【优选算法】—— 前缀和算法
前言:
- 本期,我将要带大家学习的是有关前缀和算法的学习!!!
目录
(一)什么是前缀和算法
(二)题目讲解
1、【模板】前缀和
2、【模板】二维前缀和
3、 和可被K整除的⼦数组
总结
(一)什么是前缀和算法
前缀和算法是一种用于高效计算数组前缀和的算法。前缀和是指从数组的起始位置到某一位置的所有元素的和。
下面是前缀和算法的基本步骤:
-
创建一个与原始数组相同长度的前缀和数组。初始时,前缀和数组的第一个元素与原始数组的第一个元素相同。
-
从第二个元素开始,遍历原始数组,计算每个位置处的前缀和,即将前一个位置的前缀和与当前位置的元素相加。
-
将计算得到的前缀和存储到前缀和数组的相应位置。
-
完成遍历后,前缀和数组中存储了原始数组每个位置的前缀和值。
前缀和算法的主要优势在于它可以用较低的时间复杂度O(n)计算指定范围内的元素和,而不是每次都需要重新遍历计算。
以下是一个示例,演示如何使用前缀和算法计算数组的前缀和:
- 原始数组: [1, 2, 3, 4, 5]
- 前缀和数组: [1, 3, 6, 10, 15]
【解释说明】
- 原始数组的前缀和:[1, 1+2, 1+2+3, 1+2+3+4, 1+2+3+4+5] = [1, 3, 6, 10, 15]
(二)题目讲解
1、【模板】前缀和
- 链接如下:【模板】前缀和
【算法思路】
a. 先预处理出来⼀个「前缀和」数组:
- ⽤ dp[i] 表⽰: [1, i] 区间内所有元素的和,那么 dp[i - 1] ⾥⾯存的就是[1,i-1] 区间内所有元素的和,那么:可得递推公式: dp[i] = dp[i - 1] + arr[i]
b. 使⽤前缀和数组,「快速」求出「某⼀个区间内」所有元素的和:
- 当询问的区间是 [l, r] 时:区间内所有元素的和为: dp[r] - dp[l - 1] 。
【代码展示】
#include
using namespace std;
const int N = 100010;
long long arr[N], dp[N];
int n, q;
int main()
{
cin >> n >> q;
// 读取数据
for(int i = 1; i <= n; i++) cin >> arr[i];
// 处理前缀和数组
for(int i = 1; i <= n; i++) dp[i] = dp[i - 1] + arr[i];
while(q--)
{
int l, r;
cin >> l >> r;
// 计算区间和
cout << dp[r] - dp[l - 1] << endl;
}
return 0;
} 输出展示:

【性能分析】
时间复杂度:
- 初始化前缀和数组:需要遍历整个原始数组,时间复杂度为O(n)。
- 对每个查询计算区间和:只需要进行常数次操作,时间复杂度为O(1)。
总体时间复杂度为O(n + q),其中n表示数组长度,q表示查询次数。
空间复杂度:
- 空间复杂度为O(n),其中n表示数组长度。需要额外的前缀和数组来存储计算得到的前缀和。
【注意】
这里有一个细节问题:为什么下标不从0开始,而是从 1 开始?
其实很简单,在该代码中,数组索引从1开始的原因是为了方便计算前缀和;
- 在前缀和算法中,我们需要维护一个前缀和数组,其中每个元素表示原始数组从开头到当前位置的累加和;
- 如果数组索引从0开始,那么在计算前缀和时,需要特殊处理索引为0的情况,这会增加代码的复杂性。

通过将数组索引从1开始,可以使得计算前缀和的逻辑更加简单和直观。例如,在第i个位置上的前缀和可以通过dp[i] = dp[i-1] + arr[i]来计算,而无需额外处理索引为0的情况。
2、【模板】二维前缀和
- 链接如下:【模板】二维前缀和
【算法思路】
类⽐于⼀维数组的形式,如果我们能处理出来从 [0, 0] 位置到 [i, j] 位置这⽚区域内所有元素的累加和,就可以在 O(1) 的时间内,搞定矩阵内任意区域内所有元素的累加和。因此我们接下来仅需完成两步即可:
第⼀步:搞出来前缀和矩阵
- 这⾥就要⽤到⼀维数组⾥⾯的拓展知识,我们要在矩阵的最上⾯和最左边添加上⼀⾏和⼀列0,这样我们就可以省去⾮常多的边界条件的处理(同学们可以⾃⾏尝试直接搞出来前缀和矩阵,边界条件的处理会让你崩溃的)。处理后的矩阵就像这样:
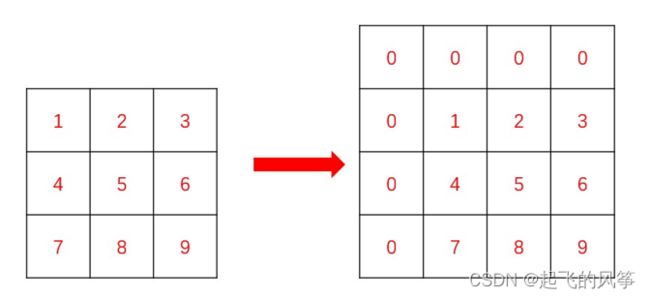
这样,我们填写前缀和矩阵数组的时候,下标直接从 1 开始,能⼤胆使⽤ i - 1 , j - 1 位
置的值。
注意 dp 表与原数组 matrix 内的元素的映射关系:
- i. 从 dp 表到 matrix 矩阵,横纵坐标减⼀;
- ii. 从 matrix 矩阵到 dp 表,横纵坐标加⼀。
前缀和矩阵中 sum[i][j] 的含义,以及如何递推⼆维前缀和⽅程
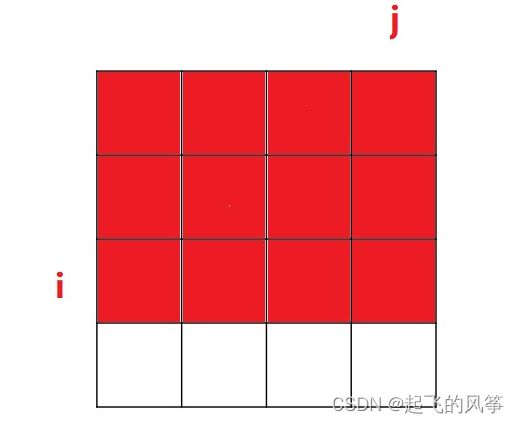
a. sum[i][j] 的含义:
- sum[i][j] 表⽰,从 [0, 0] 位置到 [i, j] 位置这段区域内,所有元素的累加和。对应下图的红⾊区域:
b. 递推⽅程:
- 其实这个递推⽅程⾮常像我们⼩学做过求图形⾯积的题,我们可以将 [0, 0] 位置到 [i, j] 位置这段区域分解成下⾯的部分:
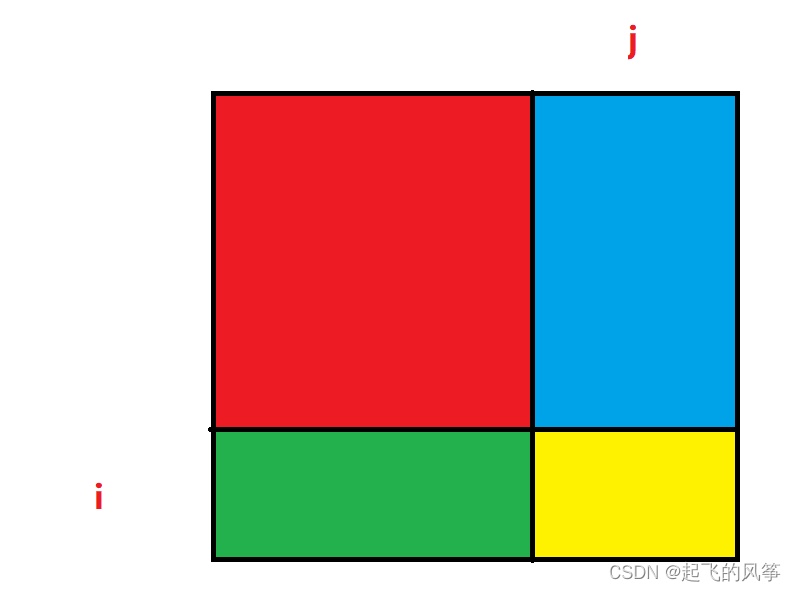
sum[i][j] =红+蓝+绿+⻩,分析⼀下这四块区域:
- i. ⻩⾊部分最简单,它就是数组中的 matrix[i - 1][j - 1] (注意坐标的映射关系)
- ii. 单独的蓝不好求,因为它不是我们定义的状态表⽰中的区域,同理,单独的绿也是;
- iii. 但是如果是红+蓝,正好是我们 dp 数组中 sum[i - 1][j] 的值,美滋滋;
- iv. 同理,如果是红+绿,正好是我们 dp 数组中 sum[i][j - 1] 的值;
- v. 如果把上⾯求的三个值加起来,那就是⻩+红+蓝+红+绿,发现多算了⼀部分红的⾯积,因此再单独减去红的⾯积即可;
- vi. 红的⾯积正好也是符合 dp 数组的定义的,即 sum[i - 1][j - 1]
综上所述,我们的递推⽅程就是:
sum[i][j]=sum[i - 1][j] + sum[i][j - 1] - sum[i - 1][j -1]+matrix[i - 1][j - 1]第⼆步:使⽤前缀和矩阵
题⽬的接⼝中提供的参数是原始矩阵的下标,为了避免下标映射错误,这⾥直接先把下标映射成dp 表⾥⾯对应的下标: row1++, col1++, row2++, col2++
接下来分析如何使⽤这个前缀和矩阵,如下图(注意这⾥的 row 和 col 都处理过了,对应的正是 sum 矩阵中的下标):

对于左上⻆ (row1, col1) 、右下⻆ (row2, col2) 围成的区域,正好是红⾊的部分。因
此我们要求的就是红⾊部分的⾯积,继续分析⼏个区域:
- i. ⻩⾊,能直接求出来,就是 sum[row1 - 1, col1 - 1] (为什么减⼀?因为要剔除掉 row 这⼀⾏和 col 这⼀列)
- ii. 绿⾊,直接求不好求,但是和⻩⾊拼起来,正好是 sum 表内 sum[row1 - 1][col2]的数据;
- iii. 同理,蓝⾊不好求,但是蓝+⻩= sum[row2][col1 - 1] ;
- iv. 再看看整个⾯积,好求嘛?⾮常好求,正好是 sum[row2][col2] ;
- v. 那么,红⾊就=整个⾯积-⻩-绿-蓝,但是绿蓝不好求,我们可以这样减:整个⾯积-(绿+⻩)-(蓝+⻩),这样相当于多减去了⼀个⻩,再加上即可
综上所述:红=整个⾯积 -(绿+⻩)-(蓝+⻩)+⻩,从⽽可得红⾊区域内的元素总和为:
sum[row2][col2]-sum[row2][col1 - 1]-sum[row1 - 1][col2]+sum[row1 -1][col1 - 1]【代码展示】
#include
using namespace std;
const int N=1010;
int arr[N][N];
long long dp[N][N];
int n,m,q;
int main()
{
cin >> n >>m >>q;
// 读⼊数据
for(int i = 1; i <= n; i++)
{
for(int j = 1; j <= m; j++){
cin >> arr[i][j];
}
}
// 处理前缀和矩阵
for(int i = 1; i <= n; i++){
for(int j = 1; j <= m; j++){
dp[i][j] = dp[i - 1][j] + dp[i][j - 1] + arr[i][j] - dp[i - 1][j -1];
}
}
// 使⽤前缀和矩阵
int x1, y1, x2, y2;
while(q--)
{
cin >>x1 >> y1 >> x2 >> y2;
cout << dp[x2][y2] - dp[x1 - 1][y2] - dp[x2][y1 - 1] + dp[x1 - 1][y1 -1] << endl;
}
return 0;
}
// 64 位输出请用 printf("%lld") 输出展示:

【性能分析】
时间复杂度:
- 初始化前缀和矩阵:需要遍历整个原始矩阵,时间复杂度为O(n * m),其中n表示行数,m表示列数。
- 对每个查询计算区域和:只需要进行常数次操作,时间复杂度为O(1)。
总体时间复杂度为O(n * m + q),其中n表示行数,m表示列数,q表示查询次数。
空间复杂度:
- 空间复杂度为O(n * m),其中n表示行数,m表示列数。需要额外的前缀和矩阵来存储计算得到的前缀和。
3、 和可被K整除的⼦数组
- 链接如下:和可被K整除的⼦数组
【解法】(暴⼒解法就是枚举出所有的⼦数组的和,这⾥不再赘述)
本题需要的前置知识:
同余定理
- 如果 (a - b) % n == 0 ,那么我们可以得到⼀个结论: a % n == b % n 。⽤⽂字叙述就是,如果两个数相减的差能被n整除,那么这两个数对n取模的结果相同。
例如: (26 - 2) % 12 == 0 ,那么 26 % 12 == 2 % 12 == 2
c++ 中负数取模的结果,以及如何修正「负数取模」的结果
- a. c++ 中关于负数的取模运算,结果是「把负数当成正数,取模之后的结果加上⼀个负号」。例如: -1 % 3 = -(1 % 3) = -1
- b. 因为有负数,为了防⽌发⽣「出现负数」的结果,以 (a % n + n) % n 的形式输出保证为正。
例如: -1 % 3 = (-1 % 3 + 3) % 3 = 2
【算法思路】
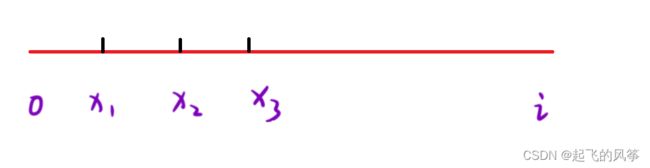
设 i 为数组中的任意位置,⽤ sum[i] 表⽰ [0, i] 区间内所有元素的和。
1、 想知道有多少个「以 i 为结尾的可被 k 整除的⼦数组」,就要找到有多少个起始位置为 x1,x2, x3... 使得 [x, i] 区间内的所有元素的和可被 k 整除。
2、设 [0, x - 1] 区间内所有元素之和等于 a , [0, i] 区间内所有元素的和等于 b ,可得
(b - a) % k == 0 。
3、由同余定理可得, [0, x - 1] 区间与 [0, i] 区间内的前缀和同余。于是问题就变成:
- 找到在 [0, i - 1] 区间内,有多少前缀和的余数等于 sum[i] % k 的即可。
我们不⽤真的初始化⼀个前缀和数组,因为我们只关⼼在 i 位置之前,有多少个前缀和等sum[i] - k 。因此,我们仅需⽤⼀个哈希表,⼀边求当前位置的前缀和,⼀边存下之前每⼀种前缀和出现的次数。
【代码展示】
class Solution {
public:
int subarraysDivByK(vector& nums, int k) {
unordered_map tmp;
tmp[0 % k] = 1; // 0 这个数的余数
int sum = 0;
int res = 0;
for(auto x : nums)
{
sum += x; // 算出当前位置的前缀和
int r = (sum % k + k) % k; // 修正后的余数
if(tmp.count(r))
res += tmp[r]; // 统计结果
tmp[r]++;
}
return res;
}
}; 【输出展示】
【性能分析】
时间复杂度:
- 遍历原始数组并计算前缀和:需要遍历原始数组一次,时间复杂度为O(n),其中n表示原始数组的长度。
- 在每个位置更新哈希表并统计结果:对于每个元素,只需要常数时间来计算前缀和、进行哈希表的操作和统计结果。总体时间复杂度为O(n)。
空间复杂度:
- 空间复杂度为O(n),其中n表示原始数组的长度。主要是用于存储前缀和的哈希表。
总结
前缀和算法是一个重要且实用的算法,可以提高问题求解的效率。掌握了前缀和算法的原理和应用,可以在各种问题中灵活运用,提升算法的效率。