【牛客网SQL进阶挑战系列】刷题记录:易忘知识点
目录
【SQL2】知识点:多条、整个表数据插入
插入记录的方式汇总:
1.普通插入(所有字段)
2.普通插入(指定字段)
3.多条插入
4.导入另一个表的数据
【SQL3】知识点:REPLACE INTO
解法一:用REPLACE INTO
解法二:先删除已存在的数据
【SQL4】知识点:更新数据
第一种方式:设置为新值
第二种方式:根据已有值替换
【SQL6】知识点:DELETE FROM
删除记录的方式汇总:
1.根据条件删除
2.全部删除(表清空,包含自增计数器重置):
【SQL7】知识点:不同删除的比较
1.DROP TABLE
2.TRUNCATE TABLE
3.DELETE TABLE
【SQL9】知识点:表的创建与修改
1.创建表
2.修改表
【SQL12】知识点:索引创建、删除与使用
1.创建索引
2.删除索引
3.使用索引
【SQL17】知识点:date_format、count(字段1,字段2)、round()
1.date_format() 通过这个函数匹配'%Y%m'年份和月份;
2.count(字段1,字段2)形式的含义
3.round(字段名,k)保留k个小数
【SQL错题1】知识点:union、any_value、last_day
1.union 与 union all
2.last_day()
3.any_value()
【SQL错题2】知识点:条件函数IF(X,A,B)如果符合X条件,返回A,否则B
【SQL错题3】知识点:容易忽略的逻辑问题(重要)
【SQL错题4】知识点:计算留存率(应用题,重要)
知识点:1.date_add()
【SQL错题5】得分不小于平均分的最低分
【SQL错题6】 知识点:多张表的连接,简单但是考验你的逻辑(适合初学者)
【SQL2】知识点:多条、整个表数据插入

我们已经创建了一张新表exam_record_before_2021用来备份2021年之前的试题作答记录,结构和exam_record表一致,请将2021年之前的已完成了的试题作答纪录导入到该表。
后台会通过执行"SELECT * FROM exam_record_before_2021;"语句来对比结果
答案:
INSERT INTO
exam_record_before_2021(uid, exam_id, start_time, submit_time, score)
SELECT
uid,
exam_id,
start_time,
submit_time,
score
FROM
exam_record
WHERE
YEAR(submit_time) < '2021';知识点:
插入记录的方式汇总:
-
1.普通插入(所有字段)
- INSERT INTO table_name VALUES (value1, value2, ...)
-
2.普通插入(指定字段)
- INSERT INTO table_name (column1, column2, ...) VALUES (value1, value2, ...)
-
3.多条插入
- INSERT INTO table_name (column1, column2, ...) VALUES (value1_1, value1_2, ...), (value2_1, value2_2, ...), ...
-
4.导入另一个表的数据
- INSERT INTO table_name SELECT * FROM table_name2 [WHERE key=value]
【SQL3】知识点:REPLACE INTO

答案:
解法一:用REPLACE INTO
REPLACE INTO examination_info
VALUES(NULL,9003,'SQL','hard',90,'2021-01-01 00:00:00');
知识点:
- 关键字NULL可以用DEFAULT替代。
- 掌握replace into···values的用法
replace into 跟 insert into功能类似,不同点在于:replace into 首先尝试插入数据到表中,
- 如果发现表中已经有此行数据(根据主键或者唯一索引判断)则先删除此行数据,然后插入新的数据;
- 否则,直接插入新数据。
【注意】插入数据的表必须有主键或者是唯一索引!否则的话,replace into 会直接插入数据,这将导致表中出现重复的数据。
解法二:先删除已存在的数据
先删除数据库中我们要加入的试卷ID所在行的数据,然后就能成功添加
DELETE FROM examination_info
WHERE exam_id=9003;
INSERT INTO examination_info
VALUES(NULL,9003, 'SQL','hard', 90, '2021-01-01 00:00:00')
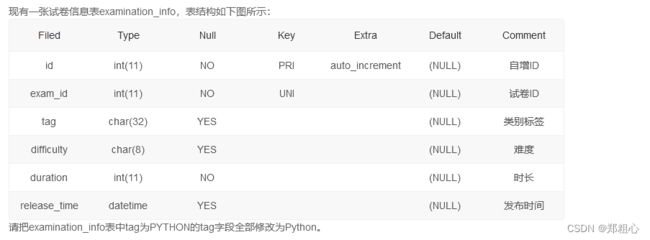
【SQL4】知识点:更新数据
答案:
第一种
UPDATE examination_info
SET tag = "Python"
WHERE tag = "PYTHON";
第二种
UPDATE examination_info
SET tag = REPLACE(tag, "PYTHON", "Python")
WHERE tag = "PYTHON";
知识点:
修改记录的方式汇总:
-
第一种方式:设置为新值
-
UPDATE table_name SET column_name=new_value [, column_name2=new_value2] [WHERE column_name3=value3] -
第二种方式:根据已有值替换
-
UPDATE table_name SET key1=replace(key1, '查找内容', '替换成内容') [WHERE column_name3=value3] - 第二种方式不仅可用于整体替换,还能做子串替换,例如要实现将tag中所有的PYTHON替换为Python(如CPYTHON=>CPython),可写作:
-
UPDATE examination_info SET tag = REPLACE(tag, "PYTHON", "Python") WHERE tag LIKE "%PYTHON%";
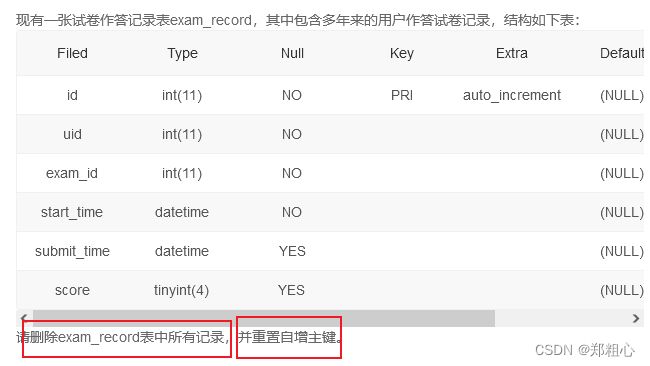
【SQL6】知识点:DELETE FROM

答案:
DELETE FROM exam_record
WHERE TIMESTAMPDIFF(MINUTE, start_time, submit_time) < 5
AND score < 60;
知识点:
删除记录的方式汇总:
-
1.根据条件删除
-
DELETE FROM table [WHERE options] [ [ ORDER BY fields ] LIMIT n ]
-
2.全部删除(表清空,包含自增计数器重置):
- TRUNCATE table
时间差:
- TIMESTAMPDIFF(interval, time_start, time_end)可计算time_start-time_end的时间差,单位以指定的interval为准,常用可选:
- SECOND 秒
- MINUTE 分钟(返回秒数差除以60的整数部分)
- HOUR 小时(返回秒数差除以3600的整数部分)
- DAY 天数(返回秒数差除以3600*24的整数部分)
- MONTH 月数
- YEAR 年数
【SQL7】知识点:不同删除的比较
TRUNCATE exam_record知识点:
-
1.DROP TABLE
- 清除数据并且销毁表,是一种数据库定义语言(DDL Data Definition Language), 执行后不能撤销,被删除表格的关系,索引,权限等等都会被永久删除。
-
2.TRUNCATE TABLE
- 只清除数据,保留表结构,列,权限,索引,视图,关系等等,相当于清零数据,是一种数据库定义语言(DDL Data Definition Language),执行后不能撤销。
-
3.DELETE TABLE
- 删除(符合某些条件的)数据,是一种数据操纵语言(DML Data Manipulation Language),执行后可以撤销(在事务中delete可以回滚)。
【SQL9】知识点:表的创建与修改
知识点:
1.创建表
- 直接创建表
- 从另一张表复制表结构创建表
- 从另一张表的查询结果创建表
1.直接创建表
CREATE TABLE
[IF NOT EXISTS] tb_name -- 不存在才创建,存在就跳过
(column_name1 data_type1 -- 列名和类型必选
[ PRIMARY KEY -- 可选的约束,主键
| FOREIGN KEY -- 外键,引用其他表的键值
| AUTO_INCREMENT -- 自增ID
| COMMENT comment -- 列注释(评论)
| DEFAULT default_value -- 默认值
| UNIQUE -- 唯一性约束,不允许两条记录该列值相同
| NOT NULL -- 该列非空
], ...
) [CHARACTER SET charset] -- 字符集编码
[COLLATE collate_value] -- 列排序和比较时的规则(是否区分大小写等)2.从另一张表复制表结构创建表
CREATE TABLE tb_name LIKE tb_name_old3.从另一张表的查询结果创建表
CREATE TABLE tb_name AS SELECT * FROM tb_name_old WHERE options2.修改表
ALTER TABLE 表名 修改选项
{ ADD COLUMN <列名> <类型> -- 增加列
| CHANGE COLUMN <旧列名> <新列名> <新列类型> -- 修改列名或类型
| ALTER COLUMN <列名> { SET DEFAULT <默认值> | DROP DEFAULT } -- 修改/删除 列的默认值
| MODIFY COLUMN <列名> <类型> -- 修改列类型
| DROP COLUMN <列名> -- 删除列
| RENAME TO <新表名> -- 修改表名
| CHARACTER SET <字符集名> -- 修改字符集
| COLLATE <校对规则名> } -- 修改校对规则(比较和排序时用到)
【SQL12】知识点:索引创建、删除与使用
1.创建索引
2.删除索引
3.使用索引
1创建索引
1.1 create方式创建索引
CREATE
[UNIQUE -- 唯一索引| FULLTEXT -- 全文索引]
INDEX index_name ON table_name -- 不指定唯一或全文时默认普通索引
(column1[(length) [DESC|ASC]] [,column2,...]) -- 可以对多列建立组合索引
1.2alter方式创建索引
ALTER TABLE tb_name ADD [UNIQUE | FULLTEXT] [INDEX] index_content(content)2删除索引
2.1drop方法
DROP INDEX <索引名> ON <表名>2.2alter方法
ALTER TABLE <表名> DROP INDEX <索引名>3索引的使用(有点不理解)
- 索引使用时满足最左前缀匹配原则,即对于组合索引(col1, col2),在不考虑引擎优化时,条件必须是col1在前col2在后,或者只使用col1,索引才会生效;
- 索引不包含有NULL值的列
- 一个查询只使用一次索引,where中如果使用了索引,order by就不会使用
- like做字段比较时只有前缀确定时才会使用索引
- 在列上进行运算后不会使用索引,如year(start_time)<2020不会使用start_time上的索引
【SQL17】知识点:date_format、count(字段1,字段2)、round()


知识点:
1.date_format() 通过这个函数匹配'%Y%m'年份和月份;
date_format(submit_time,%Y%M)
2.count(字段1,字段2)形式的含义
以202107这个月的数据来看,该分组下的集合元素有:
1100190012021-07-0209:01:012021-07-0209:21:0180
5100290012021-07-0219:01:012021-07-0219:30:0182
6100290022021-07-0518:01:012021-07-0518:59:0290
如果仅仅写COUNT(date_format(submit_time,%Y%M%d)),那么结果应该是2,因为一个是0702一个是0705,但是如果是用户活跃天数,应该是这样计算的:1001用户活跃了一天,1002用户活跃了2两天,(2+1)/2=1.5天,而不是刚刚那样计算天数。所以要先根据用户编号(uid=1001,1002)为约束,count每个uid的天数,最后累加,所以要写成:
count(distinct uid,date_format(submit_time,'%y%m%d')/count(distinct uid)其他注意点:MySQL中 COUNT在对列进行计数时不统计值为 null的条目
3.round(字段名,k)保留k个小数
最终答案:
select date_format(submit_time, '%Y%m') as month,
round((count(distinct uid, date_format(submit_time, '%y%m%d'))) / count(distinct uid), 2) as avg_active_days,
count(distinct uid) as mau
from exam_record
where submit_time is not null
and year(submit_time) = 2021
group by date_format(submit_time, '%Y%m')【SQL错题1】知识点:union、any_value、last_day
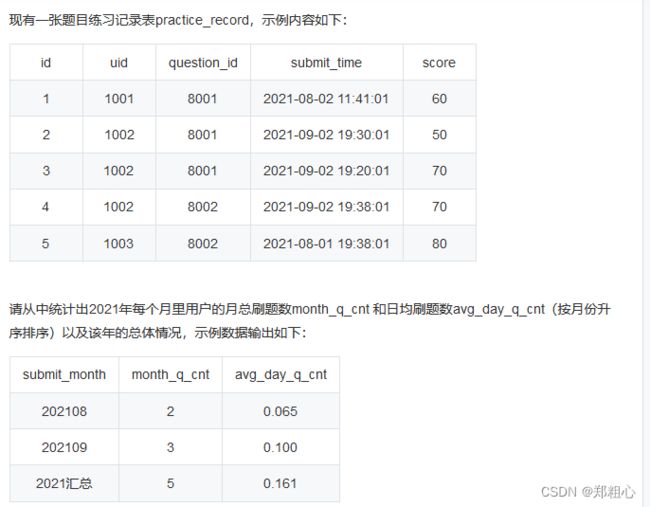
解释:2021年8月共有2次刷题记录,日均刷题数为2/31=0.065(保留3位小数);2021年9月共有3次刷题记录,日均刷题数为3/30=0.100;2021年共有5次刷题记录(年度汇总平均无实际意义,这里我们按照31天来算5/31=0.161)
答案:
关于解决最新的SQL版本中ONLY_FULL_GROUP_BY报错的办法:
ONLY_FULL_GROUP_BY的语义就是确定select 中的所有列的值要么是来自于聚合函数(sum、avg、max等)的结果,要么是来自于group by list中的表达式的值。MySQL提供了any_value()函数来抑制ONLY_FULL_GROUP_BY值被拒绝。
所以只需要在非group by的列上加any_value()就可以了
select date_format(submit_time,'%Y%m') submit_month,
any_value(count(question_id)) month_q_cnt,
any_value(round(count(question_id)/day(LAST_DAY(submit_time)),3)) avg_day_q_cnt
from practice_record
where date_format(submit_time,'%Y')='2021'
group by submit_month
union all
select '2021汇总' as submit_month,
count(question_id) month_q_cnt,
round(count(id)/31,3) avg_day_q_cnt
from practice_record
where date_format(submit_time,'%Y')='2021'
order by submit_month;知识点:
-
1.union 与 union all
- union 相当于or 会去重,union all是不去重
-
2.last_day()
- 获取当前时间的最后一天的日期,配合day()函数可以得到一个月有多少天
-
3.any_value()
- 用于select 中 非group by 的列
【SQL错题2】知识点:条件函数IF(X,A,B)如果符合X条件,返回A,否则B

答案:在这里group by 可以用SELECT中的别名age_cut是因为MYSQL更新了
SELECT IF(age>=25,'25岁及以上','25岁以下') AS age_cut,
COUNT(device_id) number
FROM user_profile
GROUP BY age_cut【SQL错题3】知识点:容易忽略的逻辑问题(重要)
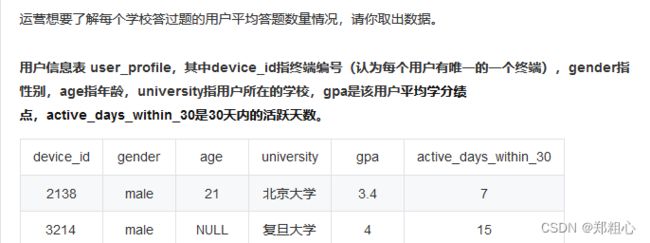
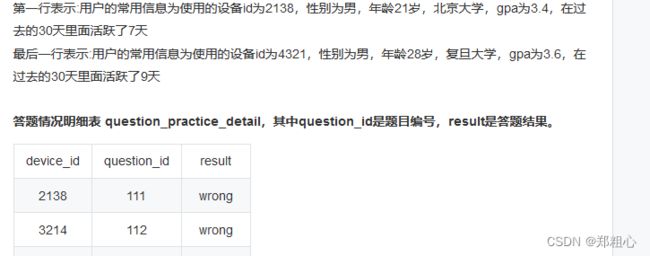
(图没截全,表结构清楚就行)
我自己写的思路:
题目要求的是求解每个学校的平均答题数,那我们需要知道每个学校的用户,每个用户的答题数然后相加,公式为:答题数/用户数
先求用户数:user_profile中按照university分组count一下行
再就每个用户的答题数:在question_pratice_detail中对device_id,count答题数
将两个表按照device_id join,按照University对答题数求和就出来了
SELECT u.university,
ROUND(SUM(a.num)/COUNT(DISTINCT u.device_id),3) avg_answer_cnt
FROM user_profile u
JOIN
(SELECT device_id ,COUNT(device_id) num FROM question_practice_detail GROUP BY device_id) a
ON
a.device_id = u.device_id
GROUP BY u.university
ORDER BY u.university答案:
这解题思路就很妙,妙在我能发出感叹:“还能这样搞的吗?”
/*
分析思路
select 查询结果 [university,'每个人平均答题数量':问题数/设备数(一个设备对应多个题,要去重)]
from 从哪张表中查找数据[两张表联结]
where 查询条件 [无]
group by 分组条件 [university]
*/
-- avg_answer_cnt = count(question_id)/count(device_id)
select university,(count(question_id)/count(distinct(q.device_id)))
as avg_answer_cnt
from user_profile u
join question_practice_detail q on u.device_id = q.device_id
group by university;最关键的一点我不明白的是以下这段代码,为了更好表述我稍微修改了一下:
select university,count(question_id)
from user_profile
join question_practice_detail using(device_id)
GROUP BY university直接将两表连接,用university分组就能知道哪些question_id是属于哪个学校的了。为了更好理解,我把表连接的所有字段都输出
select u.*,a.*
from user_profile u
join question_practice_detail a using(device_id) 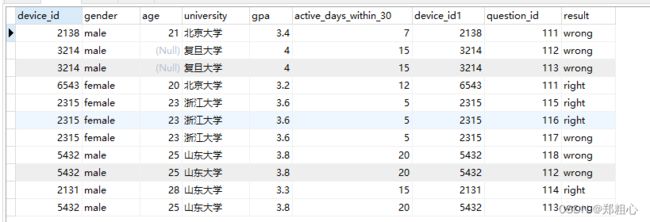
现在大概懂了表连接的字面上的意义了。就是把两个表按照一个条件拼凑在一起。(之前就是这么认为的,但是没有这次理解的这么透彻)
拼凑后就可以直接group by university了。
学习心得:遇到不太理解的点,每一步骤都查看一下查询子集。
【SQL错题4】知识点:计算留存率(应用题,重要)

所谓次日留存,指的是同一用户(在本题中则为同一设备,即device_id)在当天和第二天都进行刷题。注意,在这题我们不关心同一用户(设备)在这天答了什么题、答题结果如何,只关心他是否答题,因此对于这题来说使用 DISTINCT 去重即可。
令次日留存率为c,a为去重的数据表中符合次日留存的条目数目,b为去重的数据表中多有的条目数目,套入下面的公式即可:
![]()
解题步骤:
第一步,获取去重的所有条目数目
疑问:为什么要去重?
答:因为可能某个用户在同一天多次登陆,但是我们只算他登陆了一次,因为次日留存只在乎他是否连续两天登陆,不在乎他登陆几次。
SELECT DISTINCT device_id,date FROM question_practice_detail该SQL是筛选出device_id+date不重复的数据,即对数据去重了。可以观察一下1236这两条数据为例:

去重后得到:

第二步,获取次日留存的用户数据
分析:此时由第一步已经得到了去重的数据表,那接下来根据这个表进行表连接就行。约束条件有两个,第一,device_id相等;第二,同一用户下利用date_add判断是否第二天仍然登陆
对表起别名,分别为q1,q2
知识点:1.date_add()
date_add(date1, interval 1 day)=date2
...省略,先不加入...
(SELECT DISTINCT device_id, date FROM question_practice_detail)as q1
JOIN
(SELECT DISTINCT device_id, date FROM question_practice_detail) AS q2
ON q1.device_id = q2.device_id AND q2.date = DATE_ADD(q1.date, interval 1 day)第三步,汇总
SELECT
COUNT(q2.device_id) / COUNT(q1.device_id) AS avg_ret
FROM
(SELECT DISTINCT device_id, date FROM question_practice_detail)as q1
LEFT JOIN
(SELECT DISTINCT device_id, date FROM question_practice_detail) AS q2
ON q1.device_id = q2.device_id AND q2.date = DATE_ADD(q1.date, interval 1 day)
要用left join(左连接),因为只有这样,当q2.date = date_add(q1.date,interval 1 day )条件不满足时还能展示在条目中,将最后结果的数据展示出来:
SELECT
q1.device_id,q2.device_id,q1.date,q2.date AS avg_ret
FROM
(SELECT DISTINCT device_id, date FROM question_practice_detail)as q1
LEFT JOIN
(SELECT DISTINCT device_id, date FROM question_practice_detail) AS q2
ON q1.device_id = q2.device_id AND q2.date = DATE_ADD(q1.date, interval 1 day)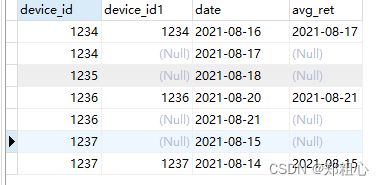
3/7≈0.428
【SQL错题5】得分不小于平均分的最低分


做题,最重要的是要讲清楚自己的分析思路!开始分析!!!!
【分析过程】
第一步,![]()
题目要我们求的是不低于SQL试卷平均分的最低得分。确定了解决的问题,接下来就是分析需要求得哪些数据。
很显然,第一个,我们要求的是SQL试卷的平均分。下表起个别名a
SELECT SUM(score)/COUNT(score) avg_score FROM exam_record
JOIN
examination_info USING(exam_id) WHERE tag = 'SQL'这里直接用avg也可以,也会忽略NULL值。
第二个,我们要求的是大于SQL平均分的数据。所以将a表的值作为一个列
SELECT * FROM exam_record,
(SELECT avg(score) avg_score FROM exam_record
JOIN
examination_info USING(exam_id) WHERE tag = 'SQL') a

第三步,只要将此表与examination_info 再join一下
SELECT * FROM exam_record,
(SELECT avg(score) avg_score FROM exam_record
JOIN
examination_info USING(exam_id) WHERE tag = 'SQL') a
JOIN examination_info USING(exam_id)然后发现就报错了。原因在于,examination_info和这个a表连不起来,没有共同的交集(即字段)
所以我们转变一下思路。从头开始!
第一步 ,先连examnation_info
SELECT * FROM exam_record
JOIN examination_info USING(exam_id)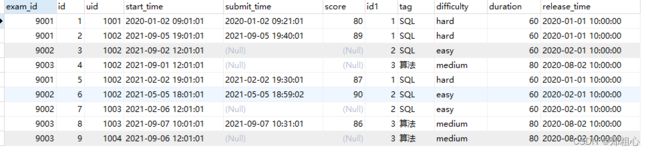
第二步,求平均值
SELECT avg(score) avg_score FROM exam_record
JOIN examination_info USING(exam_id) WHERE tag = 'SQL'第三步,对第一步建立的表进行筛选,增加条件。两个条件:1.tag = sql,2.score>平均分
SELECT MIN(score) FROM exam_record a
JOIN examination_info USING(exam_id)
WHERE tag = 'SQL'
AND a.score >= (
SELECT AVG(score) avg_score FROM exam_record
JOIN examination_info USING(exam_id) WHERE tag = 'SQL')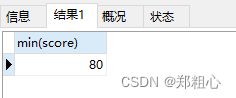
最后结果就出来了,在题目里还要将该字段重命名!
【SQL错题6】 知识点:多张表的连接,简单但是考验你的逻辑(适合初学者)


 【分析过程】
【分析过程】
可以看出来,三张表的信息是相互关联的,所以不管三七二十一,我先把三个表连在一块儿:
SELECT * FROM question_practice_detail
JOIN question_detail USING(question_id)
JOIN user_profile USING(device_id)
好了,问题就解决了。
按照题设条件,对university、difficulty level进行分组,然后按照公式:
答题数量/用户数量
就可以做出来了
SELECT university,difficult_level,
COUNT(question_id)/COUNT(DISTINCT device_id)
FROM question_practice_detail
JOIN question_detail USING(question_id)
JOIN user_profile USING(device_id)
GROUP BY university,difficult_level注意这里的用户要去重,question不用,因为同样的题做两遍也是算做题数

总结:根据这几天的刷题,我对怎么做题有了一些思路。无非就是表连接,增加筛选条件。基础打扎实!开始学习运维篇。
补充:其他较难的题我就先放放了,要不然信心都没了