Shell命令学习
What is Shell?
Shell 是一个应用程序,它连接了用户和 Linux 内核,让用户能够更加高效、安全、低成本地使用 Linux 内核,这就是 Shell 的本质。
Shell 本身并不是内核的一部分,它只是站在内核的基础上编写的一个应用程序,它和 QQ、Firefox 等其它软件没有什么区别。然而 Shell 也有着它的特殊性,就是开机立马启动,并呈现在用户面前;用户通过 Shell 来使用 Linux,不启动 Shell 的话,用户就没办法使用 Linux。
Shell 是如何连接用户和内核的?
Shell 能够接收用户输入的命令,并对命令进行处理,处理完毕后再将结果反馈给用户,比如输出到显示器、写入到文件等,这就是大部分读者对 Shell 的认知。你看,我一直都在使用 Shell,哪有使用内核哦?我也没有看到 Shell 将我和内核连接起来呀?!
其实,Shell 程序本身的功能是很弱的,比如文件操作、输入输出、进程管理等都得依赖内核。我们运行一个命令,大部分情况下 Shell 都会去调用内核暴露出来的接口,这就是在使用内核,只是这个过程被 Shell 隐藏了起来,它自己在背后默默进行,我们看不到而已。
接口其实就是一个一个的函数,使用内核就是调用这些函数。这就是使用内核的全部内容了吗?嗯,是的!除了函数,你没有别的途径使用内核。
比如,我们都知道在 Shell 中输入cat log.txt命令就可以查看 log.txt 文件中的内容,然而,log.txt 放在磁盘的哪个位置?分成了几个数据块?在哪里开始?在哪里终止?如何操作探头读取它?这些底层细节 Shell 统统不知道的,它只能去调用内核提供的 open() 和 read() 函数,告诉内核我要读取 log.txt 文件,请帮助我,然后内核就乖乖地按照 Shell 的吩咐去读取文件了,并将读取到的文件内容交给 Shell,最后再由 Shell 呈现给用户(其实呈现到显示器上还得依赖内核)。整个过程中 Shell 就是一个“中间商”,它在用户和内核之间“倒卖”数据,只是用户不知道罢了。
Shell 还能连接其它程序
在 Shell 中输入的命令,有一部分是 Shell 本身自带的,这叫做内置命令;有一部分是其它的应用程序(一个程序就是一个命令),这叫做外部命令。
Shell 本身支持的命令并不多,功能也有限,但是 Shell 可以调用其他的程序,每个程序就是一个命令,这使得 Shell 命令的数量可以无限扩展,其结果就是 Shell 的功能非常强大,完全能够胜任 Linux 的日常管理工作,如文本或字符串检索、文件的查找或创建、大规模软件的自动部署、更改系统设置、监控服务器性能、发送报警邮件、抓取网页内容、压缩文件等。
更加惊讶的是,Shell 还可以让多个外部程序发生连接,在它们之间很方便地传递数据,也就是把一个程序的输出结果传递给另一个程序作为输入。
大家所说的 Shell 强大,并不是 Shell 本身功能丰富,而是它擅长使用和组织其他的程序。Shell 就是一个领导者,这正是 Shell 的魅力所在。
可以将 Shell 在整个 Linux 系统中的地位描述成下图所示的样子。注意“用户”和“其它应用程序”是通过虚线连接的,因为用户启动 Linux 后直接面对的是 Shell,通过 Shell 才能运行其它的应用程序。

Shell 也支持编程
Shell 并不是简单的堆砌命令,我们还可以在 Shell 中编程,这和使用 C++、C#、Java、Python 等常见的编程语言并没有什么两样。
Shell 虽然没有 C++、Java、Python 等强大,但也支持了基本的编程元素,例如:
if…else 选择结构,case…in 开关语句,for、while、until 循环;
变量、数组、字符串、注释、加减乘除、逻辑运算等概念;
函数,包括用户自定义的函数和内置函数(例如 printf、export、eval 等)。
站在这个角度讲,Shell 也是一种编程语言,它的编译器(解释器)是 Shell 这个程序。我们平时所说的 Shell,有时候是指连接用户和内核的这个程序,有时候又是指 Shell 编程。
Shell 主要用来开发一些实用的、自动化的小工具,而不是用来开发具有复杂业务逻辑的中大型软件,例如检测计算机的硬件参数、搭建 Web 运行环境、日志分析等,Shell 都非常合适。
使用 Shell 的熟练程度反映了用户对 Linux 的掌握程度,运维工程师、网络管理员、程序员都应该学习 Shell。
尤其是 Linux 运维工程师,Shell 更是必不可少的,是必须掌握的技能,它使得我们能够自动化地管理服务器集群,否则你就得一个一个地登录所有的服务器,对每一台服务器都进行相同的设置,而这些服务器可能有成百上千之多,会浪费大量的时间在重复性的工作上。
Shell 是一种脚本语言
任何代码最终都要被“翻译”成二进制的形式才能在计算机中执行。
有的编程语言,如 C/C++、Pascal、Go语言、汇编等,必须在程序运行之前将所有代码都翻译成二进制形式,也就是生成可执行文件,用户拿到的是最终生成的可执行文件,看不到源码。
这个过程叫做编译(Compile),这样的编程语言叫做编译型语言,完成编译过程的软件叫做编译器(Compiler)。
而有的编程语言,如 Shell、JavaScript、Python、PHP等,需要一边执行一边翻译,不会生成任何可执行文件,用户必须拿到源码才能运行程序。程序运行后会即时翻译,翻译完一部分执行一部分,不用等到所有代码都翻译完。
这个过程叫做解释,这样的编程语言叫做解释型语言或者脚本语言(Script),完成解释过程的软件叫做解释器。
编译型语言的优点是执行速度快、对硬件要求低、保密性好,适合开发操作系统、大型应用程序、数据库等。
脚本语言的优点是使用灵活、部署容易、跨平台性好,非常适合 Web 开发以及小工具的制作。
Shell 就是一种脚本语言,我们编写完源码后不用编译,直接运行源码即可。
进入Shell的两种方式
进入 Linux 控制台
一种进入 Shell 的方法是让 Linux 系统退出图形界面模式,进入控制台模式,这样一来,显示器上只有一个简单的带着白色文字的“黑屏”,就像图形界面出现之前的样子。这种模式称为 Linux 控制台(Console)。
现代 Linux 系统在启动时会自动创建几个虚拟控制台(Virtual Console),其中一个供图形桌面程序使用,其他的保留原生控制台的样子。虚拟控制台其实就是 Linux 系统内存中运行的虚拟终端(Virtual Terminal)。
从图形界面模式进入控制台模式也很简单,往往按下Ctrl + Alt + Fn(n=1,2,3,4,5…)快捷键就能够来回切换。
例如,CentOS 在启动时会创建 6 个虚拟控制台,按下快捷键Ctrl + Alt + Fn(n=2,3,4,5,6)可以从图形界面模式切换到控制台模式,按下Ctrl + Alt + F1可以从控制台模式再切换回图形界面模式。也就是说,1 号控制台被图形桌面程序占用了。
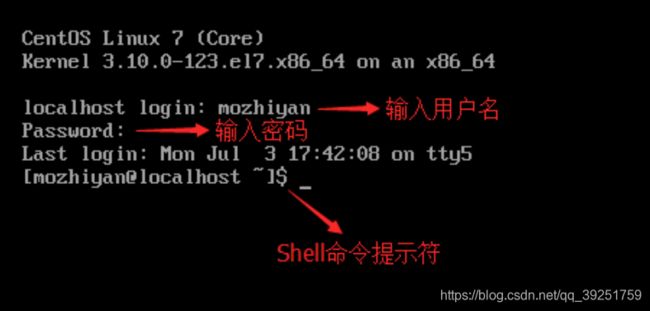
输入用户名和密码,登录成功后就可以进入 Shell 了。$是命令提示符,我们可以在它后面输入 Shell 命令。
在图形界面模式下,输入密码时往往会显示为 *,密码有几个字符就显示几个 *;而在控制台模式下,输入密码什么都不会显示,好像按键无效一样,这一点请大家不要惊慌,只要输入的密码正确就能够登录。
图形界面也是一个程序,会占用 CPU 时间和内存空间,当 Linux 作为服务器系统时,安装调试完毕后,应该让 Linux 运行在控制台模式下,以节省服务器资源。正是由于这个原因,很多服务器甚至不安装图形界面程序,管理员只能使用命令来完成各项操作。
使用终端
进入 Shell 的另外一种方法是使用 Linux 桌面环境中的终端模拟包(Terminal emulation package),也就是我们常说的终端(Terminal),这样在图形桌面中就可以使用 Shell。
打开终端后,就可以输入 Shell 命令了。
Shell 命令的基本格式
如下:
command [选项] [参数]
[]表示可选的,也就是可有可无。有些命令不写选项和参数也能执行,有些命令在必要的时候可以附带选项和参数。
ls 是常用的一个命令,它属于目录操作命令,用来列出当前目录下的文件和文件夹。
有些命令的选项后面也可以附带参数,这些参数用来补全选项,或者调整选项的功能细节。
例如,read 命令用来读取用户输入的数据,并把读取到的数据赋值给一个变量,它通常的用法为:
read str
str 为变量名。
如果我们只是想读取固定长度的字符串,那么可以给 read 命令增加-n选项。比如读取一个字符作为性别的标志,那么可以这样写:
read -n 1 sex
1是-n选项的参数,sex是 read 命令的参数。
-n选项表示读取固定长度的字符串,那么它后面必然要跟一个数字用来指明长度,否则选项是不完整的。
Linux Shell命令提示符
Linux Shell 默认的命令提示符的格式为:
[username@host directory]$
或者
[username@host directory]#
[]是提示符的分隔符号,没有特殊含义。
username表示当前登录的用户,我现在使用的是 mozhiyan 用户登录。
@是分隔符号,没有特殊含义。
host表示当前系统的简写主机名(完整主机名是 localhost.localdomain)。
~代表用户当前所在的目录为主目录(home 目录)。如果用户当前位于主目录下的 bin 目录中,那么这里显示的就是bin。
KaTeX parse error: Expected 'EOF', got '#' at position 53: …(root 用户),提示符就是#̲;如果是普通用户,提示符就是。
第二层命令提示符
有些命令不能在一行内输入完成,需要换行,这个时候就会看到第二层命令提示符。第二层命令提示符默认为>:
$ echo "Shell教程"
Shell教程
[mozhiyan@localhost ~]$ echo "
> name
> is
> R"
name
is
R
第一个 echo 命令在一行内输入完成,不会出现第二层提示符。第二个 echo 命令需要多行才能输入完成,提示符>用来告诉用户命令还没输入完成,请继续输入。
echo 命令用来输出一个字符串。字符串是一组由" “包围起来的字符序列,echo 将第一个"作为字符串的开端,将第二个"作为字符串的结尾。对于第二个 echo 命令,我们将字符串分成多行,echo 遇到第一个"认为是不完整的字符串,所以会继续等待用户输入,直到遇见第二个”。
第一个Shell脚本
几乎所有编程语言的教程都是从使用著名的“Hello World”开始的,出于对这种传统的尊重(或者说落入俗套),我们的第一个 Shell 脚本也输出“Hello World”。
打开文本编辑器,新建一个文本文件,并命名为 test.sh。
扩展名sh代表 shell,扩展名并不影响脚本执行,见名知意就好,如果你用 php 写 shell 脚本,扩展名就用php好了。
在 test.sh 中输入代码:
#!/bin/bash
echo "Hello World !" #这是一条语句
第 1 行的#!是一个约定的标记,它告诉系统这个脚本需要什么解释器来执行,即使用哪一种 Shell;后面的/bin/bash就是指明了解释器的具体位置。
第 2 行的 echo 命令用于向标准输出文件(Standard Output,stdout,一般就是指显示器)输出文本。在.sh文件中使用命令与在终端直接输入命令的效果是一样的。
第 2 行的#及其后面的内容是注释。Shell 脚本中所有以#开头的都是注释(当然以#!开头的除外)。写脚本的时候,多写注释是非常有必要的,以方便其他人能看懂你的脚本,也方便后期自己维护时看懂自己的脚本——实际上,即便是自己写的脚本,在经过一段时间后也很容易忘记。
执行Shell脚本(多种方法)
1)将 Shell 脚本作为程序运行
Shell 脚本也是一种解释执行的程序,可以在终端直接调用(需要使用 chmod 命令给 Shell 脚本加上执行权限),如下所示:
$ cd demo #切换到 test.sh 所在的目录
$ chmod +x ./test.sh #给脚本添加执行权限
$ ./test.sh #执行脚本文件
Hello World ! #运行结果
第 2 行中,chmod +x表示给 test.sh 增加执行权限。
第 3 行中,./表示当前目录,整条命令的意思是执行当前目录下的 test.sh 脚本。如果不写./,Linux 会到系统路径(由 PATH 环境变量指定)下查找 test.sh,而系统路径下显然不存在这个脚本,所以会执行失败。
通过这种方式运行脚本,脚本文件第一行的#!/bin/bash一定要写对,好让系统查找到正确的解释器。
2) 将 Shell 脚本作为参数传递给 Bash 解释器
你也可以直接运行 Bash 解释器,将脚本文件的名字作为参数传递给 Bash,如下所示:
$ cd demo #切换到 test.sh 所在的目录
$ /bin/bash test.sh #使用Bash的绝对路径
Hello World ! #运行结果
通过这种方式运行脚本,不需要在脚本文件的第一行指定解释器信息,写了也没用。
更加简洁的写法是运行 bash 命令。bash 是一个外部命令,Shell 会在 /bin 目录中找到对应的应用程序,也即 /bin/bash。
$ cd demo
$ bash test.sh
Hello World !
这两种写法在本质上是一样的:第一种写法给出了绝对路径,会直接运行 Bash 解释器;第二种写法通过 bash 命令找到 Bash 解释器所在的目录,然后再运行,只不过多了一个查找的过程而已。
检测是否开启了新进程
Linux 中的每一个进程都有一个唯一的 ID,称为 PID,使用$$变量就可以获取当前进程的 PID。
首先编写如下的脚本文件,并命名为 check.sh:
echo $$ #输出当前进程PID
然后使用以上两种方式来运行 check.sh:
$ echo KaTeX parse error: Expected 'EOF', got '#' at position 8: 1135 #̲当前进程的PID $ chmo…
1135 #当前进程的PID
$ /bin/bash check.sh
4774 #新进程的PID
你看,进程的 PID 都不一样,当然就是两个进程了。
在当前进程中运行 Shell 脚本
这里需要引入一个新的命令——source 命令。source 是 Shell 内置命令的一种,它会读取脚本文件中的代码,并依次执行所有语句。你也可以理解为,source 命令会强制执行脚本文件中的全部命令,而忽略脚本文件的权限。
# source 命令的用法为:
source filename
也可以简写为:
. filename
两种写法的效果相同。对于第二种写法,注意点号.和文件名中间有一个空格。
例如,使用 source 运行上节的 test.sh:
$ cd demo #切换到test.sh所在的目录
$ source ./test.sh #使用source
Hello World !
$ source test.sh #使用source
Hello World !
$ . ./test.sh #使用点号
Hello World !
$ . test.sh #使用点号
Hello World !
你看,使用 source 命令不用给脚本增加执行权限,并且写不写./都行,是不是很方便呢?
检测是否在当前 Shell 进程中
我们仍然借助KaTeX parse error: Can't use function '$' in math mode at position 20: …出进程的 PID,如下所示: $̲ cd demo $ echo…
4756 #当前进程PID
$ source ./check.sh
4756 #Shell脚本所在进程PID
$ echo $$
4756 #当前进程PID
$ . ./check.sh
4756 #Shell脚本所在进程PID
你看,进程的 PID 都是一样的,当然是同一个进程了。
Shell编程
Shell变量:Shell变量的定义、赋值和删除
变量是任何一种编程语言都必不可少的组成部分,变量用来存放各种数据。脚本语言在定义变量时通常不需要指明类型,直接赋值就可以,Shell 变量也遵循这个规则。
在 Bash shell 中,每一个变量的值都是字符串,无论你给变量赋值时有没有使用引号,值都会以字符串的形式存储。
这意味着,Bash shell 在默认情况下不会区分变量类型,即使你将整数和小数赋值给变量,它们也会被视为字符串,这一点和大部分的编程语言不同。例如在C语言或者 C++ 中,变量分为整数、小数、字符串、布尔等多种类型。
当然,如果有必要,你也可以使用 Shell declare 关键字显式定义变量的类型,但在一般情况下没有这个需求,Shell 开发者在编写代码时自行注意值的类型即可。
定义变量
Shell 支持以下三种定义变量的方式:
variable=value
variable=‘value’
variable=“value”
variable 是变量名,value 是赋给变量的值。如果 value 不包含任何空白符(例如空格、Tab 缩进等),那么可以不使用引号;如果 value 包含了空白符,那么就必须使用引号包围起来。使用单引号和使用双引号也是有区别的,稍后我们会详细说明。
注意,赋值号=的周围不能有空格,这可能和你熟悉的大部分编程语言都不一样。
Shell 变量的命名规范和大部分编程语言都一样:
变量名由数字、字母、下划线组成;
必须以字母或者下划线开头;
不能使用 Shell 里的关键字(通过 help 命令可以查看保留关键字)。
变量定义举例:
url=http://www.baidu.com
echo $url
todo='find name'
echo $todo
author="R"
echo $author
使用变量
使用一个定义过的变量,只要在变量名前面加美元符号$即可,如:
author="R"
echo $author
echo ${author}
变量名外面的花括号{ }是可选的,加不加都行,加花括号是为了帮助解释器识别变量的边界,比如下面这种情况:
name="Java"
echo "I am man name is ${name}hk"
如果不给 skill 变量加花括号,写成I am man name is $namehk,解释器就会把 $skillScript 当成一个变量(其值为空),代码执行结果就不是我们期望的样子了。
推荐给所有变量加上花括号{ },这是个良好的编程习惯。
单引号和双引号的区别
前面我们还留下一个疑问,定义变量时,变量的值可以由单引号’ ‘包围,也可以由双引号" "包围,它们到底有什么区别呢?
以单引号’ '包围变量的值时,单引号里面是什么就输出什么,即使内容中有变量和命令(命令需要反引起来)也会把它们原样输出。这种方式比较适合定义显示纯字符串的情况,即不希望解析变量、命令等的场景。
以双引号" "包围变量的值时,输出时会先解析里面的变量和命令,而不是把双引号中的变量名和命令原样输出。这种方式比较适合字符串中附带有变量和命令并且想将其解析后再输出的变量定义。
我的建议:如果变量的内容是数字,那么可以不加引号;如果真的需要原样输出就加单引号;其他没有特别要求的字符串等最好都加上双引号,定义变量时加双引号是最常见的使用场景。
将命令的结果赋值给变量
Shell 也支持将命令的执行结果赋值给变量,常见的有以下两种方式:
variable=`command`
variable=$(command)
第一种方式把命令用反引号(位于 Esc 键的下方)包围起来,反引号和单引号非常相似,容易产生混淆,所以不推荐使用这种方式;第二种方式把命令用$()包围起来,区分更加明显,所以推荐使用这种方式。
例如,我在 demo 目录中创建了一个名为 log.txt 的文本文件,用来记录我的日常工作。下面的代码中,使用 cat 命令将 log.txt 的内容读取出来,并赋值给一个变量,然后使用 echo 命令输出。
$ cd demo
$ log=$(cat log.txt)
$ echo $log
This is a log!
$ log=`cat log.txt` # cat 命令用来读取文件中的内容,并输出到控制台
$ echo $log
This is a log!
只读变量
使用 readonly 命令可以将变量定义为只读变量,只读变量的值不能被改变。
下面的例子尝试更改只读变量,结果报错:
#!/bin/bash
a="This is a variable"
readonly a
a="This is readonly variable "
运行脚本,结果如下:
./test.sh: line 4: a: readonly variable
删除变量
使用 unset 命令可以删除变量。语法:
unset variable_name
变量被删除后不能再次使用;unset 命令不能删除只读变量。
Shell命令替换:将命令的输出结果赋值给变量
Shell 命令替换是指将命令的输出结果赋值给某个变量。比如,在某个目录中输入 ls 命令可查看当前目录中所有的文件,但如何将输出内容存入某个变量中呢?这就需要使用命令替换了,这也是 Shell 编程中使用非常频繁的功能。
Shell 中有两种方式可以完成命令替换,一种是反引号,一种是 ( ) , 使 用 方 法 如 下 : v a r i a b l e = ‘ c o m m a n d s ‘ v a r i a b l e = (),使用方法如下: variable=`commands` variable= (),使用方法如下:variable=‘commands‘variable=(commands)
其中,variable 是变量名,commands 是要执行的命令。commands 可以只有一个命令,也可以有多个命令,多个命令之间以分号;分隔。
例如,date 命令用来获得当前的系统时间,使用命令替换可以将它的结果赋值给一个变量。
begin_time=`date` #开始时间,使用``替换
sleep 20s #休眠20秒
finish_time=$(date) #结束时间,使用$()替换
echo "Begin time: $begin_time"
echo "Finish time: $finish_time"
运行脚本,20 秒后可以看到输出结果:
Begin time: 2019年 04月 19日 星期五 09:59:58 CST
Finish time: 2019年 04月 19日 星期五 10:00:18 CST
使用 data 命令的%s格式控制符可以得到当前的 UNIX 时间戳,这样就可以直接计算脚本的运行时间了。UNIX 时间戳是指从 1970 年 1 月 1 日 00:00:00 到目前为止的秒数。
#!/bin/bash
begin_time=`date +%s` #开始时间,使用``替换
sleep 20s #休眠20秒
finish_time=$(date +%s) #结束时间,使用$()替换
run_time=$((finish_time - begin_time)) #时间差
echo "begin time: $begin_time"
echo "finish time: $finish_time"
echo "run time: ${run_time}s"
#运行脚本,20 秒后可以看到输出结果:
begin time: 1555639864
finish time: 1555639884
run time: 20s
第 6 行代码中的**(( ))是 Shell 数学计算命令**。和 C++、C#、Java 等编程语言不同,在 Shell 中进行数据计算不那么方便,必须使用专门的数学计算命令,(( ))就是其中之一。
注意,如果被替换的命令的输出内容包括多行(也即有换行符),或者含有多个连续的空白符,那么在输出变量时应该将变量用双引号包围,否则系统会使用默认的空白符来填充,这会导致换行无效,以及连续的空白符被压缩成一个。请看下面的代码:
#!/bin/bash
LSL=`ls -l`
echo $LSL #不使用双引号包围
echo "--------------------------" #输出分隔符
echo "$LSL" #使用引号包围
#运行结果:
total 8 drwxr-xr-x. 2 root root 21 7月 1 2016 abc -rw-rw-r--. 1 mozhiyan mozhiyan 147 10月 31 10:29 demo.sh -rw-rw-r--. 1 mozhiyan mozhiyan 35 10月 31 10:20 demo.sh~
--------------------------
total 8
drwxr-xr-x. 2 root root 21 7月 1 2016 abc
-rw-rw-r--. 1 mozhiyan mozhiyan 147 10月 31 10:29 demo.sh
-rw-rw-r--. 1 mozhiyan mozhiyan 35 10月 31 10:20 demo.sh~
所以,为了防止出现格式混乱的情况,我建议在输出变量时加上双引号。
再谈反引号和 $()
原则上讲,上面提到的两种变量替换的形式是等价的,可以随意使用;但是,反引号毕竟看起来像单引号,有时候会对查看代码造成困扰,而使用 $() 就相对清晰,能有效避免这种混乱。而且有些情况必须使用 ( ) : (): ():() 支持嵌套,反引号不行。
下面的例子演示了使用计算 ls 命令列出的第一个文件的行数,这里使用了两层嵌套。
$ Fir_File_Lines=$(wc -l $(ls | sed -n '1p'))
$ echo "$Fir_File_Lines"
36 anaconda-ks.cfg
要注意的是,$() 仅在 Bash Shell 中有效,而反引号可在多种 Shell 中使用。所以这两种命令替换的方式各有特点,究竟选用哪种方式全看个人需求。
Shell位置参数(命令行参数)
我们先来说一下 Shell 位置参数是怎么回事。
运行 Shell 脚本文件时我们可以给它传递一些参数,这些参数在脚本文件内部可以使用$n的形式来接收,例如,$1 表示第一个参数, 2 表 示 第 二 个 参 数 , 依 次 类 推 。 同 样 , 在 调 用 函 数 时 也 可 以 传 递 参 数 。 S h e l l 函 数 参 数 的 传 递 和 其 它 编 程 语 言 不 同 , 没 有 所 谓 的 形 参 和 实 参 , 在 定 义 函 数 时 也 不 用 指 明 参 数 的 名 字 和 数 目 。 换 句 话 说 , 定 义 S h e l l 函 数 时 不 能 带 参 数 , 但 是 在 调 用 函 数 时 却 可 以 传 递 参 数 , 这 些 传 递 进 来 的 参 数 , 在 函 数 内 部 就 也 使 用 2 表示第二个参数,依次类推。 同样,在调用函数时也可以传递参数。Shell 函数参数的传递和其它编程语言不同,没有所谓的形参和实参,在定义函数时也不用指明参数的名字和数目。换句话说,定义 Shell 函数时不能带参数,但是在调用函数时却可以传递参数,这些传递进来的参数,在函数内部就也使用 2表示第二个参数,依次类推。同样,在调用函数时也可以传递参数。Shell函数参数的传递和其它编程语言不同,没有所谓的形参和实参,在定义函数时也不用指明参数的名字和数目。换句话说,定义Shell函数时不能带参数,但是在调用函数时却可以传递参数,这些传递进来的参数,在函数内部就也使用n的形式接收,例如,$1 表示第一个参数, 2 表 示 第 二 个 参 数 , 依 次 类 推 。 这 种 通 过 2 表示第二个参数,依次类推。 这种通过 2表示第二个参数,依次类推。这种通过n的形式来接收的参数,在 Shell 中称为位置参数。
在讲解变量的命名时,我们提到:变量的名字必须以字母或者下划线开头,不能以数字开头;但是位置参数却偏偏是数字,这和变量的命名规则是相悖的,所以我们将它们视为“特殊变量”。
除了 $n,Shell 中还有 KaTeX parse error: Expected 'EOF', got '#' at position 1: #̲、*、$@、$?、$$ 几个特殊参数。
- 给脚本文件传递位置参数
请编写下面的代码,并命名为 test.sh:
#!/bin/bash
echo "Language: $1"
echo "URL: $2"
运行 test.sh,并附带参数:
$ cd demo
$ . ./test.sh Shell http://c.biancheng.net/shell/
Language: Shell
URL: http://c.biancheng.net/shell/
其中Shell是第一个位置参数,http://c.biancheng.net/shell/是第二个位置参数,两者之间以空格分隔。
2) 给函数传递位置参数
请编写下面的代码,并命名为 test.sh:
#!/bin/bash
#定义函数
function func(){
echo "Language: $1"
echo "URL: $2"
}
#调用函数
func C++ http://c.biancheng.net/cplus/
运行 test.sh:
$ . ./test.sh
Language: C++
URL: http://c.biancheng.net/cplus/
关于函数定义和调用的具体语法请访问:Shell函数定义和调用、Shell函数参数
注意事项
如果参数个数太多,达到或者超过了 10 个,那么就得用${n}的形式来接收了,例如 ${10}、${23}。{ }的作用是为了帮助解释器识别参数的边界,这跟使用变量时加{ }是一样的效果。
Shell 特殊变量及其含义
变量 含义
$0 当前脚本的文件名。
$n(n≥1) 传递给脚本或函数的参数。n 是一个数字,表示第几个参数。例如,第一个参数是 $1,第二个参数是 $2。
$# 传递给脚本或函数的参数个数。
$* 传递给脚本或函数的所有参数。
$@ 传递给脚本或函数的所有参数。当被双引号" "包含时,$@ 与 $* 稍有不同。
$? 上个命令的退出状态,或函数的返回值,我们将在《Shell $?》一节中详细讲解。
$$ 当前 Shell 进程 ID。对于 Shell 脚本,就是这些脚本所在的进程 ID。
- 给脚本文件传递参数
编写下面的代码,并保存为 test.sh:
#!/bin/bash
echo "Process ID: $$"
echo "File Name: $0"
echo "First Parameter : $1"
echo "Second Parameter : $2"
echo "All parameters 1: $@"
echo "All parameters 2: $*"
echo "Total: $#"
# 运行 test.sh,并附带参数:
$ . ./test.sh Shell Linux
Process ID: 5943
File Name: bash
First Parameter : Shell
Second Parameter : Linux
All parameters 1: Shell Linux
All parameters 2: Shell Linux
Total: 2
- 给函数传递参数
编写下面的代码,并保存为 test.sh:
#!/bin/bash
#定义函数
function func(){
echo "Language: $1"
echo "URL: $2"
echo "First Parameter : $1"
echo "Second Parameter : $2"
echo "All parameters 1: $@"
echo "All parameters 2: $*"
echo "Total: $#"
}
#调用函数
func Java http://c.biancheng.net/java/
# 运行结果为:
Language: Java
URL: http://c.biancheng.net/java/
First Parameter : Java
Second Parameter : http://c.biancheng.net/java/
All parameters 1: Java http://c.biancheng.net/java/
All parameters 2: Java http://c.biancheng.net/java/
Total: 2
Shell字符串详解
字符串(String)就是一系列字符的组合。字符串是 Shell 编程中最常用的数据类型之一(除了数字和字符串,也没有其他类型了)。
字符串可以由单引号’ '包围,也可以由双引号" "包围,也可以不用引号。
下面我们说一下三种形式的区别:
- 由单引号’ '包围的字符串:
任何字符都会原样输出,在其中使用变量是无效的。
字符串中不能出现单引号,即使对单引号进行转义也不行。
str1='string1'
- 由双引号" "包围的字符串:
如果其中包含了某个变量,那么该变量会被解析(得到该变量的值),而不是原样输出。
字符串中可以出现双引号,只要它被转义了就行。
str2="string1"
- 不被引号包围的字符串
不被引号包围的字符串中出现变量时也会被解析,这一点和双引号" "包围的字符串一样。
字符串中不能出现空格,否则空格后边的字符串会作为其他变量或者命令解析。
str1=string1
获取字符串长度
在 Shell 中获取字符串长度很简单,具体方法如下:
${#string_name}
Shell字符串拼接(连接、合并)
str1=$s1$s2 #中间不能有空格
str2="$s1 $s2" #如果被双引号包围,那么中间可以有空格
str3=$s1:$s2 #中间可以出现别的字符串
str4="$s1$:s2" #这样写也可以
Shell字符串截取
- 从字符串左边开始计数
如果想从字符串的左边开始计数,那么截取字符串的具体格式如下:
${string: start :length}
- 从右边开始计数
如果想从字符串的右边开始计数,那么截取字符串的具体格式如下:
${string: 0-start :length}
同第 1种格式相比,第 2种格式仅仅多了0-,这是固定的写法,专门用来表示从字符串右边开始计数。
这里需要强调两点:
从左边开始计数时,起始数字是 0(这符合程序员思维);从右边开始计数时,起始数字是 1(这符合常人思维)。计数方向不同,起始数字也不同。
不管从哪边开始计数,截取方向都是从左到右。
从指定字符(子字符串)开始截取
这种截取方式无法指定字符串长度,只能从指定字符(子字符串)截取到字符串末尾。Shell 可以截取指定字符(子字符串)右边的所有字符,也可以截取左边的所有字符。
- 使用 # 号截取右边字符
使用#号可以截取指定字符(或者子字符串)右边的所有字符,具体格式如下:
${string#*chars}
其中,string 表示要截取的字符,chars 是指定的字符(或者子字符串),*是通配符的一种,表示任意长度的字符串。chars连起来使用的意思是:忽略左边的所有字符,直到遇见 chars(chars 不会被截取)。
如果不需要忽略 chars 左边的字符,那么也可以不写。
注意,以上写法遇到第一个匹配的字符(子字符串)就结束了。
如果希望直到最后一个指定字符(子字符串)再匹配结束,那么可以使用##,具体格式为:
${string##*chars}
- 使用 % 截取左边字符
使用%号可以截取指定字符(或者子字符串)左边的所有字符,具体格式如下:
${string%chars*}
请注意的位置,因为要截取 chars 左边的字符,而忽略 chars 右边的字符,所以应该位于 chars 的右侧。其他方面%和#的用法相同。
Shell数组:Shell数组定义以及获取数组元素
Shell 数组的定义
在 Shell 中,用括号( )来表示数组,数组元素之间用空格来分隔。由此,定义数组的一般形式为:
array_name=(ele1 ele2 ele3 ... elen)
注意,赋值号=两边不能有空格,必须紧挨着数组名和数组元素。
下面是一个定义数组的实例:
nums=(29 100 13 8 91 44)
Shell 是弱类型的,它并不要求所有数组元素的类型必须相同,例如:
arr=(20 56 "http://c.biancheng.net/shell/")
第三个元素就是一个“异类”,前面两个元素都是整数,而第三个元素是字符串。
Shell 数组的长度不是固定的,定义之后还可以增加元素。例如,对于上面的 nums 数组,它的长度是 6,使用下面的代码会在最后增加一个元素,使其长度扩展到 7:
nums[6]=88
此外,你也无需逐个元素地给数组赋值,下面的代码就是只给特定元素赋值:
ages=([3]=24 [5]=19 [10]=12)
以上代码就只给第 3、5、10 个元素赋值,所以数组长度是 3。
获取数组元素
获取数组元素的值,一般使用下面的格式:
${array_name[index]}
其中,array_name 是数组名,index 是下标。
使用@或*可以获取数组中的所有元素,例如:
${nums[*]}
${nums[@]}
两者都可以得到 nums 数组的所有元素。
Shell获取数组长度
${#array_name[@]}
${#array_name[*]}
Shell数组拼接,Shell数组合并
array_new=(${array1[@]} ${array2[@]})
array_new=(${array1[*]} ${array2[*]})
Shell删除数组元素(也可以删除整个数组)
unset array_name[index]
# 如果不写下标,而是写成下面的形式:
unset array_name
# 那么就是删除整个数组,所有元素都会消失。
Shell内建命令(内置命令)
所谓 Shell 内建命令,就是由 Bash 自身提供的命令,而不是文件系统中的某个可执行文件。
例如,用于进入或者切换目录的 cd 命令,虽然我们一直在使用它,但如果不加以注意很难意识到它与普通命令的性质是不一样的:该命令并不是某个外部文件,只要在 Shell 中你就一定可以运行这个命令。
可以使用 type 来确定一个命令是否是内建命令:
# type cd
cd is a Shell builtin
# type ifconfig
ifconfig is /sbin/ifconfig
还记得系统变量 $PATH 吗?$PATH 变量包含的目录中几乎聚集了系统中绝大多数的可执行命令,它们都是外部命令。
通常来说,内建命令会比外部命令执行得更快,执行外部命令时不但会触发磁盘 I/O,还需要 fork 出一个单独的进程来执行,执行完成后再退出。而执行内建命令相当于调用当前 Shell 进程的一个函数。
Bash Shell 内建命令
命令 说明
: 扩展参数列表,执行重定向操作
. 读取并执行指定文件中的命令(在当前 shell 环境中)
alias 为指定命令定义一个别名
bg 将作业以后台模式运行
bind 将键盘序列绑定到一个 readline 函数或宏
break 退出 for、while、select 或 until 循环
builtin 执行指定的 shell 内建命令
caller 返回活动子函数调用的上下文
cd 将当前目录切换为指定的目录
command 执行指定的命令,无需进行通常的 shell 查找
compgen 为指定单词生成可能的补全匹配
complete 显示指定的单词是如何补全的
compopt 修改指定单词的补全选项
continue 继续执行 for、while、select 或 until 循环的下一次迭代
declare 声明一个变量或变量类型。
dirs 显示当前存储目录的列表
disown 从进程作业表中刪除指定的作业
echo 将指定字符串输出到 STDOUT
enable 启用或禁用指定的内建shell命令
eval 将指定的参数拼接成一个命令,然后执行该命令
exec 用指定命令替换 shell 进程
exit 强制 shell 以指定的退出状态码退出
export 设置子 shell 进程可用的变量
fc 从历史记录中选择命令列表
fg 将作业以前台模式运行
getopts 分析指定的位置参数
hash 查找并记住指定命令的全路径名
help 显示帮助文件
history 显示命令历史记录
jobs 列出活动作业
kill 向指定的进程 ID(PID) 发送一个系统信号
let 计算一个数学表达式中的每个参数
local 在函数中创建一个作用域受限的变量
logout 退出登录 shell
mapfile 从 STDIN 读取数据行,并将其加入索引数组
popd 从目录栈中删除记录
printf 使用格式化字符串显示文本
pushd 向目录栈添加一个目录
pwd 显示当前工作目录的路径名
read 从 STDIN 读取一行数据并将其赋给一个变量
readarray 从 STDIN 读取数据行并将其放入索引数组
readonly 从 STDIN 读取一行数据并将其赋给一个不可修改的变量
return 强制函数以某个值退出,这个值可以被调用脚本提取
set 设置并显示环境变量的值和 shell 属性
shift 将位置参数依次向下降一个位置
shopt 打开/关闭控制 shell 可选行为的变量值
source 读取并执行指定文件中的命令(在当前 shell 环境中)
suspend 暂停 Shell 的执行,直到收到一个 SIGCONT 信号
test 基于指定条件返回退出状态码 0 或 1
times 显示累计的用户和系统时间
trap 如果收到了指定的系统信号,执行指定的命令
type 显示指定的单词如果作为命令将会如何被解释
typeset 声明一个变量或变量类型。
ulimit 为系统用户设置指定的资源的上限
umask 为新建的文件和目录设置默认权限
unalias 刪除指定的别名
unset 刪除指定的环境变量或 shell 属性
wait 等待指定的进程完成,并返回退出状态码
Shell alias:给命令创建别名
alisa 用来给命令创建一个别名。若直接输入该命令且不带任何参数,则列出当前 Shell 进程中使用了哪些别名。现在你应该能理解类似ll这样的命令为什么与ls -l的效果是一样的吧。
下面让我们来看一下有哪些命令被默认创建了别名:
$ alias
alias cp='cp -i'
alias l.='ls -d .* --color=tty'
alias ll='ls -l --color=tty'
alias ls='ls --color=tty'
alias mv='mv -i'
alias rm='rm -i'
alias which='alias | /usr/bin/which --tty-only --read-alias --show-dot --show-tilde'
使用 alias 命令自定义别名
使用 alias 命令自定义别名的语法格式为:
alias new_name='command'
比如,一般的关机命令是shutdown-h now,写起来比较长,这时可以重新定义一个关机命令,以后就方便多了。
alias myShutdown='shutdown -h now'
再如,通过 date 命令可以获得当前的 UNIX 时间戳,具体写法为date +%s,如果你嫌弃它太长或者不容易记住,那可以给它定义一个别名。
alias timestamp='date +%s'
别名只是临时的
在代码中使用 alias 命令定义的别名只能在当前 Shell 进程中使用,在子进程和其它进程中都不能使用。当前 Shell 进程结束后,别名也随之消失。
要想让别名对所有的 Shell 进程都有效,就得把别名写入 Shell 配置文件。Shell 进程每次启动时都会执行配置文件中的代码做一些初始化工作,将别名放在配置文件中,那么每次启动进程都会定义这个别名。
使用 unalias 命令删除别名
使用 unalias 内建命令可以删除当前 Shell 进程中的别名。unalias 有两种使用方法:
第一种用法是在命令后跟上某个命令的别名,用于删除指定的别名。
第二种用法是在命令后接-a参数,删除当前 Shell 进程中所有的别名。
同样,这两种方法都是在当前 Shell 进程中生效的。要想永久删除配置文件中定义的别名,只能进入该文件手动删除。
Shell echo命令:输出字符串
echo 命令输出结束后默认会换行,如果不希望换行,可以加上-n参数。
echo -n "your string"
输出转义字符
默认情况下,echo 不会解析以反斜杠\开头的转义字符。比如,\n表示换行,echo 默认会将它作为普通字符对待。请看下面的例子:
$ echo "hello \nworld"
hello \nworld
我们可以添加-e参数来让 echo 命令解析转义字符。例如:
$ echo -e "hello \nworld"
hello
world
\c 转义字符
有了-e参数,我们也可以使用转义字符\c来强制 echo 命令不换行了。请看下面的例子:
echo -e "string1, \c"
echo -e "string2"
# 输出结果
string1, string2
Shell read命令:读取从键盘输入的数据
read 命令的用法为:
read [-options] [variables]
options表示选项;variables表示用来存储数据的变量,可以有一个,也可以有多个。
options和variables都是可选的,如果没有提供变量名,那么读取的数据将存放到环境变量 REPLY 中。
Shell read 命令支持的选项
选项 说明
-a array 把读取的数据赋值给数组 array,从下标 0 开始。
-d delimiter 用字符串 delimiter 指定读取结束的位置,而不是一个换行符(读取到的数据不包括 delimiter)。
-e 在获取用户输入的时候,对功能键进行编码转换,不会直接显式功能键对应的字符。
-n num 读取 num 个字符,而不是整行字符。
-p prompt 显示提示信息,提示内容为 prompt。
-r 原样读取(Raw mode),不把反斜杠字符解释为转义字符。
-s 静默模式(Silent mode),不会在屏幕上显示输入的字符。当输入密码和其它确认信息的时候,这是很有必要的。
-t seconds 设置超时时间,单位为秒。如果用户没有在指定时间内输入完成,那么 read 将会返回一个非 0 的退出状态,表示读取失败。
-u fd 使用文件描述符 fd 作为输入源,而不是标准输入,类似于重定向。
执行以下命令:
#!/bin/bash
read -p "enter your name and age:" -d '.' name age
echo "your name is ${name};"
echo "your age is ${age} old years."
# 输出结果
% ./test.sh
enter your name and age:R 24.
your name is R;
your age is 24 old years.
Shell exit命令:退出当前进程
exit 是一个 Shell 内置命令,用来退出当前 Shell 进程,并返回一个退出状态;使用$?可以接收这个退出状态。
exit 命令可以接受一个整数值作为参数,代表退出状态。如果不指定,默认状态值是 0。
一般情况下,退出状态为 0 表示成功,退出状态为非 0 表示执行失败(出错)了。
exit 退出状态只能是一个介于 0~255 之间的整数,其中只有 0 表示成功,其它值都表示失败。
Shell 进程执行出错时,可以根据退出状态来判断具体出现了什么错误,比如打开一个文件时,我们可以指定 1 表示文件不存在,2 表示文件没有读取权限,3 表示文件类型不对。
编写下面的脚本,并命名为 test.sh:
#!/bin/bash
echo "befor exit"
exit 8
echo "after exit"
# 执行脚本:
$ bash ./test.sh
befor exit
可以看到,"after exit"并没有输出,这说明遇到 exit 命令后,test.sh 执行就结束了。
注意,exit 表示退出当前 Shell 进程,我们必须在新进程中运行 test.sh,否则当前 Shell 会话(终端窗口)会被关闭,我们就无法看到输出结果了。
我们可以紧接着使用$?来获取 test.sh 的退出状态:
$ echo $?
8
Shell declare和typeset命令:设置变量属性
declare 和 typeset 都是 Shell 内建命令,它们的用法相同,都用来设置变量的属性。不过 typeset 已经被弃用了,建议使用 declare 代替。
declare 命令的用法如下所示:
declare [+/-] [aAfFgilprtux] [变量名=变量值]
其中,-表示设置属性,+表示取消属性,aAfFgilprtux都是具体的选项,它们的含义如下表所示:
选项 含义
-f [name] 列出之前由用户在脚本中定义的函数名称和函数体。
-F [name] 仅列出自定义函数名称。
-g name 在 Shell 函数内部创建全局变量。
-p [name] 显示指定变量的属性和值。
-a name 声明变量为普通数组。
-A name 声明变量为关联数组(支持索引下标为字符串)。
-i name 将变量定义为整数型。
-r name[=value] 将变量定义为只读(不可修改和删除),等价于 readonly name。
-x name[=value] 将变量设置为环境变量,等价于 export name[=value]。
运行以下脚本:
#!/bin/bash
declare -i a b c
a=1
b=2
echo -en "a+b=\n"
c=$a+$b
echo $c
# 输出结果
a+b=
3
Shell数学计算(算术运算,加减乘除运算)
如果要执行算术运算(数学计算),就离不开各种运算符号,和其他编程语言类似,Shell 也有很多算术运算符,下面就给大家介绍一下常见的 Shell 算术运算符,如下表所示。
Shell 算术运算符一览表
算术运算符 说明/含义
+、- 加法(或正号)、减法(或负号)
*、/、% 乘法、除法、取余(取模)
** 幂运算
++、-- 自增和自减,可以放在变量的前面也可以放在变量的后面
!、&&、|| 逻辑非(取反)、逻辑与(and)、逻辑或(or)
<、<=、>、>= 比较符号(小于、小于等于、大于、大于等于)
==、!=、= 比较符号(相等、不相等;对于字符串,= 也可以表示相当于)
<<、>> 向左移位、向右移位
~、|、 &、^ 按位取反、按位或、按位与、按位异或
=、+=、-=、*=、/=、%= 赋值运算符,例如 a+=1 相当于 a=a+1,a-=1 相当于 a=a-1
但是,Shell 和其它编程语言不同,Shell 不能直接进行算数运算,必须使用数学计算命令,这让初学者感觉很困惑,也让有经验的程序员感觉很奇葩。
Bash Shell 中,如果不特别指明,每一个变量的值都是字符串,无论你给变量赋值时有没有使用引号,值都会以字符串的形式存储。
换句话说,Bash shell 在默认情况下不会区分变量类型,即使你将整数和小数赋值给变量,它们也会被视为字符串,这一点和大部分的编程语言不同。
数学计算命令
要想让数学计算发挥作用,必须使用数学计算命令,Shell 中常用的数学计算命令如下表所示。
Shell 中常用的六种数学计算方式
运算操作符/运算命令 说明
(( )) 用于整数运算,效率很高,推荐使用。
let 用于整数运算,和 (()) 类似。
$[] 用于整数运算,不如 (()) 灵活。
expr 可用于整数运算,也可以处理字符串。比较麻烦,需要注意各种细节,不推荐使用。
bc Linux下的一个计算器程序,可以处理整数和小数。Shell 本身只支持整数运算,想计算小数就得使用 bc 这个外部的计算器。
declare -i 将变量定义为整数,然后再进行数学运算时就不会被当做字符串了。功能有限,仅支持最基本的数学运算(加减乘除和取余),不支持逻辑运算、自增自减等,所以在实际开发中很少使用。
如果大家时间有限,只学习 (()) 和 bc 即可,不用学习其它的了:(()) 可以用于整数计算,bc 可以小数计算。
Shell (()):对整数进行数学运算
双小括号 (( )) 的语法格式为:
((表达式))
通俗地讲,就是将数学运算表达式放在((和))之间。
表达式可以只有一个,也可以有多个,多个表达式之间以逗号,分隔。对于多个表达式的情况,以最后一个表达式的值作为整个 (( )) 命令的执行结果。
可以使用$获取 (( )) 命令的结果,这和使用$获得变量值是类似的。
(( )) 的用法
运算操作符/运算命令 说明
((a=10+66)
((b=a-15))
((c=a+b)) 这种写法可以在计算完成后给变量赋值。以 ((b=a-15)) 为例,即将 a-15 的运算结果赋值给变量 c。
注意,使用变量时不用加$前缀,(( )) 会自动解析变量名。
a=$((10+66)
b=$((a-15))
c=$((a+b)) 可以在 (( )) 前面加上$符号获取 (( )) 命令的执行结果,也即获取整个表达式的值。以 c=$((a+b))为例,即将 a+b 这个表达式的运算结果赋值给变量 c。
注意,类似 c=((a+b)) 这样的写法是错误的,不加$就不能取得表达式的结果。
((a>7 && b==c)) (( )) 也可以进行逻辑运算,在 if 语句中常会使用逻辑运算。
echo $((a+10)) 需要立即输出表达式的运算结果时,可以在 (( )) 前面加$符号。
((a=3+5, b=a+10)) 对多个表达式同时进行计算。
在 (( )) 中使用变量无需加上$前缀,(( )) 会自动解析变量名,这使得代码更加简洁,也符合程序员的书写习惯。
Shell let命令:对整数进行数学运算
let 命令和双小括号 (( )) 的用法是类似的,它们都是用来对整数进行运算,读者已经学习了《Shell (())》,再学习 let 命令就相当简单了。
注意:和双小括号 (( )) 一样,let 命令也只能进行整数运算,不能对小数(浮点数)或者字符串进行运算。
Shell let 命令的语法格式为:
let 表达式
或者
let "表达式"
或者
let '表达式'
它们都等价于((表达式))。
Shell if else语句
和其它编程语言类似,Shell 也支持选择结构,并且有两种形式,分别是 if else 语句和 case in 语句。
最简单的用法就是只使用 if 语句,它的语法格式为:
if condition
then
statement(s)
fi
condition是判断条件,如果 condition 成立(返回“真”),那么 then 后边的语句将会被执行;如果 condition 不成立(返回“假”),那么不会执行任何语句。
注意,最后必须以fi来闭合,fi 就是 if 倒过来拼写。也正是有了 fi 来结尾,所以即使有多条语句也不需要用{ }包围起来。
如果你喜欢,也可以将 then 和 if 写在一行:
if condition; then
statement(s)
fi
请注意 condition 后边的分号;,当 if 和 then 位于同一行的时候,这个分号是必须的,否则会有语法错误。
下面是if…else…的实例:
#!/bin/bash
declare -i a b
read -p "please input a:" a
read -p "please input b:" b
if (($a==$b))
then
echo "two inputed nums is equl"
else
echo "two inputed nums is not qual"
fi
# 运行结果:
% ./test.sh
please input a:5
please input b:6
two inputed nums is not qual
if elif else 语句
Shell 支持任意数目的分支,当分支比较多时,可以使用 if elif else 结构,它的格式为:
if condition1
then
statement1
elif condition2
then
statement2
elif condition3
then
statement3
……
else
statementn
fi
注意,if 和 elif 后边都得跟着 then。
Shell退出状态
每一条 Shell 命令,不管是 Bash 内置命令(例如 cd、echo),还是外部的 Linux 命令(例如 ls、awk),还是自定义的 Shell 函数,当它退出(运行结束)时,都会返回一个比较小的整数值给调用(使用)它的程序,这就是命令的退出状态(exit statu)。
很多 Linux 命令其实就是一个C语言程序,熟悉C语言的读者都知道,main() 函数的最后都有一个return 0,如果程序想在中间退出,还可以使用exit 0,这其实就是C语言程序的退出状态。当有其它程序调用这个程序时,就可以捕获这个退出状态。
if 语句的判断条件,从本质上讲,判断的就是命令的退出状态。
按照惯例来说,退出状态为 0 表示“成功”;也就是说,程序执行完成并且没有遇到任何问题。除 0 以外的其它任何退出状态都为“失败”。
之所以说这是“惯例”而非“规定”,是因为也会有例外,比如 diff 命令用来比较两个文件的不同,对于“没有差别”的文件返回 0,对于“找到差别”的文件返回 1,对无效文件名返回 2。
有编程经验的读者请注意,Shell 的这个部分与你所熟悉的其它编程语言正好相反:在C语言、C++、Java、Python 中,0 表示“假”,其它值表示“真”。
在 Shell 中,有多种方式取得命令的退出状态,其中 $? 是最常见的一种。
退出状态和逻辑运算符的组合
Shell if 语句的一个神奇之处是允许我们使用逻辑运算符将多个退出状态组合起来,这样就可以一次判断多个条件了。
Shell 逻辑运算符
运算符 使用格式 说明
&& expression1 && expression2 逻辑与运算符,当 expression1 和 expression2 同时成立时,整个表达式才成立。(如果检测到 expression1 的退出状态为 0,就不会再检测 expression2 了,因为不管 expression2 的退出状态是什么,整个表达式必然都是不成立的,检测了也是多此一举。)
|| expression1 || expression2 逻辑或运算符,expression1 和 expression2 两个表达式中只要有一个成立,整个表达式就成立。(如果检测到 expression1 的退出状态为 1,就不会再检测 expression2 了,因为不管 expression2 的退出状态是什么,整个表达式必然都是成立的,检测了也是多此一举。)
! !expression 逻辑非运算符,相当于“取反”的效果。如果 expression 成立,那么整个表达式就不成立;如果 expression 不成立,那么整个表达式就成立。
先建立一个txt结尾的文件,以执行以下的脚本用:
#!/bin/bash
read filename
read str
if test -w $filename && test -n $str
then
echo $url > $filename
echo "写入成功"
else
echo "写入失败"
fi
test 是 Shell 内置命令,可以对文件或者字符串进行检测,其中,-w选项用来检测文件是否存在并且可写,-n选项用来检测字符串是否非空。
>表示重定向,默认情况下,echo 向控制台输出,这里我们将输出结果重定向到文件。
Shell test命令(Shell [])详解,附带所有选项及说明
test 是 Shell 内置命令,用来检测某个条件是否成立。test 通常和 if 语句一起使用,并且大部分 if 语句都依赖 test。
test 命令有很多选项,可以进行数值、字符串和文件三个方面的检测。
Shell test 命令的用法为:
test expression
当 test 判断 expression 成立时,退出状态为 0,否则为非 0 值。
test 命令也可以简写为[],它的用法为:
[ expression ]
注意[]和expression之间的空格,这两个空格是必须的,否则会导致语法错误。[ ]的写法更加简洁,比 test 使用频率高。
1) 与文件检测相关的 test 选项
test 文件检测相关选项列表
文件类型判断
选 项 作 用
-b filename 判断文件是否存在,并且是否为块设备文件。
-c filename 判断文件是否存在,并且是否为字符设备文件。
-d filename 判断文件是否存在,并且是否为目录文件。
-e filename 判断文件是否存在。
-f filename 判断文件是否存在,井且是否为普通文件。
-L filename 判断文件是否存在,并且是否为符号链接文件。
-p filename 判断文件是否存在,并且是否为管道文件。
-s filename 判断文件是否存在,并且是否为非空。
-S filename 判断该文件是否存在,并且是否为套接字文件。
文件权限判断
选 项 作 用
-r filename 判断文件是否存在,并且是否拥有读权限。
-w filename 判断文件是否存在,并且是否拥有写权限。
-x filename 判断文件是否存在,并且是否拥有执行权限。
-u filename 判断文件是否存在,并且是否拥有 SUID 权限。
-g filename 判断文件是否存在,并且是否拥有 SGID 权限。
-k filename 判断该文件是否存在,并且是否拥有 SBIT 权限。
文件比较
选 项 作 用
filename1 -nt filename2 判断 filename1 的修改时间是否比 filename2 的新。
filename -ot filename2 判断 filename1 的修改时间是否比 filename2 的旧。
filename1 -ef filename2 判断 filename1 是否和 filename2 的 inode 号一致,可以理解为两个文件是否为同一个文件。这个判断用于判断硬链接是很好的方法
- 与数值比较相关的 test 选项
test 数值比较相关选项列表
选 项 作 用
num1 -eq num2 判断 num1 是否和 num2 相等。
num1 -ne num2 判断 num1 是否和 num2 不相等。
num1 -gt num2 判断 num1 是否大于 num2 。
num1 -lt num2 判断 num1 是否小于 num2。
num1 -ge num2 判断 num1 是否大于等于 num2。
num1 -le num2 判断 num1 是否小于等于 num2。
注意,test 只能用来比较整数,小数相关的比较还得依赖 bc 命令。
#!/bin/bash
read a b
if test $a -eq $b
then
echo "两个数相等"
else
echo "两个数不相等"
fi
- 与字符串判断相关的 test 选项
test 字符串判断相关选项列表
选 项 作 用
-z str 判断字符串 str 是否为空。
-n str 判断宇符串 str 是否为非空。
str1 = str2 str1 == str2 =和==是等价的,都用来判断 str1 是否和 str2 相等。
str1 != str2 判断 str1 是否和 str2 不相等。
str1 \> str2 判断 str1 是否大于 str2。\>是>的转义字符,这样写是为了防止>被误认为成重定向运算符。
str1 \< str2 判断 str1 是否小于 str2。同样,\<也是转义字符。
有C语言、C++、Python、Java 等编程经验的读者请注意,==、>、< 在大部分编程语言中都用来比较数字,而在 Shell 中,它们只能用来比较字符串,不能比较数字,这是非常奇葩的,大家要习惯。
其次,不管是比较数字还是字符串,Shell 都不支持 >= 和 <= 运算符,切记。
4) 与逻辑运算相关的 test 选项
test 逻辑运算相关选项列表
选 项 作 用
expression1 -a expression 逻辑与,表达式 expression1 和 expression2 都成立,最终的结果才是成立的。
expression1 -o expression2 逻辑或,表达式 expression1 和 expression2 有一个成立,最终的结果就成立。
!expression 逻辑非,对 expression 进行取反。
#!/bin/bash
read str1
read str2
#检测字符串是否为空
if [ -z "$str1" -o -z "$str2" ] #使用 -o 选项取代之前的 ||
then
echo "字符串不能为空"
exit 0
fi
#比较字符串
if [ $str1 = $str2 ]
then
echo "两个字符串相等"
else
echo "两个字符串不相等"
fi
前面的代码我们使用两个[]命令,并使用||运算符将它们连接起来,这里我们改成-o选项,只使用一个[]命令就可以了。
test 命令比较奇葩,>、<、== 只能用来比较字符串,不能用来比较数字,比较数字需要使用 -eq、-gt 等选项;不管是比较字符串还是数字,test 都不支持 >= 和 <=。
在 test 中使用变量建议用双引号包围起来
test 和 [] 都是命令,一个命令本质上对应一个程序或者一个函数。即使是一个程序,它也有入口函数,例如C语言程序的入口函数是 main(),运行C语言程序就从 main() 函数开始,所以也可以将一个程序等效为一个函数,这样我们就不用再区分函数和程序了,直接将一个命令和一个函数对应起来即可。
有了以上认知,就很容易看透命令的本质了:使用一个命令其实就是调用一个函数,命令后面附带的选项和参数最终都会作为实参传递给函数。
假设 test 命令对应的函数是 func(),使用test -z $str1命令时,会先将变量 $str1 替换成字符串:
如果 $str1 是一个正常的字符串,比如 abc123,那么替换后的效果就是test -z abc123,调用 func() 函数的形式就是func("-z abc123")。test 命令后面附带的所有选项和参数会被看成一个整体,并作为实参传递进函数。
如果 $str1 是一个空字符串,那么替换后的效果就是test -z,调用 func() 函数的形式就是func("-z “),这就比较奇怪了,因为-z选项没有和参数成对出现,func() 在分析时就会出错。
如果我们给 $str1 变量加上双引号,当 s t r 1 是 空 字 符 串 时 , t e s t − z " str1 是空字符串时,test -z " str1是空字符串时,test−z"str1"就会被替换为test -z “”,调用 func() 函数的形式就是func(”-z “”"),很显然,-z选项后面跟的是一个空字符串(“表示转义字符),这样 func() 在分析时就不会出错了。
所以,当你在 test 命令中使用变量时,我强烈建议将变量用双引号”"包围起来,这样能避免变量为空值时导致的很多奇葩问题。
Shell [[]]详解:检测某个条件是否成立
[[ ]]是 Shell 内置关键字,它和 test 命令类似,也用来检测某个条件是否成立。
test 能做到的,[[ ]] 也能做到,而且 [[ ]] 做的更好;test 做不到的,[[ ]] 还能做到。可以认为 [[ ]] 是 test 的升级版,对细节进行了优化,并且扩展了一些功能。
[[ ]] 的用法为:
[[ expression ]]
当 [[ ]] 判断 expression 成立时,退出状态为 0,否则为非 0 值。注意[[ ]]和expression之间的空格,这两个空格是必须的,否则会导致语法错误。
[[ ]] 不需要注意某些细枝末节
[[ ]] 是 Shell 内置关键字,不是命令,在使用时没有给函数传递参数的过程,所以 test 命令的某些注意事项在 [[ ]] 中就不存在了,具体包括:
不需要把变量名用双引号""包围起来,即使变量是空值,也不会出错。
不需要、也不能对 >、< 进行转义,转义后会出错。
#!/bin/bash
read -p "input str1:" str1
read -p "input str2:" str2
if [[ -z $str1 ]] || [[ -z $str2 ]]
then
echo "Str cann't be NULL"
elif [[ $str1 < $str2 ]]
then
echo "str1
else
echo "str1>=str2"
fi
[[ ]] 支持逻辑运算符
对多个表达式进行逻辑运算时,可以使用逻辑运算符将多个 test 命令连接起来,例如:
[ -z “$str1” ] || [ -z “$str2” ]
你也可以借助选项把多个表达式写在一个 test 命令中,例如:
[ -z “$str1” -o -z “$str2” ]
但是,这两种写法都有点“别扭”,完美的写法是在一个命令中使用逻辑运算符将多个表达式连接起来。我们的这个愿望在 [[ ]] 中实现了,[[ ]] 支持 &&、|| 和 ! 三种逻辑运算符。
使用 [[ ]] 对上面的语句进行改进:
[[ -z $str1 || -z $str2 ]]
这种写法就比较简洁漂亮了。
注意,[[ ]] 剔除了 test 命令的-o和-a选项,你只能使用 || 和 &&。这意味着,你不能写成下面的形式:
[[ -z $str1 -o -z $str2 ]]
当然,使用逻辑运算符将多个 [[ ]] 连接起来依然是可以的,因为这是 Shell 本身提供的功能,跟 [[ ]] 或者 test 没有关系,如下所示:
[[ -z $str1 ]] || [[ -z $str2 ]]
[[ ]] 支持正则表达式
在 Shell [[ ]] 中,可以使用=~来检测字符串是否符合某个正则表达式,它的用法为:
[[ str =~ regex ]]
str 表示字符串,regex 表示正则表达式。
Shell case in语句详解
当分支较多,并且判断条件比较简单时,使用 case in 语句就比较方便了。
《Shell if else》一节的最后给出了一个例子,就是输入一个整数,输出该整数对应的星期几的英文表示,这节我们就用 case in 语句来重写代码,如下所示。
#!/bin/bash
printf "Input integer number: "
read num
case $num in
1)
echo "Monday"
;;
2)
echo "Tuesday"
;;
3)
echo "Wednesday"
;;
4)
echo "Thursday"
;;
5)
echo "Friday"
;;
6)
echo "Saturday"
;;
7)
echo "Sunday"
;;
*)
echo "error"
esac
# 运行结果:
Input integer number:3↙
Wednesday
case、in 和 esac 都是 Shell 关键字,expression 表示表达式,pattern 表示匹配模式。
expression 既可以是一个变量、一个数字、一个字符串,还可以是一个数学计算表达式,或者是命令的执行结果,只要能够得到 expression 的值就可以。
pattern 可以是一个数字、一个字符串,甚至是一个简单的正则表达式。
case 会将 expression 的值与 pattern1、pattern2、pattern3 逐个进行匹配:
如果 expression 和某个模式(比如 pattern2)匹配成功,就会执行这模式(比如 pattern2)后面对应的所有语句(该语句可以有一条,也可以有多条),直到遇见双分号;;才停止;然后整个 case 语句就执行完了,程序会跳出整个 case 语句,执行 esac 后面的其它语句。
如果 expression 没有匹配到任何一个模式,那么就执行*)后面的语句(*表示其它所有值),直到遇见双分号;;或者esac才结束*)相当于多个 if 分支语句中最后的 else 部分。
如果你有C语言、C++、Java 等编程经验,这里的;;和*)就相当于其它编程语言中的 break 和 default。
对*)的几点说明:
Shell case in 语句中的*)用来“托底”,万一 expression 没有匹配到任何一个模式,*)部分可以做一些“善后”工作,或者给用户一些提示。
可以没有*)部分。如果 expression 没有匹配到任何一个模式,那么就不执行任何操作。
除最后一个分支外(这个分支可以是普通分支,也可以是*)分支),其它的每个分支都必须以;;结尾,;;代表一个分支的结束,不写的话会有语法错误。最后一个分支可以写;;,也可以不写,因为无论如何,执行到 esac 都会结束整个 case in 语句。
上面的代码是 case in 最常见的用法,即 expression 部分是一个变量,pattern 部分是一个数字或者表达式。
case in 和正则表达式
case in 的 pattern 部分支持简单的正则表达式,具体来说,可以使用以下几种格式:
格式 说明
* 表示任意字符串。
[abc] 表示 a、b、c 三个字符中的任意一个。比如,[15ZH] 表示 1、5、Z、H 四个字符中的任意一个。
[m-n] 表示从 m 到 n 的任意一个字符。比如,[0-9] 表示任意一个数字,[0-9a-zA-Z] 表示字母或数字。
| 表示多重选择,类似逻辑运算中的或运算。比如,abc | xyz 表示匹配字符串 "abc" 或者 "xyz"。
如果不加以说明,Shell 的值都是字符串,expression 和 pattern 也是按照字符串的方式来匹配的;本节第一段代码看起来是判断数字是否相等,其实是判断字符串是否相等。
最后一个分支*)并不是什么语法规定,它只是一个正则表达式,表示任意字符串,所以不管 expression 的值是什么,)总能匹配成功。
Shell while循环
while 循环是 Shell 脚本中最简单的一种循环,当条件满足时,while 重复地执行一组语句,当条件不满足时,就退出 while 循环。
Shell while 循环的用法如下:
while condition
do
statements
done
condition表示判断条件,statements表示要执行的语句(可以只有一条,也可以有多条),do和done都是 Shell 中的关键字。
while 循环的执行流程为:
先对 condition 进行判断,如果该条件成立,就进入循环,执行 while 循环体中的语句,也就是 do 和 done 之间的语句。这样就完成了一次循环。
每一次执行到 done 的时候都会重新判断 condition 是否成立,如果成立,就进入下一次循环,继续执行 do 和 done 之间的语句,如果不成立,就结束整个 while 循环,执行 done 后面的其它 Shell 代码。
如果一开始 condition 就不成立,那么程序就不会进入循环体,do 和 done 之间的语句就没有执行的机会。
注意,在 while 循环体中必须有相应的语句使得 condition 越来越趋近于“不成立”,只有这样才能最终退出循环,否则 while 就成了死循环,会一直执行下去,永无休止。
计算从 1 加到 100 的和:
i=1
sum=0
while ((i <= 100))
do
((sum += i))
((i++))
done
echo "The sum is: $sum"
# 运行结果:
The sum is: 5050
Shell until循环用法
unti 循环和 while 循环恰好相反,当判断条件不成立时才进行循环,一旦判断条件成立,就终止循环。
until 的使用场景很少,一般使用 while 即可。
Shell until 循环的用法如下:
until condition
do
statements
done
condition表示判断条件,statements表示要执行的语句(可以只有一条,也可以有多条),do和done都是 Shell 中的关键字。
until 循环的执行流程为:
先对 condition 进行判断,如果该条件不成立,就进入循环,执行 until 循环体中的语句(do 和 done 之间的语句),这样就完成了一次循环。
每一次执行到 done 的时候都会重新判断 condition 是否成立,如果不成立,就进入下一次循环,继续执行循环体中的语句,如果成立,就结束整个 until 循环,执行 done 后面的其它 Shell 代码。
如果一开始 condition 就成立,那么程序就不会进入循环体,do 和 done 之间的语句就没有执行的机会。
注意,在 until 循环体中必须有相应的语句使得 condition 越来越趋近于“成立”,只有这样才能最终退出循环,否则 until 就成了死循环,会一直执行下去,永无休止。
Shell for循环和for int循环
C语言风格的 for 循环的用法如下:
for((exp1; exp2; exp3))
do
statements
done
几点说明:
exp1、exp2、exp3 是三个表达式,其中 exp2 是判断条件,for 循环根据 exp2 的结果来决定是否继续下一次循环;
statements 是循环体语句,可以有一条,也可以有多条;
do 和 done 是 Shell 中的关键字。
for 循环中的 exp1(初始化语句)、exp2(判断条件)和 exp3(自增或自减)都是可选项,都可以省略(但分号;必须保留)。
Python 风格的 for in 循环的用法如下:
for variable in value_list
do
statements
done
variable 表示变量,value_list 表示取值列表,in 是 Shell 中的关键字。
in value_list 部分可以省略,省略后的效果相当于 in $@。
每次循环都会从 value_list 中取出一个值赋给变量 variable,然后进入循环体(do 和 done 之间的部分),执行循环体中的 statements。直到取完 value_list 中的所有值,循环就结束了。
对 value_list 的说明
取值列表 value_list 的形式有多种,你可以直接给出具体的值,也可以给出一个范围,还可以使用命令产生的结果,甚至使用通配符,下面我们一一讲解。
- 直接给出具体的值
可以在 in 关键字后面直接给出具体的值,多个值之间以空格分隔,比如1 2 3 4 5、“abc” “390” "tom"等。 - 给出一个取值范围
给出一个取值范围的具体格式为:{start…end}
start 表示起始值,end 表示终止值;注意中间用两个点号相连,而不是三个点号。根据笔者的实测,这种形式只支持数字和字母。Shell 是根据 ASCII 码表来输出的。 - 使用命令的执行结果
使用反引号``或者$()都可以取得命令的执行结果。
ls 是一个 Linux 命令,用来列出当前目录下的所有文件,*.sh表示匹配后缀为.sh的文件,也就是 Shell 脚本文件。 - 使用 Shell 通配符
Shell 通配符可以认为是一种精简化的正则表达式,通常用来匹配目录或者文件,而不是文本。 - 使用特殊变量
Shell 中有多个特殊的变量,例如 $#、$*、$@、$?、$$ 等,在 value_list 中就可以使用它们。其实,我们也可以省略 value_list,省略后的效果和使用$@一样。
Shell select in循环
select in 循环用来增强交互性,它可以显示出带编号的菜单,用户输入不同的编号就可以选择不同的菜单,并执行不同的功能。
select in 是 Shell 独有的一种循环,非常适合终端(Terminal)这样的交互场景,C语言、C++、Java、Python、C# 等其它编程语言中是没有的。
Shell select in 循环的用法如下:
select variable in value_list
do
statements
done
variable 表示变量,value_list 表示取值列表,in 是 Shell 中的关键字。select in 和 for in 的语法是多么地相似。
运行到 select 语句后,取值列表 value_list 中的内容会以菜单的形式显示出来,用户输入菜单编号,就表示选中了某个值,这个值就会赋给变量 variable,然后再执行循环体中的 statements(do 和 done 之间的部分)。
每次循环时 select 都会要求用户输入菜单编号,并使用环境变量 PS3 的值作为提示符,PS3 的默认值为#?,修改 PS3 的值就可以修改提示符。
如果用户输入的菜单编号不在范围之内,那么就会给 variable 赋一个空值;如果用户输入一个空值(什么也不输入,直接回车),会重新显示一遍菜单。
#!/bin/bash
echo "what your favourate OS?"
select name in "Linux" "Windows" "Mac OS" "UNIX" "Android"
do
echo $name
done
echo "Your choice is $name"
Shell break和continue跳出循环
使用 while、until、for、select 循环时,如果想提前结束循环(在不满足结束条件的情况下结束循环),可以使用 break 或者 continue 关键字。
在C语言、C++、C#、Python、Java 等大部分编程语言中,break 和 continue 只能跳出当前层次的循环,内层循环中的 break 和 continue 对外层循环不起作用;但是 Shell 中的 break 和 continue 却能够跳出多层循环,也就是说,内层循环中的 break 和 continue 能够跳出外层循环。
在实际开发中,break 和 continue 一般只用来跳出当前层次的循环,很少有需要跳出多层循环的情况。
Shell break 关键字的用法为:
break n
n 表示跳出循环的层数,如果省略 n,则表示跳出当前的整个循环。break 关键字通常和 if 语句一起使用,即满足条件时便跳出循环。
Shell continue 关键字的用法为:
continue n
n 表示循环的层数:
如果省略 n,则表示 continue 只对当前层次的循环语句有效,遇到 continue 会跳过本次循环,忽略本次循环的剩余代码,直接进入下一次循环。
如果带上 n,比如 n 的值为 2,那么 continue 对内层和外层循环语句都有效,不但内层会跳过本次循环,外层也会跳过本次循环,其效果相当于内层循环和外层循环同时执行了不带 n 的 continue。这么说可能有点难以理解,稍后我们通过代码来演示。
continue 关键字也通常和 if 语句一起使用,即满足条件时便跳出循环。
break 和 continue 的区别
break 用来结束所有循环,循环语句不再有执行的机会;continue 用来结束本次循环,直接跳到下一次循环,如果循环条件成立,还会继续循环。
Shell函数详解(函数定义、函数调用)
Shell 函数的本质是一段可以重复使用的脚本代码,这段代码被提前编写好了,放在了指定的位置,使用时直接调取即可。
Shell 中的函数和C++、Java、Python、C# 等其它编程语言中的函数类似,只是在语法细节有所差别。
Shell 函数定义的语法格式如下:
function name() {
statements
[return value]
}
对各个部分的说明:
function是 Shell 中的关键字,专门用来定义函数;
name是函数名;
statements是函数要执行的代码,也就是一组语句;
return value表示函数的返回值,其中 return 是 Shell 关键字,专门用在函数中返回一个值;这一部分可以写也可以不写。
由{ }包围的部分称为函数体,调用一个函数,实际上就是执行函数体中的代码。
函数定义的简化写法
如果你嫌麻烦,函数定义时也可以不写 function 关键字:
name() {
statements
[return value]
}
如果写了 function 关键字,也可以省略函数名后面的小括号:
function name {
statements
[return value]
}
函数调用
调用 Shell 函数时可以给它传递参数,也可以不传递。如果不传递参数,直接给出函数名字即可:name
如果传递参数,那么多个参数之间以空格分隔:
name param1 param2 param3
不管是哪种形式,函数名字后面都不需要带括号。
和其它编程语言不同的是,Shell 函数在定义时不能指明参数,但是在调用时却可以传递参数,并且给它传递什么参数它就接收什么参数。
Shell 也不限制定义和调用的顺序,你可以将定义放在调用的前面,也可以反过来,将定义放在调用的后面,最好按照先定义再调用的顺序写,不然可能会出错。
Shell函数参数
和 C++、C#、Python 等大部分编程语言不同,Shell 中的函数在定义时不能指明参数,但是在调用时却可以传递参数。
函数参数是 Shell 位置参数的一种,在函数内部可以使用$n来接收,例如,$1 表示第一个参数,$2 表示第二个参数,依次类推。
除了$n,还有另外三个比较重要的变量:
$#可以获取传递的参数的个数;
$@或者$*可以一次性获取所有的参数。
Linux Shell重定向(输入输出重定向)
Linux Shell 重定向分为两种,一种输入重定向,一种是输出重定向;从字面上理解,输入输出重定向就是「改变输入与输出的方向」的意思。
那么,什么是输入输出方向呢?标准的输入输出方向又是什么呢?
一般情况下,我们都是从键盘读取用户输入的数据,然后再把数据拿到程序(C语言程序、Shell 脚本程序等)中使用;这就是标准的输入方向,也就是从键盘到程序。
反过来说,程序中也会产生数据,这些数据一般都是直接呈现到显示器上,这就是标准的输出方向,也就是从程序到显示器。
我们可以把观点提炼一下,其实输入输出方向就是数据的流动方向:
输入方向就是数据从哪里流向程序。数据默认从键盘流向程序,如果改变了它的方向,数据就从其它地方流入,这就是输入重定向。
输出方向就是数据从程序流向哪里。数据默认从程序流向显示器,如果改变了它的方向,数据就流向其它地方,这就是输出重定向。
硬件设备和文件描述符
计算机的硬件设备有很多,常见的输入设备有键盘、鼠标、麦克风、手写板等,输出设备有显示器、投影仪、打印机等。不过,在 Linux 中,标准输入设备指的是键盘,标准输出设备指的是显示器。
Linux 中一切皆文件,包括标准输入设备(键盘)和标准输出设备(显示器)在内的所有计算机硬件都是文件。
为了表示和区分已经打开的文件,Linux 会给每个文件分配一个 ID,这个 ID 就是一个整数,被称为文件描述符(File Descriptor)。
与输入输出有关的文件描述符
文件描述符 文件名 类型 硬件
0 stdin 标准输入文件 键盘
1 stdout 标准输出文件 显示器
2 stderr 标准错误输出文件 显示器
Linux 程序在执行任何形式的 I/O 操作时,都是在读取或者写入一个文件描述符。一个文件描述符只是一个和打开的文件相关联的整数,它的背后可能是一个硬盘上的普通文件、FIFO、管道、终端、键盘、显示器,甚至是一个网络连接。
stdin、stdout、stderr 默认都是打开的,在重定向的过程中,0、1、2 这三个文件描述符可以直接使用。
Linux Shell 输出重定向
输出重定向是指命令的结果不再输出到显示器上,而是输出到其它地方,一般是文件中。这样做的最大好处就是把命令的结果保存起来,当我们需要的时候可以随时查询。Bash 支持的输出重定向符号如下表所示。
Bash 支持的输出重定向符号
类 型 符 号 作 用
标准输出重定向 command >file 以覆盖的方式,把 command 的正确输出结果输出到 file 文件中。
command >>file 以追加的方式,把 command 的正确输出结果输出到 file 文件中。
标准错误输出重定向 command 2>file 以覆盖的方式,把 command 的错误信息输出到 file 文件中。
command 2>>file 以追加的方式,把 command 的错误信息输出到 file 文件中。
正确输出和错误信息同时保存 command >file 2>&1 以覆盖的方式,把正确输出和错误信息同时保存到同一个文件(file)中。
command >>file 2>&1 以追加的方式,把正确输出和错误信息同时保存到同一个文件(file)中。
command >file1 2>file2 以覆盖的方式,把正确的输出结果输出到 file1 文件中,把错误信息输出到 file2 文件中。
command >>file1 2>>file2 以追加的方式,把正确的输出结果输出到 file1 文件中,把错误信息输出到 file2 文件中。
command >file 2>file 【不推荐】这两种写法会导致 file 被打开两次,引起资源竞争,所以 stdout 和 stderr 会互相覆盖
command >>file 2>>file
在输出重定向中,>代表的是覆盖,>>代表的是追加。
注意
输出重定向的完整写法其实是fd>file或者fd>>file,其中 fd 表示文件描述符,如果不写,默认为 1,也就是标准输出文件。
当文件描述符为 1 时,一般都省略不写,如上表所示;当然,如果你愿意,也可以将command >file写作command 1>file,但这样做是多此一举。
当文件描述符为大于 1 的值时,比如 2,就必须写上。
需要重点说明的是,fd和>之间不能有空格,否则 Shell 会解析失败;>和file之间的空格可有可无。为了保持一致,我习惯在>两边都不加空格。
/dev/null 文件
如果你既不想把命令的输出结果保存到文件,也不想把命令的输出结果显示到屏幕上,干扰命令的执行,那么可以把命令的所有结果重定向到 /dev/null 文件中。如下所示:
ls -l &>/dev/null
大家可以把 /dev/null 当成 Linux 系统的垃圾箱,任何放入垃圾箱的数据都会被丢弃,不能恢复。
Linux Shell 输入重定向
输入重定向就是改变输入的方向,不再使用键盘作为命令输入的来源,而是使用文件作为命令的输入。
Bash 支持的输出重定向符号
符号 说明
command <file 将 file 文件中的内容作为 command 的输入。
command <<END 从标准输入(键盘)中读取数据,直到遇见分界符 END 才停止(分界符可以是任意的字符串,用户自己定义)。
command <file1 >file2 将 file1 作为 command 的输入,并将 command 的处理结果输出到 file2。
和输出重定向类似,输入重定向的完整写法是fd<file,其中 fd 表示文件描述符,如果不写,默认为 0,也就是标准输入文件。
Linux Shell管道
我们已经知道了怎样从文件重定向输入,以及重定向输出到文件。Shell 还有一种功能,就是可以将两个或者多个命令(程序或者进程)连接到一起,把一个命令的输出作为下一个命令的输入,以这种方式连接的两个或者多个命令就形成了管道(pipe)。
Linux 管道使用竖线|连接多个命令,这被称为管道符。Linux 管道的具体语法格式如下:
command1 | command2
command1 | command2 [ | commandN... ]
当在两个命令之间设置管道时,管道符|左边命令的输出就变成了右边命令的输入。只要第一个命令向标准输出写入,而第二个命令是从标准输入读取,那么这两个命令就可以形成一个管道。大部分的 Linux 命令都可以用来形成管道。
这里需要注意,command1 必须有正确输出,而 command2 必须可以处理 command2 的输出结果;而且 command2 只能处理 command1 的正确输出结果,不能处理 command1 的错误信息。
重定向和管道的区别
乍看起来,管道也有重定向的作用,它也改变了数据输入输出的方向,那么,管道和重定向之间到底有什么不同呢?
简单地说,重定向操作符>将命令与文件连接起来,用文件来接收命令的输出;而管道符|将命令与命令连接起来,用第二个命令来接收第一个命令的输出。如下所示:
command > file
command1 | command1
尝试如下的命令,我们来看一下会发生什么:
command1 > command2
答案是,有时尝试的结果将会很糟糕。这是一个实际的例子,一个 Linux 系统管理员以超级用户(root 用户)的身份执行了如下命令:
cd /usr/bin
ls > less
第一条命令将当前目录切换到了大多数程序所存放的目录,第二条命令是告诉 Shell 用 ls 命令的输出重写文件 less。因为 /usr/bin 目录已经包含了名称为 less(less 程序)的文件,第二条命令用 ls 输出的文本重写了 less 程序,因此破坏了文件系统中的 less 程序。
这是使用重定向操作符错误重写文件的一个教训,所以在使用它时要谨慎。
Linux管道实例
【实例1】将 ls 命令的输出发送到 grep 命令:
$ ls | grep log.txt
log.txt
上述命令是查看文件 log.txt 是否存在于当前目录下。
我们可以在命令的后面使用选项,例如使用-al选项:
$ ls -al | grep log.txt
-rw-rw-r--. 1 mozhiyan mozhiyan 10月 06 21:26 log.txt
管道符|与两侧的命令之间也可以不存在空格,例如将上述命令写作ls -al|grep log.txt;然而我还是推荐在管道符|和两侧的命令之间使用空格,以增加代码的可读性。
我们也可以重定向管道的输出到一个文件,比如将上述管道命令的输出结果发送到文件 output.txt 中:
$ ls -al | grep log.txt >output.txt
【实例2】使用管道将 cat 命令的输出作为 less 命令的输入,这样就可以将 cat 命令的输出每次按照一个屏幕的长度显示,这对于查看长度大于一个屏幕的文件内容很有帮助。
cat /var/log/message | less
【实例3】查看指定程序的进程运行状态,并将输出重定向到文件中。
# ps是用来查看当前运行的进程的
$ ps aux | grep httpd > /tmp/ps.output
实例4】显示按用户名排序后的当前登录系统的用户的信息。
% who | sort
k console Oct 7 14:16
k ttys000 Oct 7 14:21
k ttys001 Oct 7 20:47
【实例5】统计系统中当前登录的用户数。
# wc -l用来显示当前输入文件内容中的行数
% who | wc -l
3
管道与输入重定向
输入重定向操作符<可以在管道中使用,以用来从文件中获取输入,其语法类似下面这样:
command1 < input.txt | command2
command1 < input.txt | command2 -option | command3
管道与输出重定向
你也可以使用重定向操作符>或>>将管道中的最后一个命令的标准输出进行重定向,其语法如下所示:
command1 | command2 | ... | commandN > output.txt
command1 < input.txt | command2 | ... | commandN > output.txt
Shell过滤器
我们己经知道,将几个命令通过管道符组合在一起就形成一个管道。通常,通过这种方式使用的命令就被称为过滤器。过滤器会获取输入,通过某种方式修改其内容,然后将其输出。
简单地说,过滤器可以概括为以下两点:
如果一个 Linux 命令是从标准输入接收它的输入数据,并在标准输出上产生它的输出数据(结果),那么这个命令就被称为过滤器。
过滤器通常与 Linux 管道一起使用。
常用的被作为过滤器使用的命令如下所示:
命令 说明
awk 用于文本处理的解释性程序设计语言,通常被作为数据提取和报告的工具。
cut 用于将每个输入文件(如果没有指定文件则为标准输入)的每行的指定部分输出到标准输出。
grep 用于搜索一个或多个文件中匹配指定模式的行。
tar 用于归档文件的应用程序。
head 用于读取文件的开头部分(默认是 10 行)。如果没有指定文件,则从标准输入读取。
paste 用于合并文件的行。
sed 用于过滤和转换文本的流编辑器。
sort 用于对文本文件的行进行排序。
split 用于将文件分割成块。
strings 用于打印文件中可打印的字符串。
tac 与 cat 命令的功能相反,用于倒序地显示文件或连接文件。
tail 用于显示文件的结尾部分。
tee 用于从标准输入读取内容并写入到标准输出和文件。
tr 用于转换或删除字符。
uniq 用于报告或忽略重复的行。
wc 用于打印文件中的总行数、单词数或字节数。
在管道中使用 cut 命令
cut 命令被用于文本处理。你可以使用这个命令来提取文件中指定列的内容。
查看系统中登录 Shell 是“/bin/bash”的用户名和对应的用户主目录的信息:
$ grep "bin/bash" /etc/passwd | cut -d: -f1,6
root:/root
R:/home/R
如果你对 Linux 系统有所了解,你会知道,/ctc/passwd 文件被用来存放用户账号的信息,此文件中的每一行会记录一个账号的信息,每个字段之间用冒号分隔,第一个字段即是账号的账户名,而第六个字段就是账号的主目录的路径。
查看当前目录下的子目录数。
$ ls -l | cut -c 1 | grep d | wc -l
5
上述管道命令主要做了如下操作:
命令ls -l输出的内容中,每行的第一个字符表示文件的类型,如果第一个字符是d,就表示文件的类型是目录。
命令cut -c 1是截取每行的第一个字符。
命令grep d来获取文件类型是目录的行。
命令wc -l用来获得 grep 命令输出结果的行数,即目录个数。