FlashAttention:Fast and Memory-Efficient Exact Attention with IO-Awareness
FlashAttention让语言模型拥有更长的上下文
- FlashAttention
-
- 序:
- 概述:
- 简介:
-
- FlashAttention
- 块稀疏 FlashAttention
- 优点:
- 标准注意力算法实现流程:
- FlashAttention
- Block-Sparse FlashAttention
- 实验
-
- 使用FlashAttention后更快的模型
-
- BERT
- GPT-2
- Long-range Arena
- 具有更长序列的更好模型
-
- Megatron-LM
- 具有长上下文的语言模型
- 长文档分类
- Path-X and Path-256
- Benchmarking Attention
FlashAttention
序:
基于 FlashAttention 技术,清华将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。
概述:
-
给 Transformer 配备更长的上下文仍然很困难,因为 Transformer 核心自注意力模块的时间复杂度以及内存复杂度在序列长度上是二次方的。
-
FlashAttention是一种新的注意力机制,旨在解决Transformer在处理长序列时速度慢且内存需求大的问题。
-
FlashAttention的创新之处在于引入了IO(输入/输出)感知的设计原则,专注于减少GPU内存(高带宽内存)和GPU片上内存(SRAM)之间的读写次数。它使用平铺(tiling)的方法来实现这一目标,从而降低了数据在不同级别存储器之间的传输次数。
-
此外,研究者还将FlashAttention扩展到块稀疏注意力(block-sparse attention),产生比现有的近似注意力方法更快的近似注意力算法。
简介:
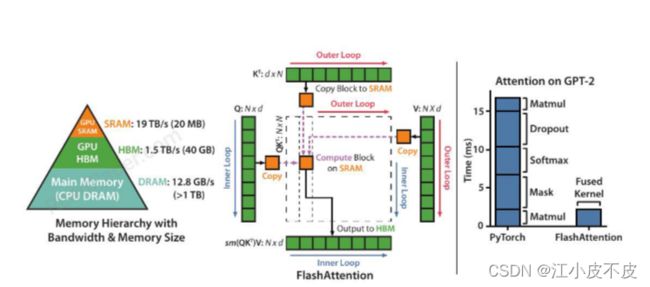
- SRAM:SRAM(Static Random Access Memory)是一种高速、低延迟的随机访问存储器。在GPU(Graphics Processing Unit,图形处理器)中,SRAM通常用于存储临时数据、缓存以及计算中的中间结果。GPU SRAM是指嵌入在GPU芯片上的SRAM存储器。
- HBM(High-Bandwidth Memory):HBM是一种高带宽、低功耗的内存技术。GPU HBM是指嵌入在GPU芯片上的HBM存储器。相对于传统的GDDR(Graphics Double Data Rate)内存,HBM具有更高的带宽和更低的能耗,使得GPU能够更快地读取和写入数据。
- DARM(Dynamic Random Access Memory):DARM是一种动态随机访问存储器,用于存储CPU(Central Processing Unit,中央处理器)中的数据和指令。DARM是一种较为常见的内存类型,具有较高的存储密度,但相对于SRAM和HBM而言,它的访问速度较慢,延迟较高。CPUDARM指的是嵌入在CPU芯片上的DARM存储器。
FlashAttention
这是一种新的注意力算法,主要目标是避免从 HBM 读取和写入注意力矩阵。
- 在不访问整个输入的情况下计算 softmax 缩减。
我们重组注意力计算以将输入分成块并在输入块上进行多次传递,从而逐步执行 softmax 缩减(也称为平铺)
- 不为后向传递存储大的中间注意力矩阵。
存储前向传播的 softmax 归一化因子,以便在后向传播中快速重新计算片上注意力,这比从 HBM 读取中间注意力矩阵的标准方法更快。我们在 CUDA 中实现了FlashAttention以实现对内存访问的细粒度控制,并将所有注意力操作融合到一个 GPU 内核中。
即使由于重新计算而增加了 FLOP,我们的算法也比标准注意力更快地运行(在 GPT-2 [67] 上高达 7.6 倍,图1 右)并且使用更少的内存(序列长度呈线性),这要归功于大量减少 HBM 访问量。
块稀疏 FlashAttention
这是一种稀疏注意力算法,比 FlashAttention 快 2-4 倍,可扩展到 64k 的序列长度。
我们通过与稀疏率成比例的因子证明块稀疏 FlashAttention具有比 FlashAttention更好的 IO 复杂性。
优点:
- 更快的模型训练
FlashAttention 在wall-clocktime更快地训练 Transformer 模型。我们训练BERT-large(序列长度 512)比 MLPerf 1.1中的训练速度记录快 15%,GPT2(序列长度 1K)比HuggingFace和 Megatron-LM的基线实现快 3 倍和远程竞技场(序列长度 1K-4K)比基线快 2.4倍。
ps:“wall-clock time”是指墙上时钟时间,也称为实际时间或绝对时间。它是指从某个事件或操作的开始到结束所经过的实际时间,包括了所有的等待时间、执行时间和其他延迟。与之相对的是“CPU时间”,它只计算CPU执行指令所花费的时间,而不考虑等待时间或其他延迟。
- 更高质量的模型。
FlashAttention 将 Transformers 扩展到更长的序列,从而提高它们的质量并启用新功能。我们观察到 GPT-2 的困惑度提高了 0.7,在长文档分类上对较长序列进行建模得到了 6.4 个提升点。 FlashAttention 使第一个 Transformer 能够在 Path-X挑战中实现优于机会的性能,仅通过使用更长的序列长度 (16K)。块稀疏 FlashAttention 使 Transformer 能够扩展到更长的序列 (64K),从而产生了第一个可以在 Path-256 上实现优于机会性能的模型。
ps:在自然语言处理中,困惑度是一种用来评估语言模型质量的指标。它衡量了一个语言模型对给定文本序列中下一个词的预测能力。困惑度越低,表示模型的预测能力越好。
- 基准化注意力。
FlashAttention 在 128 到 2K 的常见序列长度上比标准注意力实现快 3 倍,并可扩展到 64K。直到序列长度达到 512,FlashAttention 比任何现有的注意方法都更快且更节省内存,而对于超过 1K 的序列长度,一些近似注意方法(例如 Linformer)开始变得更快。另一方面,块稀疏FlashAttention 比我们所知的所有现有近似注意力方法都快。
标准注意力算法实现流程:
![]()
-
从 HBM 按块加载 Q, K,计算 S = QK ,将 S 写入 HBM。
-
从 HBM读取 S,计算 P = softmax(S),将 P 写入 HBM。
-
从 HBM 中按块加载 P和 V,计算 O = PV,将 O 写入 HBM。
-
返回O。
FlashAttention
通过tiling和recomputation技术来优化注意力机制计算
- 使用tiling技术将注意力计算过程分块
- 使用recomputation技术在每个块内重新计算注意力输出
以此来优化Transformer模型在HBM和SRAM混合内存架构下的注意力计算过程。它避免了直接在HBM上计算整个注意力所需的大量读写,通过在SRAM上分块计算和最后的聚合,实现了较低的内存和计算复杂度。
实现细节:内核融合。平铺使我们能够在一个 CUDA 内核中实现我们的算法,从 HBM 加载输入,执行所有计算步骤(矩阵乘法、softmax、可选的掩码和丢弃、矩阵乘法),然后将结果写回 HBM。这避免了重复读取和写入 HBM 的输入和输出。

HBM 访问次数是注意力运行时间的主要决定因素。
- 在图 2(左)中,我们看到尽管FlashAttention与标准注意力相比具有更高的 FLOP 计数(由于反向传递中的重新计算),但它具有更少的 HBM 访问,从而导致更快的运行时间。
- 在图 2(中)中,我们改变了FlashAttention的块大小 B.,这导致了不同数量的 HBM 访问,并测量了前向传递的运行时间。随着块大小的增加,HBM 访问次数减少(因为我们对输入的传递次数减少),运行时间减少。对于足够大的块大小(超过 256),运行时会受到其他因素(例如算术运算)的瓶颈。此外,较大的块大小将不适合较小的 SRAM 大小。
Block-Sparse FlashAttention
我们将 FlashAttention扩展到近似注意力:我们提出块稀疏 FlashAttention,其 IO 复杂度比FlashAttention小一个与稀疏性成比例的因子。

在图 2(右)中,我们验证了随着稀疏度的增加,块稀疏 FlashAttention的运行时间成比例地提高。在 LRA 基准测试中,块稀疏 FlashAttention 实现了 2.8× 的加速,同时与标准注意力表现相当。
实验
使用FlashAttention后更快的模型
BERT

我们在维基百科上使用FlashAttention训练了一个 BERT-large 模型。
表 1 将我们的训练时间与 Nvidia 的实施进行了比较,Nvidia 为 MLPerf 1.1 设置了训练速度记录。我们的实施速度提高了 15%。
GPT-2

与广泛使用的 HuggingFace和 Megatron-LM实现相比,FlashAttention 在大型 OpenWebtext 数据集上为 GPT-2 产生更快的训练时间。
表 2 显示与 Huggingface 相比高达 3× 端到端加速,与 Megatron-LM 相比高达 1.7× 加速。FlashAttention 实现了与其他两个实现相同的困惑,因为我们没有改变模型定义。
Long-range Arena
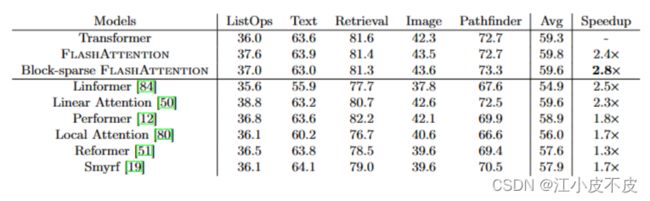
LRA:用来对长语境场景下的序列模型进行基准测试。该基准包括合成任务和现实任务
LRA 基准包含多项任务,旨在评估高效 Transformer 模型的不同能力。具体而言,这些任务包括:Long ListOps、比特级文本分类、比特级文档检索、基于像素序列的图像分类、Pathfinder(长程空间依赖性)、Pathfinder-X(极端长度下的长程空间依赖性)。
具有更长序列的更好模型
Megatron-LM
Megatron-LM是一个基于PyTorch的框架,用于训练基于Transformer架构的巨型语言模型。它实现了高效的大规模语言模型训练,主要通过以下几种方式:
- 模型并行:将模型参数分散在多个GPU上,减少单个GPU的内存占用23。
- 数据并行:将数据批次分散在多个GPU上,增加训练吞吐量4。
- 混合精度:使用16位浮点数代替32位浮点数,减少内存和带宽需求,提高计算速度4。
- 梯度累积:在多个数据批次上累积梯度,然后再更新参数,降低通信开销4。
- Megatron-LM还可以与其他框架如DeepSpeed结合,实现更高级的并行技术,如ZeRO分片和管道并行5。这样可以进一步提升训练效率和规模。
具有长上下文的语言模型

FlashAttention 的运行时和内存效率使我们能够将 GPT-2 的上下文长度增加4 倍,同时仍然比 Megatron-LM 的优化实现运行得更快。
表 4 显示,具有 FlashAttention 和上下文长度 4K 的 GPT-2 仍然比上下文长度为 1K 的 Megatron 的 GPT-2 快 30%,同时实现了 0.7 更好的困惑度。
长文档分类
使用 FlashAttention 训练具有较长序列的 Transformer 可提高 MIMIC-III 和 ECtHR数据集的性能。

Path-X and Path-256
Path-X 和 Path-256 基准测试是旨在测试长上下文的远程竞技场基准测试中具有挑战性的任务。任务是对黑白 128×128(或 256×256)图像中的两个点是否有连接它们的路径进行分类,并且图像一次一个像素地馈送到变换器。
在之前的工作中,所有 Transformer 模型要么内存不足,要么只达到随机性能。人们一直在寻找可以对如此长的上下文进行建模的替代架构。我们在这里展示了Transformer 模型能够求解 Path-X 和 Path-256 的第一个结果(表 6)。我们在 Path-64 上预训练了一个转换器,然后通过对位置嵌入进行空间插值来转移到 Path-X。 FlashAttention 在 Path-X 上达到了61.4 的准确率。此外,块稀疏 FlashAttention 使 Transformers 能够扩展到序列长度 64K,在 Path-256上实现 63.1 精度。

Benchmarking Attention

FlashAttention和块稀疏FlashAttention在长短序列下的运行时间和内存消耗情况。
- FlashAttention的运行时间随序列长度呈二次方增长,但比精确注意力基线快3倍,比PyTorch实现快很多。这表明FlashAttention可以有效降低长序列注意力的计算复杂度。
- 许多近似/稀疏注意力的运行时间随序列长度线性增长,但FlashAttention在短序列下仍比它们运行得更快。这是因为FlashAttention 减少了内存访问,加速了计算。但在512-1024长度范围,近似注意力开始超过FlashAttention。
- 块稀疏FlashAttention在所有序列长度上都比我们知道的精确、稀疏和近似注意的所有实现更快。
- FlashAttention和块稀疏FlashAttention的内存占用随序列长度线性增长,但比精确注意力基线高20倍,也高于近似注意力基线。除Lin former外,其他算法在64K长度下的A100 GPU上会耗尽内存,而FlashAttention的效率仍比Linformer高2倍。