SVM的支持向量、非线性求解以及对偶问题下的推导过程
支持向量
线性可分:
一个线性可分的训练集是指:存在超平面(w,b)对于(Xi,Yi)有:若Y~i = 1, 则wX~i + b >= 0 ;若Y~i = -1, 则wX~i + b < 0 .
这种形式标示在几何中就是存在一个平面将 训练集 进行切分,使得切分后的两侧属于两个不同的分类
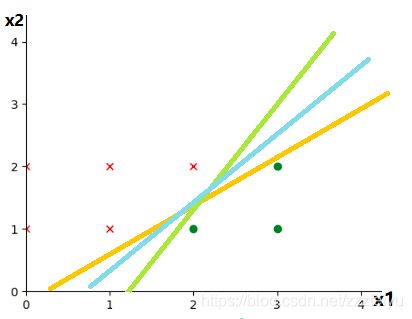
哪种划分是我们要找的:
在上图中直觉告诉我们是蓝色的,原因可以用容错率来说明,如下图所示,在误差允许情况下,蓝色线的分类的表现是最佳的.也就是找与两侧间隔最大的
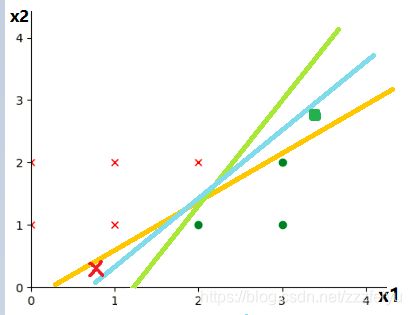
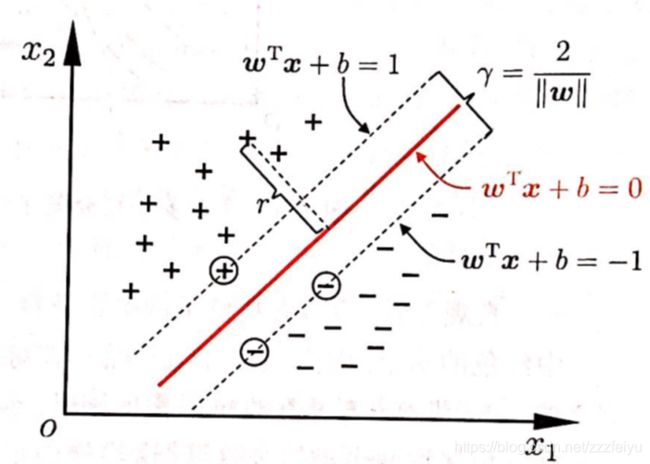
间隔:
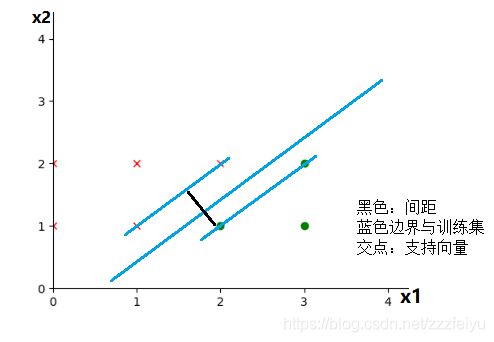
将蓝色的线平行移动,与两中分类相交第一次相交的位置的交点就是支持向量,后续的向量是不被考虑的,所以也等价于说两侧的支持向量的中间位置就决定了蓝色分类线的位置.点到平面的距离公式
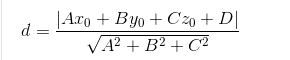
其中公式中的平面方程为Ax+By+Cz+D=0,点P的坐标(x0,y0,z0),d为点P到平面的距离。
也就是说对于wT*x + b = 0这个平面:
d = ∣ w T X o + b ∣ / ∣ ∣ w ∣ ∣ d = |wTXo + b| / ||w|| d=∣wTXo+b∣/∣∣w∣∣
由于向量wTX的乘积是一个数,所以d的分子部分结果一定是一个数c1,又因为
w T ∗ X o + b = 0 和 a ∗ w T ∗ X o + a ∗ b = 0 是 同 一 个 平 面 wT*Xo + b = 0 和 a*wT*Xo + a * b = 0 是同一个平面 wT∗Xo+b=0和a∗wT∗Xo+a∗b=0是同一个平面
所以可以通过缩放求得在支持向量上 wTXo + b = 1,即:
d = 1 / ∣ ∣ w ∣ ∣ d = 1 / ||w|| d=1/∣∣w∣∣
也就是说目标最大化d变为:最小化 ||w||²,方便求导的话也等价于 1/2 * ||w||²
支持向量机的数学描述:
基于线性可分可写为:
-
已知Xi和Yi:
-
前提条件:线性可分
-
求 w 和 b,其中w是一个向量,与X~i是同维度的
-
目标:最小化
1 / 2 ∗ ∣ ∣ w ∣ ∣ ² 1/2 * ||w||² 1/2∗∣∣w∣∣² -
限制条件:
y i [ w T ∗ x i + b ] > = 1 yi [ w T*xi + b] >= 1 yi[wT∗xi+b]>=1 -
当限制条件取等式时,求的X~i是支持向量,后续的距离都大于支持向量
-
Y~i只能是+1 或者 -1
非线性的情况
非线性可分条件的变化:
在非线性的情况下可以通过给平面的切分增加一个松弛的变量,或者说可以给一个大的允许误差,这个误差设为ξi,数学描述如下:
-
最小化:
1 / 2 ∗ ∣ ∣ w ∣ ∣ ² + C ∑ i = 1 n ξ i 1/2*||w||² + C \sum_{i=1}^n\xi i 1/2∗∣∣w∣∣²+Ci=1∑nξi -
相对应的限制条件改为:
ξ i > = 0 ( ξ i < 0 就 不 是 对 条 件 进 行 松 弛 了 ) ξi>=0 (ξi<0就不是对条件进行松弛了) ξi>=0(ξi<0就不是对条件进行松弛了)y i [ w T ∗ x i + b ] > = 1 − ξ i yi [ w T*xi + b] >= 1 -\xi i yi[wT∗xi+b]>=1−ξi
-
求的变量是 w,b,ξi
-
ξi:这个增加的松弛变量,也就是正则项的一部分,所起到的作用是将原本非线性可分的情况,通过松弛-这种软间隔的方式将限制条件可以放的更宽松(我的理解是可能在k维时候绝大部分已经被线性分开,只有少量的离散的点可能不符合线性可分,但是此时通过减少约束使得它满足而不必再更高的过度拟合),使得原本非线性可分的情况下"近似于"线性可分. 极端条件下当ξi无线大的时候,1-ξi无线小,限制条件总是可以被满足的.
-
C:C是ξi的常数系数,可以对w和ξi的比例进行缩放,这样可以通过给ξi一个适当的惩罚系数使得最小化整个式子的过程中ξi不至于过大
近似还是去更高维度求解
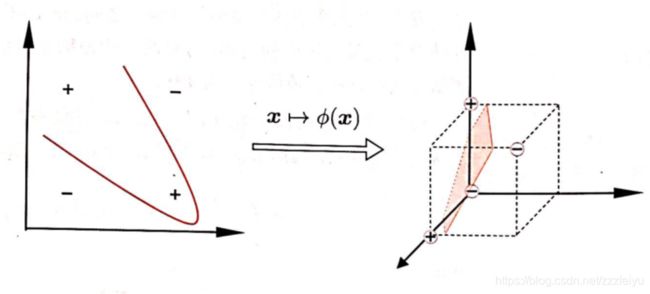
在非线性的情况下,支持向量机没有去寻找一种当前维度下近似的平面或曲面,而是将目光转向更高维度. 因为在近似无限维度的情况下,任意选取特征的训练集都是线性可分的,所以SVM首先将原训练集的x利用一个函数例如ψ(x)映射到更高的维度甚至是无限维度,然后进行线性可分的求解
数学描述
将以上两点做一个简单的综合我们可以做出如下非线性高维的求解描述:
-
最小化
1 / 2 ∗ ∣ ∣ w ∣ ∣ ² + C ∑ i = 1 n ξ i 1/2*||w||² + C \sum_{i=1}^n\xi i 1/2∗∣∣w∣∣²+Ci=1∑nξi -
代入ψ(x)限制条件变为:
ξ i > = 0 ξi>=0 ξi>=0y i [ w T ∗ ψ ( x i ) + b ] > = 1 − ξ i yi [ w T*ψ(xi) + b] >= 1 -\xi i yi[wT∗ψ(xi)+b]>=1−ξi
问题
但是这种方法是存在以下问题的:ψ(x)在高纬度甚至是无限维度下是不可知的,这里需要利用到后面的核函数,它有一个很重要的表达式如下
K ( x 1 , x 2 ) = ψ ( x 1 ) T ∗ ψ ( x 2 ) K(x1,x2) = ψ(x1)T *ψ(x2) K(x1,x2)=ψ(x1)T∗ψ(x2)
这样我们就有可能在不知道ψ(x)的显示表达式的条件下通过K(x1,x2)来替换ψ(x)进行优化
对偶问题
原问题与对偶问题
原问题:
-
最小化:f(w)
-
限制条件:
g i ( w ) ≤ 0 gi(w)≤0 gi(w)≤0h i ( w ) = 0 hi(w)=0 hi(w)=0
定义:
L ( w , α , β ) = f ( w ) + ∑ i = 1 k α i ∗ g i ( w ) + ∑ j = 1 m α i ∗ h i ( w ) L(w,\alpha,\beta) = f(w) + \sum_{i=1}^k \alpha i *gi(w) + \sum_{j=1}^m \alpha i * hi(w) L(w,α,β)=f(w)+i=1∑kαi∗gi(w)+j=1∑mαi∗hi(w)
等 价 于 L ( w , α , β ) = f ( w ) + α T ∗ g ( w ) + β T ∗ h ( w ) 等价于 L(w,\alpha,\beta) = f(w) + \alpha T*g(w) + \beta T* h(w) 等价于L(w,α,β)=f(w)+αT