一个由Dubbo Thread pool is EXHAUSTED引发的问题排查
前段时间现场的运维同学反馈某个服务出现一段时间里Dubbo消费端线程池被打满导致部分接口出现不可用的问题,这里记录下排查的过程。
首先,查看业务日志,发现出现了大量Thread pool is EXHAUSTED的报错。

项目里Dubbo服务端线程池配置如下,
<dubbo:protocol name="dubbo" port="-1" threads="500" threadpool="cached" dispatcher="message"/>
这里简单解释下,线程数设置为500,线程池类型选的是cache,这里的cache线程池并不是指JUC里提供的,Dubbo里它的实现如下:
public Executor getExecutor(URL url) {
String name = url.getParameter(THREAD_NAME_KEY, DEFAULT_THREAD_NAME);
int cores = url.getParameter(CORE_THREADS_KEY, DEFAULT_CORE_THREADS);//默认为0
int threads = url.getParameter(THREADS_KEY, Integer.MAX_VALUE);
int queues = url.getParameter(QUEUES_KEY, DEFAULT_QUEUES);//默认为0
int alive = url.getParameter(ALIVE_KEY, DEFAULT_ALIVE);//默认60s
return new ThreadPoolExecutor(cores, threads, alive, TimeUnit.MILLISECONDS,
queues == 0 ? new SynchronousQueue<Runnable>() :
(queues < 0 ? new LinkedBlockingQueue<Runnable>()
: new LinkedBlockingQueue<Runnable>(queues)),
new NamedInternalThreadFactory(name, true), new AbortPolicyWithReport(name, url));
}
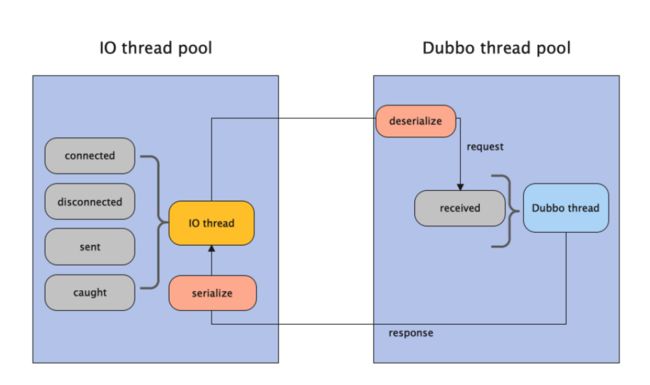
dispatcher设置的是message类型,dubbo一共提供了AllDispatcher、DirectDispatcher、MessageOnlyDispatcher、ExecutionDispatcher、ConnectionOrderedDispatcher等5种dispatcher,MessageOnlyDispatcher的示意图如下,它表示在Dubbo线程只执行received和反序列化,其他诸如sent、connected等事件均由IO线程处理,它能让服务端的线程池能尽可能地专注于执行业务代码。关于这方面更详细的信息可以参考官方文档 :Dubbo协议-Provider端线程模型。
1.jstack执行报错
基于以往的调用情况,一般来说消费端线程池设置为500绝对是够用的,所以当出现Thread pool is EXHAUSTED的时候一开始的反应就是服务端的线程被block了。用jstack pid > dubbo.log导出堆栈信息,反馈执行报错了

看网上有人说是因为进程的启动用户和执行用户不一致导致的,但我们都是用root用户执行,所以不是这个原因。实际上,在linux中jvm运行时会在/temp路径下创建一个文件夹hsperfdata_USER(USER是启动java进程的用户),文件夹下会有些pid文件用来存放jvm进程信息。jstack等命令通过读取/tmp/hsperfdata_USER下的pid文件获取连接信息。查看/tmp/hsperfdata_root内的文件,发现确实有一些pid文件,但是并没有找到需要的进程文件。
进一步查看相关资料后了解到,为了防止temp文件过多,centos7会定时调用命令/usr/bin/systemd-tmpfiles --clean进行临时文件的清理,清理规则定义在配置文件/usr/lib/tmpfiles.d/tmp.conf,执行时间由/usr/lib/systemd/system下的systemd-tmpfiles-clean.timer进行管理。查看清理规则配置文件
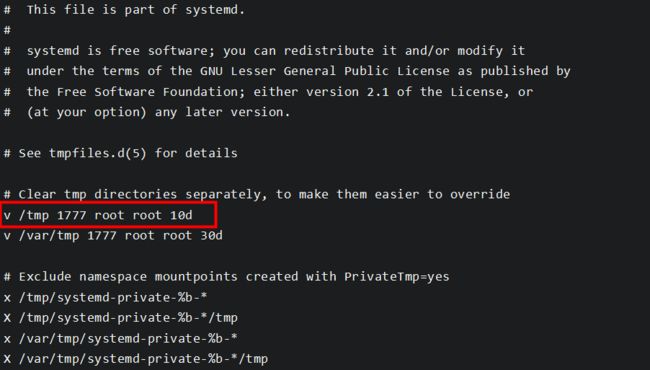
v 需要清理的目录
x 忽略的目录及目录下的子文件,可以使用shell通配符
X 忽略的指定目录,不包含子文件,可以使用shell通配符
可以发现,/temp下的文件默认是10天清理一次,查看系统日志,发现确实有删除的操作。

可以添加如下规则,让系统删除时不要删除java相关的进程文件。
x /tmp/hsperfdata
X /tmp/.java_
然而现在的问题是相关的pid文件已经被删除了,利用jstack打印堆栈信息已经不可能,只能另寻它路。这时我用报错日志Thread pool is EXHAUSTED去源码里找是在什么地方打印出来的,看能不能找到相关信息,最后定位如下相关代码。

原来Dubbo重写了线程池的AbortPolicy策略,看rejectedExecution方法,打印日志后抛出异常前,执行了一个dumpJstack方法,这名字看上去像是要输出堆栈信息,看它的具体实现,发现出现异常时会每隔10分钟执行一次。
private void dumpJStack() {
long now = System.currentTimeMillis();
//dump every 10 minutes
if (now - lastPrintTime < TEN_MINUTES_MILLS) {
return;
}
.....省略一些代码......
ExecutorService pool = Executors.newSingleThreadExecutor();
pool.execute(() -> {
//获取输出路径
String dumpPath = getDumpPath();
.....省略一些代码......
//try-with-resources
try (FileOutputStream jStackStream = new FileOutputStream(
new File(dumpPath, "Dubbo_JStack.log" + "." + dateStr))) {
//输出堆栈信息
JVMUtil.jstack(jStackStream);
} catch (Throwable t) {
logger.error("dump jStack error", t);
} finally {
guard.release();
}
});
//must shutdown thread pool ,if not will lead to OOM
pool.shutdown();
}
关键的代码在这句String dumpPath = getDumpPath(),看它的实现
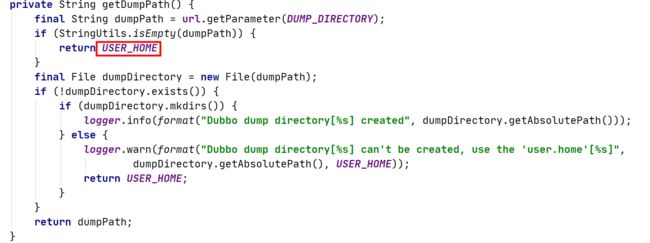
项目里并没有配置DUMP_DIRECTORY的值,所以输出路径是默认值USER_HOME,USER_HOME是根据System.getProperty("user.home")计算来的,在window环境为C:\Users\Administrator,而在linux环境里为/USER,USER表示当前的用户名。
真正获取堆栈信息的是JVMUtil.jstack(jStackStream)方法,看眼它的实现就会发现它跟jconsole这些java提供的图形化工具的原理是一样的。

找到相应的文件路径,发现确实有个名为Dubbo_JStack.log.xx的文件,xx表示文件生成的时间。打开日志文件发现有大量的DubboServerHandler线程处理TIMED_WAITING状态,看调用栈都是在等待获取Druid连接池的连接。
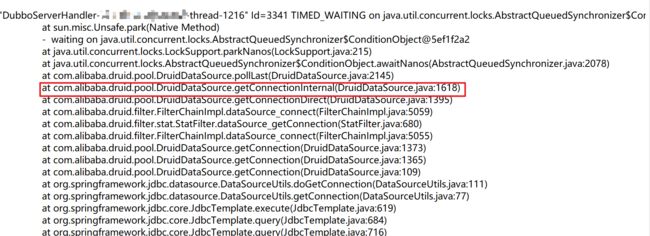
Druid连接池是一个生产者消费者模型,其中生产端是单线程的,示意图如下:
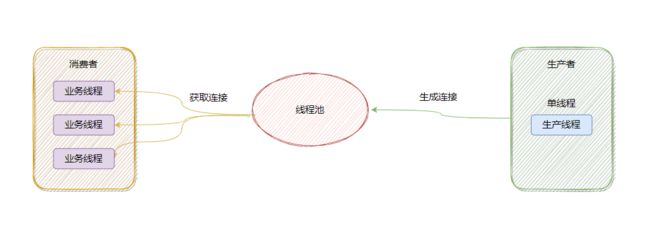
关于Druid连接池更为详细的信息可以参考:Druid连接池实现原理,文章里某些图片有一些细节上的小问题,但并不影响理解大致原理。
当连接池里没有可用连接时,消费端线程会执行等待,直到有连接被创建或者回收或者超时被唤醒。
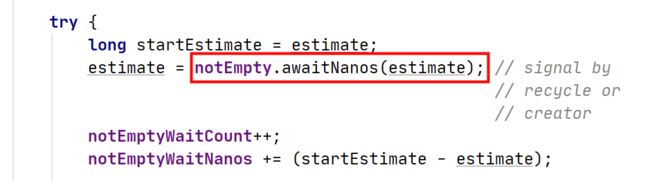
而因为Druid连接池生产端是单线程的,所以如果某一次RPC调用在获取数据库连接时耗时过长甚至超时,那么会导致后面所有RPC调用在需要获取数据库连接时阻塞,进而引发服务端Dubbo线程池溢出,抛出异常Thread pool is EXHAUSTED。
获取连接时间过长甚至超时,可能是连接池已有连接已达到maxActive,生产端不再生产连接导致,已有连接也都未回收,导致消费端一直在等待直到超时。然而,当查看日志,发现连接池内的连接数根本就没到maxActive,创建连接消耗了59s依然失败了。

2.模拟超过数据库最大连接数
去Druid项目的Github主页找看看有没有人遇到过类似的问题,发现有同学提到可能是数据库达到最大连接数。

写了一个测试案例来模拟创建大于数据库最大连接数,发现达到最大连接数后确实出现报错Connection reset。
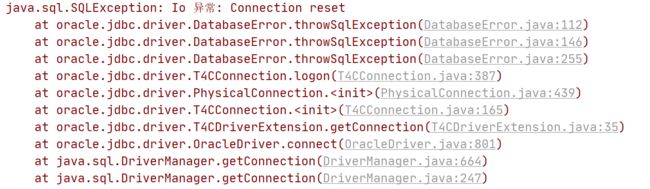
抓包的结果也显示数据库向应用端发送了RST包。

然而,当连接达到最大连接数时,会同时出现异常报错:no appropriate service handler found。
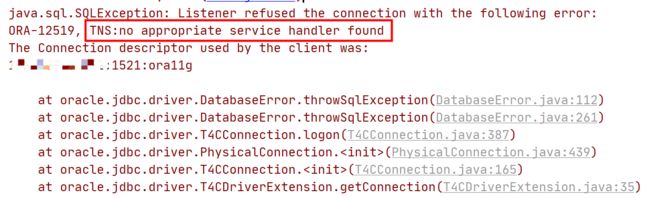
在现场的日志中并没有找到相同的报错,而且运维的同学也反馈当时数据库的连接数是正常的,并没有达到最大连接数,所以暂时排除这个可能。
3.模拟TCP握手异常
获取连接时间过长甚至超时除了Druid连接池内连接数达到maxActive外,也有可能是在创建连接过程中因为网络问题导致的。因此,接下来就模拟一下网络异常并进行测试。
Oracle客户端和服务器使用TNS作为其数据交换协议。 它提供了一种对用户透明的层, 为不同的工业标准协议提供统一、通用的接口。示意图如下,图来源于oracle文档。
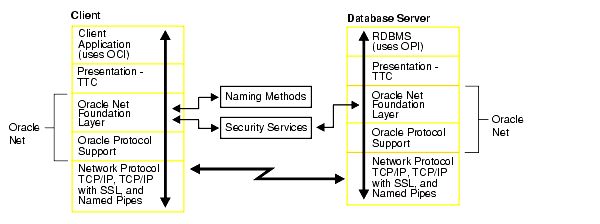
查看抓包的结果,可以看到完整的Oracle 建立连接、执行sql、返回结果的过程。
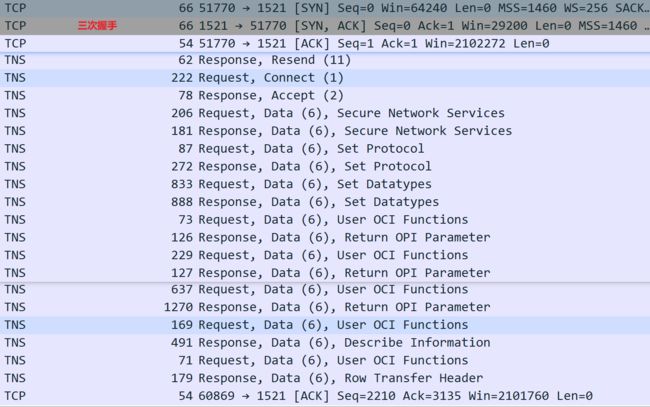
先模拟TCP三次握手异常,添加防火墙规则,拒绝客户端所有的数据包。
iptables -D INPUT -s 192.168.x.xxx -j DROP
利用Arthas观察Druid获取连接时的耗时情况,关于trace的使用可参考:Arthas官方文档
trace com.alibaba.druid.pool.DruidAbstractDataSource createPhysicalConnection -n 1000
trace结果如下,获取连接接口的耗时一共为21s。
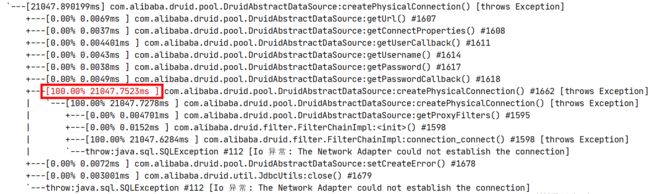
查看抓包结果,两次获取请求之前耗时确实为21s左右。

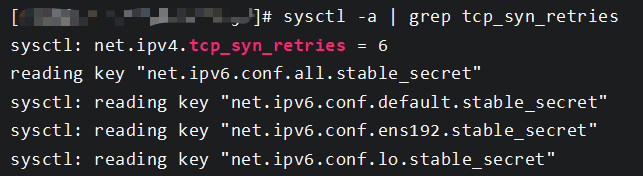
因为我这里测试的时候用是在window上,如果是linux系统,那么重试的耗时约为127s。因为linux系统默认会重传6次,每次重传失败下一次的等待时间就会翻倍。linux重传的次数可以通过sysctl -a | grep tcp_syn_retries查看。
同时业务日志出现了Druid连接池内连接数未到maxActive,获取新连接失败的报错。
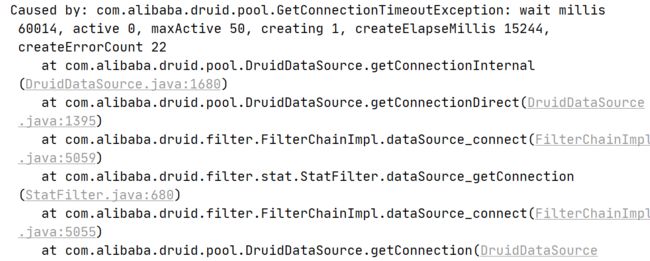
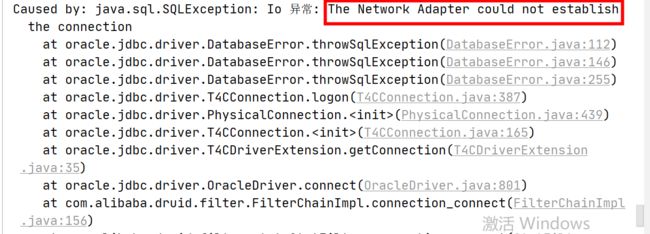
但是,它获取连接报错的原因是:The Network Adapter could not establish the connection,而现场的日志中并没有这样的报错,所以暂时排除这种可能。
4.模拟TNS协议应用层握手异常
从上面oracle数据交换协议的示意图可以看出,在经过三次握手建立TCP连接后,还要互相发送一些诸如SET DATATYPE、USER OCI的报文,接下来就模拟一下这些报文发送异常的情况。以Rquest,Connect报文中的Connect Data值作为过滤条件添加防火墙规则。
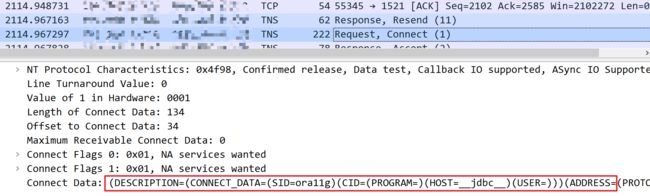
规则如下:
iptables -I INPUT -m string --algo bm --string "
(DESCRIPTION=(CONNECT_DATA=(SID=ora11g)(CID=(PROGRAM=)
(HOST=__jdbc__)(USER=))" -j DROP
trace的打印结果如下:
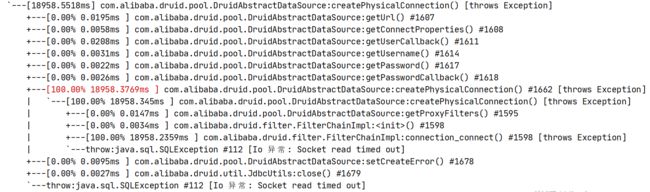
业务日志同样出现了Druid连接池未满但获取数据库连接超时的异常
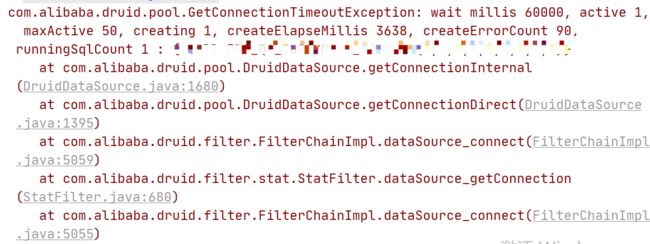
但是,它获取连接报错的原因是Socket read timed out,而现场的日志中并没有这样的报错,所以暂时也排除这种可能。

5.修改Druid等配置
由于时间问题就没有更进一步的模拟各种场景来复现现场环境的异常,但是,经过前面的分析有一件事是确定的,那就是Druid在创建数据库连接时出现了异常而且等待时间过长,导致Dubbo服务端线程被占用迟迟不能释放,最终导致线程池枯竭。
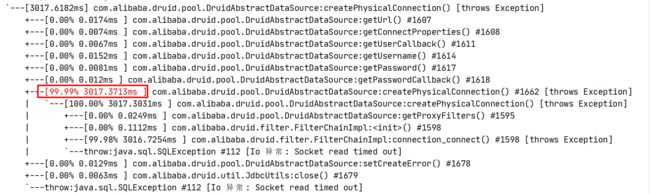
项目里Druid设置的maxWait为60000,也就是60s。测试网络异常时执行完服务端代码所要的时间,如下图,

之所以是120s,是因为Druid在maxWait时间内获取数据库连接失败后会默认重试一次。也就是说如果出现一次网络异常导致获取数据库连接失败,那么在2分钟内,Dubbo服务端的线程都不能释放,如果在RPC调用并发数比较大的时候,这非常容易导致线程池枯竭。
既然是因为创建连接导致的超时,那么解决方法有以下几种:
- 设置创建连接的超时时间
connectTimeout以及数据交互超时时间socketTimeout,关于这两个时间的作用更详细的信息可参考:深入理解JDBC的超时设置,总之它能避免单次创建连接时间过长; - 调小Druid的waitTime,它表示Druid从连接池中获取连接的最长等待时间,由于默认会重试一次,所以可以调整为Dubbo消费超时时间的1/2左右;
- 调大Druid的minIdle,它表示连接池空的最小空闲连接数,它能保证在创建连接失败时还有一定的数量的可用连接,能尽量去处理现有的访问数据库的操作,减少服务端线程等待的情况;
- 查找应用中执行时间较长的sql进行优化。和第3点一样,这也是为了让Druid连接池中有尽可能多的可用连接,从而降低创建新连接的概率。
关于第一点,如果是用的是MySQL数据库,那么可以在配置数据库连接地址url时在后面添加上jdbc:mysql://xxx.xx.xxx.xxx:3306/database?connectTimeout=3000&socketTimeout=4000。如果用的是Oracle数据库,网上有很多帖子的说法是错误的,比如
<property name="connectionProperties" value="connectTimeout=3000;socketTimeout=4000"/>
按上面的配置实际上是没有效果的,最后还是去源码中找答案,用的oracle驱动版本是ojdbc14 10.2.0.4.0,在oracle.jdbc.driver.OracleDriver#connect 中

var2里的值就包括我们在connectionProperties里设置的值,而oracle.jdbc.ReadTimeout就是我们要设置的socketTimeout。对于connectTimeout它设置的条件是var2中不包含oracle.net.CONNECT_TIMEOUT的值且DriverManager.getLoginTimeout的值不为0,而它的值可以通过Druid的loginTimeout属性设置,要注意的是它的单位是秒。
<property name="loginTimeout" value="3"/>
设置完后,重新模拟网络异常的情况,查看trace结果,可以看到已经生效了。
至于第2点和第3点,分别把waitTime设置为6000和minIdle设置为15,而第4个因为引入了其他组的依赖,需要其他同事一起参与,暂时不改动。在做了如上的改动后,现场环境在稳定运行了一段时间没有再次出现Dubbo服务端线程池Thread pool is EXHAUSTED的情况,这个问题的排查也就暂时告一段落。
这次异常排查耗费了比较多的时间,主要原因还是自己对网络通信这块知识还有很大的欠缺,下一步的计划就是要加深这一块的理论学习。
至于现场异常日志中connect reset的原因,在查阅了一些资料后了解到收到RST报文有以下几种可能:
- 端口未打开
- 请求超时
- 提前关闭,执行了close方法
- 在一个已关闭的socket上发送数据
当然实际情况远不止这几种,更多的可以参考:tcp rst产生的几种情况。后续准备按照这些可能性在测试环境进行模拟。
参考:
1.java无法热更新Unable to open socket file
2.几种TCP连接中出现RST的情况
3.Connection reset 及 connection reset by peer
4.深入理解JDBC超时设置
5.arthas在线文档
6.数据库异常引发的问题
7.Oracle的TNS协议解析