python的requests库实现百度图片爬取
- 主要功能:
通过用户输入的图片类型和数量进行图片的爬取并保存到本地。
- 结果展示:
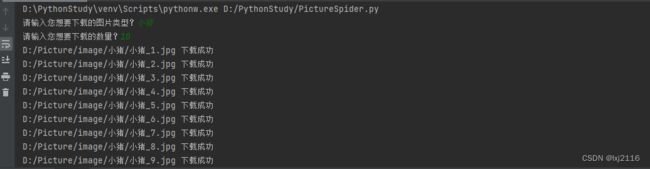
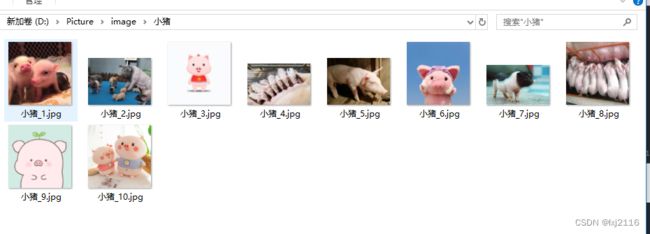
- 代码展示:
import random
import json
import requests
import os
import time
class BaiduImageSpider(object):
def __init__(self):
self.url = 'https://image.baidu.com/search/acjson?'
self.header1 = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36',
'Cookie': '登录百度账号后通过F12在请求头中自己获取cookie',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh - CN, zh;q = 0.9, en;q = 0.8',
'Accept': 'text/plain, */*; q=0.01'
}
self.header2 = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'}
def get_image(self, url, word, param):
save_url = []
html = requests.get(url=url, headers=self.header1, params=param).text
jpg = json.loads(html)
jpg["data"].pop()
for i in jpg["data"]:
save_url.append(i['thumbURL'])
directory = 'D:/Picture/image/{}/'.format(word)
if not os.path.exists(directory):
os.makedirs(directory)
i = 1
for img_link in save_url:
filename = '{}{}_{}.jpg'.format(directory, word, i)
self.save_image(img_link, filename)
i += 1
print("{}-下载完成!".format(word))
def save_image(self, img_link, filename):
html = requests.get(url=img_link, headers=self.header2).content
with open(filename, 'wb') as f:
f.write(html)
print(filename, '下载成功')
time.sleep(random.uniform(0, 1))
def run(self):
word = input("请输入您想要下载的图片类型?")
num = input("请输入您想要下载的数量?")
param = {
"tn": "resultjson_com",
"logid": "7594783827726186484",
"ipn": "rj",
"ct": "201326592",
"fp": "result",
"word": word,
"queryWord": word,
"cl": "2",
"lm": "-1",
"ie": "utf-8",
"oe": "utf-8",
"st": "-1",
"z": "0",
"ic": "0",
"hd": "0",
"latest": "0",
"copyright": "0",
"face": "0",
"istype": "2",
"nc": "1",
"pn": "0",
"rn": num,
"gsm": "1e"
}
self.get_image(url=self.url, word=word, param=param)
if __name__ == '__main__':
spider = BaiduImageSpider()
spider.run()