数据预处理之数据缩放
一、介绍
在实践中,同一个数据集合中经常包含不同类别的变量。一个很大的问题是这些变量的值域可能大不相同。如果使用原值域将会使得值域大的变量被赋予更多的权重。针对这个问题,我们需要在数据预处理时对自变量或特征使用缩放的方法。特征缩放的目的是使得所有特征都在相似的范围内,因此建模时每个特征都会变得同等重要,并且更便于机器学习的算法进行处理。
特征缩放的必要性:
- 数据中包含一些数值大,计算量复杂度高,难以收敛,不利于统计处理。
- 数据不符合正态分布,无法进行需要符合正态分布要求的数据分析
- 特征间的量纲不同,带来数据不可比问题,且量纲不同的数据特征字段可能存在数值差异巨大,导致数值大的特征字段在算法模型中的作用影响大,数值小的特征字段容易被忽略。
- 原始特征下,因为量纲不同可能导致损失函数的等高线表现出椭圆形,梯度方向垂直于等高线,下降会走zigzag路线,而不是指向local minimum。通过对特征进行zero-mean and unit-variance变换后,其损失函数的等高线图更接近圆形,梯度下降的方向震荡更小,收敛更快,如下图所示:
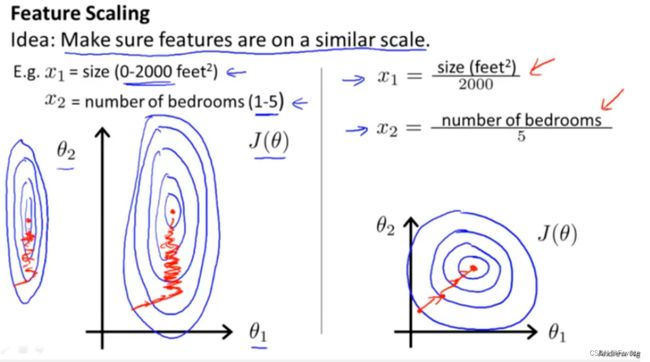
注意:首先需要对数据预处理、数据缩放,以及数据标准化、归一化之间的关系。数据预处理是数据分析挖掘中的重要步骤,数据缩放可以理解为数据预处理中的一部分,而数据标准化、归一化则是数据缩放的方法之二。同时,“归一化”和 “标准化”这两个说法有时候可以互换使用,但是二者本质上确是不同的。
| 中文 | 英文 |
|---|---|
| 特征缩放 | Feature Scaling |
| 标准化 | Standardization(Z-Score Normalization) |
| 归一化 | Normalization |
数据特征缩放的方法可以简单的概括为:“首先中心化,然后除以尺度”,即:
x s c a l e d = x − c e n t e r s c a l e x_{scaled}=\frac{x-center}{scale} xscaled=scalex−center
上面式子中, x s c a l e d x_{scaled} xscaled表示缩放后的数据, c e n t e r center center表示数据的比较基准,比较基准既可以是均值、中位数,也可以是最小值等; s c a l e scale scale表示数据特征缩放的尺度,缩放尺度可以是标准差、四分位数、最大值的绝对值或者最大最小值之间的差等。对比较基准和尺度的不同选择,就形成了不同的数据特征缩放方法。
二、数据缩放常用方法
给定数据集,令特征向量为x,维数为D,样本数量为R,可构成D×R的矩阵,一列为一个样本,一行为一维特征,如下图所示,图片来自Hung-yi Lee pdf-Gradient Descent:
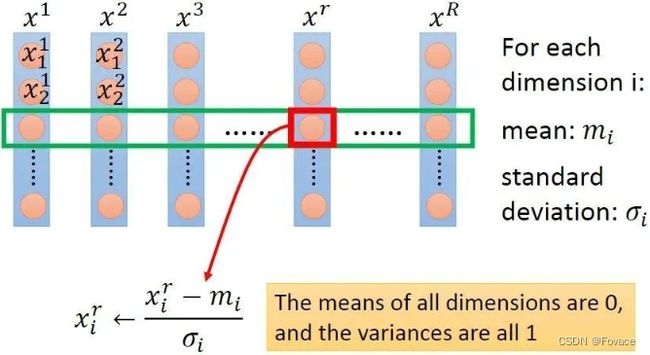
feature scaling的方法可以分成2类,逐行进行和逐列进行。逐行是对每一维特征操作,逐列是对每个样本操作,上图为逐行操作中特征标准化的示例。
(一)数据中心化(Data Centralization)
数据中心化也可以称为数据零均值化,算法简单,只要将每个值减去该数据的均值即可,公式如下:
x s c a l e d = x − x ‾ x_{scaled}=x-\overline{x} xscaled=x−x
对数据进行中心化处理后,数据实际上是没有进行”缩放“的,而只是对数据进行整体的平移,使得新数据的分布中心变为0,从而让数据更加容易向量化。中心化后的变量平均值为0,相应的最大值和最小值也同比例地发生了变化,但是中心化后变量的标准差仍然与原始数据相同,说明该变量的尺度没有发生变化。
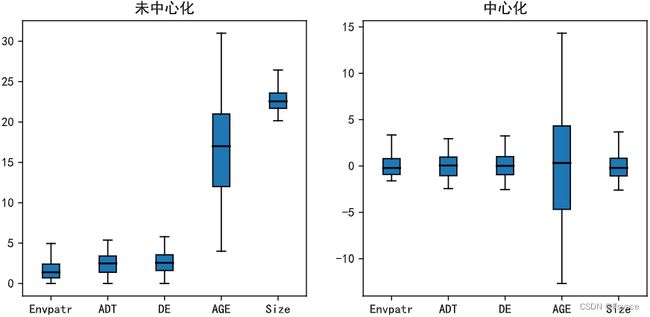
可以看到,进行中心化处理后,各变量数据的分布形状并没有发生变化,变量数据只是均值变为0。
(二)平均值归一化(Mean Normalization)
如果要将特征变量的数据映射到[-1,1]区间内,则需要计算特征变量的平均值 x m e a n x_{mean} xmean,使用平均值归一化方法公式为:
x s c a l e d = x − x m e a n m a x ( x ) − m i n ( x ) x_{scaled}=\frac{x-x_{mean}}{max(x)-min(x)} xscaled=max(x)−min(x)x−xmean
(三)标准化(Standardization)
标准化也叫中心标准化,通过数据标准化后,使所有特征的数值被转化成为均值为0、标准差为1的正态分布。公式如下:
x s c a l e d = x − x ‾ σ x_{scaled}=\frac{x-\overline{x}}{\sigma} xscaled=σx−x
机器学习实战中,经常会对不同种类的数据进行数据,比如声信号、图像像素值等,这些数据的维度不同,往往需要经过数据标准化后再使用。许多的机器学习算法都使用了这种标准化方法,如支持向量机,逻辑回归和人工神经网络等,缩放也适用于基于距离测量的算法,比如K近邻算法(KNN)。数据标准化也称为 Z-score标准化方法(Z-score Normalization),这种方法是基于特征变量原始数据x的均值 x m e a n x_{mean} xmean和标准差 x s t d x_{std} xstd进行数据的标准化,适用于特征变量的最大值 x m a x x_{max} xmax和最小值 x m i n x_{min} xmin未知的情况,或者有超出取值范围的离群数据的情况。标准化后的变量值围绕0上下波动,大于0说明高于平均水平,小于0说明低于平均水平。
实际上,数据标准化是平均值归一化的一种特殊形式。在Wiki百科中写道:
There is another form of the means normalization which divides by the standard deviation which is also called standardization.
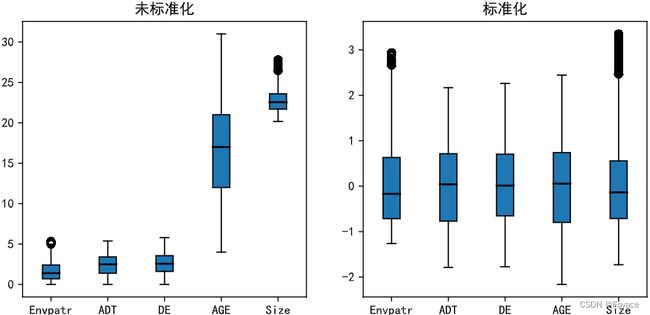
从输出结果可以观察到,各变量经过标准化后,其数据的分布范围差异明显变小,但是变量本身的分布形状并未改变,这样在建立一些模型时就能避免数据尺度差异对模型造成的负面影响。并且,其中有一部分值小于-3或者大于3,这说明这些数据的原值在序列中与均值的差异超过了3倍标准差的标准,属于非常特殊的数据,应当予以关注。
(四)归一化(Min-max Normalization)
Min-max Normalization又叫做离差标准化,该方法是将数据缩放至指定区间,一般情况下,指定区间为[0,1],这是Min-max Normalization的计算公式为:
x s c a l e d = x − m i n ( x ) m a x ( x ) − m i n ( x ) x_{scaled}=\frac{x-min(x)}{max(x)-min(x)} xscaled=max(x)−min(x)x−min(x)
如果要将该值X映射到[a,b]区间内,则公式为:
x s c a l e d = a + ( x − m i n ( x ) ) ( b − a ) m a x ( x ) − m i n ( x ) x_{scaled}=a+\frac{(x-min(x))(b-a)}{max(x)-min(x)} xscaled=a+max(x)−min(x)(x−min(x))(b−a)
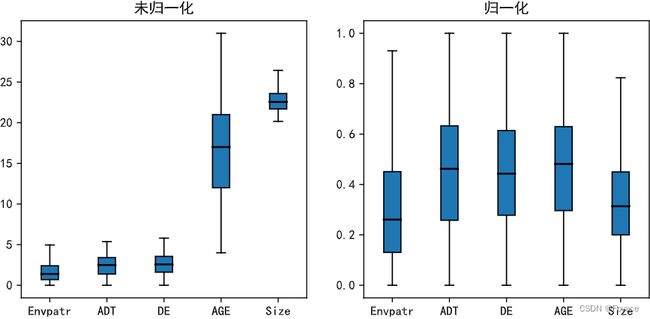
从图可以看出缩放后的最大值和最小值都在1和0之间,变量分布的形状没有发生改变。
(五)其他数据缩放方法
1、Max-ABS缩放
Max-ABS缩放可以将变量缩放至区间[-1,1],但是所采取的方式与Min-Max缩放不同。Max-ABS缩放的算法非常简单,每个变量除以其数据绝对值的最大值即可,公式为:
x s c a l e d = x ∣ x ∣ m a x x_{scaled}=\frac{x}{|x|_{max}} xscaled=∣x∣maxx
这个方法不是将原数据的所有值整体缩放至区间[-1,1],而是将原值大于0的数据缩放到区间(0,1],将原值小于0的数据缩放到区间[-1,0),原值等于0的数据缩放后还为0。
2、Robust缩放
如果数据的异常值情况比较严重,那么标准化方法就不再适用,需要用到Robust缩放方法。标准化方法之所以对异常值问题比较严重的数据不适用,是因为数据标准化算法需要用到的均值和标准差是两个极易受极端值影响的指标。Robust缩放用不易受极端值影响但是作用相近的中位数和四分位差替代了均值和标准差,公式为:
x s c a l e d = x − m e d i a n I Q R x_{scaled}=\frac{x-median}{IQR} xscaled=IQRx−median
三、数据缩放的步骤分析
对于平均值归一化、标准化和Min-max归一化而言,其计算方式都是先减去一个统计量,再除以一个统计量。
- 减一个统计量可以看成选哪个值作为原点,是最小值还是均值,并将整个数据集平移到这个新的原点位置。如果特征间偏置不同对后续过程有负面影响,则该操作是有益的,可以看成是某种偏置无关操作;如果原始特征值有特殊意义,比如稀疏性,该操作可能会破坏其稀疏性。
- 除以一个统计量可以看成在坐标轴方向上对特征进行缩放,用于降低特征尺度的影响,可以看成是某种尺度无关操作。缩放可以使用最大值最小值间的跨度,也可以使用标准差(到中心点的平均距离),前者对outliers敏感,outliers对后者影响与outliers数量和数据集大小有关,outliers越少数据集越大影响越小。
- 除以长度相当于把长度归一化,把所有样本映射到单位球上,可以看成是某种长度无关操作,比如,词频特征要移除文章长度的影响,图像处理中某些特征要移除光照强度的影响,以及方便计算余弦距离或内积相似度等。
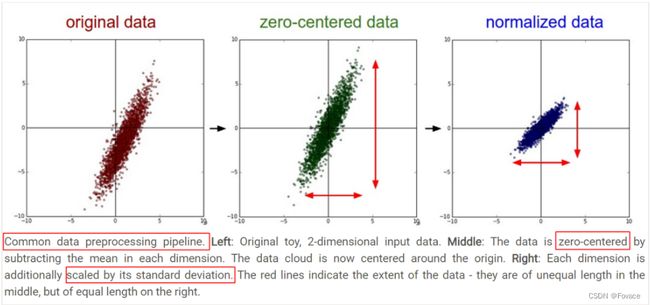
从几何上观察上述方法的作用,图片来自CS231n-Neural Networks Part 2: Setting up the Data and the Loss,zero-mean将数据集平移到原点,unit-variance使每维特征上的跨度相当,图中可以明显看出两维特征间存在线性相关性,Standardization操作并没有消除这种相关性。
可通过PCA方法移除线性相关性(decorrelation),即引入旋转,找到新的坐标轴方向,在新坐标轴方向上用“标准差”进行缩放,如下图所示,图片来自链接,图中同时描述了unit length的作用——将所有样本映射到单位球上。
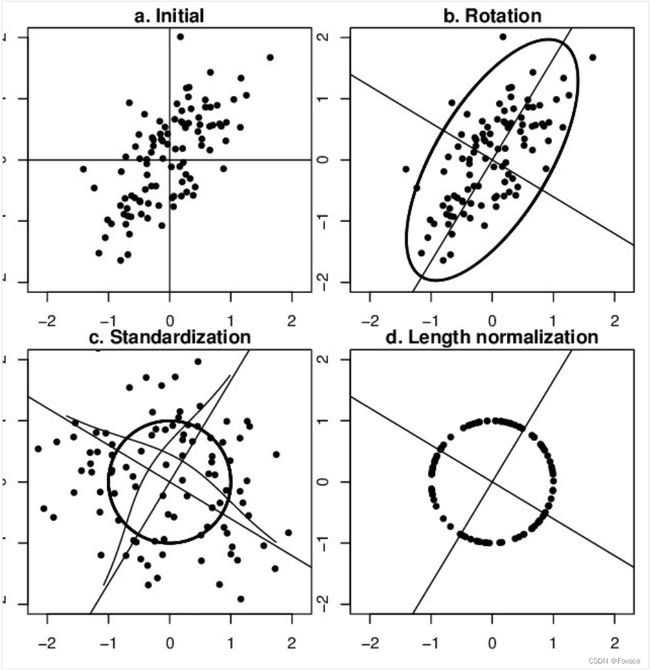
整体来看,对数据进行缩放的目的是为了获得某种“无关性”,比如偏置无关、尺度无关、长度无关等等。当归一化/标准化方法背后的物理意义和几何含义与当前问题的需要相契合时,其对解决该问题就有正向作用,反之,就会起反作用。所以,“何时选择何种方法”取决于待解决的问题。
四、数据缩放的使用
(一)需要用到数据缩放的场景
- 涉及到距离计算的算法需要使用数据缩放,这类算法主要有:
| Algorithm | Reasons of Apply Feature Scaling |
|---|---|
| K-Means | Use the Euclidean distance measure |
| K-Nearest-Neighbours | Measure the distance between pairs of samples and these distance are influenced by the measurement units |
| Principal Component Analysis | Try to get the feature with maximum variance |
| Artificial Neural Network | Apply Gradient Descent |
| Gradient Descent | Theta calculation becomes faster after feature scaling and the learning rate in the update equation of Stochastic Gradient Descent is the same for every parameter |
深入分析这些算法之所以需要使用数据缩放,主要原因在于:
-
zero-mean能够让样本间的余弦距离或内积结果的差异化增大,从而提升识别区分效果。假设数据集集中分布在第一象限遥远的右上角,将其平移到原点处,可以想象样本间余弦距离的差异被放大了。在模版匹配中,zero-mean可以明显提高响应结果的区分度。
-
对于欧式距离来说,使指定特征的尺度增大就等于是让该特征在进行距离计算时的权重增大。但权重增大对欧氏距离计算效果可能存在正向影响,比如该特征确实在计算中具有更明显的作用;但也可能是负向影响。在不确定特征到底对欧式距离计算的影响是正向,还是负向的情况下,还是需要先进行特征缩放,对各维特征等而视之。
-
增大尺度的同时也增大了该特征维度上的方差,PCA算法倾向于关注方差较大的特征所在的坐标轴方向,其他特征可能会被忽视,因此,在PCA前做Standardization效果可能更好。
-
损失函数中含有正则项时,一般需要feature scaling:对于线性模型y=wx+b而言,x的任何线性变换(平移、放缩),都可以被w和b“吸收”掉,理论上,不会影响模型的拟合能力。但是,如果损失函数中含有正则项,如λ∣∣w∣∣^2,λ为超参数,其对w的每一个参数施加同样的惩罚,但对于某一维特征xi而言,其scale越大,系数wi越小,其在正则项中的比重就会变小,相当于对wi惩罚变小,即损失函数会相对忽视那些scale增大的特征,这并不合理,所以需要feature scaling,使损失函数平等看待每一维特征。
-
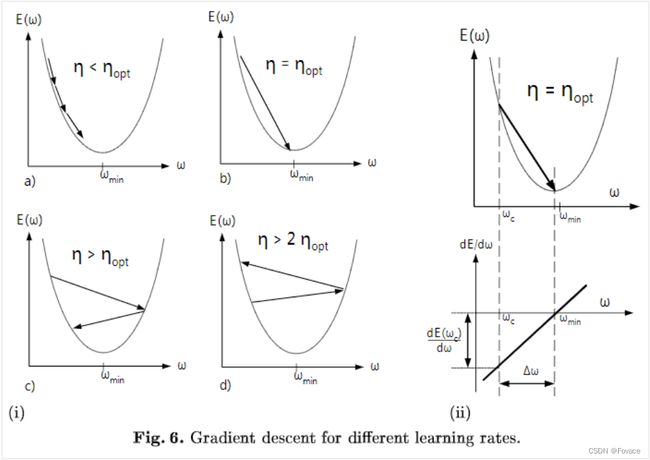
梯度下降算法,需要feature scaling。梯度下降的参数更新公式如下:
W ( t + 1 ) = W ( t ) − η d E ( W ) d W W(t+1)=W(t)-\eta\frac{dE(W)}{dW} W(t+1)=W(t)−ηdWdE(W)
E(W)为损失函数,收敛速度取决于:参数的初始位置到local minima的距离,以及学习率η的大小。一维情况下,在local minima附近,不同学习率对梯度下降的影响如下图所示:
(二)不需要用到数据缩放的场景
- 与距离计算无关的概率模型,比如Naive Bayes;
- 与距离计算无关的基于树的模型,比如决策树、随机森林等,树中节点的选择只关注当前特征在哪里切分对分类更好,即只在意特征内部的相对大小,而与特征间的相对大小无关。