一个未公开的容器逃逸方式
一个未公开的容器逃逸方式
作者:Nitro@360GearTeam
背景
最近发现了一个尚未公开的容器逃逸方法,当一个容器共享宿主机 PID namespace、且以 uid 为 0 运行(没有启用 user namespace、没有添加任何额外的 capabilities)时,可以利用某些进程的 /proc/[pid]/root 符号链接实现容器逃逸。
分析
/proc/[pid]/root 介绍
根据 proc(5) 手册,通过 /proc/[pid]/root 符号链接,可以访问任意进程的 rootfs,无论当前进程和目标进程是否属于同一 mount namespace。接着在手册中找到了一段关于访问 /proc/[pid]/root 符号链接时权限问题的描述:
Permission to dereference or read (readlink(2)) this
symbolic link is governed by a ptrace access mode
PTRACE_MODE_READ_FSCREDS check; see ptrace(2).
也就是说要访问这个符号链接,需要经过 ptrace(2) 相关的权限检查。其实这个描述挺模糊的,为什么访问一个符号链接需要检查与 ptrace 系统调用相关的权限呢?
通过查看 ptrace(2) 手册并找到与 PTRACE_MODE_READ_FSCREDS 标志位相关的部分:
Ptrace access mode checking
Various parts of the kernel-user-space API (not just ptrace()
operations), require so-called "ptrace access mode" checks, whose
outcome determines whether an operation is permitted (or, in a
few cases, causes a "read" operation to return sanitized data).
These checks are performed in cases where one process can inspect
sensitive information about, or in some cases modify the state
of, another process. The checks are based on factors such as the
credentials and capabilities of the two processes, whether or not
the "target" process is dumpable, and the results of checks
performed by any enabled Linux Security Module (LSM)—for example,
SELinux, Yama, or Smack—and by the commoncap LSM (which is always
invoked).
Prior to Linux 2.6.27, all access checks were of a single type.
Since Linux 2.6.27, two access mode levels are distinguished:
PTRACE_MODE_READ
For "read" operations or other operations that are less
dangerous, such as: get_robust_list(2); kcmp(2); reading
/proc/[pid]/auxv, /proc/[pid]/environ, or
/proc/[pid]/stat; or readlink(2) of a /proc/[pid]/ns/*
file.
PTRACE_MODE_ATTACH
For "write" operations, or other operations that are more
dangerous, such as: ptrace attaching (PTRACE_ATTACH) to
another process or calling process_vm_writev(2).
(PTRACE_MODE_ATTACH was effectively the default before
Linux 2.6.27.)
Since Linux 4.5, the above access mode checks are combined (ORed)
with one of the following modifiers:
PTRACE_MODE_FSCREDS
Use the caller's filesystem UID and GID (see
credentials(7)) or effective capabilities for LSM checks.
PTRACE_MODE_REALCREDS
Use the caller's real UID and GID or permitted
capabilities for LSM checks. This was effectively the
default before Linux 4.5.
Because combining one of the credential modifiers with one of the
aforementioned access modes is typical, some macros are defined
in the kernel sources for the combinations:
PTRACE_MODE_READ_FSCREDS
Defined as PTRACE_MODE_READ | PTRACE_MODE_FSCREDS.
PTRACE_MODE_READ_REALCREDS
Defined as PTRACE_MODE_READ | PTRACE_MODE_REALCREDS.
PTRACE_MODE_ATTACH_FSCREDS
Defined as PTRACE_MODE_ATTACH | PTRACE_MODE_FSCREDS.
PTRACE_MODE_ATTACH_REALCREDS
Defined as PTRACE_MODE_ATTACH | PTRACE_MODE_REALCREDS.
看到这段描述之后就明白了为什么访问 /proc/[pid]/root 符号链接需要经过 ptrace(2) 相关的权限检查,因为通过 /proc/[pid]/root 符号链接访问目标进程 rootfs 的这个操作类似于通过 ptrace 系统调用跟踪一个进程,都是一个进程访问另一个进程的数据。
PTRACE_MODE_READ_FSCREDS 标志位是 PTRACE_MODE_READ 和 PTRACE_MODE_FSCREDS 两个标志位的结合,因此调用进程需要拥有足够的文件系统权限或者 capabilities 才能够通过 /proc/[pid]/root 符号链接访问目标进程的 rootfs。
**那内核具体是怎样进行权限检查的呢?**解答这个问题需要分析相关的内核源码了。
相关的函数调用关系图如下:

proc 文件系统中大多数文件的实现都在 /fs/proc/base.c 文件中。当访问一个符号链接时,内核会通过符号链接文件 inode 中的 .get_link 方法拿到对应的实际路径。对于 /proc/[pid]/root 来说,其使用的 .get_link 方法为 proc_pid_get_link() 函数。
proc_pid_get_link() 函数中会调用同文件中的 proc_fd_access_allowed() 函数来检查调用进程是否拥有足够权限。
proc_fd_access_allowed() 函数通过符号链接的 inode 拿到目标进程的 task_struct 实例,接着调用 ptrace_may_access() 函数检查权限。调用该函数时第二个参数的值为 PTRACE_MODE_READ_FSCREDS。
ptrace_may_access() 函数定义在 /kernel/ptrace.c 文件中,实际工作委托给 __ptrace_may_access() 函数:
/* Returns 0 on success, -errno on denial. */
static int __ptrace_may_access(struct task_struct *task, unsigned int mode)
{
const struct cred *cred = current_cred(), *tcred;
struct mm_struct *mm;
kuid_t caller_uid;
kgid_t caller_gid;
if (!(mode & PTRACE_MODE_FSCREDS) == !(mode & PTRACE_MODE_REALCREDS)) {
WARN(1, "denying ptrace access check without PTRACE_MODE_*CREDS\n");
return -EPERM;
}
/* May we inspect the given task?
* This check is used both for attaching with ptrace
* and for allowing access to sensitive information in /proc.
*
* ptrace_attach denies several cases that /proc allows
* because setting up the necessary parent/child relationship
* or halting the specified task is impossible.
*/
/* Don't let security modules deny introspection */
if (same_thread_group(task, current))
return 0;
rcu_read_lock();
if (mode & PTRACE_MODE_FSCREDS) {
caller_uid = cred->fsuid;
caller_gid = cred->fsgid;
} else {
/*
* Using the euid would make more sense here, but something
* in userland might rely on the old behavior, and this
* shouldn't be a security problem since
* PTRACE_MODE_REALCREDS implies that the caller explicitly
* used a syscall that requests access to another process
* (and not a filesystem syscall to procfs).
*/
caller_uid = cred->uid;
caller_gid = cred->gid;
}
tcred = __task_cred(task);
if (uid_eq(caller_uid, tcred->euid) &&
uid_eq(caller_uid, tcred->suid) &&
uid_eq(caller_uid, tcred->uid) &&
gid_eq(caller_gid, tcred->egid) &&
gid_eq(caller_gid, tcred->sgid) &&
gid_eq(caller_gid, tcred->gid))
goto ok;
if (ptrace_has_cap(tcred->user_ns, mode))
goto ok;
rcu_read_unlock();
return -EPERM;
ok:
rcu_read_unlock();
/*
* If a task drops privileges and becomes nondumpable (through a syscall
* like setresuid()) while we are trying to access it, we must ensure
* that the dumpability is read after the credentials; otherwise,
* we may be able to attach to a task that we shouldn't be able to
* attach to (as if the task had dropped privileges without becoming
* nondumpable).
* Pairs with a write barrier in commit_creds().
*/
smp_rmb();
mm = task->mm;
if (mm &&
((get_dumpable(mm) != SUID_DUMP_USER) &&
!ptrace_has_cap(mm->user_ns, mode)))
return -EPERM;
return security_ptrace_access_check(task, mode);
}
可以看到,如果当前进程和目标进程处于同一线程组,是完全有权限的。
接着,因为 mode 的值包含 PTRACE_MODE_FSCREDS 标志位,所以首先检查调用进程的 fsuid 和 fsgid 是否与目标进程的 fsuid 和 fsgid 一致。如果不一致,则调用 ptrace_has_cap() 函数检查调用进程在目标进程的 user namespace 中是否拥有 CAP_SYS_PTRACE 权限,如果没有的话拒绝访问。
接着,当目标进程被设置为 nondumpable 且调用进程在目标进程的 user namespace 中没有 CAP_SYS_PTRACE 权限时,拒绝访问。
最后调用 security_ptrace_access_check() 函数执行最终检查。这个函数与 LSM 有关,这里只关注 commcap 的实现,不关注其它诸如 Yama、AppArmor 等的实现。
对于 commcap,security_ptrace_access_check() 最终调用的是 /security/commcap.c 文件中的 cap_ptrace_access_check() 函数:
/**
* cap_ptrace_access_check - Determine whether the current process may access
* another
* @child: The process to be accessed
* @mode: The mode of attachment.
*
* If we are in the same or an ancestor user_ns and have all the target
* task's capabilities, then ptrace access is allowed.
* If we have the ptrace capability to the target user_ns, then ptrace
* access is allowed.
* Else denied.
*
* Determine whether a process may access another, returning 0 if permission
* granted, -ve if denied.
*/
int cap_ptrace_access_check(struct task_struct *child, unsigned int mode)
{
int ret = 0;
const struct cred *cred, *child_cred;
const kernel_cap_t *caller_caps;
rcu_read_lock();
cred = current_cred();
child_cred = __task_cred(child);
if (mode & PTRACE_MODE_FSCREDS)
caller_caps = &cred->cap_effective;
else
caller_caps = &cred->cap_permitted;
if (cred->user_ns == child_cred->user_ns &&
cap_issubset(child_cred->cap_permitted, *caller_caps))
goto out;
if (ns_capable(child_cred->user_ns, CAP_SYS_PTRACE))
goto out;
ret = -EPERM;
out:
rcu_read_unlock();
return ret;
}
首先根据 mode 是否设置了 PTRACE_MODE_FSCREDS 标志位来决定使用有效能力集(effective capability set)还是许可能力集(permitted capability set)执行权限检查。接着如果调用进程和目标进程属于同一 user namespace,且目标进程的许可能力集是调用进程能力集的子集,那么调用进程通过权限检查。否则接着检查调用进程在目标进程所在的 user namespace 中是否拥有 CAP_SYS_PTRACE 能力,有则通过权限检查,没有则拒绝访问。
到这里我们已经可以解答文章开头提出的问题了,即在默认配置下,所有容器进程拥有相同的能力集,所以这个共享了宿主机 PID namespace 的容器能够访问其它容器进程的 rootfs。访问不了宿主机上以非 root 用户运行的进程的 rootfs,是因为调用进程的 fsuid、fsgid 分别与目标进程的 euid、suid、uid、egid、sgid、gid 不匹配。访问不了宿主机上以 root 用户运行的进程的 rootfs,是因为宿主机上以 root 用户运行的进程拥有所有的能力,其能力集不是调用进程的能力集的子集。
最后总结如下:
- 如果调用进程和目标进程属于同一个进程组,则允许访问。
- 如果访问模式中指定了
PTRACE_MODE_FSCREDS标志位,那么在接下来的文件系统权限检查中将使用调用进程的 filesystem UID(fsuid)和 filesystem GID(fsgid)。如果访问模式中指定了PTRACE_MODE_REALCREDS标志位,那么在接下来的文件系统权限检查中将使用调用进程的 real UID(uid)和 real GID(gid)。 - 如果不能满足以下任意一个条件,那么拒绝访问:
- 调用进程的 fsuid、fsgid 分别与目标进程的 euid、suid、uid、egid、sgid、gid 匹配。
- 调用进程在目标进程的 user namespace 中拥有
CAP_SYS_PTRACE能力。
- 如果目标进程被设置为 nondumpable,且调用进程在目标进程的 user namespace 中没有
CAP_SYS_PTRACE能力,那么拒绝访问。 - 如果不能满足以下任意一个条件,那么内核的 commcap LSM 模块会拒绝访问:
- 调用进程和目标进程属于同一个 user namespace,且调用进程的能力集是目标进程的许可能力集的超集。
- 调用进程在目标进程所在的 user namespace 中拥有
CAP_SYS_PTRACE能力。
利用思路
从上面的研究中,我们可以总结出一个容器逃逸的新思路。
根据上面的研究,这种情况下容器访问不了宿主机上以非 root 用户运行的进程的 rootfs 的原因是,容器进程的 fsuid、fsgid 分别与目标进程的 euid、suid、uid 和 egid、sgid、gid 不匹配。那么怎么才能让它们匹配呢?其实很简单,找到宿主机上以非 root 用户运行的进程后,我们在容器中创建一个 UID 和 GID 与目标进程 UID 和 GID 相同的用户,然后用 su 命令切换到该用户,就有权限访问目标进程的 /proc/[pid]/root 了。当然需要注意目标进程必须是 dumpable 的。
下面的示例中,首先创建一个共享宿主机 PID namespace 的 Pod,然后在宿主机中以普通用户运行命令 sleep 36000,最后在 Pod 中可通过此进程访问到宿主机文件系统:
同时在容器中可以通过创建并加入辅助组的概念扩大访问权限。下面的例子将当前用户加入 docker 组中,从而在容器中访问宿主机的 Docker 引擎,进而实现容器逃逸。
示例中首先通过 Docker 启动一个共享宿主机 PID namespace 的容器,接着通过 ps 命令找到宿主机普通用户的 uid 和 gid,并在容器中创建相应用户。然后通过任意普通进程的 /proc/[pid]/root 访问宿主机目录 /run,发现用于和 Docker 引擎通信的 socket 文件 /run/docker.sock 允许属于 gid 为 969 的用户访问。接着在容器中创建 gid 为 969 的组,并将前述创建的用户加入到这个组中。最后安装 Docker 客户端即可访问宿主机的 Docker 引擎。

NOTE:当容器共享了宿主机 PID namespace 时,也拥有 CAP_SYS_PTRACE 能力,通过 /proc/[pid]/root 符号链接可以更容易实现逃逸。
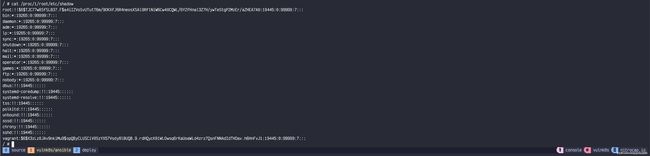
下面的示例中首先在集群中创建了一个共享宿主机 PID namespace 且添加了 CAP_SYS_PTRACE 能力的 Pod,
然后在 Pod 中通过 /proc/1/root 即可访问到宿主机文件系统。

防御和检测
从安全加固的角度来说,为了避免上述问题,在 Kubernetes 集群中需要做到:
- 容器应以非 root 用户运行。
- 禁止随意共享宿主机 PID namespace。
- 禁止随意授予容器
CAP_SYS_PTRACE权限。
至于检测方法,可以考虑在运行时实时威胁检测系统中监控容器内以 /proc/ 作为路径前缀的文件访问操作。
参考资料
- https://man7.org/linux/man-pages/man2/ptrace.2.html
- https://man7.org/linux/man-pages/man5/proc.5.html
rnetes 集群中需要做到:
- 容器应以非 root 用户运行。
- 禁止随意共享宿主机 PID namespace。
- 禁止随意授予容器
CAP_SYS_PTRACE权限。
至于检测方法,可以考虑在运行时实时威胁检测系统中监控容器内以 /proc/ 作为路径前缀的文件访问操作。
参考资料
- https://man7.org/linux/man-pages/man2/ptrace.2.html
- https://man7.org/linux/man-pages/man5/proc.5.html
原文链接:https://www.anquanke.com/post/id/290540