【Java集合】一文快速了解HashMap底层原理
目录
一、HashMap底层的数据结构(简单讲解原理)
1.1 当我们向HashMap存入一个元素的时候
1.2 当我们取获取这个元素的时候
二、JDK 1.8中对hash算法和寻址算法是如何优化的?
2.1 hash算法优化
2.1.1 hash算法的作用
2.1.2 hash算法的内容
2.2 寻址算法优化
2.2.1 寻址算法的作用
2.2.2 寻址算法的内容
2.3 hash算法优化前后对比分析
2.4 总结
三、HashMap如何解决hash碰撞问题
3.1 jdk1.8之前
3.2 jdk1.8之后
变为红黑树的触发条件
四、HashMap是如何进行扩容的
4.1 扩容的触发条件
4.1.1 为什么扩容是0.75
4.2 扩容的时候rehash问题
一、HashMap底层的数据结构(简单讲解原理)
hashMap的底层原理其实就是一个数组
HashMap map = new HashMap();
map.put(“张三”, “测试数据”);
map.put(“李四”, “测试数据”);
{
“张三”: “测试数据”,
“李四”: “测试数据”
} 1.1 当我们向HashMap存入一个元素的时候
对key张三计算出来一个hash值,根据这个hash值对数组进行取模,就会定位到数组里的一个元素中去
[<>, <>, <>, <>,<张三, 测试数据>, <>,<>,<李四, 测试数据>,<>, <>, <>, <>,<>, <>, <>, <>]假设可以放16个元素,将hash值与16取模,得到一个index为4,然后这个数据就被放到数组下标为index的位置
array[4] = <张三, 测试数据>1.2 当我们取获取这个元素的时候
map.get(“张三”) -> hash值 -> 对数组长度进行取模 -> return array[4]
上面就是HashMap大概的一个原理,当然其底层的源码本身是要更加复杂的,实现起来没有上面说的这么简单。
二、JDK 1.8中对hash算法和寻址算法是如何优化的?
map.put(“张三”, “测试数据”)
对“张三”这个key计算他的hash值,是有一定的优化的
2.1 hash算法优化
2.1.1 hash算法的作用
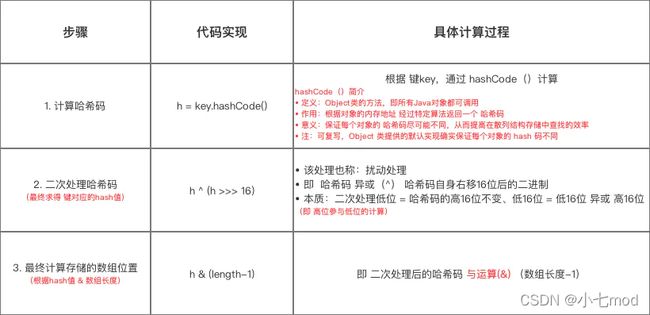
HashMap的hash算法主要是在向Map中存取元素的时候起作用,在向Map存放数据的时候会先对键值对的key值进行取hash值(注意,这里的取hash值不是直接通过调用hashCode()方法,而是通过HashMap自己的获取has值的算法来获得),得到这个hash值后,就可以再通过寻址算法来获得要将这个元素放到HashMap中数组的什么位置。
在HashMap中获取元素的时候也是先通过这个HashMap的hash算法获得一个key的hash值,然后再通过寻址算法来定位到元素所在的位置,从而获取到元素。
2.1.2 hash算法的内容
下面这个代码就叫做扰动处理函数
JDK 1.8 的 hash 方法 相比于 JDK 1.7 hash 方法更加简化,但是原理不变。
static final int hash(Object key) {
int h;
// key.hashCode():返回散列值也就是hashcode
// ^ :按位异或
// >>>:无符号右移,忽略符号位,空位都以0补齐
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}对比一下 JDK1.7 的 HashMap 的 hash 方法源码。
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}在计算hash值的时候,JDK1.7用了9次扰动处理=4次位运算+5次异或,而JDK1.8只用了2次扰动处理=1次位运算+1次异或。这样1.8的执行效率更高。
jdk1.8中HashMap的hash算法流程就是将key调用hashCode的获得hash值与该值右移16位后的值进行异或运算,得出来的结果就是HashMap的hash算法得出的hash值。(异或,不一样是1,一样是0)
比如说:有一个key的hashCode()获取到的hash值如下
1111 1111 1111 1111 1111 1010 0111 1100(原hash值)
0000 0000 0000 0000 1111 1111 1111 1111(右移16位)
1111 1111 1111 1111 0000 0101 1000 0011 ->求异或得到这个二进制结果转换成一个int的Hash值,int正好是32位其实就相当于了原key的hashCode()获取的hash值的高16位与低16位做异或运算,然后的得到的结果就是HashMap的hash值。原hash值的高16位和低16位都参与了运算,这样就保留了原hash值高低16位的全部特征。这样做的原因我们在下一章节与寻址算法结合在一起进行对比分析。
以上就是HashMap的hash算法的内容,当获取到hash值之后,就可以进行后面的步骤。
1、比如HashMap的数组只能放16个元素的话:
[16个元素] -> hash值对数组长度取模,定位到数组的一个位置,将元素添加进去
2、如果两个不同元素的key的hash值一样的话:
hash值一样 -> 他们其实都会在数组里放在一个位置,进行复杂的hash冲突的处理
上面这两条就分别对应着HashMap寻址算法和HashMap解决hash碰撞这两个知识点。
2.2 寻址算法优化
2.2.1 寻址算法的作用
当通过hash算法出HashMap的key的hash值之后,就需要再通过寻址算法来确定该元素要存放在数组的什么位置。其实就需要将这个hash值对数组长度进行一个取模,这样就能得到要存放的位置,但是HashMap对寻址算法进行了一些优化,并不是简单的直接将hash值与数组长度进行取模,而是将hash值和(数组长度 - 1)进行与运算,得到的结果就是该元素要存放的位置。
取模运算,它是性能比较差一些,为了优化这个数组寻址的过程,就改成了与运算,与运算的性能远大于取模运算。当数组的长度n是2^n时,hash & (n - 1) 的结果跟hash对n取模的结果是一样的,但是与运算的性能要比hash对n取模要高很多,这也就要求HashMap的数组的长度需要一直保持是2的n次方。这也就解释了HashMap数组的长度为什么是2的幂次方。
HashMap 的长度为什么是 2 的幂次方?
为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀。Hash 值的范围值-2147483648 到 2147483647,前后加起来大概 40 亿的映射空间,只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个 40 亿长度的数组,内存是放不下的。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来要存放的位置也就是对应的数组下标。这个数组下标的计算方法是“ (n - 1) & hash”。(n 代表数组长度)。这也就解释了 HashMap 的长度为什么是 2 的幂次方。
这个算法应该如何设计呢?
我们首先可能会想到采用%取余的操作来实现。但是,重点来了:“取余(%)操作中如果除数是 2 的幂次则等价于与其除数减一的与(&)操作(也就是说 hash%length==hash&(length-1)的前提是 length 是 2 的 n 次方;)。” 并且 采用二进制位操作 &,相对于%能够提高运算效率,这就解释了 HashMap 的长度为什么是 2 的幂次方
2.2.2 寻址算法的内容
hash & (n - 1) -> 数组里的一个位置

2.3 hash算法优化前后对比分析
我们现在已经知道了优化之后的hash算法和寻址算法,下面我们就来解决一下前面遗留下来的问题,jdk1.8之后HashMap对hash算法进行优化,这样的优化写法是如何实现了既提升了hash算法的执行效率,又保证了得到的hash值的效果保持不变。下面就结合寻址算法来进行一下对比分析。
例如HashMap的数组长度n为16
1111 1111 1111 1111 1111 1010 0111 1100(没有经过优化的原hash值)
0000 0000 0000 0000 0000 0000 0000 1111(数组长度16-1 = 15的二进制数)一个数组长度不会非常的长,所以一般数组长度的32位二进制数的前16位都是0。所以将两个数进行与运算会发现,不管hash值前16位以前是什么,与一串0进行与运算之后结果都会变成0。相当于这样来计算的话,高16位数之间的与运算结果永远都是0,相当于原hash值的前16位并没有参与到运算当中,那么与运算的计算结果就完全取决于低16位的与运算了。这样就有可能会导致两个不同的hash值与(n-1)进行与运算的时候结果出现相同的情况。
举一个例子就能看出这样计算的问题,假设有两个hash值,这两个值低16位是一样的,高16位不同。
1111 1111 1111 1111 1111 1010 0111 1100
1111 1111 1111 1110 1111 1010 0111 1100这种情况下,两个数如果和
0000 0000 0000 0000 0000 0000 0000 1111 进行与运算的话,结果会是一样的。
都是0000 0000 0000 0000 1111 1010 0111 1100
但实际上前16位应该是不同的。所以我们要将前16位和后16位的特征全部保留才可以。如果我们使用优化后的hash算法来对这两个数进行处理,将前后16位进行异或运算
1111 1111 1111 1111 1111 1010 0111 1100 (优化后hash算法)-> 1111 1111 1111 1111 0000 0101 1000 0011
1111 1111 1111 1110 1111 1010 0111 1100 (优化后hash算法)-> 1111 1111 1111 1110 0000 0101 1000 0010我们发现这样两个数计算出来的hash值就不同了,保留了前后16位的特性,也就避免了哈希冲突。
2.4 总结
- hash算法的优化:对每个key调用hashCode()获得的hash值,对hash值的高低16位进行了异或,在新生成的hash值中的低16位同时保持了原key的hash值的高低16位的特征,尽量避免一些hash值后续出现冲突,进而避免不同的key值元素进入到数组的同一个位置触发冲突。
- 寻址算法的优化:用与运算替代取模,提升性能
计算元素在HashMap中位置的步骤:
三、HashMap如何解决hash碰撞问题
上一章讲了hash算法优化(避免hash冲突和改善了hash算法效率)和寻址性能优化(提高了寻址算法的效率),这两个优化的主要就是在map.put()和map.get()时起作用。过程就是通过hash算法算出来key的hash值,然后通过寻址算法到数组中寻址,找到一个位置,把key-value对放进数组,或者从数组中取出来。
但是还是会出现这样一种情况,当有两个key或多个key时,他们算出来的hash的值,与n-1进行与运算之后,发现定位出来的数组的位置还是有可能一样的,这也就出现了冲突,我们称为hash碰撞或hash冲突
3.1 jdk1.8之前
出现这种情况,在jdk1.8之前,HahsMap是通过链表来解决hash碰撞的问题的。就是在有冲突的数组位置上,添加一串链表,把有冲突的元素都插入到这个链表中。这样当获取元素的时候,定位到这个数组位置,发现这里有一个链表,就对链表进行一个遍历,进而获取所需要的元素。但链表的时间复杂度是O(n),如果链表比较长的话,效率就会比较低。
3.2 jdk1.8之后
所以在jdk1.8之后,做了相应的优化,使用链表O(n)+红黑树O(logn)的组合来解决hash冲突。如果链表的长度达到了一定的长度之后,就会把链表转换为红黑树,遍历一棵红黑树找一个元素的时间复杂度是O(logn),性能会比链表要高。
变为红黑树的触发条件:
当链表长度大于8的时候,就会将后面的数据存放到红黑树中,如果数据个数变回6时,就会再把红黑树变回链表,但是变成红黑树的一个前提条件就是HashMap的数组长度不能小于64。
四、HashMap是如何进行扩容的
HashMap底层是一个数组,当这个数组满了之后,它就会自动进行扩容,变成一个更大的数组,让你在里面可以去放更多的元素。
4.1 扩容的触发条件
当数组的存储比例达到了75%,就会进行2倍扩容,将数组大小扩大2倍,之所以是75%是基于时间和空间的考虑,太小了会浪费空间,太大了又会影响效率
4.1.1 为什么扩容是0.75
最近在看HashMap源码,对于扩容因子=0.75感到很费解,为什么在用了75%的容量的时候就要进行扩容呢?数组中明明还有25%的空间没有使用。为什么不等到数组几乎满了(扩容因子=0.95)的时候才进行扩容?扩容因子=0.95和扩容因子=0.75有什么区别吗?
首先来看一下什么是扩容因子。假设hash函数是理想的,数据会通过hash函数均匀的映射到数组上。一个数据映射到每一个桶(bucket)的概率是相等的。那么在任意的数组容量下,put一个数据发生碰撞的概率=数组中元素的个数 / 数组长度。扩容因子 = 当前数组中元素的个数 / 数组长度。所以我们就发现扩容因子就是当前put一个数据发生碰撞的概率。如果当数组空间占用75%的时候扩容,那么当时的碰撞概率就是75%。如果95%的时候再扩容,那么碰撞的概率就是95%。
这样的话,扩容因子等于0.75还是0.95的区别就很明显了。扩容因子=0.75。当使用量接近数组容量的75%的时候,数组中还有25%的剩余空间。平均来看,就是每4个桶(bucket)中还有一个是空的,当我们向map中put数据的时候,发生碰撞的概率是75%。因为这25%的空闲空间的存在,发生hash碰撞的概率还处在一个可以接受的范围内。
而当扩容因子=0.95的时候,平均来看,就是每20个桶(bucket)中才有一个是空的,此时数组中几乎没有空闲的桶(bucket),当我们put数据的时候,碰撞的概率是95%,几乎可以认为会发生碰撞。
除此之外,碰撞的概率越大,需要付出的代价越大,因为需要向链表或者红黑树中插入数据,插入和遍历数据都会使效率变低。所以,如果扩容因子越大,碰撞的概率也就越大,发生碰撞后的代价也更大,结果导致效率大打折扣。
因此扩容因子=0.75也是一个空间换时间的考虑,0.75这个数值应该是经过充分的考虑决定的。
4.2 扩容的时候rehash问题
HashMap中的数组进行扩容之后,因为数组长度出现了变化,如果不对原有元素重新进行Hash寻址的话,就会导致以后获取数据出现定位错误。这就需要对原有的元素进行rehash,更新元素的位置,这可能会使原本在同一位置上的链表上的元素被重新分配到不同的位置。
举一个例子:
[16位的数组,<> <> <>]
[32位的数组,<> <> <> <> <> <>]扩容前,数组长度=16
n - 1 0000 0000 0000 0000 0000 0000 0000 1111
hash1 1111 1111 1111 1111 0000 1111 0000 0101
&结果 0000 0000 0000 0000 0000 0000 0000 0101 = 5(index = 5的位置)
n - 1 0000 0000 0000 0000 0000 0000 0000 1111
hash2 1111 1111 1111 1111 0000 1111 0001 0101
&结果 0000 0000 0000 0000 0000 0000 0000 0101 = 5(index = 5的位置)在数组长度为16的时候,他们两个hash值的位置是一样的,用链表来处理,存放到同一个链表中来解决hash冲突。
扩容后,数组长度=32
如果数组的长度扩容之后 = 32,就需要重新对每个hash值进行寻址,也就是用每个hash值跟新数组的length - 1进行与运算操作。
n-1 0000 0000 0000 0000 0000 0000 0001 1111
hash1 1111 1111 1111 1111 0000 1111 0000 0101
&结果 0000 0000 0000 0000 0000 0000 0000 0101 = 5(index = 5的位置)
n-1 0000 0000 0000 0000 0000 0000 0001 1111
hash2 1111 1111 1111 1111 0000 1111 0001 0101
&结果 0000 0000 0000 0000 0000 0000 0001 0101 = 21(index = 21的位置)我们发现两个数据在数组长度位16的时候与运算结果一致,但是当长度为32的时候,与运算结果不同。这也就导致两个数据需要在扩容扩容之后放到不同的数组元素中。
在数组扩容这一方面,jdk1.7和jdk1.8也是有区别的,1.7是直接用hash值和需要扩容的二进制数进行&(hash值 & length-1),在每一次扩容之后需要对所有的元素都重新进行一次与运算进行rehash,这样效率相对要低一些。
但是我们可以观察上面案例的运算结果,二进制与运算结果中如果多出一个bit的1,那么这个元素的新的下标位置 =index(原来的位置) + oldCap(原来的数组长度),如果结果并没有多出来一个bit的1,那么就还是原来的index。
jdk1.8就是通过这种运算的规律,来优化了扩容好的rehash方式,不再使用jdk1.7那种需要重新进行与运算的操作,而是只需要判断Hash值的新增参与运算的位是0还是1就直接迅速计算出了扩容后的储存方式。就是说原key的哈希值中参与到和新的数组长度求与运算的位的值是0还是1,如果是1,就说明需要将这个数据换到新的位置,也就是原始位置+扩容的大小值。如果参与的是0,就说明这个数据的位置不需要变化。通过这个方式,就避免了rehash的时候,用每个hash对(新数组.length - 1)取模,取模性能不高,位运算的性能比较高。
具体判断原key的哈希值参与到和(新数组长度-1)进行与运算的位是0还是1,在源码中的具体实现是通过下面这段完成的:
if ((e.hash & oldCap) == 0) // 注意这里oldCap没有减一就是通过将原key的与原数组长度进行按位取与操作,结果如果为0,说明原key的哈希值参与到和(新数组长度-1)最高位进行与运算的位是0,否则就是1。原理就是数组的长度都是2次幂,所以长度的二进制形式都是最高位是1,其余为都是0,也就是说只有与最高位进行与运算的数字是1结果才可能不是0,否则取与的结果肯定是零。原数组长度二进制最高位就是新数组长度-1的二进制最高位,只要判断原key的hash值与这一位进行与运算结果是0还是1就能根据之前的规律来判断元素在新数组的位置需不需要变化。
相关文章:【Java集合】HashMap系列(一)——底层数据结构分析
【Java集合】HashMap系列(二)——底层源码分析
【Java集合】HashMap系列(三)——TreeNode内部类源码分析
【数据结构】史上最好理解的红黑树讲解,让你彻底搞懂红黑树