Python从入门到自闭(基础篇)
Python从入门到自闭(基础篇)
作者:日魔
Python的创始人吉多.范罗苏姆(Guido va Rossum)(外号:龟叔)
一. Python 的历史:
1. 1989年圣诞节的时候为了打发时间决定开发一款新的脚本解释程序。
- 199年第一个python编译器诞生,他是用C语言实现的并能调用C语言的库文件。
- 1994年Python_1.0诞生,添加了lambda,map,filter and reduce.
- 2000年Python_2.0诞生,添加了垃圾回收机制。
- 2004年python_2.4诞生,添加了著名的WEB框架Django.
二. Python 小知识
这里可能会让一些比较白的小白看的脑袋疼所以可以直接阅读下面的Python基础
1.首先我们来看看在不同角度编程语言的分类(这里只从三个角度进行分类):
-
按转换过程来分类
-
编译型: 就是你得到了一本外星人的书,需要一个外星翻译给你把整本书翻译成你能看懂的语言在给你。
代表语言:C,C++…
-
解释型:就是你得到了一本外星人的书,需要一个外星翻译坐在你身边你想翻译那段就给你翻译那段。
代表语言:Python,JavaScript,PHP…
-
混合型:上面两种的结合。
代表语言:Java,C#…
-
-
按运行时结构状态分类
- 动态语言:运行时代码可根据特殊情况进行改变自身结构。
- 代表语言:Python,JavaScript,PHP…
- 静态语言:运行时结构不可改变。
- 代表语言:C,Java,C++,C#…
- 动态语言:运行时代码可根据特殊情况进行改变自身结构。
-
按数据类型的监管分类
- 动态类型语言:在运行期间才去做数据类型检查的语言。
- 代表语言:Python,JavaScript,PHP…
- 静态类型语言:变异期间(或运行之前)确定的,编写代码时要明确变量的数据类型。
- 代表语言:C,C++,C#,Java…
- 动态类型语言:在运行期间才去做数据类型检查的语言。
2.看完编程语言的分类之后我们在来看看Python解释器的分类
- CPython:从官网上下载的解释器也是使用最广的解释器。
- IPython:基于CPython之上的交互式解释器。
- PyPy:另一种Python解释器,执行速度块,利用JIT技术对Python代码进行动态编译所以可以显著提高Python代码的执行速度。
- Jython:是运行在Java平台上的Python解释器,可以直接把Python代码编译成Java字节执行。
- IronPython:和Jython类似,不过他是运行在微软.Net平台上的Python解释器,可以直接把Python代码编译成.Net的字节码。
3.接下来我们来看看Python的优缺点
- Python的优点:
- “优雅”,“明确”,“简单”,虽然入门比较容易简单但将来进行深入学习时还是非常困难的!
- 开发效率非常高,拥有强大的第三方库。
- 可移植性,他开源的属性让他注定有着优秀的可移植性。
- 可扩展性,如果你需要代码运行的更快或希望某些算法不想被公开,你可以把你的部分大妈使用C或C++进行编写然后在Python程序中使用它们。
- 可嵌入性,你可以将Python嵌入你C或C++程序,从而向你的程序用户提供脚本功能。
- Python的缺点:
- 速度慢,他的运行速度相比C语言要慢很多
- 代码不能加密
- 进程不能利用多CPU问题
4.最后来初步认识一下编码和单位转换
ASCII 1字节 不支持中文
Unicode 中文和英文4字节
utf-8 英文1字节 欧洲2字节 亚洲3字节
14.
# 单位转换:
# 1字节 == 8位
# 1B = 8b
# 1KB = 1024B
# 1MB = 1024KB
# 1GB = 1023MB
# 1TB = 1024GB
# 1PB = 1024TB
# 1EB = 1024PB
三.挑战第一关 _Python_之基础知识
1.变量
**变量:**一个存放东西的空间
1.声明变量
Name = "苍空井"
Name是你自己定的变量名,"苍空井"就是数据,=(赋值运算符)就是将等号右边的确定数据交给左边的变量
这是我们的第一段代码,他的意思简单点说就是给"苍空井"这条数据取名叫Name
要是复杂说的话就是在内存里声明一个名为Name的变量名,再将“苍空井”这条数据通过某种联系进行连接,达到存放东西的效果。
下面这个图片是这条代码在内存中的实现过程
[外链图片转存失败(img-wTnrpCiz-1565428895732)(D:\LNH_zuo_ye\Sketch002.jpg)]
2.变量声明规则
-
变量名只能由字母,数字,下划线进行组合
-
变量名不能以数字开头
-
变量名最好能见名知意
-
变量唯一每个变量只能连接一条条数据
-
这些内部关键字不能作为变量名
[‘continue’, ‘def’, ‘del’, ‘elif’, ‘else’, ‘except’, ‘exec’, ‘finally’, ‘for’, ‘from’, ‘global’, ‘if’, ‘import’, ‘in’, ‘is’, ‘lambda’, ‘not’, ‘or’, ‘pass’, ‘print’, ‘raise’, ‘return’, ‘try’, ‘while’, ‘with’, ‘yield’]
3.推荐的声明方法
#驼峰
CangJingKong = "你好"
#下划线
cang_jing_kong = "你好"
这样做会显得很专业这很重要!
2.常量
一般不变的数据称之为常量
其实在Python没有常量这一说
但是大家有个规定就是变量名全大写的变量为常量
NAME = 12054
类似于这样的写法
3.基础数据类型
-
int(整形):就是数字
a = 6 -
bool(布尔型):True = 1,False = 0,后期用于判断的必要参数
整形转布尔型只要不是0都是True(0为False)
字符串转布尔型只要字符串内部有元素就为True(否则为False)
a = True b = False -
ste(字符串):就是一个存储数据的区域,字符串是不能被修改且有序的(后面会重点讲述)
[外链图片转存失败(img-YKl53d5B-1565428895735)(C:\Users\Lenovo\Pictures\Screenshots\屏幕截图(40)].png)
a = "a" a = 'a' #和双引号一样 a = "我想打个引号'所以只能这样打出来'" #要是想在字符串内打出字符串就需要用到双引号和单引号的组合运用 a = """ a """ #这种输出的数据是可以带格式的 -
list(列表):是由一系列特定元素顺序排列组成的,其元素也可以修改的(后面会详细讲解)
a = [] -
tuple(元祖)元祖和列表相似但不可修改(后面会详细讲解)
a = () -
dict(字典):是由一组组无序的键值对组成的(后面会详细讲解)
a = {} -
set(集合):有些饶人前器理解会比较困难到后面会有详细讲解
在在这个阶段我们只需要了解这些类型就够了
4.用户交互
最常见的用户交互就是用户登陆
让我们先看看他在Python内部怎么表示
输入语句:
a = input("填写用户可视化信息")
- a是变量名
- =是赋值运算符
- input()是输入语句,但这条语句只负责将用户输入的信息记录并且类型为"str"类型
- ""内部放的是用户可以看见的提示信息
输出语句:
print("作者真的帅")
- print就是我们的输出语句
- "作者真的帅"是一段字符串也就是咱们之前说的str
- 他的作用就是将"作者真的帅"输出到屏幕上
下面是一个小例子,他实现的功能是获取用户名和密码并输出到屏幕上
[外链图片转存失败(img-K7gfoGMt-1565428895736)(C:\Users\Lenovo\Pictures\Screenshots\屏幕截图(34)].png)
5.运算符
运算符分类:
-
算数运算符:+ (加),- (减),* (乘),/ (除),// (整除),** (幂),% (取模)
-
比较(关系)运算符:== (等于),!= (不等于),< (小于),> (大于),<= (小于等于),>= (大于等于),
-
赋值运算符:= (正常的赋值运算符)
-
逻辑运算符:and (与),or (或),not (非)
and 1 and 10 如果两边都是真就输出右边的数 False and 0 如两边都是假的话就输出左边的数 10 and False 如果一真一假就输出假的那边数 or 1 or 10 如果两边都是真就输出左边的数 False or 0 如两边都是假的话就输出右边的数 10 or False 如果一真一假就输出真的那边数 not 取反真的变假的 假的变真的 not 1 就变成0 not False 就变成True -
位运算符:& (按位与运算符),| (按位或运算符),^ (按位异或运算符),~ (按位取反运算符),<< (左移动运算符),
>> (右移动运算符)(后面会详细讲解)
-
成员运算符:in (如果在制定序列内找到值就返回True,否的返回False),not in (和in得到的相反)
-
身份运算符:is (判断两个表示符是否引用自同一对象,类似id(a)==id(b),若是同一个对象返回True否则返
回False)
is not(和is得到的结果相反)(后期会详细讲解)
6.格式化输出
这里主要讲的就是占位符的使用,占位符的作用肯定是用来占位的啦!
#首先我们先来他们的样子
首先我们来输出一个名片(因为涉及到格式所以我们使用"""三引号的写法""")
print("""
-----名片------
姓名:日魔
电话:12345
--------------
""")
这样是不是像点样子了,但是我们总不能来一个人重新写一个这样的名片吧,那样就显得太过麻烦了。
这个时候就该使用我们的占位符啦
1.第一种占位方式:%s(str字符型占位符,只能补位字符串)%d或%i(int 整形占位符,只能补位整形)
在引号后面加%()进行补位记得一定要按顺序补位,如果你想在内部写%那就要打%%
print("""
-----名片------
姓名:%s
电话:%s
--------------
"""%(input("姓名"),input("电话"))
这样写就可以往这个字符串内部输入不同的数据了
2.用f和{}进行补位不过只有在3.5以后版本才能使用,
print(f"""
-----名片------
姓名:{input(">>")}
电话:{input(">>")}
--------------
""")
f是用来声明占位用的,{}里面的内容是用来补位用的。
7.字符串(str)
这里我们来详细讲解一下字符串的一些特点和用法
首先前面我们已经介绍了字符串是一组有序不可不可变的元素
接下来再让我们看看他的一些特性
-
索引
字符串中的每一个字符都有一个编号,就像我们身份证号码一样,因为名字可能出现重复但身份证号码是唯一的。 a = "abc" 0,1,2 -3,-2,-1 就像上面的字符串分别是a的下标从左到右排为0,从右向左排序为-3 -
切片
切片就是利用索引对字符串进行控制,切片有个特性就是顾头不顾尾 a = "abc" 想输出b就像下面一样写 i = a[1] 也可以 i = a[-2] 想输出a后面的值可以像下面一样写 i = a{0:} -
步长
步长就是每次输出所跨越的长度或方向 a = "absdfac" 想输出c前面的值可以像下面一样写 i = a[-1::-1] 也可以 i = a[::-1] 想输出a,b,c可以像下面一样写 i = a[::3] 想输出c,b,a可以像下面一样写 i = a[::-3]
之后我们来简答介绍一下字符串的常用方法
a = "abcdefg"
.upper() #将字符串内部所有小写变成大写
print(a.upper())
.lower() #将字符串内部所有大写变成小写
print(a.lower())
.startswith(“”,开始的索引,结束的索引) #判断开头是否为括号内的字符
print(a.startswith("a"))
.endswith(“”,开始的索引,结束的索引) #判断结尾是否为括号内的字符
print(a.endswith("g"))
.count("") #字符内有多少个方法括号内的字符
print(a.count("a"))
.strip() #删掉字符串的首尾空格,要是方法括号内部有字符就删掉首尾方法括号内的字符
print(a.strip())
split() #分割
.replace("被替换的字符","替换成的字符") #进行替换括号内第一个字符和第二个字符
print(a.replace("a","b"))
.find(要查找的元素)
print(a.find("a")) #查找元素人如果没找到返回-1
分隔符.join("被分割字符串")
print(".".join(a)) #用·左边的字符串去分割右边join内部的字符串或列表但必须都是字符串类型
.isdigit() #判断是不是阿拉伯数字
.isdecimal #判断是不是十进制
.isalnum #判断是不是字母数字汉字
.isalpha #判断是不是字母汉字
最后我们在介绍一些虽然不会经常介绍但也需要了解的一些方法
1.扩展方法
a = "abc_dem"
print(a.capitalize()) #将首字母大写
print(a.title()) # 将开头字母大写空格文字特殊符号等都能起到分割的作用
print(a.swapcase()) # 大写变小写小写变大写
print(a.center(20,"*")) # 居中,填充用逗号右边字符串进行填充一共算上要居中的字符串需要逗号左边的的 空间
print(a.index("a")) #查找元素如果没找到就会报错
2.字符串做加法和乘法
print(a + a) # 新开辟一个空间存放两个字符串的拼接
# 结果 "abc_demabc_dem"
print(a * 5) # 开辟一个新的空间存放这个字符串相乘五回的结果
# 结果"abc_demabc_demabc_demabc_demabc_dem"
# 字符串做加乘运算都是开辟的新空间
8.列表(list)
列表是一个可变有序的容器,他可以存储大部分的数据类型,他内部存储的元素分别是一个个的地址。
1.他也有和字符串很像的操作就是
索引
a = [1,"2",[3]]
0, 1, 2 #从左到右索引
-3, -2, -1 #从右向左索引
切片
a[起始值:中止值]
a[::] #从左到右输出整个列表
步长
a[起始值:中止值:步长]
a[::-1] #从右向左输出整个列表
2.接下来我们来看看列表的方法
a = [1,2,3]
增
a.append() #追加
a.insert() #插入
a.extend() #迭代添加
删
a.pop() #弹出式删除
a.remove() #按元素删除
a.clear() #清空列表
del a #删除整个列表
改
(可用切片的形式进行修改)
a[0] = 4
a.sort() #排序(默认升序)
a.sort(reverse=True) #降序
a.reverse() #将数据反转
查
print(a[0])
print(a.index(数据)) # 查询数据的索引如果查不到会报错
在最后我们也来看看列表有那些需要了解的方法
小功能
1.人工降序
a = [1,2,3,4]
a.sort() #先降序
a.reverse() #在反转
print(a)
2.不改变数据源进行反转
a = [1,2,3,4]
b = a[::-1]
print(b)
3.列表进行加减法
# lst = [1,2,3,4]
# lst = lst + [1,2,3]
# print(lst)
#结果[1,2,3,4,1,2,3]
# lst = [1,2,3] * 5
# print(lst)
# print(id(lst[0]),id(lst[3]))
# 结果[1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3]
1412983840 1412983840
9.元祖(tuple)
元祖可以简单理解成不可变的列表
元祖加法乘法
# tu = (12,3,4) + (4,5,3,4)
# print(tu)
结果:(12, 3, 4, 4, 5, 3, 4)
# tu = (1,[]) * 3
# print(tu)
# tu[-1].append(10)
# print(tu)
结果:(1, [], 1, [], 1, [])
(1, [10], 1, [10], 1, [10])
10.字典(dict)
字典应该是我们以后最常用的一个数据类型
一.让我们先看下这个小东西长成什么样子
变量名 = {键:值}
1.字典是一个无序可变可迭代的数据类型,他的存储方式为哈希列表存储一般在别的语言内这个东西叫键值对在 Python叫做字典
2.他的键只能为不可变可哈希的值 (key)
3.他的值可以随便放 (valuse)
二.咱们先看下他的相关操作
增
1.首先是暴力添加:字典名[键]=[值] #如果字典内部有这个键就将他的值进行更改,要是没有则进行添加
2.然后是温柔添加:字典名.setdefault(键,值) #如果字典内部有这个键就返回他的值,要是没有则进行添加
删
1.删除和列表一些类似
2.弹出时删除:字典名.pop(键) #有返回值效果和列表的相似将键和他的值进行删除
3.彻底删除:del 字典名 #全部删除
4.彻底删除2:del 字典名[键] #将键和他的值进行删除
5.清空整个字典:字典名.clear() #将列表删除
改
1首先是暴力修改:字典名[键]=[值] #如果字典内部有这个键就将他的值进行更改,要是没有则进行添加
2.合并字典修改:主字典名.update(辅字典名) #将主字典内没有的键值对添加到主字典内部
查
1.没错还是setdefault():字典名.setdefault(键) #如果只是写一个键这个方法就会返回这个键的值,要 是招不到键就返回None
2.get()纯查找:字典名.get(键) #查找键要是找到了返回值要是没找到返回Noeo
3.keys()查询所有键:字典名.keys() #返回这个字典的所有key(键)
4.valuses()查询所有值:字典名.valuses() #返回这个字典所有valuse(值)
5.items()查询所有键,值:变量1,变量2 = 字典名.items() #这个比较特殊需要两个变量接收第一个变量接受 键第二个变量接受值
三.他和for的结合
1.for i in 字典名 #将字典所有的键循环一遍
for i in 字典名.keys()
2.for i in 字典名.valuses() #将字典所有有值循环一遍
3.for i,j in 字典名.items() #将字典的所有键和值都循环一边,前面需要两个变量接收
四.字典嵌套
a = {"作者":{"长相":"太帅了","身材":"太棒了"}}
print(a["作者"]["长相"])
这样我们就能拿到"太帅了"
五.字典的其他方法
# dic = {"key":1,"key1":2,"key2":4,"key3":1}
# print(dic.popitem()) # 随机删除 python3.6版删除最后一个键值对
# popitem返回的是被删除的键值对
# print(dic)
# dic = {}
# dic.fromkeys("abc",[]) # 批量创建键值对 "a":[],"b":[],"c":[]
# print(dic)
# fromkeys 第一个参数必须是可迭代对象,会将可迭代对象进行迭代,成为字典的键.第二个参数是值(这个值是共用的)
# fromkeys 共用的值是可变数据类型就会有坑,不可变数据类型就没事
11.集合(set)
是一个天生自带去重可变无序的数据类型,可以将他理解成字典里没有值的键
让我们来看看他的样子
a = {1,2,"3",("4","5")}
是不是和我们的字典长得特别的相似呀
一.既然是可便的那一定就有我们的:
1.增
集合名.add()
2.删
集合名.remove(想删除的数据)
集合名.pop() #随机删除
变量名.clear()
3.改
先删后改
4.查
for循环进行查找
二.特殊操作
# s = {1,23,9,4,5,7}
# s1 = {1,2,3,4,5}
#差集 "-"
print(s - s1) #将父级集合中和子级集合重复的元素进行删除然后返回剩下的数据
(s是父级集合,s1是子级集合)
#交集 "&"
print(s & s1) #将父级集合中和子级集合重复的数据返回
(s是父级集合,s1是子级集合)
#并集 "|"
print(s | s1) #将父级集合和子集集合中的元素进行合并然后去重复
(s是父级集合,s1是子级集合)
#反交集 "^"
print(s ^ s1) #将不重复的值合并在一起并返回
(s是父级集合,s1是子级集合)
#父级子集
#大于号右边是否为子集 返回一个布尔值
print(父级 > 子集)
#小于号右边是否为父级 返回一个布尔值 #父级要完全拥有子集的所有内容
print(子集 < 父级)
12.基础数据类型整理
# 可变,不可变,有序,无序
# 1.可变:
# list
# dict
# set
# 2.不可变:
# int
# str
# bool
# tuple
# 3.有序:
# list
# tuple
# str
# 4.无序:
# dict
# set
# 取值方式:
# 1.索引
# list
# tuple
# str
#
# 2.键
# dict
#
# 3.直接
# int
# bool
# set
# 数据类型转换
# str -- int
# int -- str
# str -- bool
# bool -- str
# int -- bool
# bool -- int
# list -- tuple
# lst = [1,23,5,4]
# print(tuple(lst))
# tuple -- list
# tu = (1,23,5,4)
# print(list(tu))
# list -- set
# lst = [1,23,12,31,23]
# print(set(lst))
# set -- list
# tuple -- set
# tu = (1,2,3,4,5)
# print(set(tu))
# set -- tuple
# 重要: *****
将列表转为字符串
# list -- str
# lst = ["1","2","3"]
# print("".join(lst))
将字符串转换为字典
# s = "alex wusir 日魔"
# print(s.split())
# 目前字典转换,自己实现方法
13.Boss 程序控制语句 ____分支结构____if
学到现在总算是遇到了一个小怪物头目
让我们先来看看他的真面目
#第一种
if 1 < 2:
print("1小于2")
#第二种
if 1 < 2:
print("1小于2")
else:
print("1不小于2")
#第三种
if 1 < 2:
print("1小于2")
elif 1 > 2:
print("1大于2")
我先来介绍一下他们
- if你可以给他理解成”如果“,后面的双引号是固定格式。
- else你可以给他理解成"否则",后面的双引号是固定格式。
- elif你可以理解成"否则如果",后面的双引号是固定格式。
- print是输出的意思,这是我们之前讲过的。
然后我们在来看看他们,是不是感觉舒服多了,但这个只能作为理解不能真正的运行出来
#第一种
如果 1 < 2:
输出("1小于2")
#第二种
如果 1 < 2:
输出("1小于2")
否则:
输出("1不小于2")
#第三种
如果 1 < 2:
输出("1小于2")
否则如果 1 > 2:
输出("1大于2")
下面是他们真正运行后的结果
[外链图片转存失败(img-h2zNgaaa-1565428895742)(C:\Users\Lenovo\Pictures\Screenshots\屏幕截图(36)].png)
14.Boss 程序控制语句 ____循环结构____while
如果你成功的通过了"if"考验那么证明你已经超过了百分之20的人,坚持住你已经很棒了!
老规矩首先让我们看一下这个while长成什么样子
#第一种正常的while
while "循环判断语句":
print("循环体(如果判断语句一直成功且不遇到break(强制结束循环语句)就不会结束这个循环,并且会一直循环 循环体内部的指令)")
#加else的while语句
while "循环判断语句":
print("循环体(如果判断语句一直成功且不遇到break(强制结束循环语句)就不会结束这个循环,并且会一直循环 循环体内部的指令)")
else:
print("如果循环判断语句失败了就执行这条语句(这条语句只会执行一回不会像循环体一样一直循环)")
你可以将while语句也当成如果,下面用好理解的方式去书写一下
#第一种正常的while
如果 循环判断语句 :(格式)
(别忘了这里前面有四个空格或者一个Tab)
(循环判断语句成功后执行的循环体)
#加else的while语句
如果 循环判断语句 :(格式)
(别忘了这里前面有四个空格或者一个Tab)
(循环判断语句成功后执行的循环体)
否则:(格式)
(别忘了这里前面有四个空格或者一个Tab)
(循环判断语句失败后执行的循环体)
好啦这下应该理解的差不多了吧差不多了吧
#接下来我们来介绍一下
break和continue这俩兄弟
break:强制退出循环
continue:强制跳出本次循环,伪装成最后一条语句,不执行本次循环continue后面的循环体
下面是小例子
第一个while是运用break控制循环体输出一会循环体
第二个while是输出1到3不输出2
[外链图片转存失败(img-gtGaYKQB-1565428895746)(C:\Users\Lenovo\Pictures\Screenshots\屏幕截图(42)].png)
15.Boss 程序控制语句 ____循环结构____for
for循环应该是我们这一阶段最后一个Boss了,加油胜利就在眼前
让我们先来看看他的结构
a = "abc"
for i in a:
print(i)
他的结果为循环三次每次输出字符串内的一个元素从左到右
这里介绍一下我们的占位符
for in in a:
pass
占位符pass可以用来占位,以便后期添加各种功能.
这里在介绍一下一个迭代方法range
下面是输出从零到4
for i in range(0,5):
print(i)
下面是第二种写法
for i in range(5)
print(i)
16.驻留机制
驻留机制: 节省内存空间,提升效率(减少了开辟空间和销毁空间的耗时)
先执行代码块规则在执行小数据池规则
首先咱们先来看下两个规则
- 代码块()
- 数字
- 在通一代码块下 摘要内容相同就采用相同的内存地址(范围是-5到正无穷)
- 数字在做乘法的时候范围-5~256‘
- 数字在做乘法的时候不能使用浮点数
- 字符串
- 在同一代码块下 只要内容相同就采用相同的内存地址
- 字符串(字母,数字)进行乘法时总长度不超过20
- 特殊符号(中文符号)进行乘法的时候诚意0,1
- 布尔值
- 在同一代码块下 只要内容相同就采用相同的内存地址
- 数字
- 小数据池子
- 数字
- -5~256所有相同数字使用同一块内存地址
- 字符串
- 在同一代码块下 只要内容相同就采用相同的内存地址
- 字符串(字母,数字)进行乘法时总长度不超过20
- 特殊符号(中文符号)进行乘法的时候诚意0
- 布尔值
- 在同一代码块下 只要内容相同就采用相同的内存地址
- 数字
17.浅度拷贝,深度拷贝
这个地方会比较绕脑子
1.”=“操作
首先我们来看下”=“在内存中做了什么
a = [10,20,[30,40]]
b = a

(没错咱们的”=“操作是让a,b两个变量都指向了咱们列表的地址)
2.浅度拷贝
a = [10,20,[30,40]]
b = a.copy()
下面是他在内存内部的操作
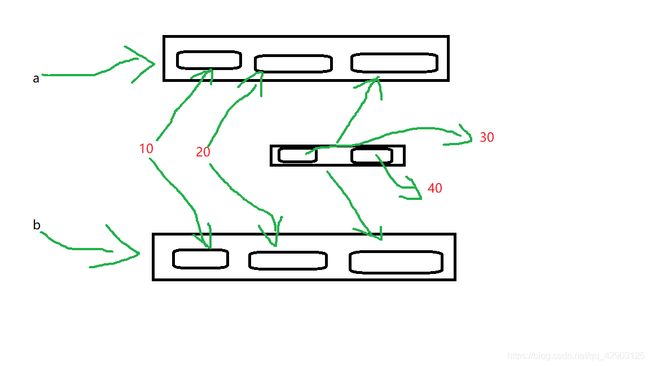
(相信你一定发现b里存放着新开辟的一个列表地址,但是不管是b指向的列表还是a指向的列表,他们列表内部存放的元素还是指向了一样的内存地址,所以对可变数据进行相关操作会让两个列表都改动)
a = [10,20,[30,40]]
b = a.copy()
a[0]=100
print(a,b)
结果就会是
[100,20,[30,40]],[10,20,[30,40]]
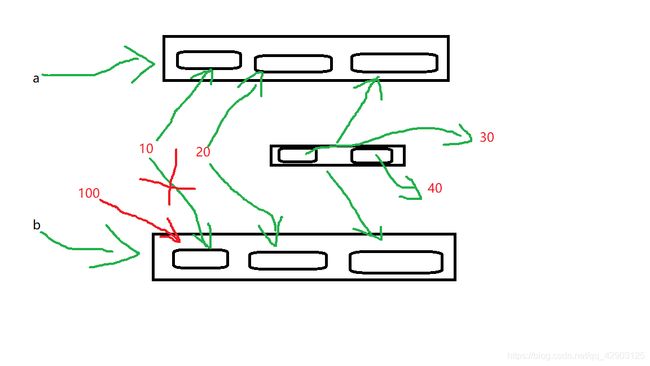
要是对内部的可变元素进行操作的话咱们来看看会是什么样子
a = [10,20,[30,40]]
b = a.copy()
a[2][1]=100
print(a,b)
结果就会是
[10,20,[30,100]],[10,20,[30,100]]

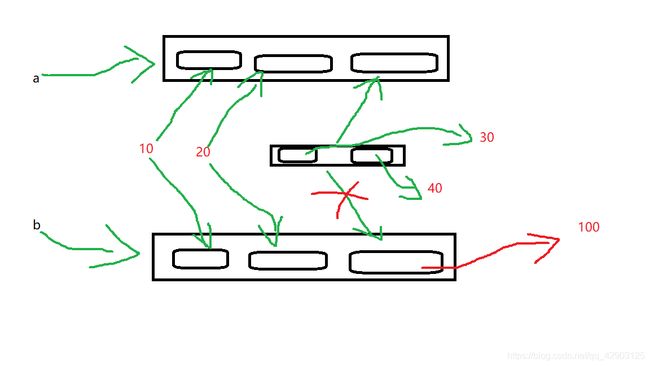
但是咱们只是对这个内部列表的地址进行操作,所以两边都会改变但我们要是对这个列表地址本身做手脚那就不一样了
a = [10,20,[30,40]]
b = a.copy()
a[2]=100
print(a,b)
结果就会是
[10,20,100],[10,20,[30,40]]
3.深度拷贝
深度拷贝就是只要遇见可变类型就将他拷贝
下面就是深度拷贝的操作
import copy #调用copy包
a = [10,20,[30,40]]
b = copy.deepcopy(a)
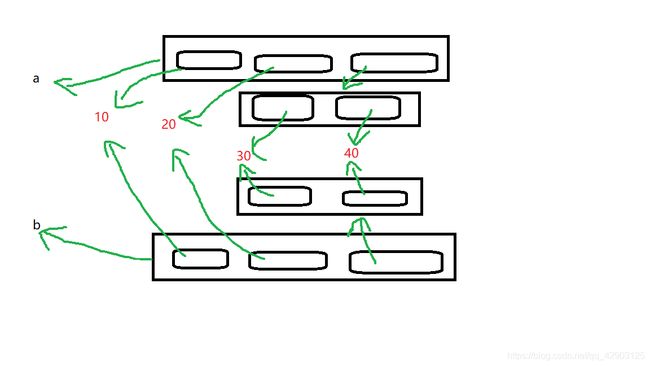
(没错就是遇到可变类型就新建一个同样格式不同地址的新可便类型但里面存放的不可变类型还是共用地址)
下面咱们先来修改一下不可变元素
import copy #调用copy包
a = [10,20,[30,40]]
b = copy.deepcopy(a)
a[0]=100
print(a,b)
[100,20,[30,40]],[10,20,[30,40]]
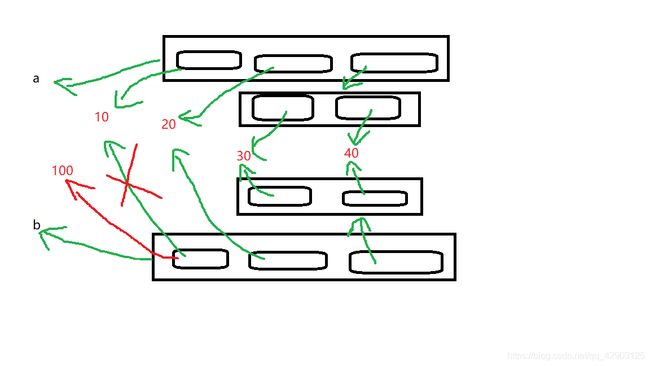
(对于不可变元素的内存操作深度拷贝和浅度拷贝是差不多的)
咱们再来看一下深度拷贝对列表内部可变元素进行操作会发生什么
import copy #调用copy包
a = [10,20,[30,40]]
b = copy.deepcopy(a)
a[2][1]=100
print(a,b)
[10,20,[30,100]],[10,20,[30,40]]
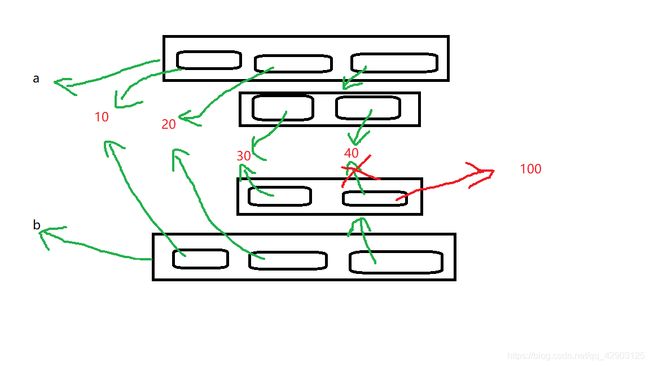
(没错这回只有a自己有所变动,这就是深度拷贝和浅度拷贝最大的区别,只要遇到可变数据类型就会进行一次浅度拷贝,从而实现真正分离)
18.编码解码(初体验)
后期我们会深度讲现在秩序知道
字符串.encode(“utf-8”) #编码
字符串.decode("utf-8") #解码
然后在记住一句话用什么编的码就用什么解这个码
(Python2使用的是ASCII)
(Python3使用的是Unicode)
19.文件操作
步骤讲解:
1.open #打开文件
2.file #文件位置
3.mode #操作方法,默认不屑就是r
4.encoding #文件编码
f = open("绝对路径/相对路径","操作方法","文件编码") #f是句柄
操作方法:
1.r(读)
a = open("绝对路径/相对路径","r","utf-8")
a.read() #输出全部
a.read(3) #按照字符去找
a.readline() #输出一行并在后面加上\n
a.readlines() #将每一行都放入列表内
rb(字节读)
f = open("timg.jpg",mode="rb")
print(f.read()) # 全部读取
print(f.read(3)) # 按照字节读取
print(f.readline()) # 按照行进行读取
print(f.readlines())
r和 rb的区别:
1.r需要指定encoding,rb不需要
2.r模式中的read(3) 按照字符读取, rb模式中的read(3) 按照字节读取
面试题:
read 和 readlines 如果文件较大时,会出现内存溢出
解决方案:
当文件交大时,使用for循环进行读取
f = open('t1',mode="r",encoding="utf-8")
for i in f:
print(i.strip())
2.w(清空文件后添加)
1.先清空文件(打开文件时清空)
2.写入内容
a = open("绝对路径/相对路径","w","utf-8")
a.write("要输入的内容只能是字符串") #必须填写字符串
wb(清空文件在添加,写的是字节) #可以将图片音频等转换为字符串
f = open('timg.jpg',mode="rb")
f1 = open("g1.jpg",mode="wb")
content = f.read()
f1.write(content)
3.a(只能在文件内容的最后添加)
a = open("绝对路径/相对路径","a","utf-8")
a.wrote()
ab(只能在文件内容的最后添加,字节)
a = open("绝对路径/相对路径","ab","utf-8")
接下来还有一些不常用的方法
# r+ 读写 (有点用) ****
# 坑 -- 使用方式是错误
# f = open("b1",mode="r+",encoding="utf-8")
# f.write("今天是周一")
# print(f.read())
# 正确的操作:
# f = open("b1",mode="r+",encoding="utf-8")
# print(f.read())
# f.write("今天是周一")
# w+ 写读 (有点用)
# f = open("b1",mode="w+",encoding="utf-8")
# f.write("今天是周一")
# f.seek(0) # 移动光标
# print(f.read())
# f = open("b1",mode="w+",encoding="utf-8")
# f.write("今天是周一")
# f.seek(0) # 移动光标
# f.write("啊啊啊啊啊啊")
# f.seek(0)
# print(f.read())
# a+ 追加读 # 坑
# f = open("b1",mode="a+",encoding="utf-8")
# f.write("今天是周一")
# f.seek(0) # 移动光标
# f.write("啊啊啊啊")
# print(f.read())
# 其他操作:
# seek() 移动光标
# f.seek(0,0) # 移动光标到文件的头部
# f.seek(0,1) # 移动光标到当前位置
# f.seek(0,2) # 移动光标到文件末尾
# f.seek(6) # 光标是按照字节移动
# f = open("a1","r",encoding="utf-8")
# print(f.read(5))
# f.seek(0,0) # 移动光标到文件的头部
# f.seek(0,1) # 移动光标到当前位置
# f.seek(0,2) # 移动光标到文件末尾
# print(f.read())
# f = open("c1","r",encoding="gbk")
# f.seek(6) # 光标是按照字节移动
# print(f.read(3))
# 查看光标:
# tell 查光标
# f = open("c1","r",encoding="gbk")
# print(f.read(3))
# print(f.tell()) # 按照字节进行计算
# 修改文件:
# import os # 操作系统交互的接口
#
# f = open('a2',"r",encoding="utf-8")
# f1 = open("a1","w",encoding="utf-8")
# for i in f:
# i = i.replace("日","天")
# f1.write(i)
#
# f.close()
# f1.close()
# os.remove("a2") # 删除不能找回
# os.rename("a1","a2")
# import os # 操作系统交互的接口
# f = open('a2',"r",encoding="utf-8")
# f1 = open("a1","w",encoding="utf-8")
# for i in f:
# i = i.replace("天","日")
# f1.write(i)
#
# f.close()
# f1.close()
# os.rename("a2","a3")
# os.rename("a1","a2")
# 考点:
# import os # 操作系统交互的接口
# f = open('a2',"r",encoding="utf-8")
# f1 = open("a1","w",encoding="utf-8")
# i = f1.read().replace("天","日") # 将文件中全部内容读取 容易导致内存溢出
# f1.write(i)
#
# f.close()
# f1.close()
# os.rename("a2","a3")
# os.rename("a1","a2")
# with open("a3","r",encoding="utf-8")as f,\
# open('a2',"r",encoding="utf-8")as f1:
# print(f.read())
# print(f1.read())
# 1.自动关闭文件
# 2.同一时间操作多个文件
# 文件操作的目的:
# 1.持久化: 永久存储
万恶之源——函数
函数就是你的英雄主动技能,你可以创作他但不会有任何效果,除非你去使用它
1.下面就是我们创建的函数,但要记住如果我们不去使用它那么他也只会声明出来放在那里没有用
def 函数名(形参):
函数体
2.函数的返回值,返回给函数的调用者
# return 值 == 返回值
# return:
# 1.可以返回任意类型数据
# 2.return 返回多个内容是元组的形式
# 3.return 下方不执行,并且会终止当前这个函数
# 4.return 不写或写了return后面不写值都返回None
return
然后我们再来使用它
函数名(实参)
相信大家很想了解什么是形参,实参,那我们就来讲解一下我们函数最有意思的东西传参。
1.形参
# 形参: 函数定义阶段括号中的参数叫做形参
1.位置参数:
一一对应
2.默认参数:
函数定义的时括号中写好的就是默认参数
不进行传参使用默认参数,进行传参时使用传递的参数
2.实参
# 实参: 函数调用阶段括号中的参数叫做实参
1.位置参数:
一一对应
2.关键字参数:
按照名字进行传参
3.混合参数:
位置参数和关键字参数一起使用
3.传参
位置参数 > 默认参数(关键字参数)
传参: 将实参传递给形参的过程叫传参
万恶之源——函数的进阶
1.动态传参
上面我们讲了正常的传参,这回我们来讲讲我们的进阶传参
如果说我们之前的传参都需要一一对应,那么动态传参就是
可以不限定你的形参个数。
函数体中 * 就是打散, *args将元组中的元组进行打散 *kwargs将字典的键获取
*变量名 #位置参数接取,
**变量名 #指定参数接取,只有在形参的时候是聚合的
*args (书写规范)
*kwargs(书写规范)
形参
位置参数
#动态位置参数: 先执行位置参数,位置参数接受后额外的参数动态位置参数进行接受 获取的是一个元组
默认参数
#动态关键字参数(默认): 先执行默认参数,默认参数接受后额外的默认参数动态默认参数进行接受,获取的是一个字典
2.函数备注
函数的备注在学习的后期或工作中都是非常有用的一项操作
# def b(a:int,b:int): # :int 是提醒用户这个参数应该为整形
# """ # """ 是我们的函数备注
# 求差 # 备注信息
# :param a: int #第一个形参
# :param b: int # 第二个形参
# :return: int #返回值
# """
# return a - b
#
# print(a.__doc__)
# print(b.__doc__) # 查看函数的注释
# print(a.__name__) # 查看函数的名字
3.命名空间

命名空间:
内置空间 : Python解释器自带的空间
全局空间 : py文件中顶格写的就是全局空间
局部空间 : 函数体中就是局部空间
1执行程序的时候会先执行内置空间,然后在执行全局空间,最后如果全局空间声明并调用了函数才会开辟局外空间
2.查找内容的时候如果是在局部空间找就先找局部空间,要是没找到就去全局寻找,要是全局也没有就去内置空间寻找
作用域:
1.全局作用域:全局+内置
2.局部作用域:局部
4.函数的嵌套
不管在什么位置,只要是函数名()就是在调用一个函数
# 混合嵌套:
# def f1():
# print(11)
#
# def f2():
# print(22)
# f1()
#
# def f3():
# print(33)
# f1()
#
# def run():
# f3()
# f2()
# f1()
# run()
# def func(a):
# print(a)
# return f1(foo(a))
#
# def foo(b):
# print(b)
# return b + 5
#
# def f1(args):
# return args + 10
#
# print(func(5))
# def foo(a):
# a = 10
# def f1(b):
# c = b
# def foo(c):
# print(c)
# print(foo.__doc__)
# foo(c)
# print(b)
# f1(a)
# print(a)
# foo(25)
# def foo():
# a = 10
# func(a)
#
# def func(a):
# print(a)
#
# foo()
5.global(修改全局)和nonlocal(修改局部)
# global : 只修改全局 找不到会在局部空间和全局空间都创建一个
# nonlocal : 只修改局部,修改离nonlocal最近的一层,上一层没有继续向上上层查找.只限在局部 找不到会报错
# a = 10
# def func():
# global a
# a = a - 6
# print(a)
#
# print(a)
# func()
# print(a)
# a = 100
# def func():
# b = 10
# def foo():
# b = a
# def f1():
# nonlocal b
# b = b + 5
# print(b) # 105
# f1()
# print(b) # 105
# foo()
# print(b) # 10
# func()
# print(a) # 100
6.函数名的第一类对象及使用
大家不要被这个名字所迷惑,其实这章主要讲的是函数名的一些使用方法
1.当作值赋给变量
def a(a=0):
print(a)
b = a # 将函数a的函数内存地址赋给变量b
b() # 对b进行调用就等于调用函数a
2.当作元素付给容器
例子列表为容器:
def a(a=0):
print(a)
def b(b=1):
print(b)
def c(c=2):
print(c)
lis = [a,b,c] # 将函数a,b,c的函数内存地址放在列表容器lis里面
lis[0]() # 取出列表容器lis里面的第一个函数地址并调用
lis[1]() # 取出列表容器lis里面的迪二哥函数地址并调用
lis[2]() # 取出列表容器lis里面的迪三哥函数地址并调用
for i in lis: # 利用for循环拿出每个lis列表中的元素
i() # 将列表内的每个函数内存地址都赋给i在进行调用
例子字典为容器:
msg = """
1 登录
2 注册
3 主页
"""
choose = input(msg) # 1
if choose.isdecimal():
if dic.get(choose):
dic[choose]()
else:
print("请正确输入!")
3.当作参数付给函数
def func(a): # 2.a收到函数地址
print(111)
a() # 3.对a()进行调用相当于对foo()进行调用
def foo():
print(222)
func(foo) # 1.将函数地址当作参数进行传参
4.当作函数的返回值
def func():
def foo():
print(111)
return foo # 返回foo函数地址
a = func()
a()
func()() # func返回foo的地址并调用
总结:
函数名的第一类对象的使用方式如下:
1.可以当做值,赋值给变量
2.可以当做容器中的元素
3.可以当做函数的参数
4.可以当做函数的返回值
str,int,list,tuple,dict
7.迭代器
首先我们这回来好好了解一下什么是可迭代对象
可迭代对象:
list,tuple,str,set,dict 取值方式只能直接看
只要有__iter__()方法就是可迭代对象
lst = [1,2,3,4]
lst.__iter__() # 也可以写成iter(lst)
print(lst.__iter__()) # 返回迭代器地址
迭代器:
迭代器就是个工具
具有__iter__()和__next__()两个方法才是迭代器
Lst = [1,2,3,4,5]
L = Lst.__iter__() # 将可迭代对象转换成迭代器
L.__iter__() # 迭代器指定__iter__()还是原来的迭代器
print(L.__next__()) #结果1 也可以写成next(L)
print(L.__next__()) #结果2
for i in lst: # 循环将可迭代对象全部取出到没有之后回报错
print(i)
w
# lst = [1,2,3,4,5]
# l = iter(lst)
# print(next(l))
# print(next(l)) #买了瓶矿泉水喝了5口
# print(next(l)) #结果1 2 3 4 5
# print(next(l))
# print(next(l))
# lst = [1,2,3,4,5]
# print(next(iter(lst))) # 买了5瓶水,每瓶矿泉水只喝一口
# print(next(iter(lst))) # 结果1 1 1 1 1
# print(next(iter(lst)))
# print(next(iter(lst)))
# print(next(iter(lst)))
for的本质:
(我们都知道for会循环可迭代对象,那我们来说下他的原理)
l = [1,2,3,4,5] # 首先创建一个可迭代对象
L = l.__iter__() # 将L变成迭代器
while 1:
try: # try:和except:是一对防报错方法
print(L.__next__())# L迭代器将所有值都迭代出来
except StopIteration: # try:和exce
break
总结:
pyhton3:
iter()和 __iter__() 都有
next()和__next__()都有
python2:
iter()
next()
迭代器的优点:
1.惰性机制 -- 节省空间
迭代器的缺点:
1.不能直接查看值 迭代器查看到的是一个迭代器的内存地址
2.一次性,用完就没有了
3.不能逆行(后退)
空间换时间: 容器存储大量的元素,取值时 取值时间短,但是容器占用空间较大
时间换空间: 迭代器就是节省了空间,但是取值时间较长
迭代器是基于上一次停留的位置,进行取值
可迭代对象:具有iter()方法就是一个可迭代对象
迭代器:具有iter()和next()方法就是一个迭代器
8.推导式
一.列表推导公式
1.普通循环
print([i for i in range(10)])
print([变量 for循环])
2.筛选
print([i for i in range(10) if i % 2 == 0])
print(加工后的变量 for循环 加工条件)
二.集合推到公式
1.普通循环
print({i for i in range(10)})
2.筛选模式
print({i for i in range(10) if i % 2 == 1})
三.字典推导公式
1.普通循环
print({i: i+1 for i in range(10)})
{键:值 for循环}
2.筛选循环
print({i: i+1 for i in range(10) if i % 2 == 0})
{加工后的键:值 for循环 加工条件}
3.字典的高阶使用方法
print(dict([(1,2),(3,4)]))
print(dict(k=1,v=2,c=3))
dic1 = {"key1":1,"key2":2}
dic2 = {"a":1,"b":2}
dic2.update(dic1)
print(dic2)
print(dict(**dic1,**dic2))
print(dict(((1,2),(3,33))))
for i in ((1,(2,3)),(3,33)):
k,v = i
dic = {}
dict(k=1)
dict([(1,2)])
四.生成器推导式
1.普通模式
tu = (i for i in range(10))
( 变量 for循环)
2.筛选模式
tu = (i for i in range(10) if i > 5)
(加工后的变量 for循环 加工条件)
9.生成器
生成器核心是迭代器
迭代器是Python自带的
生成器是程序员自己做的迭代器
# 生成器的作用是节省空间
# 可迭代对象:
# 优点: list,tuple,str 节省时间,取值方便,使用灵活(具有自己私有方法)
# 缺点: 大量消耗内存
# 迭代器:
# 优点:节省空间
# 缺点:不能直接查看值,使用不灵活,消耗时间,一次性,不可逆行
# 生成器:
# 优点:节省空间,人为定义
# 缺点:不能直接查看值,消耗时间,一次性,不可逆行
# 使用场景:
# 1.当文件或容器中数据量较大时,建议使用生成器
# 数据类型 (pyhton3: range() | python2 :xrange()) 都是可迭代对象 __iter__()
# 文件句柄是迭代器 __iter__() __next__()
# with open("a.txt","w",encoding="utf-8")as f
# lst = [1,2,3,4]
# l = lst.__iter__()
# print(l)
# 区别什么是迭代器,什么是生成器
#迭代器的地址
#生成器的地址
send() 生成器具有send方法
他一共有三种调用方法但第三种咱么不常用
1.基于函数
def func():
print("这是一个生成器")
yield "生成器"
print("这是第二个生成器")
yield "生成器"
print(func()) #输出生成器的地址
l = func() # 生成一个生成器并将生成器地址交给l
print(func().__next__()) # 启动生成器并输出第二个值
print(l.__next__()) # 启动生成器并输出第一个值
print(l.__next__()) # 启动生成器并输出第二个值
# yield 和 return 的区别
# 相同点:
# 1.都是返回内容
# 2.都可以返回对个,但是return写多个只会执行一个
# 1.return 终止函数 yield是暂停生成器
# 2.yield能够记录当前执行位置
# 一个yield 对应一个 next
# yield 将可迭代对象一次性返回
# yield from 将可迭代对象一个一个返回,调用一次返回一个元素(返回不可迭代对象会报错)
def a():
yield 1
yield from ("hei2",2)
l = a()
print(next(l))
print(next(l))
print(next(l))
结果:
1
hei2
2
2.推到式方式编写
tu = (i for i in range(10))
tu = (i for i in range(10) if i > 5)
10.进阶f占位符
f"" f-strings
name =
age =
msg = "姓名:xx 年龄:xx"
msg = "姓名:%s 年龄:%s"%(name,age)
f"姓名:{name} 年龄:{age}"
f"姓名:{'alex'}"
f"姓名:{34}"
print(F"姓名:{input('name:')} 年龄:{input('age:')}")
def foo():
print("is foo")
lst = [1,2,3,4]
dic = {"key1":23,"key2":56}
print(f"""{dic['key1']}""")
print(f"{3+5}")
print(f"{3 if 3>2 else 2}")
print(f"""{':'}""")
msg = f"""{{{{'alex'}}}}"""
print(msg)
name = "alex"
print(f"{name.upper()}")
print(f"{':'}")
11.匿名函数函数
匿名函数 == 一行函数
匿名函数的名字叫做 lambda
lambda == def == 关键字
x是普通函数的形参 (位置,关键字 ...) 可以不接收参数 (x:可以不写)
:后边x 是普通函数的函数值(只能返回一个数据类型) (:x返回值必须写)
例子
print((lambda x:x+6)(5))
print([lambda :5][0]())
列表内存储的是这个匿名函数的内存地址
print((lambda :5)())
直接调用
a = lambda :5
a()
a存放的是匿名函数的地址
lst = [lambda :i for i in range(3)]
print(lst[0]())
结果 2
tu = (lambda :i for i in range(3))
print(next(tu)())
结果 0
会暂停函数从而简介控制for循环
函数体中存放的是代码
生成器体中存放的也是代码
就是yield导致函数和生成器的执行结果不统一
12.内置函数(上)
a = "88 + 99"
a = """
def func():
print(111)
func()
"""
print(type(a))
print(eval(a)) # 神器一
exec(a) # 神器二
注意:千万记住 禁止使用
exec(input("请输入内容:"))
print(hash("123"))
print(hash(12))
print(hash(-1))
print(hash(-10))
print(hash((2,1)))
dic = {[1,2,3]:2}
print(hash([1,2,3]))
hash() 作用就是区分可变数据类型和不可变数据类型
lst = [1,2,3]
help(list) 查看帮助信息
def func():
print(1)
lst = [1,23,4,]
print(callable(lst)) # 查看对象是否可调用
print(int("010101",16))
print(float(3))
print(int(3))
print(complex(20)) # 复数
print(bin(100)) # 十进制转二进制
print(oct(10)) # 十进制转八进制
print(hex(17)) # 十进制转十六进制
print(divmod(5,2)) # (商,余)
print(round(3.534232,2)) # 保留小数位
print(pow(2,2)) #幂 pow 两个参数是求幂
print(pow(2,2,3)) #幂 pow 两个参数是求幂后的余
s = "你好"
s1 = bytes(s,encoding="utf-8") # 将字符串进行编码
print(str(s1,encoding="utf-8"))
print(s.encode("utf-8"))
print(ord("你")) # 通过元素获取当前(unicode)表位的序号
print(chr(20320)) # 通过表位序号查找元素
a = 'alex'
print(repr(a)) #查看你数据的原生态 -- 给程序员使用的
print(a) # 给用户使用的
lst = [1,2,0,4,5]
print(all(lst)) # 判断容器中的元素是否都位真 and
lst = [1,2,3,0,1,23] # 判断容器中的元素是否有一个为真
print(any(lst))
a = 10
def func():
a = 1
print(locals()) # 查看当前空间变量
print(1)
func()
print(globals()) # 查看全局空间变量
内置函数(下)
sep : 每个元素的分割 默认是空格
end : print语句的结束语句 默认是\n
sum()求和 可迭代对象容器,容器的元素必须是数字
sum([1,2,34,5,6,7],100) 指定开始位置的值
abs() 绝对值
dir() 查看当前对象所有方法
format() > < ^ o b x d
zip() 拉链 -- 当长度不一致时选择最短的进行合并
小练习
dict(zip(list1,list2))
reversed() 反转
filter() - 过滤 函数名(指定过滤规则),可迭代对象
map() -- 映射 函数名(对每个元素执行的方法),可迭代对象
sorted() 可迭代对象,key=指定规则
max() 可迭代对象,key=指定规则
min() 可迭代对象,key=指定规则
reduce 累计算
print(dict([(1,2),(3,4)]))
print(dict(k=1,v=2,c=3))
dic1 = {"key1":1,"key2":2}
dic2 = {"a":1,"b":2}
dic2.update(dic1)
print(dic2)
print(dict(**dic1,**dic2))
print(dict(((1,2),(3,33))))
for i in ((1,(2,3)),(3,33)):
k,v = i
dic = {}
dict(k=1)
dict([(1,2)])
sep : 每一个元素之间分割的方法 默认 " " ****
print(1,2,3,sep="|")
end :print执行完后的结束语句 默认\n ****
print(1,2,3,end="")
print(4,5,6,end="")
file : 文件句柄 默认是显示到屏幕
print(1,2,3,4,file=open("test","w",encoding="utf-8"))
print() # flush 刷新
print(sum([1,2,2,1]))
print(sum([10,20,30,40],100))
print(abs(9)) # 绝对值
print(dir(list)) # 查看当前对象所有方法 返回的是列表
print(dir(str)) # 查看当前对象所有方法
lst1 = [1,2,34,5]
lst2 = ["alex","wusir","宝元"]
print(list(zip(lst1,lst2))) # 拉链
print(dict(zip(lst1,lst2)))
print(format("alex",">20")) # 右对齐
print(format("alex","<20")) # 左对齐
print(format("alex","^20")) # 居中
print(format(10,"b")) # bin 二进制
print(format(10,"08b"))
print(format(10,"08o")) # oct 八进制
print(format(10,"08x")) # hex 十六进制
print(format(0b1010,"d")) # digit 十进制
print(list(reversed("alex")))
lst = [1,2,3,4,5]
print(list(reversed(lst))) 反转
print(lst)
filter -- 过滤
lst = [1,2,3,4,5,6]
def func(a):
return a>1
print(list(filter(func,lst)))
print(list(filter(lambda x:x>1,lst)))
lst = [1,2,3,4,5,6]
def f(func,args):
new_lst = []
for i in args:
if func(i):
new_lst.append(i)
return new_lst
def func(a):
return a>1
print(f(func,lst))
print(list(filter(lambda x:x>2,[1,2,3,4,5])))
lst = [{'id':1,'name':'alex','age':18},
{'id':1,'name':'wusir','age':17},
{'id':1,'name':'taibai','age':16},]
print(list(filter(lambda x:x['age']>16,lst)))
map 映射函数 (将每个元素都执行了执行的方法)
print(list(map(lambda x,y:x+y,[1,2,3,4],[11,2,3,411,22])))
print([i*8 for i in [1,2,3,4]])
print(sorted([1,-22,3,4,5,6],key=abs)) # key指定排序规则
lst = []
for i in [1,-22,3,4,5,6]:
lst.append(abs(i))
lst.sort()
print(lst)
filter() -- 过滤
def func(a):
return a == 1
print(list(filter(func,[1,2,3,4,6])))
1,指定过滤规则(函数名[函数的内存地址]) 2,要过滤的数据
自己模拟
def filter(func,argv):
lst = []
for i in argv:
ret = func(i)
if ret:
lst.append(i)
return lst
def foo(a):
return a>2
print(filter(foo,[1,2,3,4])) # filter(foo,[1,2,3,4])
def func(a):
return a>1
print(list(filter(func,[1,2,3,4,5])))
print(list(filter(lambda a:a>1,[1,2,3,4,5])))
map() -- 映射 (将可迭代对象中的每个元素执行指定的函数)
def func(a,b):
return a+b
print(list(map(func,[1,2,3,4,5],[33,22,44,55])))
def map(argv,args):
lst = []
num = len(args) if len(args) < len(argv) else len(argv)
for i in range(num):
lst.append(argv[i] + args[i])
return lst
print(map([1,2,3,4],[3,4,5,6,7,8,9,0]))
print(list(map(lambda x,y:x+y,[1,2,3,4,5],[33,22,44,55])))
sorted() -- 排序
print(sorted([1,2,3,4,5,6],reverse=True))
print(sorted([1,2,3,4,5,-6],reverse=True,key=abs))
lst = ["三国演义","红楼梦","铁道游击队","西游记","水浒传","活着"]
print(sorted(lst,key=len))
lst = [{"age":19},{"age1":20},{"age2":80},{"age3":10}]
print(sorted(lst,key=lambda x:list(x.values())))
print(sorted(lst,key=lambda x:list(x.keys()),reverse=True))
help(sorted)
lst = [{'id':1,'name':'alex','age':18},
{'id':2,'name':'wusir','age':17},
{'id':3,'name':'taibai','age':16},]
print(sorted(lst,key=lambda x:x['age']))
max() -- 最大值
print(max(10,12,13,15,16))
print(max([10,12,13,15,-16],key=abs))
min() -- 最小值
from functools import reduce # 累计算
从 functools工具箱中拿来了reduce工具
def func(x,y):
return x+y
print(reduce(func,[1,2,3,4,5]))
print(reduce(lambda x,y:x+y,[1,2,3,4,5]))
zip()
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。zip 方法在 Python 2 和 Python 3 中的不同:在 Python 3.x 中为了减少内存,zip() 返回的是一个对象。如需展示列表,需手动 list() 转换,如果需要了解 Pyhton3 的应用,可以参考 Python3 zip()。
zip 语法:
zip([iterable, ...])
参数说明:
iterabl -- 一个或多个迭代器;
返回值
返回元组列表。
>>>a = [1,2,3]
>>> b = [4,5,6]
>>> c = [4,5,6,7,8]
>>> zipped = zip(a,b) # 打包为元组的列表
[(1, 4), (2, 5), (3, 6)]
>>> zip(a,c) # 元素个数与最短的列表一致
[(1, 4), (2, 5), (3, 6)]
>>> zip(*zipped) # 与 zip 相反,*zipped 可理解为解压,返回二维矩阵式
[(1, 2, 3), (4, 5, 6)]
13.装饰器(初识)
装饰器: 面试笔试必问
开放封闭原则:
1.代码扩展进行开放
2.修改源代码是封闭
在不修改源代码及调用方式,对功能进行额外添加就是开发封闭原则
def index():
print("这是一个主页")
index()
装饰(额外功能) 器:工具(函数)
import time
def index():
time.sleep(2) #
print("这是小明写的功能")
def func():
time.sleep(1) #
print("这是小刚写的功能")
def red():
time.sleep(2) #
print("这是小红写的功能")
start_time = time.time() # 时间戳
index()
print(time.time() - start_time)
start_time = time.time() # 时间戳
func()
print(time.time() - start_time)
start_time = time.time() # 时间戳
red()
print(time.time() - start_time)
import time
def index():
time.sleep(2) #
print("这是小明写的功能")
def func():
time.sleep(1) #
print("这是小刚写的功能")
def red():
time.sleep(2) #
print("这是小红写的功能")
def times(func):
start_time = time.time() # 时间戳
func()
print(time.time() - start_time)
times(index)
times(func)
import time
def index():
time.sleep(2) #
print("这是小明写的功能")
def func():
time.sleep(1) #
print("这是小刚写的功能")
def red():
time.sleep(2) #
print("这是小红写的功能")
def times(func):
start_time = time.time() # 时间戳
func()
print(time.time() - start_time)
f = index
index = times
index(f)
f1 = func
func = times
func(f1)
第一版装饰器
import time
def func():
time.sleep(1) #
print("这是小刚写的功能")
def red():
time.sleep(2) #
print("这是小红写的功能")
def index():
time.sleep(2) #
print("这是小明写的功能")
def times(func):
def foo():
start_time = time.time() # 时间戳 被装饰函数执行前干的事
func()
print(time.time() - start_time) # 被装饰函数执行后干的事
return foo
index = times(index)
index()
func = times(func)
func()
def foo():
print("被装饰的函数")
def warpper(func): # func == None
def inner():
print("日魔最色")
func() # None()
print("日魔最骚")
return inner() # 不能加括号
foo = warpper(foo()) # 不能加括号 foo = warpper(None)
foo()
def foo():
print("被装饰的函数")
def warpper(func): # func == foo函数的内存地址
def inner():
print("日魔最色")
func() # foo()
print("日魔最骚")
return inner() # 不能加括号 # return None
foo = warpper(foo) # 不能加括号 foo = warpper(None)
foo()
def func():
print("被装饰的函数")
def warpper(f):
def inner():
print("111")
f()
print("222")
return inner
func = warpper(func)
func()
def warpper(f):
def inner():
print("111")
f()
print("222")
return inner
# python帮咱们做的一个东西,语法糖
@warpper # func = warpper(func)
def func():
print("被装饰的函数1")
@warpper # index = warpper(index)
def index():
print("被装饰的函数2")
func()
def warpper(f):
def inner():
print("111")
f()
print("222")
return inner
@warpper # func = warpper(func)
def func():
print("被装饰的函数1")
@warpper # index = warpper(index)
def index():
print("被装饰的函数2")
# python帮咱们做的一个东西,语法糖
func()
def foo():
print("被装饰的函数")
def warpper(func): # func == foo函数的内存地址
def inner():
print("日魔最色")
func() # foo()
print("日魔最骚")
return inner # 不能加括号 # return None
foo = warpper(foo) # 不能加括号 foo = warpper(None)
foo()
def warpper(f):
def inner():
print("111")
f()
print("222")
return inner
@warpper # func = warpper(func)
def func():
print("被装饰的函数1")
@warpper # index = warpper(index)
def index():
print("被装饰的函数2")
func()
index()
python帮咱们做的一个东西,语法糖
要将语法糖放在被装饰的函数正上方
def warpper(f):
def inner():
print("111")
f()
print("222")
return inner
@warpper # func = warpper(func)
def func():
print("被装饰的函数1")
@warpper # index = warpper(index)
def index():
print("被装饰的函数2")
func()
index()
def warpper(f):
def inner(*args,**kwargs):
print("被装饰函数执行前")
ret = f(*args,**kwargs)
print("被装饰函数执行后")
return ret
return inner
@warpper
def func(*args,**kwargs):
print(f"被装饰的{args,kwargs}")
return "我是func函数"
@warpper
def index(*args,**kwargs):
print(11111)
print(func(1,2,3,4,5,6,7,8,a=1))
14.有参装饰器(进阶)
一.有参装饰器
1.普通装饰
def a(a1):
def b(b1):
def c():
print("装饰器")
b1()
return c
return b
def j():
print("被装饰含函数")
o = a("进行第一层函数嵌套传参")
j = o(j)
j()
2.装饰糖的使用
def a(a1):
def b(b1):
def c():
print("装饰器")
b1()
return c
return b
@a("进行第一层函数嵌套传参")
def j():
print("被装饰含函数")
二.下面是一些小例子和小技巧
def warpper(func):
def inner(*args,**kwargs):
user = input("user:")
pwd = input("pwd:")
if user == 'alex' and pwd == "dsb":
func(*args,**kwargs)
return inner
@warpper
def foo():
print("被装饰的函数")
foo()
def auth(argv):
def warpper(func):
def inner(*args,**kwargs):
if argv == "博客园":
print("欢迎登录博客园")
user = input("user:")
pwd = input("pwd:")
if user == 'alex' and pwd == "dsb":
func(*args,**kwargs)
elif argv == "码云":
print("欢迎登录码云")
user = input("user:")
pwd = input("pwd:")
if user == 'alex' and pwd == "jsdsb":
func(*args, **kwargs)
return inner
return warpper
def foo():
print("被装饰的函数")
msg = input("请输入您要登录的名字:")
a = auth(msg)
foo = a(foo)
foo()
def wrapper(func):
def inner(*args,**kwargs):
print("走了,走了,走了")
func()
return inner
@wrapper
def foo():
print("这是一个点燃")
foo()
foo()
def auth(argv):
def wrapper(func):
def inner(*args,**kwargs):
if argv:
print("我加上功能了!")
func(*args,**kwargs)
else:
func(*args,**kwargs)
return inner
return wrapper
def foo():
print("这是一个点燃")
wrapper = auth(False)
foo = wrapper(foo)
foo()
def auth(argv):
def wrapper(func):
def inner(*args,**kwargs):
if argv:
print("我加上功能了!")
func(*args,**kwargs)
else:
func(*args,**kwargs)
return inner
return wrapper
https://www.cnblogs.com/
@auth("guobaoyuan") # @auth == foo = wrapper(foo) = auth(True) flask框架
def foo():
print("这是一个点燃")
foo()
多个装饰器装饰一个函数
多个装饰器装饰一个函数时,先执行离被装饰函数最近的装饰器
def auth(func): # wrapper1装饰器里的 inner
def inner(*args,**kwargs):
print("额外增加了一道 锅包肉")
func(*args,**kwargs)
print("锅包肉 38元")
return inner
def wrapper1(func): # warpper2装饰器里的 inner
def inner(*args,**kwargs):
print("额外增加了一道 日魔刺生")
func(*args,**kwargs)
print("日魔刺生 白吃")
return inner
def wrapper2(func): # 被装饰的函数foo
def inner(*args,**kwargs):
print("额外增加了一道 麻辣三哥")
func(*args,**kwargs)
print("难以下嘴")
return inner
@auth # 1 7
@wrapper1 # 2 6
@wrapper2 # 3 5
def foo(): # 4
print("这是一个元宝虾饭店")
foo = wrapper2(foo) # inner = wrapper2(foo)
foo = wrapper1(foo) # inner = wrapper1(inner)
foo = auth(foo) # inner = auth(inner)
foo() # auth里边的inner()
def auth(func): # wrapper1装饰器里的 inner
def inner(*args,**kwargs):
print(123)
func(*args,**kwargs)
print(321)
return inner
def wrapper1(func): # warpper2装饰器里的 inner
def inner(*args,**kwargs):
print(111)
func(*args,**kwargs)
return inner
def wrapper2(func): # 被装饰的函数foo
def inner(*args,**kwargs):
print(222)
func(*args,**kwargs)
print(567)
return inner
@auth
@wrapper1
@wrapper2
def foo():
print("www.baidu.com")
foo()
14.闭包
什么是闭包?
1.在嵌套函数内,使用(非本层变量)和非全局变量就是闭包
闭包的作用:
1.保护数据的安全性
2.装饰器
.__closure__) # 判断是不是闭包是就返回地址不是就返回None
实例
def func():
a = 1
def foo():
print(a)
print(foo.__closure__) # 判断是不是闭包
func()
10w
lst = []
def h6(money):
lst.append(money)
if len(lst) == 7:
print("第一周平均价格:",sum(lst) / 7)
h6(200000)
h6(100000)
h6(1400000)
h6(100000)
lst[0] = 10
h6(1100000)
h6(2500000)
h6(2500000)
1128571.4285714286
1100001.4285714286
def h6(money):
lst = []
lst.append(money)
if len(lst) == 7:
print("第一周平均价格:",sum(lst) / 7)
h6(200000)
h6(100000)
h6(1400000)
h6(100000)
h6(1100000)
h6(2500000)
h6(2500000)
def h6():
lst = []
def foo(money):
lst.append(money)
if len(lst) == 7:
print("第一周平均价格:",sum(lst) / 7)
return foo
foo = h6()
foo(111)
foo(1500000)
foo(1100000)
foo(100000)
foo(200000)
foo(300000)
foo(1200000)
foo(1100000)
闭包的作用:
1.保护数据的安全性
2.装饰器
例一:
def wrapper():
a = 1
def inner():
print(a)
return inner
ret = wrapper()
a = 2
def wrapper():
def inner():
print(a)
return inner
ret = wrapper()
def wrapper(a,b):
def inner():
print(a)
print(b)
inner()
print(inner.__closure__)
a = 1
b = 2
wrapper(11,22)
函数常见错误点
1.
item = '哈哈哈'
def func():
item = 'alex'
def inner():
print(item)
for inner in range(10):
pass
inner()
func()
结果
报错
因为inner在函数的最后里面纯的是9的内存地址
2.
data_list = []
def func(arg):
return data_list.insert(0, arg)
data = func('绕不死你')
print(data)
print(data_list)
结果
# None
# ["绕不死你"]
局部空间可以对全局的可变类型参数在不改变地址的情况下进行内部修改
3.
def extendList(val,list=[]):
list.append(val)
return list
list1 = extendList(10)
list2 = extendList(123,[])
list3 = extendList('a')
print('list1=%s'%list1)
print('list2=%s'%list2)
print('list3=%s'%list3)
结果
list1=[10,'a']
list2=[123]
list3=[10,'a']
每个函数每次调用内部形参默认值的地址是唯一不变的,除非对他进行赋值
(每次调用这个函数的时候默认值会被重新赋值一边)
4.
def extendList(val,list=[]):
list.append(val)
return list
print('list1=%s'% extendList(10))
print('list2=%s'% extendList(123,[]))
print('list3=%s'% extendList('a'))
结果
list1=[10]
list2=[123]
list3=[123,'a']
在更改列表之前已经把列表进行了打印
5.
name = '宝元'
def func():
print("a")
print(name)
name = 'alex'
func()
在进入函数之后python检查到有格式上的错误
Python运行
词法分析:查看是否有格式上的错误,不是从上到下
语义分析:查看是否有逻辑上的错误
语法分析:真正执行代码从上到下,从上到下执行
这道题在词法查询的时候发现有name,所以当语法分析经过的时候询问语法分析的时候语法分析说我这边有name但语法分析却看不到他下面的代码,所以产生报错
21.自定义模块
模块能干什么?
1.文件化管理 提高可读性,避免重复代码
2.拿来就用 (避免重复造轮子) python中类库特别多
定义一个模块
一个文件就是一个模块 (模块就是一个工具箱 工具(函数))
import时会做三件事:
1.将test.py文件中所有代码读取到当前文件
2.当前文件开辟空间
3.等待被调用
import 导入同一个模块名是,只执行一次
import test # 导入 拿test工具箱
import test # 导入 拿test工具箱
import test # 导入 拿test工具箱
def t1():
print("高级工程师")
import test
test.t1()
test.t2()
print(test.tt)
import test # 只能将整个工具箱拿来
a = test.t1
b = test.t2
a()
b()
import test as t # 工具箱名字过长可以起别名
t.t1()
import test # 导入模块不能加后缀名
飘红不代表报错
from test import t1 as t # 从test工具箱中将t1这个工具拿过来
def t1():
print("高级工程师")
t1()
t()
as 支持 import 和 from
from 和 import 推荐使用from
from test import t1
t1()
import 和 from 的区别:
1.from只能执行导入的工具
2.import 能够执行整个模块中所有的功能
3.from容易将当前文件中定义的工能覆盖
4.from比import灵活
import 只能导入当前文件夹下的模块
import 后边不能加点操作
from day15 import ttt
from day15.ttt import func
func()
import 和 from 使用的都是相对路径
import sys # 和python解释交互接口
print(sys.path)
sys.path.append(r"C:\Users\oldboy\Desktop")
print(sys.path)
模块导入顺序:
sys.path.append(r"C:\Users\oldboy\Desktop")
内存 > 内置 > 第三方> 自定义
sys.path.insert(0,r"C:\Users\oldboy\Desktop")
内存 > 自定义 > 内置 > 第三方
模块的两种用法: if __name__ == "__main__"
1.当做模块被导入 import from
2.当做脚本被被执行
import test
只有py文件当做模块被导入时,字节码才会进行保留
以后你们导入模块会产生的坑
1.注意自己定义模块的名字
import abcd
abcd.func()
2.注意自己的思路 -- 循环导入时建议 导入模式放在需要的地方
from test import b
a = 10
print(b)
import test,c,abcd 不建议这样导入
test.t1()
print(c.ac)
abcd.func()
import test
import c
import abcd # 建议这样导入
import from
from test import * # 拿整个工具箱
t1()
t2()
print(tt)
通过__all__ 控制要导入的内容
22.内置模块
1.time(时间模块)
time.time() # 时间戳 浮点数 秒
# 将时间戳转换成结构化时间
下面就是结构化时间
(tm_year=2019, tm_mon=8, tm_mday=22, tm_hour=22, tm_min=10, tm_sec=22, tm_wday=3, tm_yday=234, tm_isdst=0)
time.localtime(time.time()) # 命名元祖
time.localtime(time.time())[0] #可用索引取出元祖内的参数
time.localtime(time.time()).tm_year # 也可用名字来取值
#将结构化时间转化为时间戳
time.mktime(结构化时间)
#将结构化时间转换为字符串
a = time.localtime() # 获得结构化时间
time.strftime(a,"%Y-%m-%d %H:%M:%S") # 左边放的是格式化时间,右边放的是输出格式
#将字符串转换成结构化时间
a = "2018-10-1 10:11:12"
time.strptime(a,"%Y-%m-%d %H:%M:%S")
总结:
time.time() 时间戳
time.sleep() 睡眠
time.localtime() 时间戳转结构化
time.strftime() 结构化转字符串
time.strptime() 字符串转结构化
time.mktime() 结构化转时间戳
%Y 年
%m 月
%d 日
%H 时间
%M 分钟
%S 秒
2.datetime
from datetime import datetime,timedelta
print(datetime.now()) # 获取当前时间
print(datetime(2018,10,1,10,11,12) - datetime(2011,11,1,20,10,10))
指定时间
将对象转换成时间戳
d = datetime.now()
print(d.timestamp())
将时间戳转换成对象
import time
f_t = time.time()
print(datetime.fromtimestamp(f_t))
将对象转换成字符串
d = datetime.now()
print(d.strftime("%Y-%m-%d %H:%M:%S"))
将字符串转换成对象
s = "2018-12-31 10:11:12"
print(datetime.strptime(s,"%Y-%m-%d %H:%M:%S"))
可以进行加减运算
from datetime import datetime,timedelta
print(datetime.now() - timedelta(days=1))
print(datetime.now() - timedelta(hours=1))
3.random
# random -- 随机数
import random
print(random.randint(1,50))
选择1-50之间随机的整数
print(random.random())
0-1 之间随机小数,不包含1
print(random.uniform(1,10))
1- 10 之间随机小数,不包含10
print(random.choice((1,2,3,4,5,7)))
#从容器中随机选择一个
print(random.choices((1,2,3,4,5,7),k=3))
从容器中随机选择3个元素,以列表的形式方式,会出现重复元素
print(random.sample((1,2,3,4,5,7),k=3))
从容器中随机选择3个元素,以列表的形式方式,不会出现重复元素
print(random.randrange(1,10,2)) # 随机的奇数或随机的偶数
lst = [1,2,3,4,5,6,7]
random.shuffle(lst)
# 洗牌 将有序的数据打散
print(lst)
4.sys
1.sys.path # 获得模块的查找顺序,可用列表操作对他进行操作(添加自定义查询地址)
会获得下面这样的列表:
['D:\\Python_LNH\\B_K_Y_0.1\\conf', 'D:\\Python_LNH', 'C:\\Python36\\python36.zip', 'C:\\Python36\\DLLs', 'C:\\Python36\\lib', 'C:\\Python36', 'C:\\Python36\\lib\\site-packages', 'C:\\PyCharm 2018.1.3\\helpers\\pycharm_matplotlib_backend']
2.sys.argv # 在pycharm内部可获取当前文件地址
#在cmd可代替input
import sys
a = sys.argv
print(a)
在pycharm里执行会获得下面列表
['D:/Python_LNH/B_K_Y_0.1/conf/cl.py']
3.sys.modules # 查看加载到内存里的模块(Python会将你常用的模块放在内存里提升速度)
4.sys.platform
# 查看当前操作系统平台
# mac - darwin win - win32
# mac -- linux 查看 ls
5.sys.version # 查看解释器版本
5.json,pickle(将列表和字典做转换字符串)
序列化:
1.json
2.pickle
1.json
4个方法 2组
dumps ,loads -- 用于网络传输(只负责转换)(可配合文件操作)
dump ,load -- 用于文件存储(可以将列表或字典转换为字符串存储在文件里
也可以将文件内的列表和字典类型的字符串转换为源数据类型)
dic = {"key": 1}
lst = [1,2,3,4]
import json # 重点
a = json.dumps(dic) # 将字典序列成了字符串
b = json.loads(a) # 将字符串反序列成原数居类型
print(a,type(a))
print(b,type(b))
a1 = json.dumps(lst) # 将列表序列成了字符串
b1 = json.loads(a1) # 将字符串反序列成原数据类型
print(a1,type(a1))
print(b1,type(b1))
将数据类型转换成字符串(序列化),将字符串转成原数据类型(反序列)
能够序列: 字典,列表,元组序列后变成列表
dic = {"key":1}
json.dump(dic,open("a","a",encoding="utf-8"))
# 将源数据类型转换成字符串,写入到文件中
print(json.load(open("a","r",encoding="utf-8"))['key'])
# 将文件中字符串转成源数据类型
dic = {"key":"宝元"}
f = open("a","a",encoding="utf-8")
f.write(json.dumps(dic)+"\n")
f.write(json.dumps(dic)+"\n")
f.write(json.dumps(dic)+"\n")
f.write(json.dumps(dic)+"\n")
f1 = open("a","r",encoding="utf-8")
for i in f1:
print(json.loads(i),type(json.loads(i)))
dic = {"meet":27,"太白":30,"alex":36,"wusir":33}
print(json.dumps(dic,ensure_ascii=False,sort_keys=True))
2.pickle
只有python有,几乎可以序列python中所有数据类型,匿名函数不能序列
import pickle
def func():
print(1)
a = pickle.dumps(func) # 将原数据类型转换成类似字节的内容
print(pickle.loads(a)) # 将类似字节的内容转换成原数据类型
6.os(系统模块)
工作路径:
import os # os是和操作系统做交互,给操作发指令
print(os.getcwd()) # 获取当前文件工作的路径 ***
os.chdir("D:\Python_s25\day16") # 路径切换 **
print(os.getcwd())
print(os.curdir)
print(os.pardir)
文件夹 ***
os.mkdir("a2") # 创建文件夹
os.rmdir("a2") # 删除文件夹
os.makedirs('a1/a2/a3') # 递归创建文件夹
os.removedirs("a1/a2/a3") # 递归删除文件夹
print(os.listdir(r"D:\Python_s25\day17")) # 查看当前文件下所有的内容
文件 ***
os.remove(r"D:\Python_s25\day17\a") #删除文件,彻底删除 找不回来
os.rename() # 重命名
路径
print(os.path.abspath("test")) # 返回的是绝对路径 ***
print(os.path.split(r"D:\Python_s25\day17\test")) #将路径分割成一个路径和一个文件名 **
print(os.path.dirname(r"D:\Python_s25\day17\test")) #获取到父目录 ***
print(os.path.basename(r"D:\Python_s25\day17\test")) #获取文件名 **
print(os.path.join("D:\Python","day17","test")) # 路径拼接 ***(非常重要)
判断
print(os.path.exists(r"D:\Python_s25\day17\blog")) # 判断当前路劲是否存在 **
print(os.path.isabs(r"D:\Python_s26\day17\blog")) # 判断是不是绝对路径 **
print(os.path.isdir(r"D:\Python_s25\day17\blog")) # 判断是不是文件夹 **
print(os.path.isfile(r"D:\Python_s25\day17\blog")) # 判断是不是文件 **
print(os.path.getsize(r"D:\Python_s25\day17\01 今日内容.py")) # 获取文件大小
print(os.path.getsize(r"D:\Python_s25")) # 获取文件大小 ***
7.re(正则)
name = "alexdsb"
print(name.find("dsb"))
import re
findall 返回的是列表
print(re.findall("\w","宝元-alex_dsb123日魔吃D烧饼")) \w 字母.数字.下划线.中文 ***
print(re.findall("\W","宝元-alex_dsb123日魔吃D烧饼")) \w 不是字母.数字.下划线.中文 ***
print(re.findall("\d","十10⑩")) # \d 匹配数字 ***
print(re.findall("\D","十10⑩")) #\D 匹配非数字 ***
print(re.findall("^a","alex")) # 以什么开头 ***
print(re.findall("x$","alex")) # 匹配什么结尾 ***
print(re.findall("a.c","abc,aec,a\nc,a,c")) # 匹配任意一个字符串(\n除外) ***
print(re.findall("a.c","abc,aec,a\nc,a,c",re.DOTALL))
print(re.findall('[0-9]',"alex123,日魔dsb,小黄人_229")) ***
print(re.findall('[a-z]',"alex123,日魔DSB,小黄人_229"))
print(re.findall('[A-Z]',"alex123,日魔DSB,小黄人_229"))
[0-9] # 取0-9之前的数字
[^0-9] # 取非 0-9之间的数字
print(re.findall("[^0-9a-z]","123alex456")) ***
print(re.findall("a*","alex,aa,aaaa,bbbbaaa,aaabbbaaa")) # 匹配*左侧字符串0次或多次 贪婪匹配 ***
print(re.findall("a*","alex,aa,aaaa,bbbbaaa,aaabbbaaa"))
print(re.findall("a+","alex,aa,aaaa,bbbbaaa,aaabbbaaa")) 匹配左侧字符串一次或多次 贪婪匹配 ***
print(re.findall("a?","alex,aa,aaaa,bbbbaaa,aaabbbaaa")) # 匹配?号左侧0个或1个 非贪婪匹配 ***
print(re.findall("[0-9]{11}","18612239999,18612239998,136133333323")) # 指定查找的元素个数 ***
print(re.findall("a{3,8}","alex,aaaabbbaaaaabbbbbbaaa,aaaaaaaaabb,ccccddddaaaaaaaa")) ***
print(re.findall("(.+)","alex wusir")) 分组 ***
print(re.findall("(.+?)","alex wusir")) 控制贪婪匹配 ***
print(re.findall("\n","alex\nwusir"))
print(re.findall("\t","alex\twusir"))
print(re.findall("\s","alex\tdsbrimocjb")) # \s 匹配空格
print(re.findall("\S","alex\tdsbrimocjb")) # \s 匹配非空格
print(re.findall("\Aa","asfdasdfasdfalex"))
print(re.findall("d\Z","asfdasdfasdfalex"))
print(re.findall("alex","alex\twusiralex"))
print(re.findall("a.c","abc,aec,a d,a,c"))
print(re.findall("^a.............c$","abc,aec,a d,a,c"))
print(re.findall('[0-9a-zA-Z]',"alex123,日魔DSB,小黄人_229"))
print(re.findall('[-0-9]',"alex-123,日魔DSB,小黄人_229"))
a|b 或
print(re.findall("a|b","alexdsb"))
print(re.findall("a(.?)c","alc,abc,adc,a c"))
print(re.findall("(.)","alex wusir"))
print(re.findall("(.+)","alex wusir"))
print(re.findall("(.+)","alex wusir"))
print(re.findall("(.+?)","alex wusir"))
print(re.findall("(?:.+?)","alex wusir"))
有如下字符串:'alex_sb ale123_sb wu12sir_sb wusir_sb ritian_sb' 的 alex wusir '
找到所有带_sb的内容
s = 'alex_sb ale123_sb wu12sir_sb wusir_sb ritian_sb'
print(re.findall("(.+?)_sb",s))
print(re.findall("(.+)_sb",s))
search 和 match 区别
search 从任意位置开始查找
match 从头开始查看,如果不符合就不继续查找了
group()进行查看
print(re.search("a.+","lexaaaa,bssssaaaasa,saaasaasa").group())
print(re.match("a.+","alexalexaaa,bssssaaaasa,saaasaasa").group())
split -- 分割
print(re.split("[:;,.!#]","alex:dsb#wusir.djb"))
sub -- 替换
s = "alex:dsb#wusir.djb"
print(re.sub("d","e",s,count=1))
compile 定义匹配规则
s = re.compile("\w")
print(s.findall("alex:dsb#wusir.djb"))
s = re.finditer("\w","alex:dsb#wusir.djb") # 返回的就是一个迭代器
print(next(s).group())
print(next(s).group())
for i in s:
print(i.group())
import re # (给分组命名)
ret = re.search("<(?P\w+)>\w+","hello
")
ret = re.search("<(?P\w+)>(?P\w+)","hello
")
print(ret.group("tag_name"))
print(ret.group("content"))
print(ret.group("tag_name"))
print(ret.group())
8.hashlib(加密校验)
摘要算法,加密算数 ...
1.加密
2.校验
md5,sha1,sha256,sha512
1.md5,加密速度快,安全系数低
2.sha512 加密速度慢,安全系数高
明文(123adsa) -- 字节 -- 密文(bs2501153023ras32rf150q23r13ar)
1.当要加密的内容相同时,你的密文一定是一样的
2.当你的明文不一样时,密文不一定一样
3.不可逆
import hashlib
md5 = hashlib.md5() # 初始化
md5.update("alex".encode("utf-8")) # 将明文转换成字节添加到新初始化的md5中
print(md5.hexdigest()) # 进行加密
dic = {"534b44a19bf18d20b71ecc4eb77c572f":"alex"}
534b44a19bf18d20b71ecc4eb77c572f
9b4c00b63b24c060abd31c6cb96b7bc8
msg = input("请输入密码")
print(msg)
加盐
加固定盐
import hashlib
md5 = hashlib.md5("rimo_dsb".encode("utf-8")) # 初始化
md5.update("alex".encode("utf-8")) # 将明文转换成字节添加到新初始化的md5中
print(md5.hexdigest()) # 进行加密
加动态盐
import hashlib
user = input("username:")
pwd = input("password:")
md5 = hashlib.md5(user.encode("utf-8")) # 初始化
md5.update(pwd.encode("utf-8")) # 将明文转换成字节添加到新初始化的md5中
print(md5.hexdigest()) # 进行加密
1f174367fa08bf51d789a5c988f8ff1e
d599321766c76d5ce8b9e2b53ebd5764
60c6d277a8bd81de7fdde19201bf9c58a3df08f4
35f319ca1dfc9689f5a33631c8f93ed7c3120ee7afa05b1672c7df7b71f63a6753def5fd3ac9db2eaf90ccab6bff31a486b51c7095ff958d228102b84efd7736
import hashlib
sha1 = hashlib.sha1()
sha1.update("alex".encode("utf-8"))
print(sha1.hexdigest())
import hashlib
sha1 = hashlib.sha1()
sha1.update("日魔就是一个大SB".encode("utf-8"))
print(sha1.hexdigest())
sha1 = hashlib.sha1()
sha1.update("日魔就是一个大SB".encode("gbk"))
print(sha1.hexdigest())
中文内容编码不同时密文是不一致,英文的密文都是一致的
import hashlib
md5 = hashlib.md5()
md5.update(b"afdadfadfadsfafasdfasfdfdfdfdfdfdfdfdfdfdfdfdfdfdfdfdfdfd")
md5.update(b"afdadfadfadsfafasdfasfdfdfdfdfdfdfdfdfdfdfdfdfdfdfdfdfdfd")
md5.update(b"afdadfadfadsfafasdfasfdfdfdfdfdfdfdfdfdfdfdfdfdfdfdfdfdfd")
print(md5.hexdigest())
efe9bb9e7e090768597517019e5716b6
efe9bb9e7e090768597517019e5716b6
import hashlib
md5 = hashlib.md5()
md5.update(b"afdadfadfadsfafasd")
print(md5.hexdigest())
import hashlib
def file_check(file_path):
with open(file_path,mode='rb') as f1:
md5= hashlib.md5()
while True:
content = f1.read(1024) # 2049 1025 1
if content:
md5.update(content)
else:
return md5.hexdigest()
print(file_check('python-3.6.6-amd64.exe'))
ftp
9.collections(复合型数据类型)
collections -- 基于python自带的数据类型之上额外增的几个数据类型
命名元组:
from collections import namedtuple
limit = namedtuple("limit",["x","y"])
l = limit(1,2)
print(l.x)
print(l[0])
双端队列
from collections import deque
lst = [1,2,3,4]
deque = [1,2,3,4]
deque.append(1)
deque.remove(1)
print(deque)
l = deque([1,2])
l.append(3)
l.appendleft(0)
l.pop()
l.popleft()
l.remove(2)
print(l)
队列: 先进先出
栈: 先进后出
from collections import OrderedDict
有序字典(python2版本) -- python3.6 默认是显示有序
dic = OrderedDict(k=1,v=11,k1=111)
print(dic)
print(dic.get("k"))
dic.move_to_end("k")
from collections import defaultdict
默认字典
dic = defaultdict(list)
dic[1]
print(dic)
lst = [11,22,33,44,55,77,88,99]
dic = defaultdict(list)
for i in lst:
if i > 66:
dic['key1'].append(i)
else:
dic['key2'].append(i)
print(dict(dic))
from collections import Counter
计数 返回一个字典
lst = [1,2,112,312,312,31,1,1,1231,23,123,1,1,1,12,32]
d = Counter(lst)
print(list(d.elements()))
print(dict(d))
重要Counter
23.包
管理模块(文件化)
什么是包?
文件夹下具有__init__.py的就是一个包
import bake #现在不好使
bake.api.es
指定功能导入
import bake.api.es
bake.api.es.func()
import bake.api.es as f
f.func()
f.foo()
from bake.api.es import func,foo
func()
foo()
导入模块中全部
import bake
bake.api.es.foo() # 建筑师
bake.api.es.func() # 体验师 -- 宾馆 -- 睡觉(裸睡) -- 体验(酒店设施,酒店的床) -- 写报告
bake.cmd.manage.rimo() # 炊事班
bake.db.models.alex() # 保洁部
路径
绝对路径:从包的最外层进行查找,就是绝对路径
from bake.api.es import *
from ..
func()
import sys
print(sys.path)
23.日志
# logging -- 日志
# 1.记录用户的信息
# 2.记录个人流水
# 3.记录软件的运行状态
# 4.记录程序员发出的指令
# 5.用于程序员代码调试
# 日志中要记录的信息
# 默认从warning开始记录
# 手动挡
# import logging
# logging.basicConfig(
# level=logging.DEBUG,
# format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
# datefmt='%Y-%m-%d %H:%M:%S',
# filename="test.log",
# filemode="a",
# )
#
#
# logging.debug("你是疯儿,我是傻") # debug 调试
# logging.info("疯疯癫癫去我家") # info 信息
# logging.warning("缠缠绵绵到天涯") # info 警告
# logging.error("我下不床") # error 错误
# logging.critical("你回不了家") # critical 危险
# 自动挡
import logging
# 初始化一个空日志
logger = logging.getLogger() # -- 创建了一个对象
# 创建一个文件,用于记录日志信息
fh = logging.FileHandler('test.log',encoding='utf-8')
# 创建一个文件,用于记录日志信息
fh1 = logging.FileHandler('test1.log',encoding='utf-8')
# 创建一个可以在屏幕输出的东西
ch = logging.StreamHandler()
# 对要记录的信息定义格式
msg = logging.Formatter('%(asctime)s - [line:%(lineno)d] %(filename)s - %(levelname)s - %(message)s')
# 对要记录的信息定义格式
msg1 = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')
# 设置记录等级
logger.setLevel(10) or logger.setLevel(logging.DEBUG)
# 等级对应表
'''
DEBUG - 10
INFO - 20
WARNING - 30
ERROR - 40
CRITICAL - 50
'''
# 将咱们设置好的格式绑定到文件上
fh.setFormatter(msg)
fh1.setFormatter(msg)
# 将咱们设置好的格式绑定到屏幕上
ch.setFormatter(msg1)
# 将设置存储日志信息的文件绑定到logger日志上
logger.addHandler(fh) #logger对象可以添加多个fh和ch对象
logger.addHandler(fh1)
logger.addHandler(ch)
# 记录日志
logger.debug([1,2,3,4,])
logger.info('logger info message')
logger.warning('logger warning message')
logger.error('logger error message')
logger.critical('logger critical message')
24.面向对象
1.面向对象初识
面向 对象(核心) 编程
1.结构清晰,可读性高
2.上帝思维
面向对象:
类 : 对一事物的统称和概况
对象 : 实实在在存在的东西,具有特征和功能
1.减少重复代码
2.可读性高
函数式编程 vs 面向对象
def login():
pass
def check_buy_goods():
pass
def change_pwd():
pass
def shopping():
pass
def register():
pass
def check_unbuy_goods():
pass
class Auth:
def login(self):
pass
def register(self):
pass
def change_pwd(self):
pass
class Shopping:
def shopping(self):
pass
def check_buy_goods(self):
pass
def check_unbuy_goods(self):
pass
2.类(结构)
class -- def 都是关键字
def 函数名(使用下划线):
函数体
class 类名(使用驼峰体):
静态属性 (类变量,静态字段)
方法 (类方法,动态属性,动态字段)
class People:
mind = "有思想" # 静态属性
def eat(self): # 方法
print("在吃饭")
def work(self):
print("在工作")
class Dog:
hair = "有毛" # 静态属性
def eat(self):
print("吃大bb")
def lick(self):
print("会舔")
3.类名角度操作类
class People:
mind = "有思想" # 静态属性
def eat(self): # 方法
print("在吃饭")
def work(self):
print("在工作")
查看类下所有内容
print(People.__dict__)
万能的点 查看单个属性或方法
print(People.mind)
增:
People.emotion = "有情感"
删:
del People.mind
改:
People.mind = "无脑"
print(People.__dict__)
查:
print(People.mind) # 单独查一个
People.eat(1)
一般情况下我们不使用类名去操作方法 (类方法除外)
4.对象角度操作类
class People:
mind = "有思想" # 静态属性
def eat(self): # 方法
print("self --->",self)
print("在吃饭")
def work(self):
print("在工作")
创建对象 -- 类名()
p = People() # 实例化对象
print(p.__dict__) # 对象的空间
print("p---->",p)
print(p.mind)
p.eat()
p.work()
class People:
mind = "有思想" # 静态属性
def __init__(self,name,age,sex): # 初始化
# self == p
self.name = name
self.age = age
self.sex = sex
def eat(self): # 方法
print(self.name)
print("在吃饭")
def work(self):
print("在工作")
p = People("alex",19,"男") # 实例化一个对象
p.eat()
类外部给对象创建属性 不建议这样使用
p.mind = "无脑" # 给对象创了一个空间
print(People.__dict__)
print(p.__dict__)
对象只能使用类中的属性和方法,不能进行修改
1. 实例化一个对象,给对象开辟空间
2. 自动执行__init__方法
3. 自动将对象的地址隐性传递给了self
5.什么是self
`class People:
mind = "有思想" # 静态属性
def __init__(self,name,age,sex,high=None): # 初始化(给创建的对象封装独有属性)
# self == p
self.name = name
self.age = age
self.sex = sex
if high:
self.high = high
def eat(self): # 方法
print(f"{self.name}在吃饭")
def work(self):
print("在工作")
p1 = People("alex",19,"未知",170) # 实例化一个对象
p2 = People("wusir",19,"未知",170) # 实例化一个对象
p3 = People("rimo",19,"未知",170) # 实例化一个对象
p4 = People("李俊玲",19,"未知",170) # 实例化一个对象
p5 = People("狗哥",19,"未知",170) # 实例化一个对象
p1.eat()
p2.eat()
# p2 = People("日魔",15,"人x",40) # 实例化一个对象
# p3 = People("狗哥",21,"男",175) # 实例化一个对象
# p4 = People("豹哥",18,"男",100) # 实例化一个对象
# self :
# 1.就是函数的位置参数
# 2.实例化对象的本身(p和self指向的同一个内存地址)
6.类空间
1.给对象空间添加属性
class A:
def __init__(self,name):
# 类里边给对象添加属性
self.name = name
def func(self,sex):
self.sex = sex
a = A("meet")
a.func("男")
# 类外边给对象添加属性
a.age = 18
print(a.__dict__)
总结:给对象空间添加属性可以在类的内部,类的外部,类中的方法
2.给类空间添加属性
class A:
def __init__(self,name):
# 类内部给类空间添加属性
A.name = name
def func(self,age):
# 类中的方法给类空间添加属性
A.age = age
类外部给类空间添加属性
A.name = "alex"
a = A('meet')
a.func(19)
print(A.__dict__)
总结:给类空间添加属性可以在类的内部,类的外部,类中的方法
class B:
def __init__(self,name):
self.name = name
def index(self):
print(self.name,"is index")
b = B("alex")
b.index()
7.类关系
1.依赖关系
主 -- 人
次 -- 冰箱
class People:
def __init__(self,name):
self.name = name
def open(self,bx):
bx.open_door(self)
def close(self,bx):
bx.close_door(self)
class Refrigerator:
def __init__(self,name):
self.name = name
def open_door(self,p):
print(f"{p.name} 打开冰箱")
def close_door(self,p):
print(f"{p.name} 关闭冰箱")
r = People("日魔")
aux = Refrigerator("奥克斯")
r.open(aux)
r.close(aux)
class People:
def __init__(self,name):
self.name = name
def open(self,bx):
bx.open_door(self)
def close(self,bx):
bx.close_door(self)
class Refrigerator:
def __init__(self,name):
self.name = name
def open_door(self,p):
print(f"{p.name} 打开冰箱")
def close_door(self,p):
print(f"{p.name} 关闭冰箱")
r = People("日魔")
aux = Refrigerator("奥克斯")
r.open(aux)
r.close(aux)
class People:
def __init__(self,name):
self.name = name
def eat(self,food,flag):
food.eat(self,flag)
class Food:
def __init__(self,name):
self.name = name
def eat(self,p,f):
if f:
print(f"{p.name} 吃了 {self.name}")
else:
print(f"{p.name} 消化了 {self.name}")
p = People("日魔")
f = Food("大煎饼")
p.eat(f,False)
总结:将一个类的对象当做参数传递到另一个类中使用 -- 依赖关系
2.组合关系
class Boy:
def __init__(self,name):
self.name = name
def eat(self):
print(f"{self.name}和{self.girl} 一起吃了个烛光晚餐!")
def make_keep(self):
print(f"{self.name}带着{self.girl}去做俯卧撑!")
b = Boy("日魔")
b.girl = "乔bi萝"
# b.eat()
b.make_keep()
class Boy:
def __init__(self,name,g):
self.name = name # self = b
self.g = g # g就是girl类实例化的一个对象内存地址
def eat(self):
print(f"{self.name}和{self.g.age}岁,且{self.g.weight}公斤的{self.g.name}py朋友.一起吃了个烛光晚餐!")
def make_keep(self):
self.g.live(f"{self.g.weight}公斤的{self.g.name}给{self.name}踩背")
class Girl:
def __init__(self,name,age,sex,weight,*args):
self.name = name
self.age = age
self.sex = sex
self.weight = weight
self.args = args
def live(self,argv):
print(f"直播内容:{argv}")
g = Girl("乔毕萝",54,"女",220)
b = Boy("太正博",g)
b.make_keep()
总结: 将一个类的对象封装到另一个类的对象属性中
总结:
依赖关系:将一个类的对象当做参数传递到另一个类中使用 -- 依赖关系
组合关系:将一个类的对象封装到另一个类的对象属性中
8.继承
继承 - 子承父业
程序中 A(B)
A -- 子类,派生类
B -- 父类,基类,超类
class Human:
def __init__(self,name,age,sex):
self.name = name
self.sex = sex
self.age = age
def eat(self):
print("吃")
class Dog:
def __init__(self, name, age, sex):
self.name = name
self.sex = sex
self.age = age
def eat(self):
print("吃")
class Cat:
def __init__(self, name, age, sex):
self.name = name
self.sex = sex
self.age = age
def eat(self):
print("吃")
class Pig:
def __init__(self, name, age, sex):
self.name = name
self.sex = sex
self.age = age
def eat(self):
print("吃")
class Animal: # 父类
"""
动物类
"""
live = "活的"
def __init__(self, name, age, sex):
print("is __init__")
self.name = name
self.sex = sex
self.age = age
def eat(self): # self 是函数的位置参数
print("吃")
class Human(Animal): # 子类
pass
class Dog(Animal): # 子类
pass
通过子类的类名使用父类的属性和方法
Human.eat(12)
Human.__init__(Human,"日魔",18,"男")
print(Human.live)
print(Human.__dict__)
通过子类的对象使用父类的属性和方法
p = Human("日魔",18,"男")
d = Dog("rimo",1,'母')
print(d.__dict__)
print(p.__dict__)
p = Human("日魔",18,"男")
print(p.live)
查找顺序:
不可逆(就近原则)
通过子类,类名使用父类的属性或方法(查找顺序):当前类, 当前类的父类,当前类的父类的父类 --->
通过子类对象使用父类的属性或方法(查找顺序):先找对象,实例化这个对象的类,当前类的父类, --->
## 重要
继承: 单继承,多继承
Python2: python2.2 之前都是经典类,python2.2之后出现了新式类,继承object就是新式类
Python3: 只有新式类,不管你继不继承object都是新式类
继承的优点:
1.减少重复代码
2.结构清晰,规范
3.增加耦合性(不在多,在精)
9.多继承
经典类: (深度优先) 左侧优点,一条路走到头,找不到会到起点向右查询
新式类: (c3算法)
多继承是继承多个父类
经典类: 多继承时从左向右执行
class Immortal(object):
def fly(self):
print("会飞")
# def eat_tao(self):
# print("会遁地")
class Monkey:
def eat_tao(self):
print("吃桃")
def climb_tree(self):
print("会爬树")
class SunWuKong(Immortal,Monkey):
pass
sxz = SunWuKong()
sxz.eat_tao()
class A:
# name = "宝元"
pass
class B(A):
pass
# name = "太正博"
class C(A):
# name = "alex"
pass
class D(B, C):
# name = "日魔22"
pass
class E:
pass
# name = "日魔11"
class F(E):
# name = "日魔"
pass
class G(F, D):
# name = "bb"
pass
class H:
# name = "aaa"
pass
class Foo(H, G):
pass
f = Foo()
print(f.name)
经典类: (深度优先) 左侧优点,一条路走到头,找不到会到起点向右查询
class O(object):
# name = "宝元"
pass
class D(O):
# name = "日魔"
pass
class E(O):
# name = "太正博"
pass
class F(O):
# name = "alex"
pass
class B(D,E):
# name = "三哥"
pass
class C(E,F):
# name = "文刚"
pass
class A(B,C):
# name = "春生"
pass
a = A()
print a.name
新式类: (c3)
mro(Child(Base1,Base2)) = [ Child ] + merge( mro(Base1), mro(Base2), [ Base1, Base2] )
mro(A(B,C)) = [ A ] + merge( mro(B), mro(C), [ B, C])
mro(A(B,C)) = [ A ] + merge([B,D,E,O], [C,E,F,O], [ B, C])
mro(B(D,E)) = [B,D,E,O]
mro(C(E,F)) = [C,E,F,O]
mro(A(B,C)) = [A,B,D,C,E,F,O]
print A.mro()
class A(object):
pass
class B(A):
pass
class C(A):
pass
class F:
pass
class D(B,F):
pass
class E(D,C):
pass
mro(Child(Base1,Base2)) = [ Child ] + merge( mro(Base1), mro(Base2), [ Base1, Base2] )
mro(E(D,C)) = [ E ] + merge( mro(D), mro(C), [ D, C] )
[E,D,B,C,A,F]
经典类不能使用mro 新式类才能使用mro
print(E.mro())
class B:
pass
class V(B):
pass
class F(B):
pass
class A(F,B):
pass
class D(A):
pass
class R(D,A):
pass
[R,D,A,F,B]
"""
mro(Child(Base1,Base2)) = [ Child ] + merge( mro(Base1), mro(Base2), [ Base1, Base2] )
mro(R(D,A)) = [ R,D,A,F,B ]
"""
print(R.mro())
01.meo(c3算法)
"""
mro(Child(Base1,Base2)) = [ Child ] + merge( mro(Base1), mro(Base2), [ Base1, Base2] )
mro(R(D,A)) = [ R,D,A,F,B ]
"""
"""
mro(子类(父类1,父类2)) = [子类] + 子类(父类1(父类的父类),父类2(父类的父类),[父类1,父类2])
"""
计算的时候先匹配头看有没有和头一样的尾部,要是没有就放进列表内。要是有就跳过去看下一个以此类推
10.使用子类和父类方法或属性
class Animal: # 父类
"""
动物类
"""
live = "活的"
def __init__(self, name, age, sex):
# self = p的内存地址
self.name = name
self.sex = sex
self.age = age
def eat(self): # self 是函数的位置参数
print("吃")
方法一: 不依赖(不需要)继承
class Human: # 子类
def __init__(self, name, age, sex, hobby):
# print(Animal.live)
# self = p的内存地址
Animal.__init__(self,name,age,sex)
self.hobby = hobby
class Dog:
def __init__(self, name, age, sex, attitude):
# self = p的内存地址
self.name = name
self.sex = sex
self.age = age
p = Human("日魔",18,"男","健身")
print(p.__dict__)
方法二: 依赖(需要)继承
class Dog(Animal):
def __init__(self, name, age, sex, attitude):
# self = p的内存地址
# super(Dog,self).__init__(name,age,sex) # 完整写法
super().__init__(name,age,sex) # 正常写法
self.attitude = attitude
d = Dog("日魔",18,"男","忠诚")
print(d.__dict__)
def func(self):
self = 3
print(self)
self = 3
func(self)
1
class Base:
def __init__(self, num):
self.num = num
def func1(self):
print(self.num)
class Foo(Base):
pass
obj = Foo(123)
obj.func1()
class Base:
def __init__(self, num):
self.num = num
def func1(self):
print(self.num)
class Foo(Base):
def func1(self):
print("Foo. func1", self.num)
obj = Foo(123)
obj.func1()
class Base:
def __init__(self, num):
self.num = num
def func1(self):
print(self.num)
self.func2()
def func2(self):
print("Base.func2")
class Foo(Base):
def func2(self):
print("Foo.func2")
obj = Foo(123)
obj.func1()
class Base:
def __init__(self, num):
self.num = num
def func1(self):
print(self.num)
self.func2()
def func2(self):
print(111, self.num)
class Foo(Base):
def func2(self):
print(222, self.num)
a = Base(1)
b = Base(2)
c = Foo(3)
lst = [a, b, c]
print(lst)
for obj in lst:
obj.func2()
class Base:
def __init__(self, num):
self.num = num
def func1(self):
print(self.num)
self.func2()
def func2(self):
print(111, self.num)
class Foo(Base):
def func2(self):
print(222, self.num)
lst = [Base(1), Base(2), Foo(3)]
for obj in lst:
obj.func1()
1
111 1
2
111 2
3
222 3
11.面向对象的三大特征
1.继承 √
2.封装 : 将一些代码或数据存储到某个空间中 √
函数,对象,类
3.多态 : Python默认就是多态 √
a = "alex"
a = 100
int a = 100
4.print带色
开头格式: \033[
结尾格式: \033[0m
print('\033[0;35m字体变色,但无背景色 \033[0m') # 有高亮
print('\033[1;35m字体变色,但无背景色 \033[0m') # 有高亮
print('\033[4;35m字体变色,但无背景色 \033[0m') # 有高亮
print('\033[5;35m字体变色,但无背景色 \033[0m') # 有高亮 # 不好使
print('\033[7;35m字体变色,但无背景色 \033[0m') # 有高亮
print('\033[8;35m字体变色,但无背景色 \033[0m') # 有高亮 # 不好使
print('\033[1;32m 字体变色,但无背景色 \033[0m') # 有高亮
print('\033[1;33m 字体变色,但无背景色 \033[0m') # 有高亮
print('\033[1;36m 字体变色,但无背景色 \033[0m') # 有高亮
print('\033[1;32m 字体变色,但无背景色 \033[0m') # 有高亮
print('\033[1;33m 字体变色,但无背景色 \033[0m') # 有高亮
print('\033[1;36;40m 字体变色,但无背景色 \033[0m') # 有高亮
print('\033[1;32;40m 字体变色,但无背景色 \033[0m') # 有高亮
print('\033[1;30;43m 字体变色,但无背景色 \033[0m') # 有高亮
print('\033[1;30;43m 字体变色,但无背景色 \033[0m') # 有高亮
print('\033[0;36m骑牛远远过前村,')
print('短笛横吹隔陇闻。')
print('多少长安名利客,')
print('机关用尽不如君。\033[0m')
12.鸭子类型
鸭子类型(编程思想)
鸭子类型: 当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子。
class Str:
def index(self):
print("啊啊啊")
def walk(self):
print("一步两步")
def do(self):
print("左手右手一个慢动作")
class List:
def index(self):
print("嗯嗯嗯")
def walk(self):
print("一步两步")
def do(self):
print("左手右手一个慢动作")
a = A()
b = B()
a.call()
b.call()
统一接口 ,归一化(规范)
def call(object):
object().call()
call(B)
call(A)
python中 str,list,tuple中很多使用鸭子类型
str.index()
list.index()
tuple.index()
13.类的约束
约束:类(子类)
版一:
class WechatPay:
def pay(self):
print("微信支付")
class AliPay:
def pay(self):
print("支付宝支付")
class QQpay:
def fuqian(self):
print("QQ支付")
qq = QQpay()
qq.fuqian()
wei = WechatPay()
ali = AliPay()
qq = QQpay()
wei.pay()
ali.pay()
qq.fuqian()
def pay(object):
object().pay()
版二
方式一:
class PayClass:
def pay(self):
pass
class WechatPay(PayClass):
def pay(self):
print("微信支付")
class AliPay(PayClass):
def pay(self):
print("支付宝支付")
class QQpay(PayClass):
def fuqian(self):
print("QQ支付")
def pay(object):
object().pay()
pay(QQpay)
版三:
方式一: (推荐并且常用的方式)
raise 主动抛出异常(主动报错)
class PayClass:
def pay(self):
raise Exception("你子类必须要写一个pay方法")
class WechatPay(PayClass):
def pay(self):
print("微信支付")
class AliPay(PayClass):
def pay(self):
print("支付宝支付")
class QQpay(PayClass):
def pay(self):
print("QQ支付")
# def pay(self):
# pass
def pay(object):
object().pay()
pay(QQpay)
方法二
抽象类,接口类: 制定一些规则
from abc import ABCMeta,abstractmethod # 抽象类,接口类
class PayClass(metaclass=ABCMeta): # 元类
@abstractmethod
def pay(self):
raise Exception("你子类必须要写一个pay方法")
class WechatPay(PayClass):
def pay(self):
print("微信支付")
class AliPay(PayClass):
def pay(self):
print("支付宝支付")
class QQpay(PayClass):
def pay(self):
print("QQ支付")
def pay(object):
object().pay()
pay(WechatPay)
pay(AliPay)
pay(QQpay)
qq = QQpay()
qq.pay()
14.类的私有成员
# 私有 : 只能自己有
# 以__开头就是私有内容
# 私有内容的目的就是保护数据的安全性
#其实私有的东西可用特殊的方法查找到:_类名私有的属性和方法
class Human:
live = "有思想" # 类公有的属性
__desires = "有欲望" # (程序级别)类私有的属性
_desires = "有欲望" # (程序员之间约定俗成)类私有的属性
def __init__(self,name,age,sex,hobby):
self.name = name
self.age = age
self.sex = sex # 对象的公有属性
self.__hobby = hobby # 对象的私有属性
def func(self):
# 类内部可以查看对象的私有属性
print(self.__hobby)
def foo(self): # 公有方法
# 类内部可以查看类的私有属性
print(self.__desires)
def __abc(self): # 私有方法
print("is abc")
# print(Human.__dict__)
# print(Human._desires)
# class B(Human):
# pass
# def run(self):
# print(self.__desires)
# self._Human__abc() # 强制继承(非常不推荐使用)
# b = B("日魔",28,"男","女孩子")
# print(b.__desires)
# b.run()
# b._Human__abc()
# _类名私有的属性和方法
# 子类不能继承父类中私有的方法和属性
# 类的外部查看
# print(obj.name)
# print(Human.live)
# Human.live = "无脑"
# print(Human.live)
# obj.__abc()
# print(Human.__desires) # 保证数据的安全性
15.super解析
总结:
1.按照mro的查找顺序进行查找
2.super(类名,self) 从当前mro中查找类名的下一个类
3.super是按照mro的顺序进行继承
class Info(Foo,Bar):
def f1(self):
# super里的类名是指定查找mro中类名的下一个类, self是指定查找时使用的mro顺序
super(Info,self).f1() # Foo() 对象的内存地址 # super(子类名,子类的mro列表)
print('in Info f1')
class A:
def f1(self):
print('in A')
class Foo(A):
def f1(self):
super().f1()
print('in Foo')
class Bar(A):
def f1(self):
print('in Bar')
class Info(Foo,Bar):
def f1(self):
# super里的类名是指定查找mro中类名的下一个类, self是指定查找时使用的mro顺序
super(Info,self).f1() # Foo() 对象的内存地址 # super(子类名,子类的mro列表)
print('in Info f1')
aa = Info() # 对象的内存地址
aa.f1()
[Info', Foo', Bar', A', 'object']
a = Foo()
b = a
print(a)
print(b)
print(Info.mro())
obj = Info()
obj.f1()
class A:
def f1(self):
print('in A f1')
def f2(self):
print(self)
print('in A f2')
class Foo(A):
def f1(self):
super(Foo,self).f2() # 查找当前类(Foo)的下一个类
# A.f2()
# [Foo --> A ---> object]
print('in A Foo')
obj = Foo()
obj.f1()
class A:
def f1(self):
print('in A')
class Foo(A):
def f1(self):
super().f1()
print('in Foo')
class Bar(A):
def f1(self):
print('in Bar')
class Info(Foo,Bar):
def f1(self):
super(Foo,self).f1()
print('in Info f1')
# [Info -- Foo -- Bar -- A]
obj = Info()
obj.f1()
16.类的其他成员
之前在类内部定义的方法(位置参数为self)的方法叫做实例方法
1.实例方法
class a():
def sl(self):
print("这是示例方法")
2.类方法
@classmethod
class b():
def l(cls):
print("这是类方法")
3.静态方法
@staticmathod
class c():
def jt():
print("这是静态方法")
# 1.类的其他成员
# 实例方法
# 依赖对象,不需要装饰器装饰,方法的参数是self
# 类方法
# @classmethod : 依赖类 被classmethod装饰器装饰的方法参数是cls
# 静态方法
# @staticmethod : 不依赖对象和类 就是一个普通的函数
1.类方法
class A:
def func(self): #实例方法
print("is A func")
# a = A() # 实例化 一个对象(实例)
A.func() # 添加参数
a.func()
import time
class Times:
t = time.time() # 类属性
@classmethod
def func(cls):
print(cls) # 类的地址
print("is A func")
# object = cls()
# object = cls()
cls.t = 1010101
a = A()
a.func()
Times.func()
print(Times.t)
class Human:
count = 0
def __init__(self, name, age):
self.name = name
self.age = age
@classmethod
def add_count(cls):
cls.count += 1
@classmethod
def get(cls):
return cls.count
Human("日魔",56)
Human("日魔",56)
Human("日魔",56)
Human("日魔",56)
Human("日魔",56)
Human("日魔",56)
Human("日魔",56)
Human("日魔",56)
Human("日魔",56)
Human("日魔",56)
print(Human.get())
类方法可以自动变换类名 (最大的作用)
1.使用类方法可以获取到类地址进行实例化
2.可以通过类名修改类属性
类方法偶然会使用,使用最多的还是实例方法
2.静态方法 (使用更少)
class A:
def func(self): # 实例方法
print("is A func")
@classmethod
def cls_func(cls): # 类方法
print("is A cls_func")
@staticmethod
def static_func():
print("他就是普通的函数了")
静态方法不依赖于对象和类 (静态方法就是一个普通的函数)
def static_func():
print("他就是普通的函数了")
A.static_func()
a = A()
a.static_func()
17.属性
class a():
@property
def h(self):
print("伪装属性")
@h.setter
def h(self,a):
print("设置属性")
@h.getter
def h(self):
print("查看属性")
@h.deleter
def h(self):
print("删除属性")
属性: 组合(伪装)
class A:
live = "有思想"
def func(self):
print("is A func")
A.live
A.func()
class A:
@property
def func(self):
print("is A func")
a = A()
a.func
BMI 人体体质指标
BMI = 体重(kg) / (身高(m) ** 2)
class Bmi:
live = "有思想"
def __init__(self, height, weight):
self.height = height
self.weight = weight
@property
def bmi(self):
return self.weight / self.height ** 2
@bmi.setter
def bmi(self,value):
print(value)
print("设置属性时执行我")
@bmi.getter
def bmi(self):
print("查看属性时执行我")
@bmi.deleter
def bmi(self):
print("删除属性时执行我")
rimo = Bmi(1.8,100)
print(rimo.live) # 真属性
rimo.live = "无脑"
del Bmi.live
print(rimo.live)
print(rimo.bmi)
print(Bmi.__dict__)
rimo.bmi = 20 # 伪装成属性进行设置
print(rimo.bmi) # 伪装成属性
del rimo.bmi
class Bmi:
live = "有思想"
def __init__(self, height, weight):
self.height = height
self.weight = weight
@property
def bmi(self):
return self.weight / self.height ** 2
@bmi.setter
def bmi(self,value):
print(value)
print("设置属性时执行我")
@bmi.getter
def bmi(self):
print("查看属性时执行我")
@bmi.deleter
def bmi(self):
print("删除属性时执行我")
rimo = Bmi(1.8,100)
print(rimo.live) # 真属性
class Foo:
def get_AAA(self):
print('get的时候运行我啊')
def set_AAA(self,value):
print('set的时候运行我啊')
def delete_AAA(self):
print('delete的时候运行我啊')
AAA = property(get_AAA,set_AAA,delete_AAA) #内置property三个参数与get,set,delete一一对应
f1=Foo()
f1.AAA
f1.AAA = 'aaa'
del f1.AAA
18.type元类
元类 -- 构建类
object与type的关系 (了解)
1.object是type的对象
2.新式类都默认继承object
print(issubclass(type,object)) # type是object的子类
print(isinstance(object,type)) # object是type的对象
python大部分自带的类和自己定义的类都是由type类实例化出来的
python中一切皆对象
issubclass() # 判断参数1是不是参数2的子类
isinstance() # 判断参数1是不是参数2的对象
object 和 type 的关系
object 是 type 的对象
type 是 object 的子类
type 查看数据类型 (能够查看出当前内容从属于那个类)
print(type("alex"))
print(type([1,2,3,4]))
print(type((1,2,3,40)))
python自带的类
class A:
pass
a = A()
print(type(a))
print(type(A))
print(type(str))
print(type(list))
print(type(tuple))
print(type(object))
python自带的 str,list,tuple 也是某一个类的对象 (python中一切皆对象)
isinstance 判断参数1是不是参数2的对象
print(isinstance([1,2,3],list))
print(isinstance(str,type))
print(isinstance(list,type))
print(isinstance(object,type))
issubclass 判断参数1是不是参数2的子类
class A:
pass
class B(A):
pass
print(issubclass(B,A))
19.反射
# 通过字符串操作对象的属性和方法
# 1.对象的角度使用反射
# 2.类的角度使用反射
# 3.当前模块使用反射
# 4.其他模块使用反射
# 模块部分使用反射的方式:
# 方法一:
# import sys
# sys.modules[__name__]
# 方法二:
# globals()[__name__]
# hasattr(对象,字符串)
# getattr(对象,字符串,查找不到的返回值)
# setattr(对象,字符串,值)
# delattr(对象,字符串)
# hasattr() 及 getattr() 配合使用
# if hasattr():
# getattr()
python中一切皆对象
反射:(自省)
通过字符串操作对象的属性和方法
class A:
def __init__(self,name):
self.name = name
def func(self):
print("is A func")
a = A("rimo")
A.func()
print(a.name)
a.func()
反射(组合) -- # 通过字符串操作对象的属性和方法
getattr() # 获取
setattr() # 设置
hasattr() # 判断是否存在
delattr() # 删除
对象:
print(hasattr(a,"name")) # 返回 True就是说明name这个属性在对象a中存在
print(getattr(a,"name"))
f = getattr(a,"func")
f()
setattr(a,"age",18)
print(a.__dict__)
delattr(a,"name")
print(a.__dict__)
类:
class A:
def __init__(self,name):
self.name = name
def func(self):
print("is A func")
a = A("rimo")
print(hasattr(A,"name"))
f = getattr(A,"func")
f(11)
def func():
print("is func")
当前模块:
print(globals()["func"])
import sys
o = sys.modules[__name__] # 获取当前模块名对应的对象
f = getattr(o,"func")
f()
其他模块
import test
test.func()
o = globals()["test"]
getattr(o,"func")()
反射的应用场景:
class Blog:
def login(self):
print("is login")
def register(self):
print("is register")
def comment(self):
print("is comment")
def log(self):
print("is log")
def log_out(self):
print("is log_out")
b = Blog()
func_dic = {
"1":b.login,
"2":b.register,
"3":b.comment,
"4":b.log,
"5":b.log_out
}
msg = """
1.登录
2.注册
3.评论
4.日志
5.注销
"""
choose = input(msg)
if choose in func_dic:
func_dic[choose]()
class Blog:
def login(self):
print("is login")
def register(self):
print("is register")
def comment(self):
print("is comment")
def log(self):
print("is log")
def log_out(self):
print("is log_out")
b = Blog()
msg = """
login
register
comment
log
log_out
"""
while 1:
choose = input(msg)
if hasattr(b,choose):
getattr(b,choose)()
else:
print("请重新输入!")
class Blog:
def login(self):
print("is login")
def register(self):
print("is register")
def comment(self):
print("is comment")
def log(self):
print("is log")
def log_out(self):
print("is log_out")
b = Blog()
msg = """
login
register
comment
log
log_out
"""
while 1:
choose = input(msg)
if choose == "login":
b.login()
elif choose == "register":
b.register()
elif choose == "comment":
b.comment()
...
hasattr *****
getattr *****
setattr ***
delattr **
if hasattr(b,"func"):
getattr(b,"func")
20.双下方法
双下方法:给源码程序员使用,咱们慎用 (以便你们更好的阅读源码)
__len__
class A(object):
def __init__(self,name):
self.name = name
print("触发了__init__")
def __len__(self): # len() 触发
print("走这里")
return len(self.name) # return len("alex") str中__len__
# 必须有返回值,返回值的类型必须是整型
a = A("alexqrqwr")
print(len(a))
str
a = "12345" # str这个类的实例
lst = [1,2,3,4,4,5,5,5,5] # list这个类的实例
print(len(a))
print(len(lst))
__hash__ hash()触发
class A(object):
def __init__(self,name,age):
self.name = name
self.age = age
def __hash__(self): # hash()
hash({1,2,345}) # 可变数据类,不可数据类型
# 必须有返回值,返回值的类型必须是整型
a = A("meet",25)
print(hash(a))
__str__ *** Django
class A:
def __init__(self,name,age,sex):
self.name = name
self.age = age
self.sex = sex
def __str__(self): # print 触发 str()
print(111)
return f"姓名:{self.name} 年龄:{self.age} 性别:{self.sex}"
# 必须有返回值,返回值的类型必须是字符串
a = A("meet",20,"男")
a1 = A("meet11",200,"男11")
str(a)
print(a)
print(a1)
a = A("meet",20,"男")
a1 = A("meet2",200,"女")
print(f"姓名:{a.name} 年龄:{a.age} 性别:{a.sex}") # "姓名:meet 年龄:20 性别:男"
print(f"姓名:{a1.name} 年龄:{a1.age} 性别:{a1.sex}") # "姓名:meet2 年龄:200 性别:女"
__repr__
class A:
def __init__(self):
pass
def __repr__(self): # print触发 %r
print(1111)
return "日魔"
def __str__(self): # str 优先级高于 repr 两个都存在就只执行str
return "宝元"
a = A()
print("%r"%(a))
__call__ *** 面试题
class A:
def __init__(self):
pass
def __call__(self, *args, **kwargs): # 对象()时调用的__call__
print("走我")
print(*args, **kwargs)
a = A()
a()
__eq__ # 等于
class A(object):
def __init__(self,name,age):
self.name = name
self.age = age
def __eq__(self, other): # a == a1
if self.name == other.name:
return True
else:
return False
a = A("meet",56)
a1 = A("meet",108)
print(a == a1)
__del__ 析构方法
class A:
def __init__(self):
pass
def __del__(self): del 触发
print("删除时执行我")
a = A()
import time
time.sleep(5)
del a
a = 1
b = a
a = b
垃圾回收
80 5/s
引用计数
标记清除
分袋回收 袋一:10 2/h 袋二: 5/3 4h 袋三: 3 20h
__new__ 单例模式(面试必问) # 工厂模式 等等
class A(object):
def __init__(self,name): # 初始化
self.name = name
print("我是__init__,先走我")
def __new__(cls, *args, **kwargs):
obj = object.__new__(A)
print("我在哪:",obj)
return obj # obj == __init__()
# print("我是__new__,先走我")
# return "啦啦啦"
a = A("meet")
print("我是谁:",a)
class A:
def __init__(self):
print(1111)
a = A()
print(a)
class A(object):
def __init__(self,name): # 初识化
self.name = name
def __new__(cls, *args, **kwargs):
obj = object.__new__(A) # 调用的是object类中的__new__ ,只有object类中的__new__能够创建空间
return obj #本质: obj == __init__() return __init__() # 触发了__init__方法
# print("先执行的是我")
# return "宝元"
a = A("meet") # a是对象的内存地址
a1 = A("日魔") # a是对象的内存地址
a2 = A("朝阳") # a是对象的内存地址
print(a.name)
print(a1.name)
print(a2.name)
先执行__new__方法在执行__init__方法
class A:
__a = None #__a = 0x000001F346079FD0
def __init__(self,name,age):
self.name = name
self.age = age
def __new__(cls, *args, **kwargs):
if cls.__a is None:
obj = object.__new__(cls)
cls.__a = obj
return cls.__a
a = A("meet",123) # 0x000001F346079FD0
a1 = A("日魔",11)
print(a.name)
print(a1.name)
单例模式:不管你创建多少次,使用的都是同一个内存空间
模块的导入,手写的单例模式
实例化对象时发生的事
1.创建对象,并开辟对象空间 __new__
2.自动执行__init__方法
__item__ 可以向操作字典一样操作实例方法
dic["键"] = 值
del dic["键"]
dic["键"]
class A:
def __init__(self,name,age):
self.name = name
self.age = age
def __getitem__(self, item):
print(self.__dict__)
print(self.__dict__[item]) # self.__dict__ 获取的就是字典
def __setitem__(self, key, value):
self.__dict__[key] = value
def __delitem__(self, key):
del self.__dict__[key]
a = A("meet",58)
a["sex"] = "男"
a["sex"]
del a["sex"]
print(a.__dict__)
了解一下上下文
__enter__
__exit__
class my_open:
def __init__(self,file,mode="r",encoding="utf-8"):
self.file = file
self.mode = mode
self.encoding = encoding
def __enter__(self):
self.f = open(self.file,self.mode,encoding=self.encoding)
return self.f
def __exit__(self, exc_type, exc_val, exc_tb):
print(exc_type,exc_val,exc_tb) # 没有错误时就是None
self.f.close()
with my_open("a.txt") as ffff:
for i in ffff:
print(i)
print(ffff.read(1111))
print(ffff.read())
with open("a") as f: 使用了上下文
21.异常处理
错误:
1.语法错误
print(111
[1;2;3;4]
2.逻辑错误
lst = [1,2,3]
lst[5]
dic = {"key":1}
dic["name"]
print(a)
print(111
1 + "alex"
int("alex")
name = "alex"
def func():
print(name)
name = "a"
func()
什么异常?
除去语法错误的就是异常
异常划分的很细
常用,更多
异常处理:
处理异常:
1. if
num = input(">>")
if num.isdecimal():
int(num)
if len(num) == 0:
pass
if 处理一些简单的异常,if异常处理的方式
2. try
try: # 尝试
int("alex")
except ValueError:
"""其他代码逻辑"""
为什么要用异常处理?
1.出现异常,异常下方的代码就不执行了(中断了)
2.用户体验不良好
异常处理:
检测到异常后"跳"过异常及异常下发的代码
try:
[1,2,3][7]
print(111)
dic = {"key":1}
dic["name"]
except Exception:
pass
异常分支:
根据不同分支,执行不同逻辑
try:
int(input("请输入数字:"))
except ValueError as e:
print(e)
# print(34533)
int(input("请输入数字:"))
try:
int(input("请输入数字:"))
except Exception as e:
print(e)
int(input("请输入数字:"))
分支 + 万能 + else + finally
try:
num = int(input("请输入数字:"))
lst = [1,2,3]
# dic = {"name":"meet",1:"rimo"}
# print(dic[num])
print(lst[num])
except ValueError as e:
print(e)
except KeyError as e:
print(f"没有{e}这个键")
except IndexError as e:
print(e)
except Exception as e:
print(e)
else:
print("都没有错,走我!")
finally:
print("有错没有错,都走我!,清理工作")
class EvaException(BaseException):
def __init__(self,msg):
self.msg = msg
def __str__(self):
return self.msg
try:
a = EvaException('类型错误')
raise a
except EvaException as e:
print(e)
断言
assert 条件
assert 1 == 1
if 1 == 1:
print(111)
assert 1 == 2
if 1 == 2:
print(222)
分支 + 万能 + else + finally