自动化测试框架unittest与pytest的区别!
引言
前面文章已经介绍了python单元测试框架,大家平时经常使用的是unittest,因为它比较基础,并且可以进行二次开发,如果你的开发水平很高,集成开发自动化测试平台也是可以的。而这篇文章主要讲unittest与pytest的区别,pytest相对unittest而言,代码简洁,使用便捷灵活,并且插件很丰富。
Unittest vs Pytest
主要从用例编写规则、用例的前置和后置、参数化、断言、用例执行、失败重运行和报告这几个方面比较unittest和pytest的区别:
用例编写规则
用例前置与后置条件
 断言
断言

测试报告
 失败重跑机制
失败重跑机制

参数化
 用例分类执行
用例分类执行

如果不好看,可以看下面表格:

总体来说,unittest用例格式复杂,兼容性无,插件少,二次开发方便。pytest更加方便快捷,用例格式简单,可以执行unittest风格的测试用例,无须修改unittest用例的任何代码,有较好的兼容性。pytest插件丰富,比如flask插件,可用于用例出错重跑,还有xdist插件,可用于设备并行执行,效率更高。
实例演示
讲了七大区别,总要演示一下具体实例,用事实说话。
前后置区别
这里抽用例前置与后置的区别来讲,先看unittest的前后置使用:
import unittest
class TestFixtures01(unittest.TestCase):
# 所有用例执行前执行
def setUp(self) -> None:
print("setUp开始")
def tearDown(self) -> None:
print("tearDown结束")
# 每条用例执行前执行
@classmethod
def setUpClass(cls) -> None:
print("setUpClass开始")
@classmethod
def tearDownClass(cls) -> None:
print("tearDownClass结束")
# 测试用例
def test_001(self):
print("测试用例001")
class TestFixtures02(unittest.TestCase):
def test_002(self):
print("测试类2")
# 每个模块执行前执行
def setUpModule():
"""
在所有测试类在调用之前会被执行一次,函数名是固定写法,会被unittest框架自动识别
"""
print('集成测试 >>>>>>>>>>>>>>开始')
def tearDownModule():
print("集成测试 >>>>>>>>>>>>>>结束")
if __name__ == '__main__':
unittest.main()
运行结果:
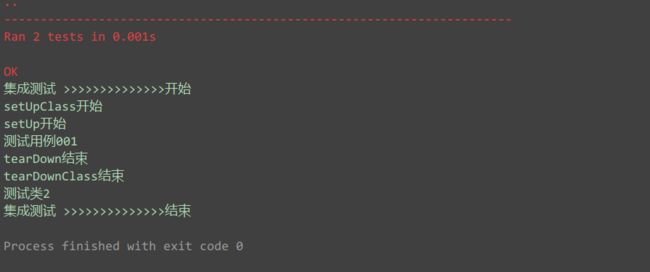
从结果上得知, 三个方法的逻辑优先级: setUp()&tearDown() < setUpClass()&tearDownClass() < setUpModule()&tearDownModule()
接下来看pytest的前后置:
1、我们都知道在自动化测试中都会用到前后置,pytest 相比 unittest 无论是前后置还是插件等都灵活了许多,还能自己用 fixture 来定义。
首先了解一下,用例运行前后置级别如下:
1.模块级:全局的,整个模块开只运行一次,优先于测试用例。
2.类级别:定义在类里面,只针对此类生效。类似unittest的cls装饰器
3.函数级:只对函数生效,类下面的函数不生效。
4.方法级:定义在类里面,每个用例都执行一次
def setup_module():
print('\n整个模块 前 只运行一次')
def teardown_module():
print('\n整个模块 后 只运行一次')
def setup_function():
print('\n不在类中的函数,每个用例 前 只运行一次')
def teardown_function():
print('\n不在类中的函数,每个用例 后 只运行一次')
def test_ab():
b = 2
assert b < 3
def test_aba():
b = 2
assert b < 3
class Test_api():
def setup_class(self):
print('\n此类用例 前 只执行一次')
def teardown_class(self):
print('\n此类用例 后 只执行一次')
def setup_method(self):
print('\n此类每个用例 前 只执行一次')
def teardown_method(self):
print('\n此类每个用例 后 执行一次')
def test_aa(self):
a = 1
print('\n我是用例:a') # pytest -s 显示打印内容
assert a > 0
def test_b(self):
b = 2
assert b < 3
运行结果:

2、这是原始用法,下面看使用Fixture,Fixture 其实就是自定义 pytest 执行用例前置和后置操作,首先创建 conftest.py 文件 (规定此命名),导入 pytest 模块,运用 pytest.fixture 装饰器,默认级别为:函数级:

其它用例文件调用即可,如下定义一个函数,继承 conftest.py 文件里的 login 函数即可调用:
# conftest.py配置需要注意以下点:
# conftest.py配置脚本名称是固定的,不能改名称
# conftest.py与运行的用例要在同一个pakage下,并且有__init__.py文件
# 不需要import导入 conftest.py,pytest用例会自动查找
import pytest
def test_one(login):
print("登陆后,操作111")
# def test_two():
# print("操作222")
#
# def test_three(login):
# print("登陆后,操作333")运行结果:

3、扩展用法,多个自定义函数和全局级别展示:(全局的比如用于登录获取到token其他用例模块就不需要再登录了)
import pytest
def test_one(login):
print("登陆后,操作111")
def test_two(login,open_page):
print("测试用例2")
def test_three(open_page):
print("测试用例3")运行结果:

细心的人应该可以知道,测试用例2并没有调用login函数,因为前置设置的是共享模式,类似全局函数。
参数化区别
参数化应用场景,一个场景的用例会用到多条数据来进行验证,比如登录功能会用到正确的用户名、密码登录,错误的用户名、正确的密码,正确的用户名、错误的密码等等来进行测试,这时就可以用到框架中的参数化,来便捷的完成测试。
参数化 就是数据驱动思想,即可以在一个测试用例中进行多组的数据测试,而且每一组数据都是分开的、独立的。
unittest参数化其实是:ddt,叫数据驱动。
pytest数据驱动,就是参数化,使用@pytest.mark.parametrize
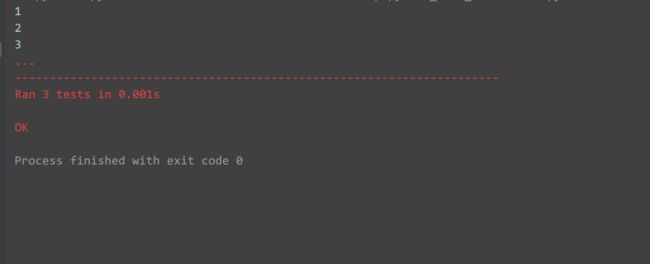
1.先看unittest如何进行参数化:
test_data = [1,2,3]
@ddt.ddt
class Testddt(unittest.TestCase):
@ddt.data(*test_data)
def test_001(self,get_data):
print(get_data)
if __name__ == '__main__':
unittest.main()运行结果:
2.pytest中参数化的用法
在测试用例的前面加上:
@pytest.mark.parametrize("参数名",列表数据)
参数名:用来接收每一项数据,并作为测试用例的参数。
列表数据:一组测试数据。
@pytest.mark.parametrize("参数1,参数2",[(数据1,数据2),(数据1,数据2)])
示例:
@pytest.mark.parametrize("a,b,c",[(1,3,4),(10,35,45),(22.22,22.22,44.44)])
def test_add(a,b,c):
res = a + b
assert res == c
实例:
@pytest.mark.parametrize('data',[1,2,3])
class Testddt(object):
def test_001(self,data):
print(data)
if __name__ == '__main__':
pytest.main(['-sv'])运行结果:

下面是配套学习资料,对于做【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!