机器学习中岭回归、LASSO回归和弹性网络与损失函数
今天咱们来聊点纯技术的东西,这东西是基础,不说往后没法说,在机器学习领域中,我们可以通过正则化来防止过拟合,什么是正则化呢?常见的就是岭回归、LASSO回归和弹性网络。
先说说什么叫做过拟合?咱们看下图

左1叫欠拟合,中间的拟合得比较好,右1就是过拟合了,因为它对局部过于重视,导致图形边界太复杂,我们不能为了拟合而拟合,像右1这种情况在本数据肯定拟合得很好,但是换个数据就不行了,所以过拟合没有啥实用性。下面这张对数据分类得也是一样的
图二:
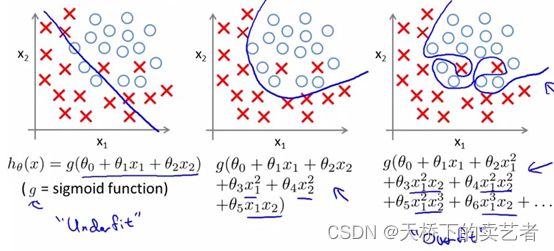
我们可以看到为了增加拟合度,上图右1得算法是多么得复杂。正则化得目的就是抑制复杂得算法来达到过拟合得目的。主要是通过一个惩罚函数将模型得系数进行压缩来实现。在这之前我们还是先聊下最小二乘法和损失函数。
最小二乘法在统计学和机器学习中应用非常广泛。
下图中有4个红点,我们需要拟合这4个点得趋势,那么我们需要找到一条线,假设我们已经找到了,就是下图蓝色线。那么红点得位置得Y就是Y得实际值,同X轴中蓝线的Y的值就是Y的预测值,这样说可以理解吧。Y的实际值和Y的预测值之间的差值,就是我们的误差,在统计学中也叫残差,就是绿色的部分。

那么我们怎么找到一条最合适的拟合4个点的趋势的线呢,就是
Y1(实际值)-Y1(误差值)+ Y2(实际值)-Y2(误差值)+ Y3(实际值)-Y3(误差值)+ Y4(实际值)-Y4(误差值)等于最小的时候。
也就是所有绿色线长度加起来最小的时候。因为有时候实际值减去平均值可能会有负值,所以我们把他们的差值进行平方后再相加,就是
(Y1(实际值)-Y1(误差值))2+ (Y2(实际值)-Y2(误差值))2+ (Y3(实际值)-Y3(误差值))2+ (Y4(实际值)-Y4(误差值))2
在数据统计中我们可以使用Y_i来表示Y的实际值,Y_i表示预测值,Σ为累加的意思,表示这些项式的的加和,可以使用下面的公式来表示

在机器学习中以最优化参数组合的函数称为损失函数。在本例中,我们的平方和这个函数就是损失函数,其实就是误差达到最小的函数。我们求出一条线,使得所有的平方和达到最小,就是我们最合适的拟合线。
刚才那种情况是比较简单的,复杂的时候,如图二右一这种情况,为了达到损失函数最小,可能会出现过拟合。我们常见的用来防止过拟合的正则化有岭回归,LASSO回归和弹性网络。现在咱们线来聊下岭回归。
岭回归就是在刚才的损失函数①中加入了一个惩罚函数,叫L2范数,就是β平方后进行累加,然后乘以系数λ。这里需要注意下这里的系数不包含截距项。

加入了L2范数后,损失函数的公式就是如下:
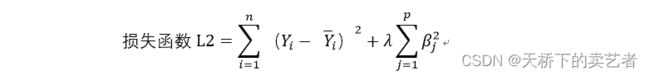
我们可以看到在L2范数中加入了λ这个参数后,如果模型中的β很多的话,β平方后进行累加这个值就会增大,这个时候λ就可以对β平方后进行累加的和进行压缩,优化咱们的损失函数。λ这个函数属于超参数,数据中是无法估计出来的,只能在不断的模型交叉验证中不断迭代后,得出一个最佳的λ。我们既往的文章《手把手教你使用R语言做LASSO 回归》中我们可以看到下图(下图是LASSO 回归生成,但是原理是一样的)

其实就是一个λ不断变大,交叉验证,然后获得最优性能的一个过程,在这个过程中可以看到系数被压缩。
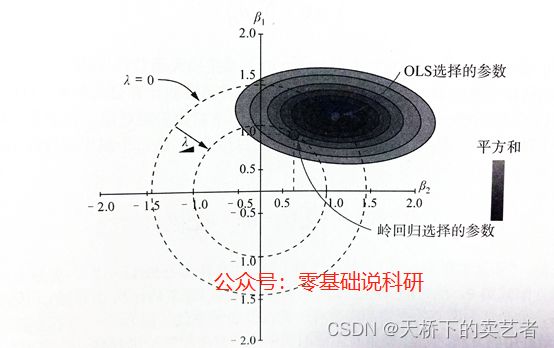
由上图我们可以发现,当λ=0时β1和β2的系数都是1.5这样,当λ进一步向圈内压缩,β1和β2的系数变小,岭回归选择的点β2的系数已经被压缩到0.6这样,因此使用岭回归避免了训练模型对数据的过拟合。
接下来咱们聊聊LASSO回归,它和岭回归有什么不同呢?岭回归使用的是L2范数,而LASSO使用的是L1范数,公式如下:

岭回归的范数是β系数平方累加,而LASSO则是β系数的绝对值进行累加,下面是LASSO回归损失函数的公式
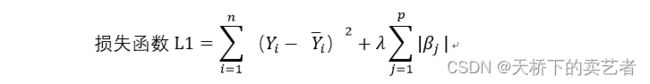
那么问题来了,这两个函数有什么不同呢?岭回归会压缩系数,但是系数不会压缩到0,但是LASSO回归是可以将系数压缩到0的。从而可以帮我们进行指标筛选。
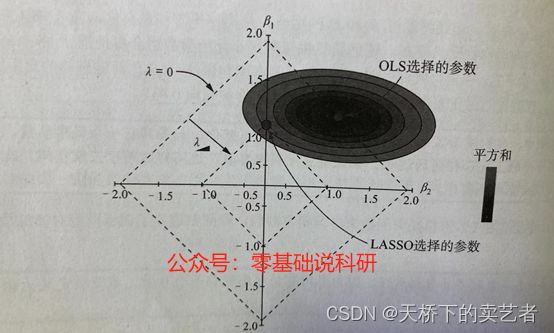
我们可以看到岭回归的惩罚函数是圆形,而LASSO回归的惩罚函数是菱形的,在同样的λ岭回归中β2的系数是0.6这样,而LASSO回归中β2的系数是0,表明β2已经被移除了。
最后咱们来聊聊什么是弹性网络,弹性网络等于把岭回归和LASSO回归进行了打包组合,它的公式如下:

由此可见弹性网络引入了α这个超参数,当α为0的时候,弹性网络就等于岭回归,当α等于1的时候,它就等于LASSO回归。因此它就具有了岭回归和LASSO回归的优点,更受欢迎。
说到这里,理论基本结束了,说理论真费时间。下面我们来结合glmnet包和我的《手把手教你使用R语言做LASSO 回归》这篇文章回看一下,
我们线看下glmnet包中glmnet函数的参数的解释,

主要看参数alpha 这个参数,1是lasso而0是ridge penalty,是不是和我们的弹性网络很相似

接着咱们来看下LASSO中生成压缩系数的图
cvfit=cv.glmnet(x,y)
plot(cvfit)

我们可以看到cv.glmnet函数生成了这个λ变化的MSE的图,

我们可以看到cv.glmnet函数就是一个交叉验证的函数,它是通过提供的λ值来计算MSE最后得到一个最优解。印证了我们上面说的内容。
最后总结一下,咱们今天初步介绍了岭回归、LASSO回归和弹性网络与损失函数,损失函数是机器学习中的重要内容,不说这个后面没方法说。后续有空咱们介绍一下怎么R语言手动推导逻辑回归或者线性回归的结果。了解了原理,回归怎么生成结果的,很多问题R中的问题迎刃而解,比如说下面这种报错:1: glm.fit:算法没有聚合 2: glm.fit:拟合機率算出来是数值零或一


这些都是模型没有收敛导致的,有空再聊。