在自动驾驶的领域里面如何玩仿真 【1】 概述和写在前面的一些话
在自动驾驶的领域里面如何玩sil仿真 【1】 写在前面的一些话
停了两年
很久没登录CSDN了,之前野心勃勃开的题目随着自己进入一家初创公司开始后就没有时间和精力去更新了,发现这两三年有很多人喜欢这几个都不算太监(甚至头都没有写完)的文章,不少人私信问我为什么不写下去?
第一,自己确实没时间,很惭愧,时间管理小学生;
第二,写着写着发现自己的经验和知识并不足以支撑那么大的topic,需要自己沉淀沉淀。当自己觉得有能力接着往下写了,我会继续开题的。
这几年很幸运,首先,在两家公司,一家初创,一家大厂,找到了自己在自动驾驶圈子的定位----自动驾驶仿真,也非常幸运在一开始就在两个大牛手底下干活,一个前百度自动驾驶T9 level的仿真构架师,一个前Curise的 自动驾驶仿真部门负责人,都是从零开始搭建自己全栈级别的自动驾驶仿真云平台,让我从技术以及工程落地的角度体会到仿真原来是这么玩的,而且在全链条可信度高以及足够的数据支撑下对于软件迭代速度的恐怖的指数级别加速。所以这几年,我跟着学到了非常多,很感激这两年愿意教弱如菜鸡的我的所有人。
写这个原因
几年里面,我和很多业内的专家以及开发,项目都聊过自动驾驶仿真,很惊讶于目前国内对于仿真在自动驾驶的应用理解,很多人都还停留在商业软件(carmaker,carsim)上面点点点以及台架(hil)上面,对于自建sil链路很少或者完全不理解,甚至有些人完全不知道仿真是干什么的。但是很欣慰的是,目前国内越来越多的公司对于自动驾驶仿真逐渐重视起来,都开始了自己全栈自研的道路。但是如何玩怎么玩,相信有一部分公司还是无从下手的。
现在我仍然在某大厂,第三次从零开始给某欧洲项目搭建自己的自动驾驶sil链路的工程落地,不过这次是我自己主刀。在主刀的过程中,我也遇到很多难题,也解决了许多问题,不仅仅是技术上的,项目上,上下游对接,内部项目节点等等。有一天我在写周报的时候突然想到,既然我自己参与了多次自建仿真sil链路的build up,为什么不自己把在sil链路搭建的原理,可以公开的技术路线和快速见效的工程落地的理解和经验以及一些未来趋势整理整理写出来,第一供自己整理思路,第二大家互相交流。
内容有些什么
这一次我准备分成5篇文章聊聊sil链路。
第一部分算个引言吧,也就是这一篇,大白话讲一下仿真和一些sil基础原理上面的东西,还有一些名词解释。hil和pil不聊,因为不太熟。
第二,三,四部分我会把一个完整的仿真回归测试的链路拆分成几个部分,从数据的整理清洗,到场景库的建立,再到仿真云平台的大致结构,到仿真模拟器(logsim 和worldsim的功能和实现还有优缺点,以及未来趋势),后面评测体系的建立和维护。最后得出的结果如何能反馈出算法的优劣。
第五部分我会聊聊目前自动驾驶业界遇到的瓶颈和我自己的一些方法论,以及优化技巧。谈一谈仿真的置信度还有可靠性问题。最后还有未来以务实的角度去聊聊仿真未来发展的趋势。
写自动驾驶仿真的太多了 这个有什么不一样
讲技术讲趋势讲框架的太多,天花乱坠,从VR到AI学院派一堆,我要从另外一个角度,就是回归地面回归实际,从一个自动驾驶公司的角度讲如果最有效搭建仿真全链路,实现快速的工程落地的思路,我这里讲到的技术层面90%不是什么前沿的仿真技术,而是被无数人夯实被验证有效的技术以及经验方法论,所以对于一些公司层面的仿真技术路线会有比较好的参考意义。
仿真是一台时间机器
自动驾驶的核心就是功能算法,实现AD ADAS各种功能 AEB ELK,功能开发出来了,我们如何验证这个功能呢? 搞工程的根据V模型脱口而出----测,我们用啥测? 首先,你有一台车,然后你有ADC刷好了底层软件,然后灌进去你的功能,尝试拉起算法(就这几步骤前提这一块测试同学请打开你们的麦克风骂娘吧,只要坐车上就开始各种问题,有时候坐在车上测一版软件一天过去了,要么在修车,要么在拉人看软件问题。之前鄙人客串过测试,在车上做客一整天,下车只想拉会骂人)如果是主动安全相关功能测试,那就在大几万块块一天的测试场地带着几万块的假人假车玩碰碰车。愉快的一天结束后,可能一个法规测试集都没搞完。
所以路测的弊端可以很清晰的反应出来:效,率,低,下。对于目前崇尚敏捷开发的快速的软件迭代的前提下就是一个现眼包,无法支撑起敏捷开发要求的高效率要求。
怎么办?如果我们可以省掉这些上面说的环节呢?
首先省掉一台车。只有ADC和传感器搭起来的台架,我们ADC刷进去对应的算法,拉起来,然后播给算法最原始的感知的数据,然后记录下来算法产生的控车数据。恭喜,喜提HIL台架一个。这里播给最原始的感知数据如果是车端采集然后在离线播放,喜提HIL-replay一套。如果是通过数据格式生成的,或者在纯虚拟的沙盘地图中录下的原始感知数据,喜提HIL-sim一套。

我们再干掉这些传感器,只有一个ADC版子,上面装底软再刷进去功能软件,拉起来,拨给它传感器预处理后的数据(其实这里大家都叫中间件数据,我这里数据格式已protobuf为例,目前主流厂商都是基于ros的框架魔改并且套用dds做域内的试试通信,比如百度开元的apollo。如果纯采用的是can或者lin这种数据格式算是比较过时吧当然这些格式都是可以转换成proto),然后记录下来算法产生的控车数据,恭喜你,这玩意就是PIL。

手起刀落,我们连ADC也干掉,只剩下软件了,跑在哪里,来个电脑吧,我们跑在X86环境下面,这个时候我们有一个仿真模拟器,在这个环境下面我们跑自动驾驶功能算法,得出来的结果做下一步分析,这个就是sil(或者mil,二者在仿真环境上区别不大,所以这里我们只讨论sil)。
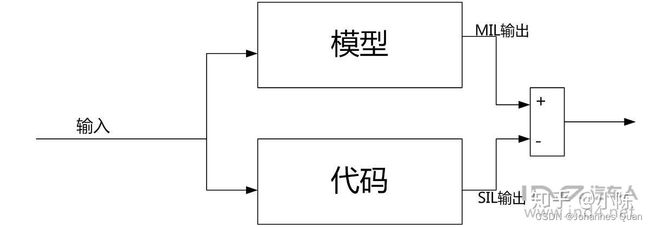
所以从hil到sil是一个逐渐在做减法的过程,也是一个逐渐再减掉仿真链路中影响功能稳定性因素的过程。但是,这些影响稳定性的因素对于自动驾驶作为一个软硬件完整的结合又是不能被忽略掉的。
为什么呢?我来举个很简单的栗子好了。
在hil台架上面,我们有这一套完整的ADC,和车端是完全一样的,包括soc的频率,算力,而这些工业级别的soc处理能力和我们的pc不在一个量级上,基本上是pc5-6年前的水平,所以我们在分配不同自动驾驶算法(感知,融合,pnc等等)的cpu占用率上面就不能过于豪放,需要毫厘必争。所以我们会在一些corner case中会出现多个算法一起超频导致soc过热 coredump的情况。而这种情况,我们只能在hil或者pil台架上面做冒烟测试压测出来,用sil? 不好意思,我用一台主机的cpu不说双开,十开功能算法照样稳如一匹老狗。
所以hil,pil,sil在应用范围上各有各的特点,可以用下面的图来表示:

但是我们从批量回归测试数量级上的潜力来说,从hil到sil是一个指数级别的增长。原因也是同上面一样。
所以应用sil仿真做自动驾驶功能算法的回归性测试,可以做到快速大量的回归,从而符合敏捷开发的要求。
all in all 一句话可以比喻仿真在自动驾驶的作用:
一台时间机器。
目前市场内自动驾驶公司的关于仿真的road map
在我认识的朋友以及自动驾驶业内人士所在公司中,传统主机厂对于仿真的理解比较守旧,可能也跟他们所在车上搭载的自动驾驶功能相对简单相关,大多l2以及以下(主动安全+ACC)所以此类功能实现起来并不需要dds 那样内容丰富且高效的通讯形式,而是使用传统汽车底盘CAN 最多LIN 线进行通讯而完成,而这些通讯形式都是来自于商业公司,我们在做仿真时一旦涉及到顶层状态机的测试往往因为需要去购买CAN相关解析设备而提高了自己的成本,并且无法在X86环境下运行,所以从ADAS开始这些传统厂商因为需要购买设备的缘故往往把仿真和hil划了等号。 x86? 买个carmaker lisence 单机跑跑法规测试集合就行。
但是目前在新势力和互联网自动驾驶公司,是和传统车企的思维完全不一样的。首先,很多的企业新势力直接锚点L3 L4至少也是一个L2.9,所以传统底盘的分布式通讯根本就无法织成这样复杂的通讯需求。其次,他们并没有传统车企的供应商包袱,能自研绝对不找供应商。所以目前主流的通讯形式就是各种类型的dds变种和魔改。消息内容的结构采用 google的 protobuf去做, 开源,简介,高效。
所以在这次,我们主要围着dds +protobuf这种形式的自动驾驶模式阐述如何做全栈自研的仿真,在仿真模拟器的开发里面这个概念非常重要。
什么是DDS和protobuf?什么是logsim和worldsim?
Data Distribution Service 数据分发服务,是新一代分布式实时通信中间件协议,采用发布/订阅体系架构,强调以数据为中心,提供丰富的QoS服务质量策略,以保障数据进行实时、高效、灵活地分发,可满足各种分布式实时通信应用需求。
DDS 里面有几个概念非常重要:
Domain:代表一个通信域,由Domain ID唯一标识,只有在同一个域内的通信实体才可以通信;如果考虑车内通信,可以只划分1个Domain,也可以按照交互规则或其他规则,定义多个Domain;在仿真里面,如果我们要实现复杂的闭环模式(影子模式 shadow mode 很多叫法)有一种解决方式就是定义两个域,一个real domain,一个 sim domain。
Domain Participant:代表域内通信的应用程序的本地成员身份,简单来说,就是说明同一数据域内的通信成员;这里面我们相当于拉起不同的进程,每个进程就是一个应用程序。
Topic:是数据的抽象概念,由TopicName标识,关联相应数据的数据类型(DataType),如果把车内所涉及的所有Topic集合在一起,这样就形成一个虚拟的全局数据空间“Global Data Space”,进一步弱化了节点的概念,所以域参与者已经不是节点的概念了;这里我们就可以使用protobuf 生成的 datatype去定义这些topic。
DataWriter:数据写入者,类似缓存,把需要发布的主题数据从应用层写入到DataWriter中;
DataReader:数据读取者,同样可以理解为一种缓存,从订阅者得到主题数据,随之传给应用层;
Publisher:发布者,发布主题数据,至少与1个DataWriter关联,通过调用DataWriter的相关函数将数据发出去;
Subscriber:订阅者,订阅主题数据,至少与1个DataReader关联。当数据到达时,应用程序可能忙于执行其他操作或应用程序只是等待该消息时,这样就会存在两种情况,同步访问和异步通知。
所以我们来看一下DDS的通讯原理:
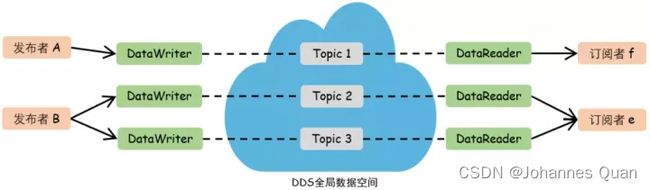
在这里发布者就是publisher,代表着某个在domain里面运行的某个进程,或者软件。比如我们知道,整个自动驾驶大概的由perception和fusion,plan和control组成,比如我们这里发布者B就是感知模块,它pub出来了两个主题数据,一个是 radar objects(雷达输出的目标物),一个是 vision objects(视觉输出的目标物体),通过domain 域内,fusion 模块作为订阅者e订阅了这两个topic,所以就收到了perception 模块发出来的这两个topic,然后在fusion 模块内部做融合处理,完成了一次dds 域内的sub和pub的过程。
当然dds的用法不止这些,比如Qos之类的,具体感兴趣的话可以看看这篇:
分布式实时通信——DDS技术
rotobuf(Google Protocol Buffers),官方文档对 protobuf 的定义:protocol buffers 是一种语言无关、平台无关、可扩展的序列化结构数据的方法,可用于数据通信协议和数据存储等,它是 Google 提供的一个具有高效协议数据交换格式工具库,是一种灵活、高效和自动化机制的结构数据序列化方法。
就是一种序列化数据的方法,具体可以看看:
protobuf的优缺点
Logsim是什么,log就是离线的实车数据,logsim,就是讲离线的实车数据回灌到原始版本或者改进版本的算法中,实现场景重现和算法回归。所以logsim是一个和实车数据强相关的仿真工具
Worldsim,就是创建一个完全虚拟的场景,可以理解为一个沙盘地图中,在这个场景中我们初始化各种各样的物体,然后通过初始化自车以及自动驾驶算法,让算法在虚拟的自车中运行,测试算法的性能。
网上有很多将这两个区别,如果想知道的详细一点,可以自行百度一下。
结尾
OK 我觉得科普完了,下面一章我开始进入深水区,先逐步拆解整个sil 仿真链路中的组成部分,然后每一个都拆开讲讲如何搭建,并且快速落地。
因为logsim的sil链路是相对比world sim链路复杂的多,所以我会著墨跟多在这个上面。
worldsim的链路其实和logsim在除了数据处理后面的链路上共用。
那么为了下一个章节的开始附一张logsim sil的链路的简单图示吧:
