点执行
CREATE TABLE t ( ... ) ENGINE = ReplicatedMergeTree('/clickhouse/tables/01/t', 'rep_101') ...;
第二个节点执行
CREATE TABLE t ( ... ) ENGINE = ReplicatedMergeTree('/clickhouse/tables/01/t', 'rep_102') ...;
ReplicatedMergeTree 的第一个参数是副本信息在ZooKeeper路径,一般按照 /clickhouse/tables/{shard}/{table_name} 的格式写,如果只有一个分片{shard}就写01即可;第二个参数是副本名称,不同的副本名称不能相同,可以使用主机名。
※注意: 即使rename表名,ZooKeeper路径也是不会改变的,注意保持路径不要重复。
clickhouse有两个内置的宏变量:{database} 和 {table},因此ZooKeeper路径也可以使用:
/clickhouse/tables/01/{database}/{table}
※注意: 当rename表名后,宏变量会扩展到另一个路径,表会指向Zookeeper中不存在的路径,并进入只读模式,所以不要轻易rename副本表,如果使用宏变量。
如果觉得设置麻烦,也可以在配置文件中设置默认参数,例如:
<macros>
<layer>05layer>
<shard>02shard>
<replica>example05-02-1replica>
macros>
<default_replica_path>/clickhouse/tables/{shard}/{database}/{table}default_replica_path>
<default_replica_name>{replica}default_replica_name>
不同的节点副本名称参数不一样即可。这样,下面的语句就是等价的:
CREATE TABLE table_name (
x UInt32
) ENGINE = ReplicatedMergeTree
ORDER BY x;
CREATE TABLE table_name (
x UInt32
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/{database}/table_name', '{replica}')
ORDER BY x;
执行CREATE语句就表示创建一个副本,如果已有数据的情况下创建新的副本,新副本会自动同步历史数据。
(3)数据恢复
当服务器启动时,如果ZooKeeper不可用,副本表会切换到只读模式。系统周期性尝试连接ZooKeeper。如果在INSERT操作中,ZooKeeper不可用,或者与ZooKeeper交互出错,会引发异常。连接ZooKeeper后,系统会检查本地文件系统的数据集是否与期望的数据集匹配(ZooKeeper中保存的信息)。如果出现轻微的不一致,系统会通过与副本同步数据来解决。当系统检测到损坏的数据块(文件大小错误)或无法识别的数据块(写入文件系统但不记录在ZooKeeper中)时,系统会将其移动到 detached 子目录中(不删除,ClickHouse不会执行任何破坏性的操作)。任何缺失的数据块都从其他副本中拷贝。
※注意: 当服务器启动(或与ZooKeeper建立新的会话)时,它只检查所有文件的数量和大小。如果文件大小匹配,但在中间的某个地方改变了字节,则不会立即检测到这一点,而只有在尝试读取SELECT查询的数据时才会检测到。该查询将抛出一个关于不匹配的校验异常或者压缩块大小的异常。在这种情况下,数据部块被添加到验证队列中,并在必要时从副本中复制。如果本地数据集与预期数据集相差太多,就会触发安全机制。服务器将此信息写入日志并拒绝启动。这样做的原因是,这种情况可能表明了一个配置错误,例如,如果一个分片上的副本被意外地配置为类似于另一个分片上的副本。但是,这种机制的阈值设置得相当低,这种情况可能会在正常故障恢复期间发生。在这种情况下,数据是半自动恢复的,需要给clickhouse一个触发信号:可以在ZooKeeper 上创建节点:
/path_to_table/replica_name/flags/force_restore_data
或者执行下面命令:
sudo -u clickhouse touch /var/lib/clickhouse/flags/force_restore_data
如果某个节点上的数据完全丢失了,可以在丢失节点上执行 drop table,删除 ZooKeeper 上的副本信息,然后重新执行create table语句。
(4)转换MergeTree为ReplicatedMergeTree
重命名现有的MergeTree表,然后用旧名称创建一个ReplicatedMergeTree表。将数据从旧表移动到新表数据的 detached 目录中。然后在其中一个副本上运行 ALTER TABLE ATTACH PARTITION,将这些数据部分添加到新表工作集中。
(5)转换ReplicatedMergeTree为MergeTree
用不同的名称创建一个新的MergeTree表。将ReplicatedMergeTree表data目录移下的所有数据移动到新表的 data 目录。然后删除ReplicatedMergeTree表并重新启动服务器。
2. Distributed 表引擎
副本虽然能够提高数据的可用性,降低丢失风险,但是并没有解决存储的横向扩展问题。要解决数据水平切分的问题,需要引入分片的概念。通过分片把一份完整的数据进行切分,不同的分片分布到不同的节点上,再通过 Distributed 表引擎把数据拼接起来一同使用,所以在实际使用中往往是副本表+分布式表一起使用。
Distributed 引擎表不存储任何数据,但可以在多个服务器上进行分布式查询处理。换句话说就是 Distributed 表引擎更类似于一种跨节点的表管理工具,在使用的时候基于本地表(如 MergeTree表)和集群创建 Distributed 表(本质是视图)。这里有三个概念:
- 本地表:真正存储数据的对象,或者称之为表,如一个 MergeTree 表。
- 集群:clickhouse 的 cluster(集群)概念和其他分布式组件的集群概念不同,是可定义的,我更愿意称之为狭义的clickhouse集群,换句话说一个有多个物理节点的广义clickhouse集群可以定义多个狭义集群。如不特别说明,下文提到的集群都是指狭义集群。集群可提供DDL语句同步、副本和分片定义等功能。
- Distributed 表引擎本身不存储数据,只是一个分布式视图,会查询本地表数据,而且读取是自动并行化的。在读取期间,会使用远程服务器上的表索引(如果有的话)。
(1) 集群配置
Distributed 表因为需要定义副本和分片数量,所以需要在配置文件中先配置集群信息。clickhouse的集群是表级别的,并且是在配置文件中定义的,所以对于clickhouse集群在使用前一定要规划好。对于一个6节点、3分片、2副本的集群可配置如下。编辑metrika.xml文件:
<yandex>
<remote_servers>
<gmall_cluster>
<shard>
<internal_replication>trueinternal_replication>
<replica>
<host>hadoop101host>
<port>9000port>
replica>
<replica>
<host>hadoop102host>
<port>9000port>
replica>
shard>
<shard>
<internal_replication>trueinternal_replication>
<replica>
<host>hadoop103host>
<port>9000port>
replica>
<replica>
<host>hadoop104host>
<port>9000port>
replica>
shard>
<shard>
<internal_replication>trueinternal_replication>
<replica>
<host>hadoop105host>
<port>9000port>
replica>
<replica>
<host>hadoop106host>
<port>9000port>
replica>
shard>
gmall_cluster>
remote_servers>
<zookeeper-servers>
<node index="1">
<host>example1host>
<port>2181port>
node>
<node index="2">
<host>example2host>
<port>2181port>
node>
<node index="3">
<host>example3host>
<port>2181port>
node>
zookeeper-servers>
<macros>
<shard>01shard>
<replica>rep_1_1replica>
macros>
yandex>
配置文件是动态扫描的,如果增加了新的集群不需要重启数据库,但是如果使用的是域名(不是IP),修改了域名后需要重启数据库。
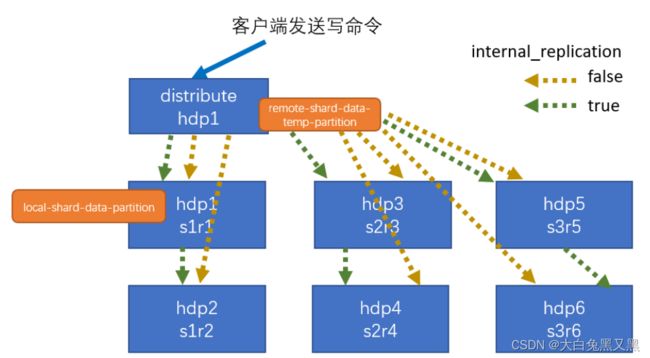
是集群名称,可以定义多个集群,可查询“system.clusters”表查看已有集群信息。 表示是否启用内部复制,如果为 true 表示当往 Distributed 表中写入数据时只写入到一个副本,其他副本数据通过复制表和ZooKeeper异步进行(下图绿线),也即此时的本地表必须是副本表,如果为 false 表示往 Distributed 表中写入数据时会同时往所有副本表中写数据,此时本地表可以不是副本表,一般配置为 true,官方建议也是 true,这样可以加快写效率,而且可以保证数据一致性,但是不能保证写过程中一致性(因为是异步进行的)。但是在大数据量情况下,更高效的做法是直接写本地表,读分布式表,例如对于3分片的集群,写数据的时候通过三个线程写入三个分片节点所在本地表。 - 除了上述配置项外,还可以在分片shard配置项内添加权重配置weight,写入数据时会有更大概率落入权重较大的分片中,假如一个shard weight是1,第二个shard weight是2,则会有1/3的数据写入第一个shard,2/3的数据写入第二个shard。
(2) 创建 Distributed 表
在创建 Distributed 表之前需要先创建本地表,因为我们是两副本,所以就是Replicated表:
create table st_order_mt_local on cluster gmall_cluster (
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine=ReplicatedMergeTree('/clickhouse/tables/{shard}/test_db/st_order_mt_local','{replica}')
partition by toYYYYMMDD(create_time)
primary key (id) order by (id,sku_id);
创建 Distributed 表语句如下:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = Distributed(cluster, database, table[, sharding_key[, policy_name]])
[SETTINGS name=value, ...]
表引擎参数如下:
- cluster:服务器配置文件中的集群名称(集群名称不能有点),例如我们配置的 mall_cluster
- database:使用的数据库名称,例如 test_db
- table:引用的本地表表名,例如前面定义的 st_order_mt_local
- sharding_key:分片的key(可选),决定写入数据的时候数据分发到哪一个节点上,一般使用hash值或者rand(),也可以直接使用列字段值(例如 int类型列),这样可以保证key一样的记录可以存储在同一个分片中,从而降低 IN 和 JOIN 语句的运行复杂度。如果数据分布不均匀,这需要用hash函数包装。
- policy_name:策略名称,它会被用作存储临时文件以便异步发送数据
直接定义 Distributed 表结构会比较麻烦,更常见的用户是直接基于本地表创建:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] AS [db2.]name2
ENGINE = Distributed(cluster, database, table[, sharding_key[, policy_name]]) [SETTINGS name=value, ...]
则 st_order_mt_local 表对应的 Distributed 表为:
create table st_order_mt on cluster gmall_cluster as st_order_mt_local
engine = Distributed(gmall_cluster, default, st_order_mt, intHash64(id));
和之前的建表语句不同,在建表语句中我们使用了 on cluster 选项,根据集群配置信息,可以自动同步DDL语句到所有集群节点上。一般我们可以可以配置3个集群,一个作为默认集群,专门用来同步DDL,再配置两个internal_replication分别为true和false的集群供用户选择。
在创建 Distributed 表时一般有三种推荐命名规则,可根据业务选择:
- 本地表表名为:业务前缀 + _local;Distributed 表表名为:业务前缀。这也是我们例子中使用的命名规则,好处是本地表和分布式表容易区分,而且在迁移数据到clickhouse以后原有的任务使用的表名不需要改变。
- 本地表表名为:业务前缀;Distributed 表表名为:业务前缀 + _all。
- 本地表表名为:业务前缀 + _local;Distributed 表表名为:业务前缀 + _all。
Distributed 表的分片机制和Hdfs的横向存储扩展是不同的,Hdfs是按照分块存储的,一个块满了以后再切分一个新块,Distributed 表的分片机制更像kafka的分区机制,即使数据很少根据分片机制也会分布到不同的集群节点上。如果集群进行扩容增加了新的节点,一般也不需要手动 rebalance,可以增加新节点的权重,不影响select效率。
关于分片的选择,一般建议:
- 集群、数据量都不大,没有合适的分片key,可以直接使用rand()。
- 集群有几十个节点,或者经常需要 JOIN 、IN 操作,可以根据关联的key,或者key的hash值分片。
- 集群规模超过百台,建议直接写本地表,尤其是对于一些小表,没必要分散到太多节点上。当然,也可以配置一个小集群供小表使用,或者将集群分化为“层”。
如果直接写 Distributed,可以异步写入,也可以同步写入,通过 insert_distributed_sync 控制。
- insert_distributed_sync 为 0(默认值)表示异步写入,
- insert_distributed_sync 为 1表示同步写入,只有当所有数据都保存在所有shard上(如果internal_replication为true,每个shard至少有一个副本写成功),INSERT操作才会成功。
对于异步写入。当插入到表中时,将数据块基于分片信息写入到本地文件系统,然后在后台将不同分片数据发送到远程服务器。发送数据的周期由distributed_directory_monitor_sleep_time_ms和distributed_directory_monitor_max_sleep_time_ms设置项管理。分布式引擎会分别发送带有插入数据的每个文件,但是你可以使用distributed_directory_monitor_batch_inserts(默认是关闭的)设置启用批量发送文件。该设置通过更好地利用本地服务器和网络资源来提高集群性能。通过查看表目录“/var/lib/clickhouse/data/database/table/”中待发送的文件列表(即待发送的数据),判断数据是否发送成功。执行后台任务的线程数可以通过设置background_distributed_schedule_pool_size(默认值是16个线程)来设置。
如果在对分布式表进行INSERT操作后,服务器宕机或进行了重启(例如,由于硬件故障),则插入的数据可能会丢失。如果在表目录中检测到损坏的数据部件,则将其转移到broken子目录并不再使用。
当查询一个分布式表时,SELECT查询被发送到所有的shard,不管数据是如何分布在shard上的,所以即使没有按照建表时的分片机制插入数据也没关系。在查询时,默认是查询其中一个副本数据,对于具有采样键(建表语句指定了 sample)的副本表可以通过设置 max_parallel_replicas 提高查询效率。当启用max_parallel_replicas选项时,查询处理将跨单个分片中的所有副本并行化。关于 Distributed 表的查询还会有一些注意和优化事项,如使用 IN 和 GLOBAL IN 的不同等,我们将在后面的文章中介绍。