聊一聊进程、线程和协程以及线程的那些“锁“事
进程 线程 协程
进程 线程 协程
进程 Process
进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位
通俗的讲:进程可以理解为我们在电脑上正在运行的一个个应用,例如:QQ,微信,LOL

打开一个浏览器急速一个进程,打开两个浏览器就是两个进程,进程和进程之间具有独立性,它们具有各自的虚拟地址空间和文件描述符
线程 thread
线程(英语:thread)是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。同一个进程的多个线程之间是共享同一份虚拟空间地址和文件描述符的。在一个进程中的多线程,可以并发的执行(后面有并发的介绍)。
就拿百度网盘来说,如果有下载任何和上传任务的话,那么百度网盘这个进程里面至少有两个线程来完成工作,一个是上传 一个是下载
-
我们使用htop来看一下,百度网盘开了几个线程

-
进程和线程我们都讲过了,那么现在来问一个问题,如何实现多任务?
其实如果你看完了进程和线程应该也能明白,多任务嘛,可以 多进程 也可以多线程,还可以采用多进程+多线程的方式
协程coroutine
在详细讲解协程之前,我们先看一下这个场景,比如一个饭店有两个厨师,一个小工,小工负责摘菜 洗菜 啥的,那么饭店运转的时候,其实就有三个线程,这没有问题,但是忽然有一天小工请假了,就剩下两个厨师了?怎么办?老板这时候说,你看你俩也不是很忙,有人点菜的时候就炒菜,没人点菜的时候就洗洗菜啥的,别闲着(周扒皮已上线),明白了吧,就是为了更高效率的利用线程,而不是频繁的创建线程 销毁线程 以及CPU频繁的切换上下文,不能让线程闲着
- 协程,英文Coroutines,是一种基于线程之上,但又比线程更加轻量级的存在,因为是自主开辟的异步任务,所以很多人也更喜欢叫它们纤程(Fiber),或者绿色线程(GreenThread)。正如一个进程可以拥有多个线程一样,一个线程也可以拥有多个协程。具有对内核来说不可见的特性。(其实这里有一个问题,就是协程是无序的,那么我们怎么保证数据的事务性呢?有好的想法可以和我交流哦)
进程的状态
三种基本状态
三种基本状态:就绪态、执行态、阻塞态。
这三种基本状态每个OS 中都会有的,因些称为基本态,下而是给出三种基本状态的定义:
-
就绪(Ready)状态
通过Ready 我们可以看到,处于此状态的进程已经处于准备好要运行了。
此时进程已经分配好除CPU 外的所有必要资源,只需要获得CPU,便可立即执行。
处于就绪态的进程都是在就绪队列中,等待着调度程序的调度(分配CPU)。 -
执行(Running)状态
处于此状态的进程是已经获得CPU 且正在执行中。
对于这一状态,在单CPU OS 中,同一时刻只能有一个进程处于此状态,而在多CPU OS,则可以有多个(不超过CPU 的数量)进程同时处于执行状态。 -
阻塞(Block)状态
处于此状态的进程是因为在执行的过程中由于发生某种需要等待的事件(I/O 请求,申请缓存失败,等待接收数据等),而暂时无法继续运行。
在多道批处理系统中,此时需要进程把处理机释放,并选取新的就绪进程执行。
与就绪队列相对应的,处于阻塞状态的进程都在阻塞队列中,某些OS 中,出于提高效率的目的,根据阻塞的原因,会有多个阻塞队列。
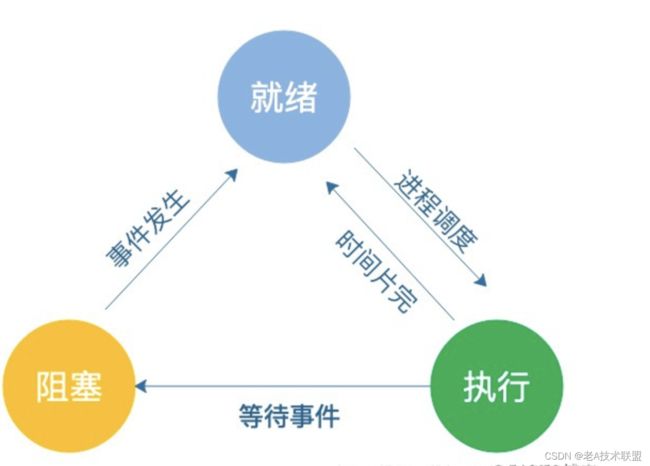
上图是进程的三种基本状态的转换图,进程在运行的过程中会经常的发生状态的转换。
从图中我们可以看到,就绪态和执行态是可以相互转换的,但是执行态到阻塞态是单向的,这是因为就算阻塞的进程“通畅” 了,因为处理机已经分配给别的进程了,因此进程的状态只能切换到就绪态,并且也是单项的,因为等待的事件也只可以在执行中才能发生。
创建状态和终止状态
我们知道,进程创建时,需要对其分配除CPU处的所有的必要资源,
但是,如果此时OS 因为资源不足无法给进程分配资源,那么进程应该处于什么状态呢?
为了满足上述问题,满足进程状态的完整性以及增强管理的灵活性,
通常会在OS中为进程新增两种常见的状态:创建状态和终止状态。
下面给出两种状态的定义:
创建状态
进程创建的过程中,所需的资源尚不能得到满足,此时创建工作尚未完成,进程无法被调度执度,进程此时就处于创建状态。
终止状态
进程正常运行结束或都出现导致进程终止的错误,或是被 os 所终结,或是被父过程终结,则进入终止状态。
进入终止状太的进程将不能再执行,但是OS 依然保持一个记录,其中保存着状态码和计时器统计数据,等待别的进程收集,一旦资源被收集完成,OS 会立即删除该进程。

认识并发和并行
- 如果我们第一次理解并发,很容易理解错误,认为并发 就是同时发生的意思,而慢慢的,你会了解到并行,那么我们就先看看并发和并行。
- 并发
并发是指一个cpu交替执行多个任务,而不是同时执行,只不过因为CPU执行的速度过快,而会使得人们感到是在“同时”执行,执行的先后取决于各个程序对于时间片资源的争夺。通俗点理解,并发就像一个厨师架了两口锅,一个炒西红柿鸡蛋,一个炒尖椒肉丝,猛一想,好像是一个厨师同时在炒两个菜,但其实,同一个时刻,厨师只能颠一个勺,颠完西红柿鸡蛋颠尖椒肉丝。来回切换。这里面的厨师 就是CPU 。西红柿鸡蛋和尖椒肉丝就是要处理的线程。 - 并行:多个CPU同时执行多个任务,就好像有两个程序,这两个程序是真的在两个不同的CPU内同时被执行。我想起来小时候家里养的一头母猪,可以同时奶12个猪仔(一般母猪有6对乳头,即12个乳头,养殖必备知识点,记一下),对应起来,这头母猪其实就是一个12核的计算机,同时奶12个猪仔这件事情,就是并行(尴尬的笑)
什么是锁
锁是计算机对资源进行并发访问控制的一种机制,多线程情况下来实现对临界资源的同步互斥访问。
为什么需要锁
- 我们先来演示一段代码,这段代码中,我开启了1000个协程,每次都对c+1操作,那么一般来讲,我们最后得到的结构是1000
package main
import (
"fmt"
"time"
)
func main() {
c:=0
for i:=0;i<1000;i++{
go func(){
c=c+1
fmt.Printf("i am %d ,and the res is %d the i addr is %v the c addr is %v \n",i,c,&i,&c)
}()
}
time.Sleep(time.Second)
fmt.Println(c)
}
-
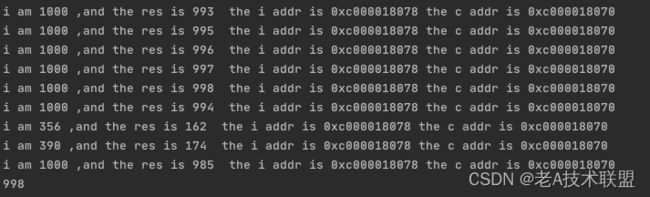
但是我们实际运行后发现并不是1000,而是每次都发生变化
-
我们考虑是不是因为这1000个协程执行的顺序并不是一致的,换句话说,一个协程拿到的c的值是1000,一个协程拿到的c的值是966,但是第一个协程反而先执行,第二个协程后执行,就导致c的值被覆盖


-
通过上面的运行结果我们发现两个问题,
第一 协程执行是无序的
第二 c的最终结果并不是1000 而且每次都会发生变化
第三 明明只有最后一次循环i的值是1000,但是打印出来,有很多协程里面的i都是1000?
其实后面打印的信息已经给了我们回复,不管是i 还是c 在整个程序运行中,这1000个协程用的是同一个变量地址,所以 最后一次循环的时候,i的值被修改为1000,其实其他未执行完毕的协程里面 i和c的值都发生了变化,也就是说,这一份资源,有多个协程去使用和修改。就像我们上学的时候,数学老师正在黑板上写微积分,还没写完,忽然英语老师开始在黑板上写主谓宾,主谓宾还没写完,美术老师上来画了个哆啦A梦,导致这块黑板不停的被写,而下面学生一群懵逼,哈哈,而在这个场景里面,这个黑板就是变量对应的内存地址,一个个的老师对应的就是每一个协程 -
我们可以通过-race 来查看锁竞争的情况
zhangguofu@zhangguofudeMacBook-Pro testp $ go run -race /Users/zhangguofu/website/testp/main.go
997
Found 3 data race(s)
exit status 66
zhangguofu@zhangguofudeMacBook-Pro testp $ go run -race /Users/zhangguofu/website/testp/main.go
998
Found 3 data race(s)
exit status 66
- 那么怎么避免这种情况呢?那就是给资源上锁,必须等第一个老师说下课了,第二个老师才能上来,那么在Go中对于并发程序进行公共资源的访问的限制,就是这种锁机制,称为互斥锁(sync.mutex)
- 我们对上面的代码进行优化
package main
import (
"fmt"
"sync"
"time"
)
var mutex sync.Mutex
func main() {
c:=0
for i:=0;i<1000;i++{
go func(){
mutex.Lock()//我声明 我要上课了,这个黑板我独占
c=c+1
fmt.Printf("i am %d ,and the res is %d the i addr is %v the c addr is %v \n",i,c,&i,&c)
mutex.Unlock() //我声明,我下课了,我不用黑板了
}()
}
time.Sleep(time.Second)
fmt.Println(c)
}
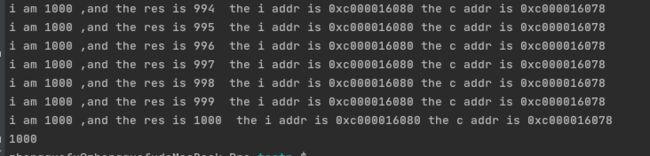
- 我们执行代码,发现 c的最后结果是1000了,而且c的值确实是+1递增的,但是i还是存在资源竞争,为什么?因为i 并没有上锁啊
- 我们继续对上面的代码优化,其实就是把 i 传到协程里面(其实就是传参,说明以下,在go中,对变量的一切操作都是值操作,指针也是值,而不存在引用传递)
package main
import (
"fmt"
"sync"
"time"
)
var mutex sync.Mutex
func main() {
c:=0
for i:=0;i<1000;i++{
go func(i int){
mutex.Lock()//我声明 我要上课了,这个黑板我独占
c=c+1
fmt.Printf("i am %d ,and the res is %d the i addr is %v the c addr is %v \n",i,c,&i,&c)
mutex.Unlock() //我声明,我下课了,我不用黑板了
}(i)
}
time.Sleep(time.Second)
fmt.Println(c)
}
- 我们再次执行代码,发现结果返回正常

- 上面演示了锁的必要性,我们下面来具体聊一聊锁
锁的类型
操作系统层面
所有的高级语言锁的实现都是依赖操作系统底层锁的实现,操作系统层面上锁的实现机制有自旋锁(spinlock)和mutex
自旋锁
当一个线程尝试去获取某一把锁的时候,如果这个锁此时已经被别人获取(占用),那么此线程就无法获取到这把锁,该线程将会等待,间隔一段时间后会再次尝试获取。这种采用循环加锁 -> 等待的机制被称为自旋锁(spinlock)。这种方式线程一直处于运行状态而非阻塞状态,如果持有锁的线程能在短时间内释放锁资源,那么那些等待竞争锁的线程就不需要做内核态和用户态之间的切换进入阻塞状态,它们只需要等一等(自旋),等到持有锁的线程释放锁之后即可获取,这样就避免了用户进程和内核切换的消耗。
因为自旋锁避免了操作系统进程调度和线程切换,所以自旋锁通常适用在时间比较短的情况下。由于这个原因,操作系统的内核经常使用自旋锁。但是,如果长时间上锁的话,自旋锁会非常耗费性能,它阻止了其他线程的运行和调度。线程持有锁的时间越长,则持有该锁的线程将被 OS(Operating System) 调度程序中断的风险越大。如果发生中断情况,那么其他线程将保持旋转状态(反复尝试获取锁),而持有该锁的线程并不打算释放锁,这样导致的是结果是无限期推迟,直到持有锁的线程可以完成并释放它为止。
解决上面这种情况一个很好的方式是给自旋锁设定一个自旋时间,等时间一到立即释放自旋锁。自旋锁的目的是占着CPU资源不进行释放,等到获取锁立即进行处理。但是如何去选择自旋时间呢?如果自旋执行时间太长,会有大量的线程处于自旋状态占用 CPU 资源,进而会影响整体系统的性能。因此自旋的周期选的额外重要!
- 从上面我们看出,如果说资源的竞争不激烈,或者说持有锁的线程时间很短(至少不会比CPU上下文切换的时间长),那么自旋锁还是很有优势的,避免了CPU频繁的上下文切换,但是如果竞争激烈,锁的占有时间长,就不适合自旋锁了,因为自旋锁始终是占用CPU的。就像我们考试的时候一样,如果卷子简单,我们就不会跳着题做,从1到6道题一下子就做完了,但是有时候卷子很难,那么我们就要把难题先挂起来,等会做的题做完了再回头解决这些难题,比如先做2 4 6 ,再回头来看 1 3 5 ,难易程度 可以理解为对CPU的使用时长,CPU 就是我们的脑子啦!
互斥锁(英語:Mutual exclusion,缩写Mutex)
用于多线程编程中,防止两条线程同时对同一公共资源(也可以说是临界资源,就是能够被多个线程共享的数据)进行读写的机制。具有排他性和唯一性,该目的通过将代码切片成一个一个的临界区域(就是对公共资源操作的那一段代码)达成。临界区域指的是一块对公共资源进行存取的代码,并非一种机制或是算法。一个程序、进程、线程可以拥有多个临界区域,但是并不一定会应用互斥锁。比如我们刚开始演示的一段golang的代码,使用的就是互斥锁。
mutex的本质是一种变量。假设mutex为1时表示锁是空闲的,此时某个进程如果调用lock函数就可以获得所资源;当mutex为0时表示锁被其他进程占用,如果此时有进程调用lock来获得锁时会被挂起等待。
- 我们可以看一下golang里面的Mutex的实现方式,注释里面说Mutex是一种互斥锁,零值是未锁定的状态,互斥锁不能被拷贝使用
// A Mutex is a mutual exclusion lock.
// The zero value for a Mutex is an unlocked mutex.
//
// A Mutex must not be copied after first use.
type Mutex struct {
state int32
sema uint32
}
sync.Mutex 由两个字段 state 和 sema 组成。其中 state 表示当前互斥锁的状态,而 sema 是用于控制锁状态的信号量。我们在代码中演示一下
package main
import (
"fmt"
"sync"
"time"
)
var mutex sync.Mutex
func main() {
c:=0
for i:=0;i<1;i++{
go func(i int){
fmt.Printf("%+v \n",mutex)
mutex.Lock()//我声明 我要上课了,这个黑板我独占
fmt.Printf("%+v \n",mutex)
c=c+1
mutex.Unlock() //我声明,我下课了,我不用黑板了
fmt.Printf("%+v \n",mutex)
}(i)
}
time.Sleep(time.Second)
fmt.Println(c)
}
- 打印结果
{state:0 sema:0}
{state:1 sema:0}
{state:0 sema:0}
锁状态
死锁
死锁是指两个或两个以上的进程(或线程)在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。
最直观的理解就是,线程A需要线程B的资源,线程B需要线程A的资源,比如两个小情侣,吵架了,还都要求对方先道歉,那么这个时候如果没有外力干预,两个人就永远处于等待状态(线程不会说,算了,这个资源我不要了^_^)
死锁发生的条件
- 互斥条件
线程对资源的访问是排他性的,如果一个线程对占用了某资源,那么其他线程必须处于等待状态,直到该资源被释放。就像一群人吃饭,一个人一个碗。 - 请求和保持条件
其实条件1并不能满足死锁的条件,如果所有线程都自给自足,就不会发生资源竞争,发生资源竞争的另一个条件就是,线程吃着自己碗里的,还要占别人碗里的,线程 T1 至少已经保持了一个资源 R1 占用,但又提出使用另一个资源 R2 请求,而此时,资源 R2 被其他线程 T2 占用,于是该线程 T1 也必须等待,但又对自己保持的资源 R1 不释放。 - 不剥夺条件
条件1和2就可以满足死锁的条件吗?并不是,如果你吃着自己碗里的,还想要占别人碗里的,关键是不能抢别人碗里的,线程对未使用的资源占有自主权,在未使用前,谁也不能抢这个资源 ,只能在使用完以后由自己释放。 - 环路等待条件
俗话说的好,一个巴掌拍不响。 在死锁发生时,必然存在一个“进程 - 资源环形链”,即:{p0,p1,p2,…pn},进程 p0(或线程)等待 p1 占用的资源,p1 等待 p2 占用的资源,pn 等待 p0 占用的资源。如果张三想抢李四的饭碗,李四用完给他了,这就没死锁了,必须得是,张三想抢李四的饭碗,李四想抢赵六的饭碗,赵六想抢张三的饭碗,诶,三个人成一个死循环了,都在等下一位的饭碗。
解决死锁的方法
- 如果并发查询多个表,约定访问顺序;张三不是想要李四的碗吗?没关系,让张三先吃,李四等张三吃完再吃,赵六等李四吃完再吃,张三李四吃完了,赵六想用哪个碗就用哪个碗
- 在同一个事务中,尽可能做到一次锁定获取所需要的资源;张三吃饭需要几个碗,再在吃饭的时候就一次申请完毕,比如张三说,我需要张三和李四两个碗,能申请到就吃饭,申请不到就等着。
- 对于容易产生死锁的业务场景,尝试升级锁颗粒度,使用表级锁;这个就牛逼了,我也不管你用几个碗了,我餐厅同一个时间就允许一个人吃饭!就是豪横,其他的人在外面等着,一个吃完一个进去,这多tm反人类啊,一刀切的政策往往不可取
- 采用分布式事务锁或者使用乐观锁。分布式事务锁我们后面详细讲,简单说一下乐观锁,就是张三去吃饭了,张三认为李四不会用碗,但是张三盛饭的时候发现李四的碗不在了,或者李四吃完饭没刷碗,张三很生气,说算了,我不吃了。
活锁
活锁和死锁产生的条件一样,只是表现不同。死锁下线程进入等待状态,而活锁下线程仍然处于运行状态尝试获取锁。活锁下线程仍然消耗CPU,这样看来,活锁和死锁的区别也有点类似spinlock和mutex。
锁策略
- 锁的存在是为了保护临界资源,操作系统层面提供spinlock(自旋锁)和mutex(互斥锁)两种方式,需要考虑的是怎样实现以保证锁的高效。而应用层考虑的是如何更高效的使用他们, 使用什么样的策略去保护不同的临界资源。
独占锁
也被称为写锁,排它锁等。被独占锁保护的资源,同一时刻只能有一个线程可以进行读写操作。
共享锁
共享锁(shared lock),有时候也被称为读锁。被共享锁保护的资源,当有线程写时仍然可以被别的线程读取,读线程数并不限定为1。但是同一时刻只能有一个线程写入。
- 两者的区别就是 别人能不能看你表演,能看你表演,你是写,别人是读,这是共享锁,如果别人不能看你表演,只能你自己写,那你就是写锁。
可重入锁
可重入锁可以并且只能被已经持有锁的线程加锁多次,一个线程内有多个地方形成对该锁的嵌套获取时可以防止死锁发生。实现上可重入锁会记录自己被lock的次数,只有unlock的次数和lock次数相等时才完成对锁的释放。
- 就是有一个线程使用到该资源,就对该资源封印一次,一个线程释放该资源,就解封一次,没有任何封印的时候,才算是完成了对该资源的释放
饥饿锁
饥饿:是指如果线程T1占用了资源R,线程T2又请求封锁R,于是T2等待。T3也请求资源R,当T1释放了R上的封锁后,系统首先批准了T3的请求,T2仍然等待。然后T4又请求封锁R,当T3释放了R上的封锁之后,系统又批准了T4的请求…,T2可能永远等待。解决这种方式,我们可以使用队列来实现公平锁,让每一个线程都有机会得到执行
数据库系统
数据库系统中的锁用于事务控制,保证数据库的ACID特性,有乐观锁, 悲观锁和两段锁等。
-
乐观锁
乐观锁 是并发访问控制的一种模式,实际上并没有对任何资源加锁。乐观锁假定事务大部分情况下不会出现冲突,运行时不对资源加锁,而在commit时检测是否有冲突,发现有冲突时执行rollback并重启事务。资源竞争不激烈时采用乐观锁可以消除等待锁释放、加锁的开销,实现高吞吐量。资源竞争激列的情况下频繁的rollback和事务重启,效率会很差。 乐观锁通常采用给资源增加版本号的方式来实现。需要注意的是冲突检查和commit/rollback两个操作需要保证原子性,避免产生TOCTTOU问题,mysql上可以使用一个带条件的update语句实现比较和更新操作的原子性。 -
悲观锁
悲观锁假定冲突一定会发生,写操作直接对资源加独占锁,其他事务的写操作必须等待。读操作时,其他事务不能修改资源但是可读。悲观锁能有效的避免事务冲突,但是不会产生冲突的事务操作也需要加锁进行导致性能会比较差。 -
两段锁
数据库事务操作遵循两段锁协议来保证事务操作的串行化。两段锁协议分为两个阶段: a. 加锁阶段(Expanding phase), 只能获取锁,不能释放锁 b. 解锁阶段(Shrinking phase),修改数据然后释放锁,不能获取锁
分布式系统
分布式锁不是进程内的锁,而是分布式系统中各个服务访问临界资源前需要获取的锁。大部分基于共享存储,利用外部数据系统提供的原子操作来实现,如基于Redis的SetNx操作实现, Mysql的条件更新操作, Zookeeper的原生操作支持等。利用分布式一致性协议,如Paxos, Raft等也可以实现分布式锁。