Hadoop之部署HDFS
下载hadoop
首先进入Hadoop官网 Apache Hadoop
选择download进入下载页面

选择你要下载的版本,这里选择的是最新版的二进制包(一般都选择二进制的)
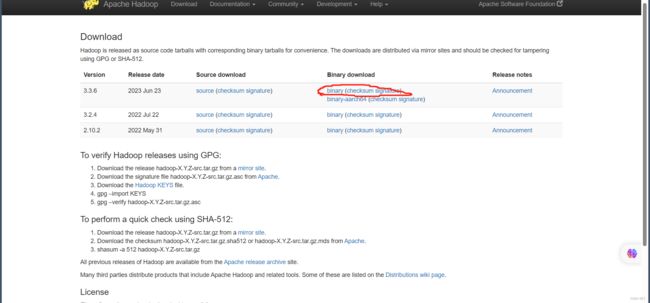
点击 binary进入下一个页面
这个页面里圈起来的三个链接都可以进行下载,推荐用的是第一个链接
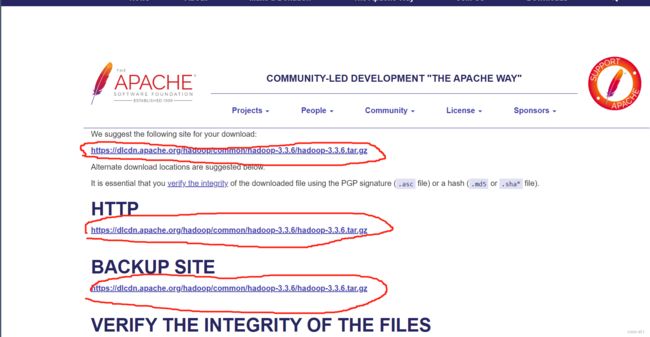
P:apache是外网,下载速度对网络环境有要求,速度慢的小伙伴可以从网盘里直接提取哦
链接:https://pan.baidu.com/s/1VCD63Uj-moKoOcdK8cIulQ?pwd=51as
提取码:51as
创建集群
首先需要在VMware创建一个虚拟机
创建完成后,右键虚拟机,选择管理-克隆
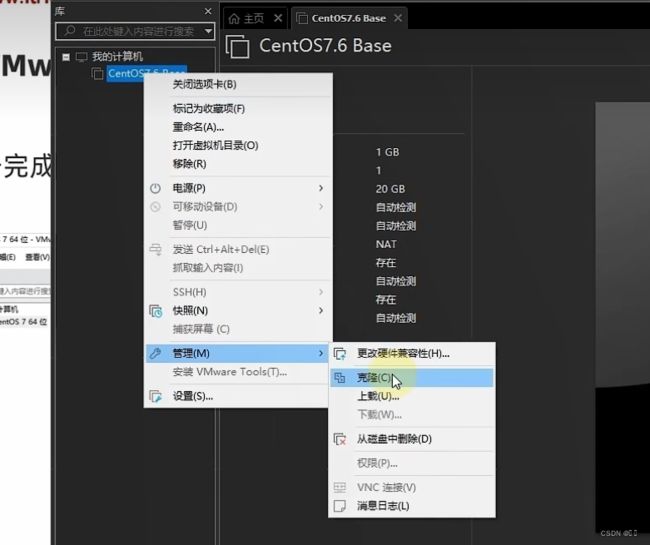
点击下一步。到选择克隆类型时选择完整克隆

这里将虚拟机名称为node1

点击完成后,node1克隆成功,再按照上述过程克隆node2,node3即可
点击node1 选择内存,为其分配内存为4g
点击node2 选择内存,为其分配内存为2g
点击node3 选择内存,为其分配内存为2g
打开node1 的终端
进入root模式,修改主机名

修改IP地址
进入vim /etc/sysconfig/network-scripts/ifcfg-ens33进行修改
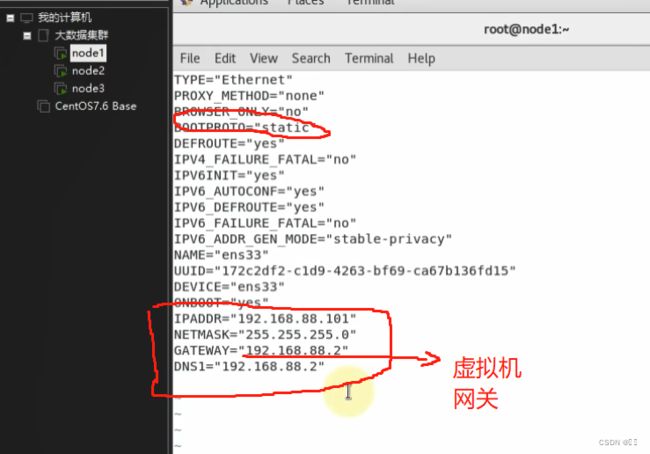
然后重启网卡

上述操作在node2,node3依次执行
node2 的ip改为192.168.88.102
node3 的ip改为192.168.88.103
配置主机名映射
按照以下路径找到hosts文件,并以管理员的身份打开,添加以下内容保存


在虚拟机node1,node2,node3依次进行修改
vim /etc/hosts
192.168.88.101 node1
192.168.88.102 node2
192.168.88.103 node3SSH免密登录
在进行第二步时,需要输入yes和root的密码


创建hadoop用户并配置免密登录

配置JDK环境
Java Downloads | Oracle 中国
选择对应的jdk安装包,这里用的是jdk1.8
链接:https://pan.baidu.com/s/1lX-7WAxIhh334FqSI4Tdjw?pwd=51as
提取码:51as
首先可以创建一个文件夹来部署jdk


node1部署完成后,将jdk安装包复制给node2,node3,在node1中执行以下命令,然后再在node2和node3依次执行上述命令
注:先用 ll 命令查看jdk的名称,这里是jdk1.8.0_361,不一样的将下述命令的jdk名称改成自己的,复制node3就把下述命令的node2改成node3

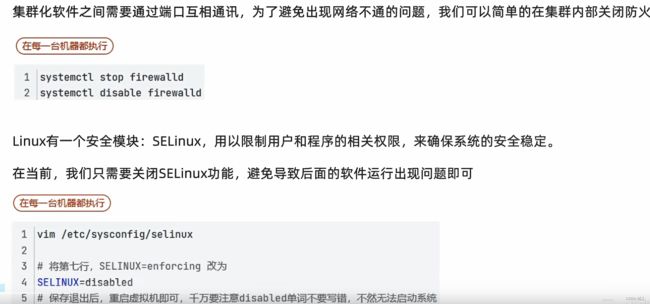
关闭防火墙和SELinux
每台机器分别执行下述命令,执行完成执行 init 6 重启
修改时间并同步时间


快照保存
每次部署完后都可以进行一个快照,以便日后修改出错时可以回到最初的完好配置,而不需要在一步步的配置了

HDFS部署
三台虚拟机部署完成后,
可以将HDFS的角色按以下分配

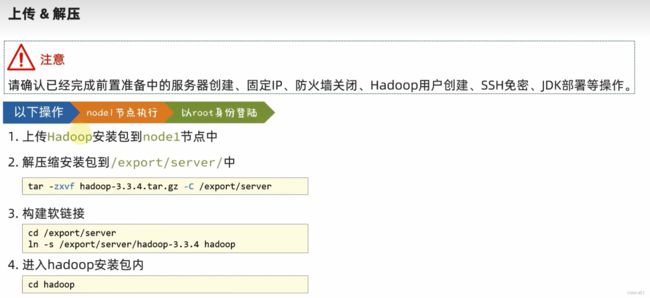
开始进行Hadoop安装包的上传和解压
上传过程中可以在finalshell中打开虚拟机后直接将安装包拖入即可
注: 要在node1中执行,并以root登录
hadoop安装包目录结果
进行配置文件修改
配置workers文件
在finalshell中以此输入以下命令
注:vim workers 进入编辑页面,i进入写模式,esc退出写模式,shift+:进入底部,wq保存退出
编辑页面仅留node1 node2 node3


配置hadoop-env.sh文件
输入命令
vim hadoop-env.sh进入编辑页面,在编辑页面添加以下命令
注:仅在空白地方添加以下命令,不要删除本来的内容

配置core-site.xml文件
输入命令
vim core-site.xml进入编辑页面,先找到configuration

在两个configuration中间添加对应内容

配置hdfs-site.xml文件
输入命令
vim hdfs-site.xml添加以下内容

准备数据目录
在node1添加
mkdir -p /data/nn
mkdir -p /data/dn在node2 node3 添加
mkdir -p /data/nn

分发hadoop文件夹
在node1执行以下命令
cd /export/server
scp -r hadoop-3.3.6 node2:`pwd`/
scp -r hadoop-3.3.6 node3:`pwd`/在node2执行,为hadoop配置软连接
ln -s /export/server/hadoop-3.3.6 /export/server/hadoop在node3执行,为hadoop配置软连接
ln -s /export/server/hadoop-3.3.6 /export/server/hadoop配置环境变量
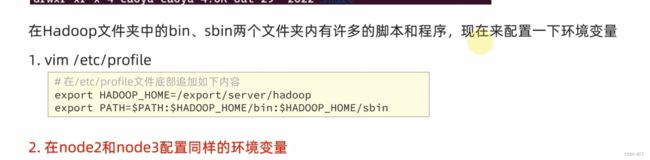
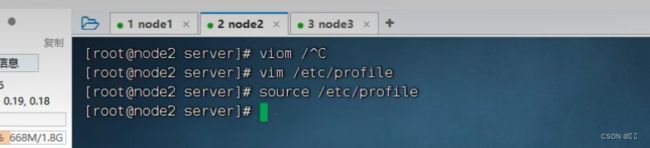
配置好后在node1到node3依次执行source保存
source /etc/profile
授权为hadoop用户

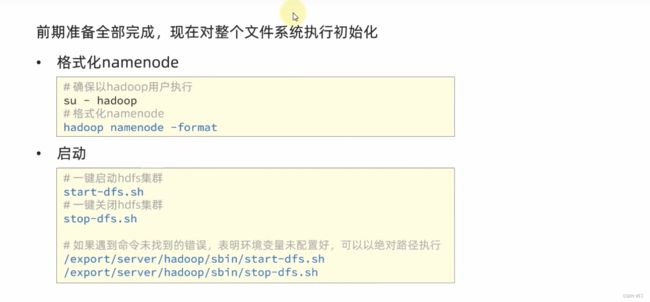
格式化整个文件系统
先切换到hadoop用户
启动Hadoop后,可以在浏览器打开
