ElasticSearch
1、elasticSearch作用
主要用于搜索和分析数据
2、应用
应用程序搜索
网址搜索
日志处理和分析
基础设施指标和容器监测
地理空间数据分析和可视化
安全分析
业务分析
3、基本概念
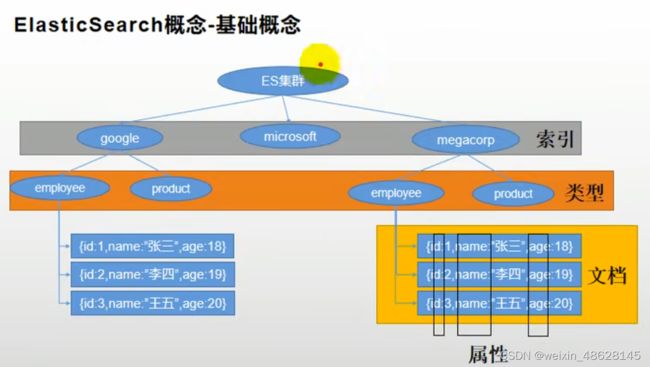
(1) index 索引,相当于mysql的Database
(2)Type 类型 相当于数据库的表
(3)Document文档(文档是JSON格式的,就像是mysql中的某个table里面的内容)
(4)倒排索引(索引表,就是把句子进行拆分,做成一个索引表,句子中有相关的单词就把句子加入到记录中,最后再进行相关性得分)

4、安装
docker pull elasticsearch:7.4.2
docker pull kibana:7.4.2 可视化检索数据
二、初步索引
使用postman
1、_cat
http://地址:9200/_cat/nodes 查看所有节点
http://地址:9200/_cat/health 查看es的健康状况
http://地址:9200/_cat/master 查看主节点
http://地址:9200/_cat/indices 查看所有索引
2、索引一个文档(保存)
(1)put操作(创建跟更新数据) 必须带id http://地址:9200/索引/类型/id
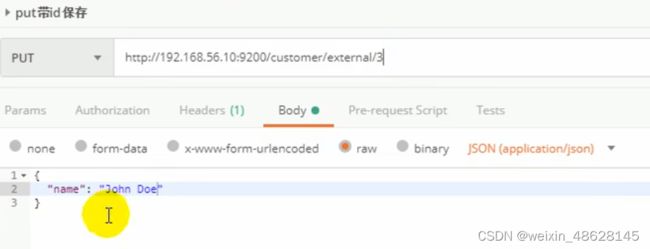
(2)post操作(新增跟更新) 不带id的话系统会自动赋予id (永远都是新增),带了id如果id存在就是更新
http://地址:9200/索引/类型/id
http://地址:9200/索引/类型/

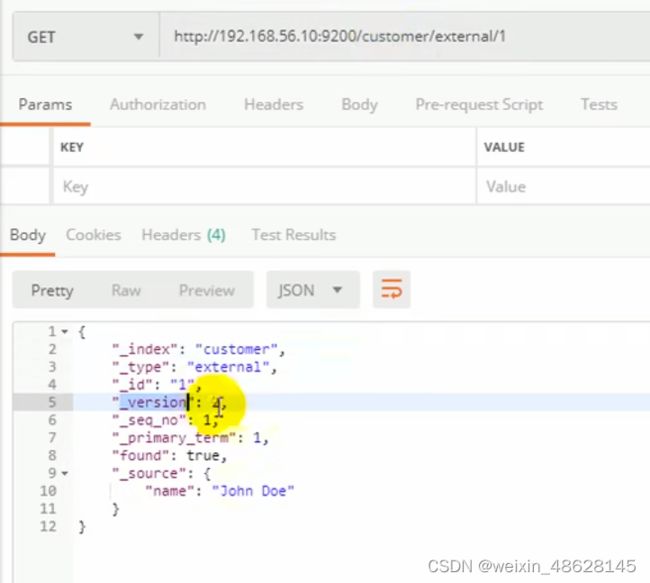
(3)get查询 http://地址:9200/索引/类型/id

(4) post带_update (数据要加一个"doc",如果数据跟原来的一样,则不会发生任何改变,版本号什么均不变)

(5)delect删除文档 http://地址:9200/索引/类型/id
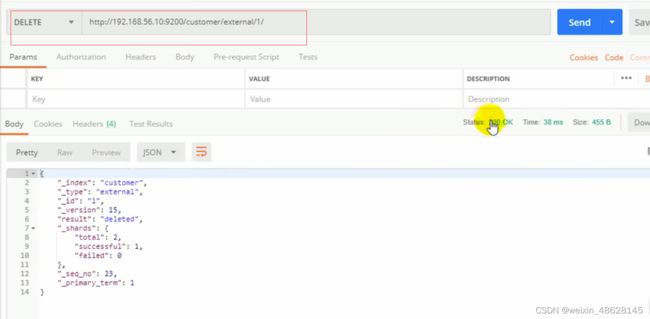
删除索引 http://地址:9200/索引 (没有删除类型,想要删除类型,就把类型下面的所有文档都删除)
(6) 批量增加数据 http://地址:9200/索引/类型/_bulk
要使用kibana操作,postman没法识别

批量操作(不指定索引跟类型,通过批量进行多种操作)
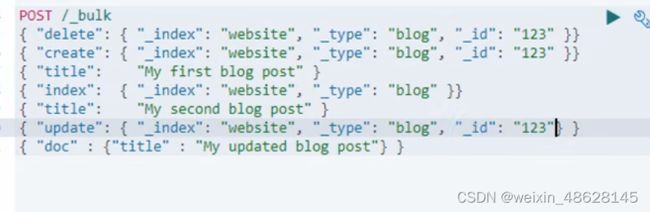
(7)检索
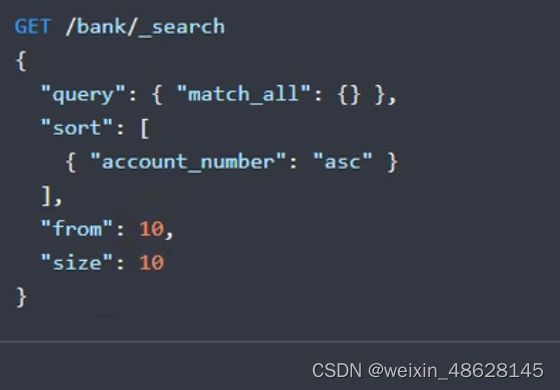
一、查询银行下索引所有的数据,按账号进行升序 _search
方式1(URI + 检索参数)

方式2 query DSL (uri + 请求体)
_search表示检索,query表示查询条件,sort表示排序条件

检索从10开始的10个数据
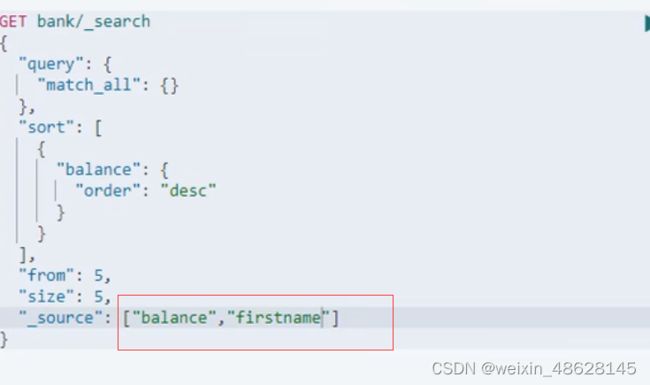
指定返回的属性(这样只会返回balance跟firstname 属性的内容 就像select balance, firstname...一样)
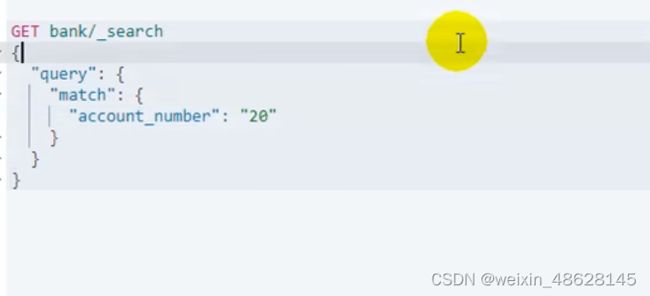
二、match查询 (就像mysql中 where account_number = 20),但是他使用的是倒排索引,只要包含内容,就都能检索到,有点像模糊查询,他会按评分进行排序(评分就是匹配度)
match查询多个词(只要匹配address中包含mill或 road都会被检索到)

match_phase匹配整个短语(这样,只有address包含mill lane才能被匹配)

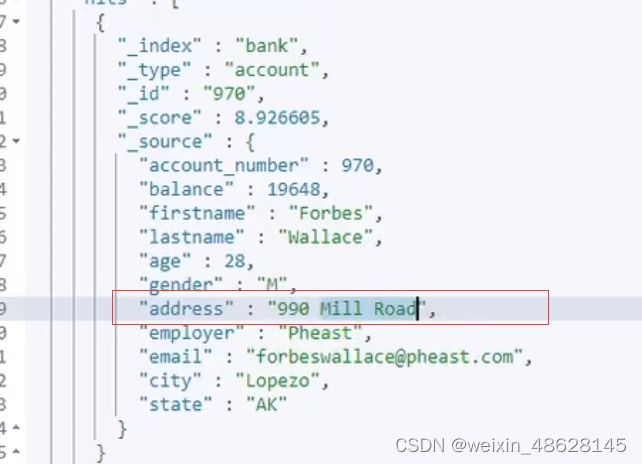
multi_match 只要属性address或city中包含mill就能被检索到

只要属性address或city中包含mill或movico就能被检索到

bool复合查询 must表示必须符合 (gender包含F,address包含mill)
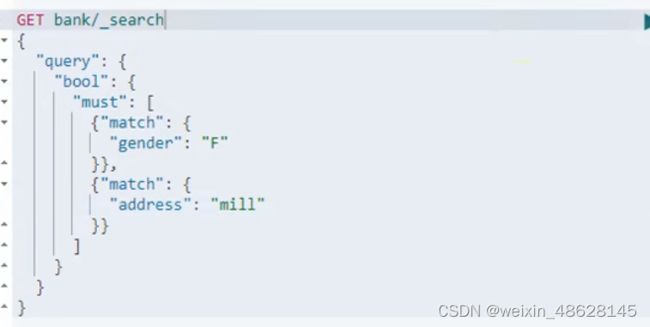
must_not必须不匹配(gender包含F,address包含mill,age不包含38)

should 应该,匹配上最好,匹配不上也可以 (匹配了得分更高)
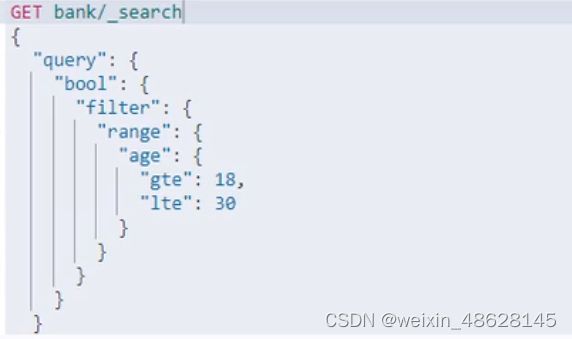
三、filter结果过滤(只会过滤,但没有记录得分,所有匹配数据的匹配得分都是0)
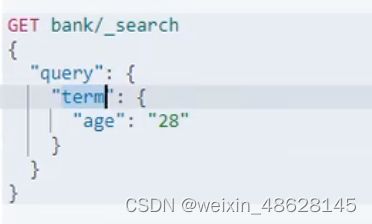
四、term 精确检索推荐使用term,全文检索使用match
非文本字段推荐使用trem查询(比如age这些)
这个也是精确匹配
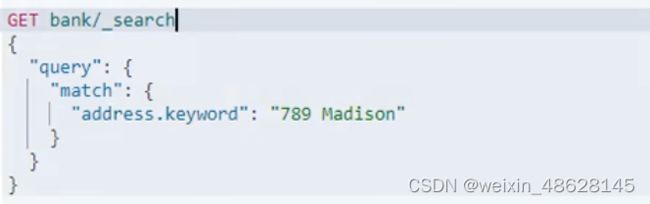
这是全文检索,但是adress必须包含有789 Madison

五、aggregations聚合(相当一 group by sum average等)
年龄的分布情况,最多提供10种


分布情况及年龄平均值


只看聚合结果不看记录size设置为0

按年龄聚合,并请求这些年龄段的这些人的平均薪资(在ageAgg里面进行子聚合即可)

聚合里面再聚合(年龄分布,统计好后的年龄分布中各年龄段的性别统计)

聚合里面再聚合然后再聚合(年龄分布,统计好后的年龄分布中各年龄段的性别统计,然后性别统计后再薪资统计)

六、映射mapping
指定数据的类型
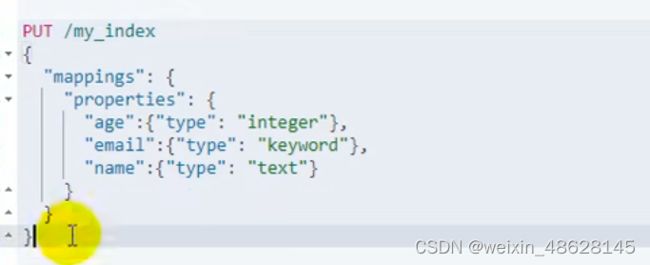
在索引下增加新字段 (inde默认是为true的,为false表示不能被索引)

在索引下更新字段(没法,只能把数据迁移到别的索引 get /老索引/_mapping 就能获取老的索引,然后复制到新的,并适当修改)
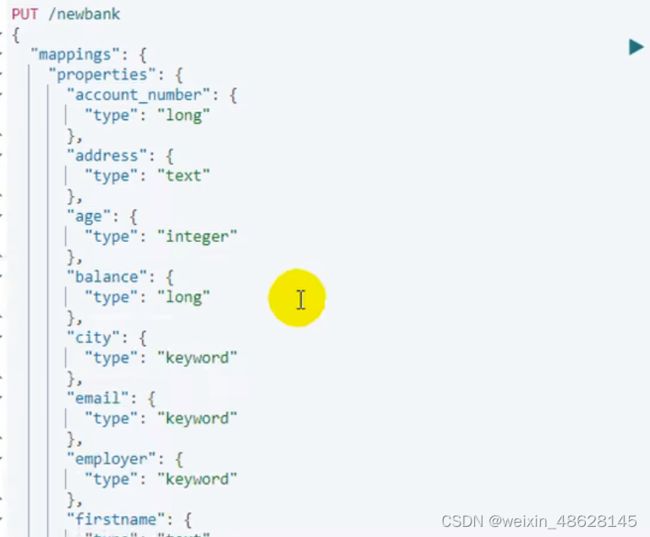
数据迁移_reindex(因为新版本的type类型已经要被去掉了,迁移bank索引下,account类型下的数据到索引newbank中,它的类型就统一变成_doc)

七、分词器(ik分词器,可适用中文,因为标准版的是只支持英文分词)
下载ik分词器到es的pluns中
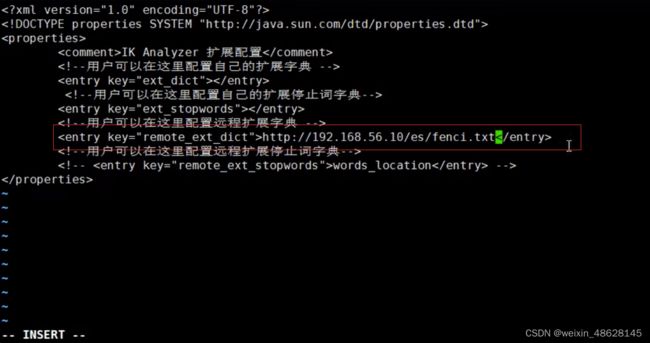
但是对于新的网络词汇,ik自身是识别不出来的,但是它可以进行外部词汇扩展,主要利用nginx去进行配置
在nginx的html目录下面增加一个es目录
在es目录下新增一个fenci.txt
在里面增加新词汇就行
然后再去ik分词器的config文件中下面这个文件

即可
三、SpringBoot和es整合
1、使用9300:TCP(一般不用,因为springboot版本不同,transport-api.jar不同,会出现不适配问题)
2、9200:http
(1)JestClient:非官方,更新慢
(2)RestTemplate:模拟发Http请求,es很多操作需要自己封装,麻烦
(3)HttpClient:同上
(4)Elasticsearch-Rest-Client(elasticsearch-rest-high-level-client) 用这个
3、使用
(1)创建新模块

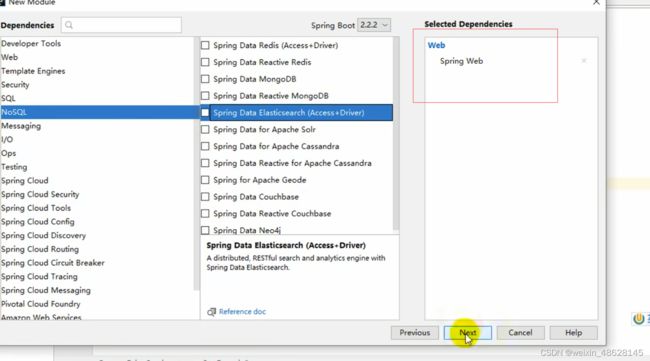
(2)导入maven
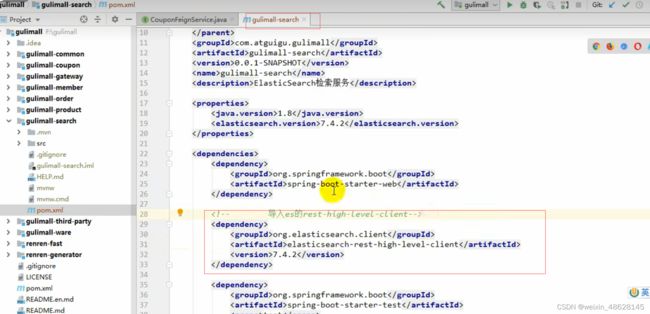
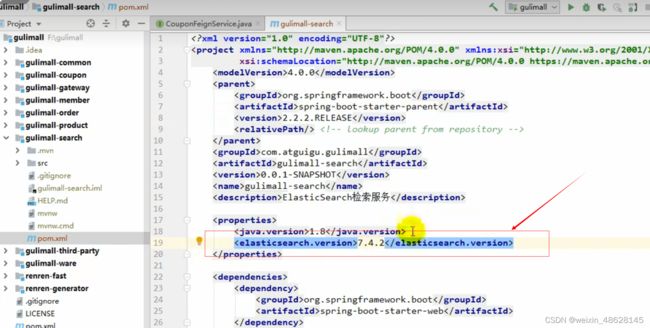
因为springboot默认版本是6.8.5所以要改成我们的版本7.4.2
(3)进行服务注册
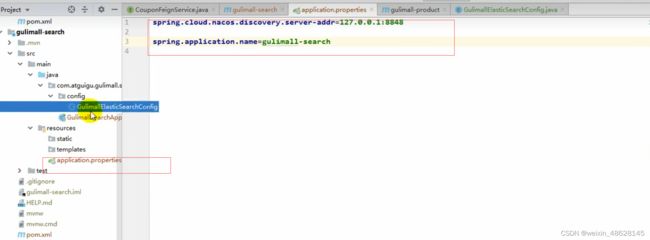

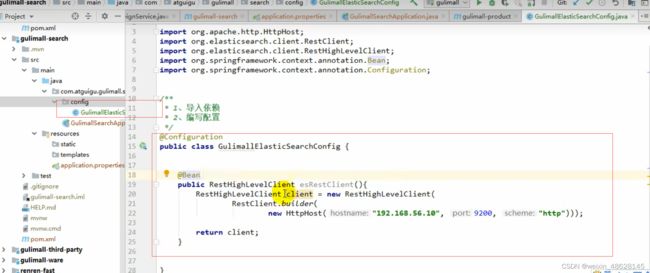
(4)配置文件,给容器注入一个RestHighLevelClient
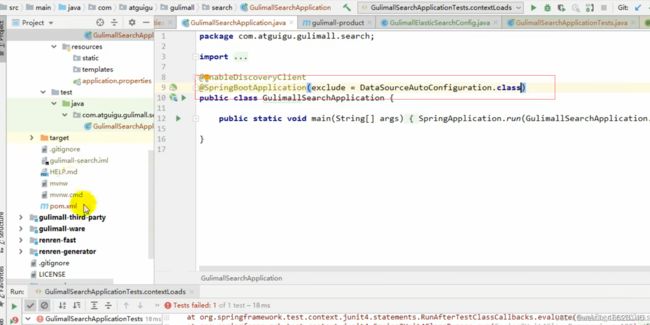
(5)进行单元测试
排除数据源
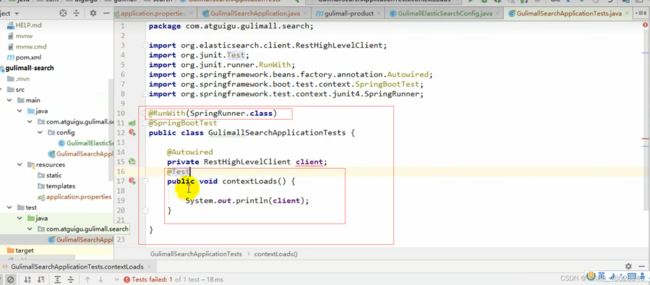

成功
(6)使用
通用的设置项

先设置index索引和id
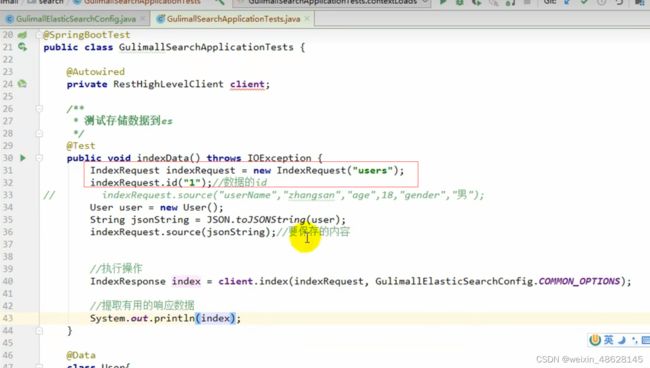
然后使用key-value或者json写入数据
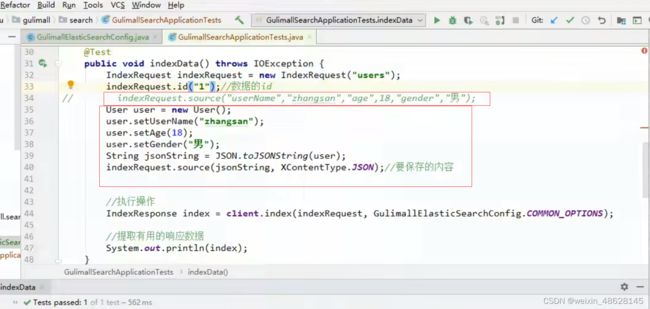
最后进行执行即可
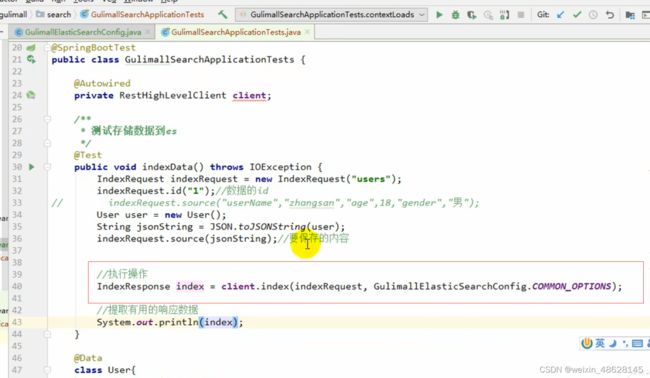
检索
1、创建索引请求
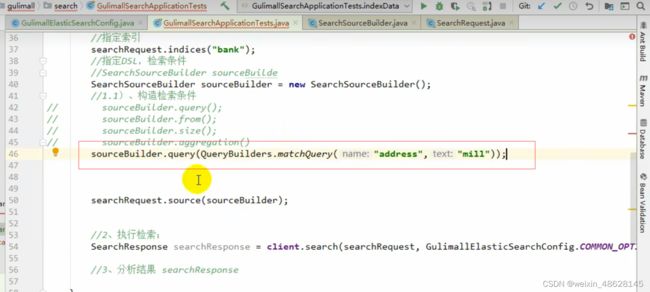
2、指定索引
3、指定DSL,检索条件
4、执行索引
5、分析结果

查询条件基本上跟DSL差不多,根据需要去写
两个单独的聚合并行
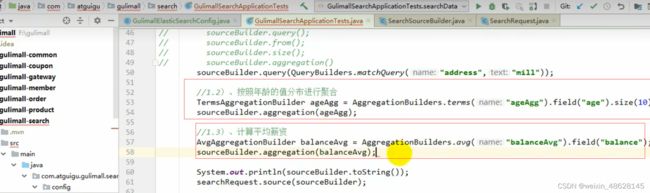
获取到检索到的每条数据
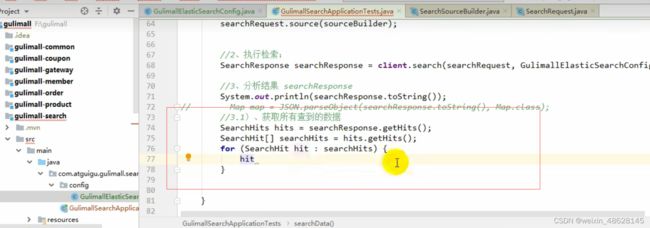
转换成对应的实体类
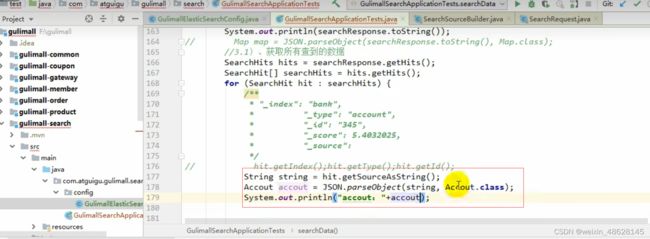
处理聚合的信息
应用
上架商品
商品id
spuid
商品标题
商品价格
商品图片(不能检索、不能聚合)
商品销量
商品库存
热度评分
品牌id
商品类别id
品牌名字
品牌图片
类别名字
属性规格类(规格id,规格名字,规格值)
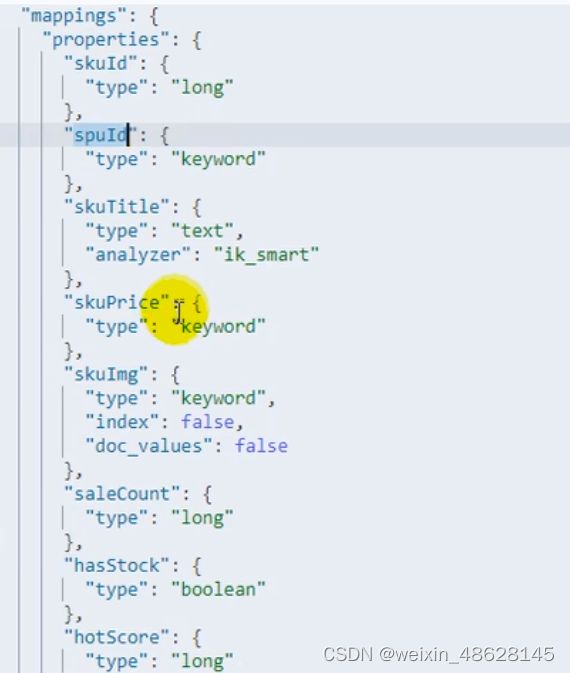


attrs是规格数组,要标为嵌入式的,不然检索会出现问题。