计算机基础与其他笔记
文章目录
-
- tabby 终端工具
- 延时任务的几种设计
- 设计一个安全的对外接口
- 蓝绿部署和金丝雀发布
- APM 系统
- 秒杀系统的设计
- 常见的零拷贝技术
- https 加解密原理
- 阻塞/非阻塞 和 同步/异步
- post 请求是两个TCP包
- linux 查看端口命令
- 红黑树的五个特点
- B树,B+树,B*树,LSM树(log-structured merge-tree)
- 工具类应该屏蔽构造方法
- 虚拟内存
- 递归三个步骤
- 字符从内存输出,如何显示在屏幕
- 短链接的好处
- 如何设计高并发系统
- 缓存的本质思想是空间换时间
- 代码校验
- 10. 个人项目包命名
- 11. 类命名规范
- 需要分布式锁的两类场景
- 分布式事务的一种解决方案:事务消息+最终一致性
- 数据库事务的一致性指的是:不能破坏关系数据的完整性以及业务逻辑上的一致性。
- 分布式系统中,往往追求更高的可用性,不要求强一致性,BASE理论是对CAP理论的扩充,指Basically Available(基本可用)、Soft state(软状态)即允许状态有一段时间不同步、Eventually consistent(最终一致性)
- RPC常见误区
- solr 优化入手点
- 项目中各层的日志可以分开存储,日志输出时注意排除敏感信息
- 构建SaaS 时的最佳实践
- IaaS、PaaS、SaaS区分
- 服务调用时的超时时间设置
- Oauth2 流程
- 正向代理 和 反向代理
- 云和云原生的理解
- 8. maven常见scope
- 10. 可以用动态规划的题目特征
- 11. 二进制位运算中的一个技巧
- 网络物理层的作用
- 数据链路层总结
- 数据包传输的流程
- 网络层总结
- 传输层总结
- 应用层总结
- 三次握手
- 四次挥手
- TCP的可靠传输
- DNS解析
- 对于debug日志,必须判断是否为debug级别后,才进行使用
tabby 终端工具
支持 linux sftp powershell git
延时任务的几种设计
- 数据库轮询:
优点:简单易行,支持集群操作
缺点 :
(1)对服务器内存消耗大
(2)存在延迟,比如你每隔3分钟扫描一次,那最坏的延迟时间就是3分钟
(3)假设你的订单有几千万条,每隔几分钟这样扫描一次,数据库损耗极大 - JDK的DelayQueue 或 Netty的HashedWheelTimer
优点:效率高,任务触发时间延迟低
缺点 :
(1)服务器重启后,数据全部消失,怕宕机
(2)集群扩展相当麻烦
(3)容易出现OOM异常 - redis的zset
优点 :
(1)由于使用Redis作为消息通道,消息都存储在Redis中。如果发送程序或者任务处理程序挂了,重启之后,还有重新处理数据的可能性。
(2)做集群扩展相当方便
(3)时间准确度高
缺点 :
(1)需要额外进行redis维护 - redis的Keyspace Notifications
可以在key失效之后,提供一个回调,实际上是redis会给客户端发送一个消息。缺点是可靠性不高。Redis的发布/订阅目前是即发即弃(fire and forget)模式的。 - 利用支持延时消息的MQ
设计一个安全的对外接口
- 数据加密:https
- 数据加签:md5
- 时间戳机制:解密后的数据,拿到时间戳字段,判断请求时间是否合法
- 限流机制:常用的限流算法包括:固定窗口计数器算法、滑动窗口计数器算法、漏桶限流、令牌桶限流
- 黑名单
- 数据合法性校验
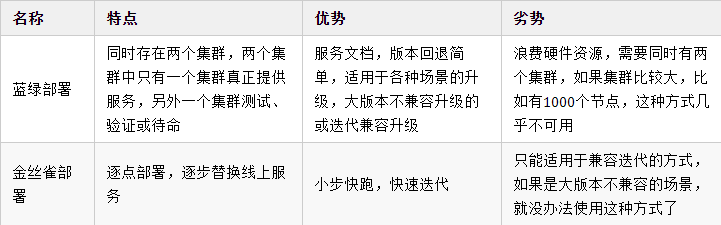
蓝绿部署和金丝雀发布
APM 系统
通常认为是 Application Performance Management 的简写,俗称监控系统。它主要有三个方面的内容,分别是 Logs(日志)、Traces(链路追踪) 和 Metrics(报表统计)
秒杀系统的设计
需要关注的方面:
- 超卖问题
- 高并发
- 接口防刷
- 秒杀url 防泄漏
- 数据库隔离设计
秒杀url的设计
为了避免有程序访问经验的人通过下单页面url直接访问后台接口来秒杀货品,我们需要将秒杀的url实现动态化。具体的做法就是通过md5加密一串随机字符作为秒杀的url,然后前端访问后台获取具体的url,后台校验通过之后才可以继续秒杀。
秒杀页面静态化
将商品的描述、参数、成交记录、图像、评价等全部写入到一个静态页面,用户请求不需要通过访问后端服务器,不需要经过数据库,直接在前台客户端生成,这样可以最大可能的减少服务器的压力。
单体redis升级为集群redis
秒杀是一个读多写少的场景,使用redis做缓存再合适不过。不过考虑到缓存击穿问题,我们应该构建redis集群,采用哨兵模式,可以提升redis的性能和可用性。
精简sql
典型的一个场景是在进行扣减库存的时候,传统的做法是先查询库存,再去update。这样的话需要两个sql,而实际上一个sql我们就可以完成的。可以用这样的做法:update miaosha_goods set stock =stock-1 where goos_id ={#goods_id} and version = #{version} and stock>0;这样的话,就可以保证库存不会超卖并且一次更新库存,还有注意一点这里使用了版本号的乐观锁,相比较悲观锁,它的性能较好。
redis预减库存
很多请求进来,都需要后台查询库存,这是一个频繁读的场景。可以使用redis来预减库存,在下单之前先扣除库存,如果库存不够就不会进入下单流程。如果下单失败再把库存加回去。
接口限流
秒杀最终的本质是数据库的更新,但是有很多大量无效的请求,我们最终要做的就是如何把这些无效的请求过滤掉,防止渗透到数据库。
首先第一步就是通过前端限流,用户在秒杀按钮点击以后发起请求,那么在接下来的5秒是无法点击(通过设置按钮为disable)。这一小举措开发起来成本很小,但是很有效。
后端可以设置同一个用户xx秒内重复请求直接拒绝。还可以加上令牌桶算法限流。
异步下单
最常采用的办法是使用队列,队列最显著的三个优点:异步、削峰、解耦 。下完单,入库没有问题可以用短信通知用户秒杀成功。假如失败的话,可以采用补偿机制,重试。
服务降级
假如在秒杀过程中出现了某个服务器宕机,或者服务不可用,应该做好后备工作。可以开发一个备用服务,假如服务器真的宕机了,直接给用户一个友好的提示返回,而不是直接卡死,服务器错误等生硬的反馈。

常见的零拷贝技术
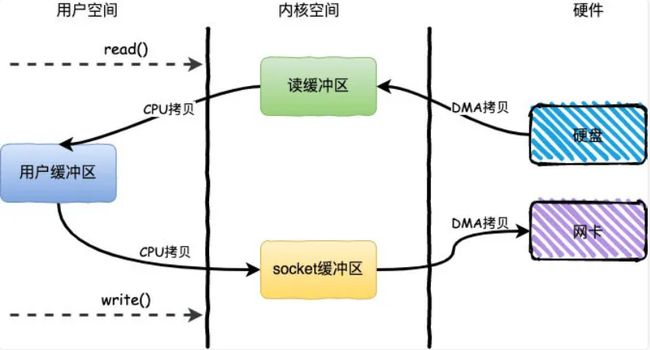
传统 IO 底层实际上通过调用read()和write()来实现。
整个过程发生了4次用户态和内核态的上下文切换和4次拷贝,具体流程如下:
- 用户进程通过read()方法向操作系统发起调用,此时上下文从用户态转向内核态
- DMA控制器把数据从硬盘中拷贝到读缓冲区
- CPU把读缓冲区数据拷贝到应用缓冲区,上下文从内核态转为用户态,read()返回
- 用户进程通过write()方法发起调用,上下文从用户态转为内核态
- CPU将应用缓冲区中数据拷贝到socket缓冲区
- DMA控制器把数据从socket缓冲区拷贝到网卡,上下文从内核态切换回用户态,write()返回
使用 DMA拷贝,因为对于一个IO操作而言,都是通过CPU发出对应的指令来完成,但是相比CPU来说,IO的速度太慢了,CPU有大量的时间处于等待IO的状态。因此就产生了DMA(Direct Memory Access)直接内存访问技术,本质上来说他就是一块主板上独立的芯片,通过它来进行内存和IO设备的数据传输,从而减少CPU的等待时间。
mmap+write:
mmap+write简单来说就是使用mmap替换了read+write中的read操作,减少了一次CPU的拷贝。mmap主要实现方式是将读缓冲区的地址和用户缓冲区的地址进行映射,内核缓冲区和应用缓冲区共享,从而减少了从读缓冲区到用户缓冲区的一次CPU拷贝。
整个过程发生了4次用户态和内核态的上下文切换和3次拷贝,具体流程如下:
- 用户进程通过mmap()方法向操作系统发起调用,上下文从用户态转向内核态
- DMA控制器把数据从硬盘中拷贝到读缓冲区
- 上下文从内核态转为用户态,mmap调用返回
- 用户进程通过write()方法发起调用,上下文从用户态转为内核态
- CPU将读缓冲区中数据拷贝到socket缓冲区
- DMA控制器把数据从socket缓冲区拷贝到网卡,上下文从内核态切换回用户态,write()返回
mmap的方式节省了一次CPU拷贝,同时由于用户进程中的内存是虚拟的,只是映射到内核的读缓冲区,所以可以节省一半的内存空间,比较适合大文件的传输。

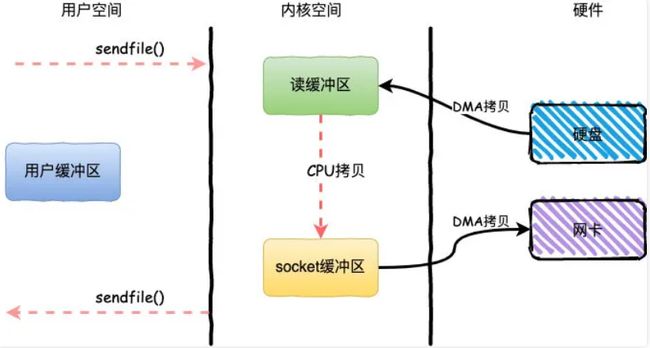
sendfile:
sendfile同样减少了一次CPU拷贝,而且还减少了2次上下文切换。通过使用sendfile数据可以直接在内核空间进行传输,因此避免了用户空间和内核空间的拷贝,同时由于使用sendfile替代了read+write从而节省了一次系统调用,也就是2次上下文切换。
整个过程发生了2次用户态和内核态的上下文切换和3次拷贝,具体流程如下:
- 用户进程通过sendfile()方法向操作系统发起调用,上下文从用户态转向内核态
- DMA控制器把数据从硬盘中拷贝到读缓冲区
- CPU将读缓冲区中数据拷贝到socket缓冲区
- DMA控制器把数据从socket缓冲区拷贝到网卡,上下文从内核态切换回用户态,sendfile调用返回
sendfile方法IO数据对用户空间完全不可见,所以只能适用于完全不需要用户空间处理的情况,比如静态文件服务器。
sendfile+DMA Scatter/Gather:
Linux2.4内核版本之后对sendfile做了进一步优化,通过引入新的硬件支持,这个方式叫做DMA Scatter/Gather 分散/收集功能。它将读缓冲区中的数据描述信息–内存地址和偏移量记录到socket缓冲区,由 DMA 根据这些将数据从读缓冲区拷贝到网卡,相比之前版本减少了一次CPU拷贝的过程。
整个过程发生了2次用户态和内核态的上下文切换和2次拷贝,其中更重要的是完全没有CPU拷贝,具体流程如下:
- 用户进程通过sendfile()方法向操作系统发起调用,上下文从用户态转向内核态
- DMA控制器利用scatter把数据从硬盘中拷贝到读缓冲区离散存储
- CPU把读缓冲区中的文件描述符和数据长度发送到socket缓冲区
- DMA控制器根据文件描述符和数据长度,使用scatter/gather把数据从内核缓冲区拷贝到网卡
- sendfile()调用返回,上下文从内核态切换回用户态

https 加解密原理
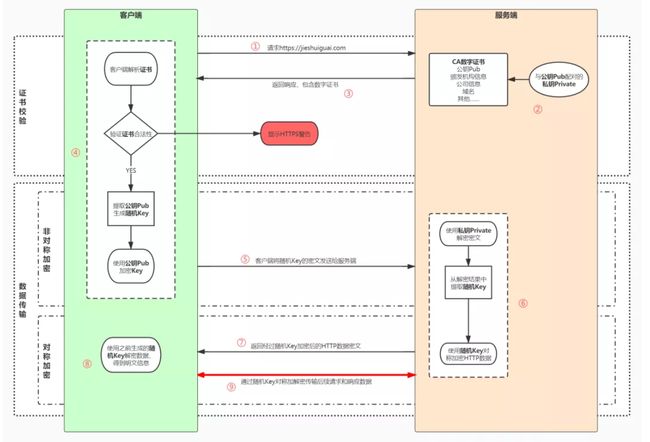
- 用户在浏览器发起HTTPS请求(如 https://www.mogu.com/),默认使用服务端的443端口进行连接;
- HTTPS需要使用一套CA数字证书,证书内会附带一个公钥Pub,而与之对应的私钥Private保留在服务端不公开;
- 服务端收到请求,返回配置好的包含公钥Pub的证书给客户端;
- 客户端收到证书,校验合法性,主要包括是否在有效期内、证书的域名与请求的域名是否匹配,上一级证书是否有效(递归判断,直到判断到系统内置或浏览器配置好的根证书),如果不通过,则显示HTTPS警告信息,如果通过则继续;
- 客户端生成一个用于对称加密的随机Key,并用证书内的公钥Pub进行加密,发送给服务端;
- 服务端收到随机Key的密文,使用与公钥Pub配对的私钥Private进行解密,得到客户端真正想发送的随机Key;
- 服务端使用客户端发送过来的随机Key对要传输的HTTP数据进行对称加密,将密文返回客户端;
- 客户端使用随机Key对称解密密文,得到HTTP数据明文;
- 后续HTTPS请求使用之前交换好的随机Key进行对称加解密。
使用非对称加密是为了安全地传递客户端的随机Key
依然考虑中间人攻击的情况,非对称加密的算法都是公开的,所有人都可以自己生成一对公钥私钥。
当服务端向客户端返回公钥A1的时候,中间人将其替换成自己的公钥B1传送给浏览器。
而浏览器此时一无所知,傻乎乎地使用公钥B1加密了密钥K发送出去,又被中间人截获,中间人利用自己的私钥B2解密,得到密钥K,再使用服务端的公钥A1加密传送给服务端,完成了通信链路,而服务端和客户端毫无感知。
由CA机构的签名解决这个问题。
- CA机构拥有自己的一对公钥和私钥
- CA机构在颁发证书时对证书明文信息进行哈希
- 将哈希值用私钥进行加签,得到数字签名
客户端可以用CA机构的公钥解开签名,验证明文未被篡改。而中间人因为没有CA机构的私钥,所以篡改后无法更改签名。
注意这里有两对公钥私钥,一对是证书的,一对是CA机构的。
阻塞/非阻塞 和 同步/异步
阻塞/非阻塞:描述的是调用者调用方法后的状态,比如:线程A调用了B方法,A线程处于阻塞状态。
同步/异步:描述的方法跟调用者间通信的方式,如果不需要调用者主动等待,调用者调用后立即返回,然后方法本身通过回调,消息通知等方式通知调用者结果,就是异步的。如果调用方法后一直需要调用者一直等待方法返回结果,那么就是同步的
post 请求是两个TCP包
get 请求在发送过程中会产生一个 TCP 数据包;post 在发送过程中会产生两个 TCP 数据包。对于 get 方式的请求,浏览器会把 http header 和 data 一并发送出去,服务器响应 200(返回数据);而对于 post,浏览器先发送 header,服务器响应 100 continue,浏览器再发送 data,服务器响应 200 ok(返回数据)。
linux 查看端口命令
netstat -lntup
说明: l:listening n:num t:tcp u:udp p:process
红黑树的五个特点
- 节点只有红的和黑的
- 根节点是黑的
- 如果一个节点是红的,子节点一定是黑的(反之不一定)
- 叶子节点都是黑的,并且是null
- 从根节点到任意叶子节点,经过的黑色节点数相同
B树,B+树,B*树,LSM树(log-structured merge-tree)
B树是多路平衡二叉查找树,可在非叶子结点存放关键字。
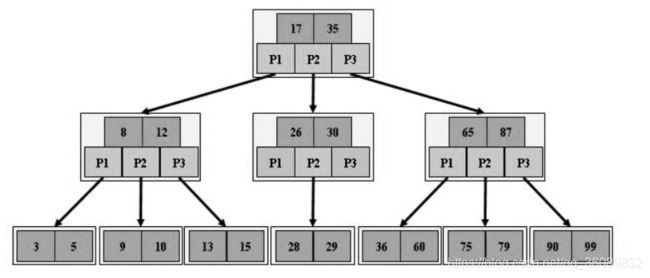
B+树在B树基础上改进,只在叶子结点存放关键字,以及指向关键字的指针。并且结点有序,叶子结点有指向兄弟结点的指针。所以能够范围查找,也适合文件系统和数据库系统

B*树在B+树基础上在非根非叶子结点之间增加链指针。
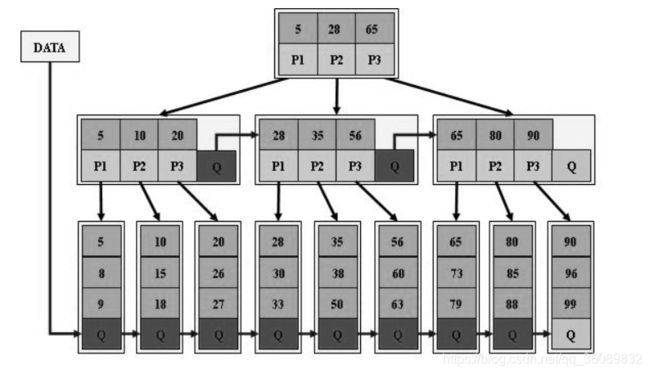
LSM树,在B+树基础上改进,B+树可能产生大量随机IO读写。而LSM树采用 WAL,在内存中暂存写数据并排序,使得子树有序,再顺序写入磁盘,读取的时候虽然不知道在哪颗子树上,需要遍历所有的子树,但是在单个子树内是有序的。牺牲部分读性能换取写入性能。
工具类应该屏蔽构造方法
虚拟内存
通过虚拟内存可以让程序拥有超过物理内存大小的内存空间。另外,虚拟内存为程序提供了一块连续的私有的内存空间,好像程序独占主存一样。由于局部性原理,可以只装入程序的一部分,其他部分暂存在虚拟存储器中,在需要时再调入内存。用时间换空间。
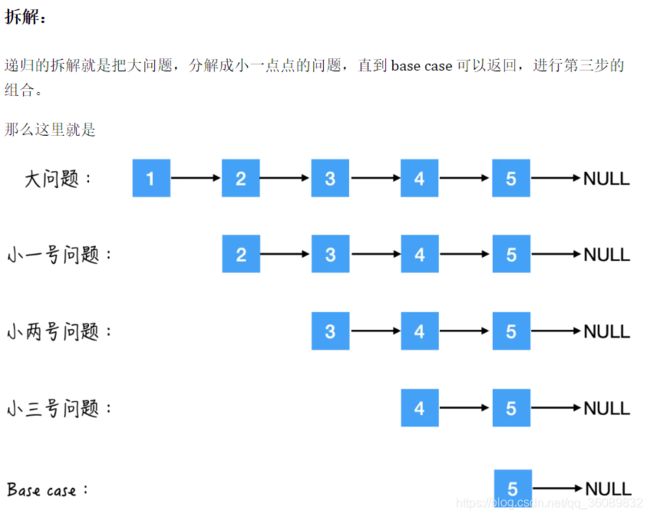
递归三个步骤
找base case 、拆解 、 组合
翻转链表:



字符从内存输出,如何显示在屏幕
System.out.print() 将内存中的字符串(char[])按utf-16解码为unicode码点,再以系统编码方式(如utf-8,将码点编码)输出字节流,控制台收到的字节流,以相同的方式(utf-8)解码为unicode码点。系统将码点以图形的形式显示
短链接的好处
- 对于有长度限制的场景节省字数
- 对应的二维码容易识别
如何设计高并发系统

1、系统拆分
将系统按业务拆分为多个子系统,用 dubbo 或者优秀的 http 封装交互。数据库也按业务垂直拆分。
2、缓存
针对读多写少的场景。可以用预热等方法提升可靠性。
3、MQ
针对业务逻辑复杂,但客户端不需要同步接收最终结果的场景。
4、分库分表
分库分表,可能到了最后数据库层面还是免不了抗高并发的要求,好吧,那么就将一个数据库拆分为多个库,多个库来扛更高的并发;然后将一个表拆分为多个表,每个表的数据量保持少一点,提高 sql 跑的性能。
读写分离
读写分离,这个就是说大部分时候数据库可能也是读多写少,没必要所有请求都集中在一个库上吧,可以搞个主从架构,主库写入,从库读取,搞一个读写分离。读流量太多的时候,还可以加更多的从库。
ElasticSearch
Elasticsearch,简称 es。es 是分布式的,可以随便扩容,分布式天然就可以支撑高并发,因为动不动就可以扩容加机器来扛更高的并发。那么一些比较简单的查询、统计类的操作,可以考虑用 es 来承载,还有一些全文搜索类的操作,也可以考虑用 es 来承载。
上面的 6 点,基本就是高并发系统肯定要干的一些事儿,大家可以仔细结合之前讲过的知识考虑一下,到时候你可以系统的把这块阐述一下,然后每个部分要注意哪些问题,之前都讲过了,你都可以阐述阐述,表明你对这块是有点积累的。
说句实话,毕竟你真正厉害的一点,不是在于弄明白一些技术,或者大概知道一个高并发系统应该长什么样?其实实际上在真正的复杂的业务系统里,做高并发要远远比上面提到的点要复杂几十倍到上百倍。你需要考虑:哪些需要分库分表,哪些不需要分库分表,单库单表跟分库分表如何 join,哪些数据要放到缓存里去,放哪些数据才可以扛住高并发的请求,你需要完成对一个复杂业务系统的分析之后,然后逐步逐步的加入高并发的系统架构的改造,这个过程是无比复杂的,一旦做过一次,并且做好了,你在这个市场上就会非常的吃香。
其实大部分公司,真正看重的,不是说你掌握高并发相关的一些基本的架构知识,架构中的一些技术,RocketMQ、Kafka、Redis、Elasticsearch,高并发这一块,你了解了,也只能是次一等的人才。对一个有几十万行代码的复杂的分布式系统,一步一步架构、设计以及实践过高并发架构的人,这个经验是难能可贵的。
缓存的本质思想是空间换时间
缓存的思想实际在操作系统或者其他地方都被大量用到。 比如 CPU Cache 缓存的是内存数据用于解决 CPU 处理速度和内存不匹配的问题,内存缓存的是硬盘数据用于解决硬盘访问速度过慢的问题。
代码校验
我们在开发程序的时候都要有一颗“不信任”的心,就是不要相信任何调用方,比如你提供了API接口出去,你有这几个参数,那我觉得作为被调用方,任何可能的参数情况都应该被考虑到,做校验,因为你不相信调用你的人,你不知道他会传什么参数给你。
举个简单的例子,你这个接口是分页查询的,但是你没对分页参数的大小做限制,调用的人万一一口气查 Integer.MAX_VALUE 一次请求就要你几秒,多几个并发你不就挂了么?
10. 个人项目包命名
- pers.个人名.项目名.模块名.…… 个人项目,指个人发起,独自完成,可分享的项目,copyright主要属于个人
- priv.个人名.项目名.模块名.…… 私有项目,指个人发起,独自完成,非公开的私人使用的项目,copyright属于个人。
11. 类命名规范
需要分布式锁的两类场景
- 性能要求:避免一个job执行多次
- 正确性要求:避免对一份数据同时修改
分布式事务的一种解决方案:事务消息+最终一致性
其他的还有 XA Transaction,一致性更强但可用性较低,实现复杂。
TCC (Try、Confirm、Cancel)补偿事务,有些场景不方便处理补偿。
数据库事务的一致性指的是:不能破坏关系数据的完整性以及业务逻辑上的一致性。
如A给B转账,不论转账的事务操作是否成功,其两者的存款总额不变(这是业务逻辑的一致性)。
数据库层面会在一个事务执行之前和之后,数据会符合你设置的约束(唯一约束,外键约束,check约束等)和触发器设置;此外,数据库的内部数据结构(如 B 树索引或双向链表)都必须是正确的。
分布式系统中,往往追求更高的可用性,不要求强一致性,BASE理论是对CAP理论的扩充,指Basically Available(基本可用)、Soft state(软状态)即允许状态有一段时间不同步、Eventually consistent(最终一致性)
RPC常见误区
RPC 和 HTTP 不是并行的概念,RPC是一种设计,通常涉及传输协议和序列化协议。HTTP是一种协议,RPC通常是基于自定义的TCP协议,但也可以使用HTTP作为传输协议。RPC 使用自定义的TCP协议最大的好处是减少无用信息的传输,而HTTP报头中大多数内容往往用不到。只要RPC客户端和服务端统一好传输协议,就可以只传输必要的数据,提高效率。用个比喻就是 HTTP协议 = 普通话,自定义TCP协议 = 方言
solr 优化入手点
1、业务代码层面优化
减少不必要的solr请求。
2、限定fl字段
只指定业务需要的字段返回。实践中从返回50个字段减少到1个字段,整体耗时减少60%。效果受硬件性能影响。
3、对facet字段使用docValues
4、对索引优化
减少不必要的copyField使用,定期对索引进行optimize。
5、小心使用模糊搜索
可以类比为sql里的like语句,对性能有一定影响。
项目中各层的日志可以分开存储,日志输出时注意排除敏感信息
构建SaaS 时的最佳实践
- 基准代码
一份基准代码,多份部署。禁止多个应用共用一份代码。 - 依赖
显式声明依赖关系,使用maven管理即可 - 配置
在环境中存储配置,代码和配置严格分离。判断一个应用是否正确地将配置排除在代码之外,一个简单的方法是看该应用的基准代码是否可以立刻开源,而不用担心会暴露任何敏感的信息。 - 后端服务
把后端服务统一看作资源,不区分本地服务和远端服务。 - 构建,发布,运行
严格分离构建和运行 - 进程
以一个或多个无状态进程运行应用,任何需要持久化的数据都要存储在 后端服务 内,比如数据库。
一些互联网系统依赖于 “粘性 session”, 这是指将用户 session 中的数据缓存至某进程的内存中,并将同一用户的后续请求路由到同一个进程。粘性 session 是 12-Factor 极力反对的。Session 中的数据应该保存在诸如 Memcached 或 Redis 这样的带有过期时间的缓存中。 - 端口绑定
通过端口绑定提供服务 - 并发
通过进程模型进行扩展,垂直扩展是有瓶颈的,通过启动多个进程来有效增加并发能力。 - 易处理
快速启动和优雅终止可最大化健壮性。就网络进程而言,优雅终止是指停止监听服务的端口,即拒绝所有新的请求,并继续执行当前已接收的请求,然后退出。此类型的进程所隐含的要求是HTTP请求大多都很短。 - 开发环境与线上环境等价
尽可能的保持开发,预发布,线上环境相同。后端服务 是保持开发与线上等价的重要部分,例如数据库,队列系统,以及缓存。
IaaS、PaaS、SaaS区分
IaaS: 基础设施即服务 (阿里云服务器)
PaaS:平台即服务 (阿里云RDS) ,Docker 就是基于PaaS产生的虚拟化容器技术
SaaS: 软件即服务 在云上直接可以访问无需本地化部署安装,类似钉钉,云上OA,教务系统(需求变化不大,具有很强的通用性)
通俗角度
如果你想搭建一个博客网站。不采用云服务,你所需要准备的大概是:买服务器,安装服务器软件,编写博客网站代码。
IaaS
如果你采用IaaS服务,那么意味着你就不用自己买服务器了,随便在哪家购买虚拟机,但是还是需要自己装服务器软件
PaaS
如果你采用PaaS的服务,那么意味着你既不需要买服务器,也不需要自己装服务器软件,只需要自己编写博客网站代码
SaaS
如果你再进一步,直接就在CSDN上写博客,那么也不需要自己编写博客网站代码了,CSDN会负责博客的升级、维护、增加服务器等,而你只需要专心写博客即可,此即为SaaS。
服务调用时的超时时间设置
需要考虑整个调用链中所有依赖服务的耗时、各个服务是否是核心服务等很多因素。可能因重复请求带来脏数据问题,因此服务端必须考虑接口的幂等性。
设置调用方的超时时间之前,先了解清楚依赖服务的TP99响应时间是多少(如果依赖服务性能波动大,也可以看TP95),调用方的超时时间可以在此基础上加50%
区分是可重试服务还是不可重试服务,如果接口没实现幂等则不允许设置重试次数。注意:读接口是天然幂等的,写接口则可以使用业务单据ID或者在调用方生成唯一ID传递给服务端,通过此ID进行防重避免引入脏数据
如果调用方是高QPS服务,则必须考虑服务方超时情况下的降级和熔断策略。(比如超过10%的请求出错,则停止重试机制直接熔断,改成调用其他服务、异步MQ机制、或者使用调用方的缓存数据)
Oauth2 流程

B是关键,即用户怎样才能给于客户端授权。有了这个授权以后,客户端就可以获取令牌,进而凭令牌获取资源。
OAuth 2.0定义了四种授权方式。
- 授权码模式(authorization code)
- 简化模式(implicit)
- 密码模式(resource owner password credentials)
- 客户端模式(client credentials)
正向代理 和 反向代理
正向代理即是客户端代理, 代理客户端, 服务端不知道实际发起请求的客户端.
反向代理即是服务端代理, 代理服务端, 客户端不知道实际提供服务的服务端

正向代理中,proxy和client同属一个LAN,对server透明;
反向代理中,proxy和server同属一个LAN,对client透明。
实际上proxy在两种代理中做的事都是代为收发请求和响应,不过从结构上来看正好左右互换了下,所以把后出现的那种代理方式叫成了反向代理
云和云原生的理解
云:将各种资源通过网络整合在一起的产物
云原生:为了让服务运行在云上的解决方案(容器化、微服务、CI/CD、DevOps)
8. maven常见scope
- compile:默认值,参与编译、测试、运行,打包时会被包括。
- test:仅参与编译、测试
- provided:和compile区别仅在于不会被打包
- runtime:仅参与运行,会被打包
10. 可以用动态规划的题目特征
- 求一个问题的最优解
- 大题目可以拆解成多个小题目,小题目也有最优解,大题目的最优解依赖于小题目的最优解
- 小题目之间互相有重叠的更小的子题目
- 可以从上到下分析问题,从下到上计算结果
11. 二进制位运算中的一个技巧
一个整数减去1,和自身做与运算,可以把自身的二进制数最右边的1变为0
网络物理层的作用
- 规范与传输媒体接口有关的的几种特性:电气特性(工作电压)、功能特性(电平的意义)、过程特性(不同事件的出现顺序)、机械特性(比如尺寸)
- 由于硬件设备和传输媒体的种类很多,通过规范可以屏蔽这些差异,使数据链路层不用关心实际的传输媒体。
数据链路层总结
- 传输单元是帧
- MTU : maximum transfer unit 帧的数据部分最大长度
- MAC地址6个字节
- 数据链路层的三个问题是:透明传输、差错检测、封装成帧
数据包传输的流程
- 传输层对应用层数据加上 源端口 和 目的端口 成为数据段
- 网络层在头部加上 源IP 和 目的IP 成为数据包
- 网络层使用 ARP 协议获取 目的IP 的MAC地址
- 查看 源IP 和 目的IP 是否是同一网段,如果是,则在ARP缓存中找有没有目的IP的MAC地址,如果找不到就在网络中发ARP广播
- 如果不是同一网段,则在ARP缓存中找有没有网关的MAC地址,找不到同样发送ARP广播
- 拿到下一跳(目的主机 或者 网关)的MAC地址后,数据链路层在头部加上 源MAC 和 下一跳MAC 成为数据帧,然后发送出去(如果两者通过交换机连接,则多一步交换机查找自己的MAC表来转发)
- 如果下一跳是路由器,有两种可能,一种是主机在同一网段,通过路由器连接,此时路由器功能和交换机相同。通过查MAC表转发。通常情况是可以查到的,如果查不到,此时不会发广播(每个端口都转发)。因为路由器不知道此时自身是作为交换机还是路由器,即不知道目的MAC是本网段还是外网段的,会提取目的IP确认网段,因为是同一网段,所以直接交付,确认转发端口发送出去。
- 如果两个主机不在同一网段,这时查MAC表也查不到。提出 目的IP 会发现不是同一网段,然后在路由表中查找 转发端口 和 下一跳IP,查不到就走默认路由。然后去MAC表查找 下一跳IP 的MAC地址,查不到就发ARP广播。 拿到下一跳MAC地址后,再加上数据帧头部,源MAC是转发端口的MAC,目的MAC是下一跳的MAC地址,再通转发端口发出。

所以路由器是包含交换机的功能的,并且首先进行交换机做的工作(但不会进行广播)
网络层总结
- ARP: IP ——> MAC
- ICMP: Intenet Control Message Protocol,网际控制报文协议
- ICMP协议的功能主要有:
- 确认IP包是否成功到达目标地址,ping命令
- 通知在发送过程中IP包被丢弃的原因,比如目标不可达,则当前节点向发送方发一个ICMP报文
- CIDR:Classless Inter-Domain Routing,使用网络前缀替代网络号和子网号,格式为 “/”+网络号位数
传输层总结
- UDP的主要特点是①无连接②尽最大努力交付③面向报文④无拥塞控制⑤支持一对一,一对多,多对一和多对多的交互通信⑥首部开销小(只有四个字段:源端口,目的端口,长度和检验和)
- TCP的主要特点是①面向连接②每一条TCP连接只能是一对一的③提供可靠交付④提供全双工通信⑤面向字节流
- TCP报文头部固定有20字节,后面有可选的4n字节。
- 源端口和目的端口,各占2个字节,分别写入源端口和目的端口;
- 序号,占4个字节,TCP连接中传送的字节流中的每个字节都按顺序编号。例如,一段报文的序号字段值是 301 ,而携带的数据共有100字段,显然下一个报文段(如果还有的话)的数据序号应该从401开始;
- 确认号,占4个字节,是期望收到对方下一个报文的第一个数据字节的序号。例如,B收到了A发送过来的报文,其序列号字段是501,而数据长度是200字节,这表明B正确的收到了A发送的到序号700为止的数据。因此,B期望收到A的下一个数据序号是701,于是B在发送给A的确认报文段中把确认号置为701;
- 数据偏移,占4位,它指出TCP报文的数据距离TCP报文段的起始处有多远;
- 保留,占6位,保留今后使用,但目前应都位0;
- 紧急URG,当URG=1,表明紧急指针字段有效。告诉系统此报文段中有紧急数据;
- 确认ACK,仅当ACK=1时,确认号字段才有效。TCP规定,在连接建立后所有报文的传输都必须把ACK置1;
- 推送PSH,当两个应用进程进行交互式通信时,有时在一端的应用进程希望在键入一个命令后立即就能收到对方的响应,这时候就将PSH=1;
- 复位RST,当RST=1,表明TCP连接中出现严重差错,必须释放连接,然后再重新建立连接;
- 同步SYN,在连接建立时用来同步序号。当SYN=1,ACK=0,表明是连接请求报文,若同意连接,则响应报文中应该使SYN=1,ACK=1;
- 终止FIN,用来释放连接。当FIN=1,表明此报文的发送方的数据已经发送完毕,并且要求释放;
- 窗口,占2字节,指的是通知接收方,发送本报文你需要有多大的空间来接受;
- 检验和,占2字节,校验首部和数据这两部分;
- 紧急指针,占2字节,指出本报文段中的紧急数据的字节数;
- 选项,长度可变,定义一些其他的可选的参数。
应用层总结
- 传输单元为 数据
- DNS: 域名——> IP
三次握手
过程:
- 客户端发送 SYN=1,seq=x 的报文,然后进入 syn-sent 状态
- 服务端接收到报文后,返回 SYN=1,ACK=1,ack=x+1,seq=y 的报文(虽然客户端的同步请求不带数据,但是规定要消耗一个序号,所以 ack=x+1),然后进入 syn-received 状态
- 客户端收到确认后,要再给服务器确认,发送 ACK=1,ack=y+1,seq=x+1 的报文(服务端同样要消耗一个序号),然后进入 established 状态
- 服务端收到确认后,也进入 established 状态,之后就可以正常通信了

为什么需要三次握手:如果是两次握手,客户端收到确认后只能确保自己收发正常,而服务器只能保证接收正常,不知道发送是否正常。另外,如果第一次握手的报文延迟了,客户端发起重试,然后两个报文最终都到达了服务端,服务端确认后就会产生两个连接。如果使用三次握手,即使客户端收到了第二个确认报文,也不会再给服务端确认,这样就只产生一个连接。
如果第三个报文丢失了怎么办:服务端等待超时后会重传默认5次,如果还没有回应,会主动关闭连接,如果之后再收到客户端的报文,会发送 RST 报文。
四次挥手
过程:
- 客户端没有数据要发送后,发送一个 FIN=1,seq=x 的报文,进入 FIN-WAIT-1 状态 (通常来说这个报文不会携带数据,但也要消耗一个序号)
- 服务端接收到后,返回一个 ACK=1,seq=y,ack=x+1 的报文,进入 CLOSE-WAIT 状态。TCP服务器通知高层的应用进程,客户端向服务器的方向就释放了,这时候处于半关闭状态,即客户端已经没有数据要发送了,但是服务器若发送数据,客户端依然要接受。
- 客户端收到确认后,就进入 FIN-WAIT-2 状态,等待服务端发送释放连接请求,在此之前还要接收服务端的数据
- 服务端发送完数据后,发送一个 FIN=1,ACK=1,seq=z,ack=x+1 的报文,进入 LAST-ACK 状态
- 客户端收到报文后,返回一个 ACK=1,seq=x+1,ack=z+1 的报文,进入 TIME-WAIT 状态,注意此时TCP连接还没有释放,必须经过2∗MSL(最长报文段寿命)的时间后,当客户端撤销相应的TCB后,才进入CLOSED状态。
- 服务端收到确认后,进入 CLOSED 状态

为什么客户端要等待 2*MSL(Maximum Segment Lifetime) 时间:
- 保证客户端发送的最后一个ACK报文能够到达服务器,因为这个ACK报文可能丢失,服务器等待超时后会重新发送一次,而客户端就能在这个2MSL时间段内收到这个重传的报文,接着给出回应报文,并且会重启2MSL计时器。
- 防止类似与“三次握手”中提到了的“已经失效的连接请求报文段”出现在本连接中。客户端发送完最后一个确认报文后,在这个2MSL时间中,就可以使本连接持续的时间内所产生的所有报文段都从网络中消失。这样新的连接中不会出现旧连接的请求报文。
TCP的可靠传输
- 使用校验和,如果有差错,直接丢弃,不确认
- 丢弃重复数据
- 对报文编号,接收方对数据包排序,把有序数据传递给应用层
- ARQ协议(Automatic Repeat Request),使用确认和重传机制,如果长时间收不到确认,就会重传。包括停止-等待ARQ 和 连续ARQ
- 停止-等待ARQ 每发送一个分组就会停下,等待确认,若收到重复分组,则直接丢弃,但还是要发送确认。优点:简单。缺点:信道利用率低。
- 连续ARQ协议 维持一个发送窗口,窗口内的分组可以连续发送,无需等待确认,接收方采用累积确认,对按序到达的最后一个分组确认。优点:信道利用率高。缺点:若中间分组异常,则之后的分组都不能确认,需要重传,在网络环境差的情况下效率未必高于停止-等待协议。
- 使用滑动窗口实现流量控制,窗口大小可变,当接收方来不及接收数据时,可以用确认报文中的窗口字段控制发送方窗口大小。
- 拥塞控制。这是一个全局性的过程,涉及所有的主机和路由器。而流量控制是端到端的问题。发送方维持一个拥塞窗口变量cwnd。拥塞控制窗口的大小取决于网络的拥塞程度,并且动态变化。发送方让自己的发送窗口取为拥塞窗口和接收方的接受窗口中较小的一个。拥塞控制采用四种算法:
- 慢开始:cwnd初始值为1,每次增长一倍,为了防止增长过快造成拥塞,还维持另一个变量:慢开始门限ssthresh,一旦cwnd超过ssthresh,就采用拥塞避免算法。
- 拥塞避免:每次cwnd增长1。当判断网络出现拥塞,cwnd重新置为1,ssthresh设置为原来的一半。
- 快重传:接收方成功的接受了发送方发来的M1,M2并且分别发送了ACK,现在接收方没有收到M3,而收到了M4,显然接收方不能确认M4,因为M4是失序的报文段。在收到M4,M5等报文段的时候,不断重复的向发送方发送M2的ACK,如果接收方一连收到三个重复的ACK,那么发送方不必等待重传计时器到期,尽早重传未被确认的报文段

- 快恢复:当发送方连续收到三个重复确认时,执行“乘法减小”算法,慢启动门限减半。把cwnd值设置为慢启动门限减半后的值,然后开始执行拥塞避免算法,拥塞窗口cwnd值线性增大。

DNS解析
首先在本地域名服务器上找,然后去根域名服务器,再去顶级域名服务器,最后去权限域名服务器。

“.”对应的就是根域名服务器,默认情况下所有的网址的最后一位都是“.”,为了方便用户,通常都会省略,浏览器在请求DNS的时候会自动加上,所有网址真正的解析过程为: . -> .com. -> google.com. -> www.google.com.。
对于debug日志,必须判断是否为debug级别后,才进行使用
if (logger.isDebugEnabled()) {
logger.debug("Processing trade with id: " +id + " symbol: " + symbol);
}