【MLC】 TensorIR 练习
文章目录
-
- 前言
- TensorIR 练习
-
- TensorIR: 张量程序抽象案例研究
- 练习 1:广播加法
- 练习 2:二维卷积
- 练习 3:变换批量矩阵乘法程序
- 总结
前言
- 这两天重新看了一下天奇的mlc课程文档,把里边儿的TensorIR 练习写了一下,顺便推广一下相关资料
- MLC-机器学习编译-B站,MLC-文档
- bbuf老哥-B站
- Archer哥的二三事
- 有关于TVM其实我是跟着二三事入门的,然而当前TVM学习的难点不在于资料不够而是不够集成,初学者往往面出现对一堆资料无从下手的情况,此时需要有人指出一条学习路线,才能更好地利用把把散落在各地的资料解决学习途中的困惑,二三事就是这么个路子,从前端讲到后端,由浅入深,结合其他资料以及GPT(读代码很方便),往往快速理解TVM各个阶段的操作与设计。
- 话说回来MLC这门课程是讲AI编译原理,个人认为最大的优点是用python作为示例demo(文档比较完善,代码可以直接跑),加上天奇讲的很清楚,所以很适合作为入门。
- bbuf是宝藏,dddd~
TensorIR 练习
- 2.5. TensorIR 练习
- 练习文档如上所示,在练习前建议复习一下2.4 TensorIR: 张量程序抽象案例研究,下面内容简单分为两部分,首先会简单总结2.4的例子,然后会贴上2.5的过程,结合实现回忆做一个记录。
TensorIR: 张量程序抽象案例研究
- 2.4用的例子是一个matmul后边接一个relu这么个小计算图,首先会给出ir_module的代码,然后对其中用到的语法进行解释,这玩意主要是构造了一个计算的过程,表示C = Relu(A*B)。
import tvm from tvm.ir.module import IRModule from tvm.script import tir as T @tvm.script.ir_module class MyModule: @T.prim_func def mm_relu(A: T.Buffer((128, 128), "float32"), B: T.Buffer((128, 128), "float32"), C: T.Buffer((128, 128), "float32")): T.func_attr({"global_symbol": "mm_relu", "tir.noalias": True}) Y = T.alloc_buffer((128, 128), dtype="float32") for i, j, k in T.grid(128, 128, 128): with T.block("Y"): vi = T.axis.spatial(128, i) vj = T.axis.spatial(128, j) vk = T.axis.reduce(128, k) with T.init(): Y[vi, vj] = T.float32(0) Y[vi, vj] = Y[vi, vj] + A[vi, vk] * B[vk, vj] for i, j in T.grid(128, 128): with T.block("C"): vi = T.axis.spatial(128, i) vj = T.axis.spatial(128, j) C[vi, vj] = T.max(Y[vi, vj], T.float32(0)) def transform(mod, jfactor): sch = tvm.tir.Schedule(mod) block_Y = sch.get_block("Y", func_name="mm_relu") i, j, k = sch.get_loops(block_Y) j0, j1 = sch.split(j, factors=[None, jfactor]) sch.reorder(j0, k, j1) block_C = sch.get_block("C", "mm_relu") sch.reverse_compute_at(block_C, j0) return sch.mod mod_transformed = transform(MyModule, jfactor=12) rt_lib_transformed = tvm.build(mod_transformed, "llvm") f_timer = rt_lib.time_evaluator("mm_relu", tvm.cpu()) f_timer_transformed = rt_lib_transformed.time_evaluator("mm_relu", tvm.cpu()) print("Time cost of mod %g sec" % f_timer(a_nd, b_nd, c_nd).mean) print("Time cost of transformed mod_transformed %g sec" % f_timer_transformed(a_nd, b_nd, c_nd).mean) # display the code below # print(IPython.display.Code(mod_transformed.script(), language="python")) - 如何写一个T.prim_func(函数可用链接定位到源码):
- 参数里边儿定义了输入输出,类型是T.Buffer,可以用T.alloc_buffer申请
- T.func_attr作用是PrimFuncFrame属性的赋值
- T.grid,是一个构造多重循环(跟多用几个range一个效果)的语法糖
- T.block,构造了一个BlockFrame,可以用get_block拿到,继续往下探索可以发现一个设计:
class ConcreteScheduleNode : public ScheduleNode { friend class Schedule; friend class ScheduleCopier; ...... BlockRV GetBlock(const String& name, const Optional<String>& func_name) override; ...... };- 关于这个东西问了下GPT,得到的解答是:对外提供给用户的主要是通过Schedule类来操作和访问调度信息。Schedule类封装了ScheduleNode中的成员函数,并提供了更高级别的接口,使用户能够方便地进行调度和优化操作。
- 类似的设计在TVM中很常见,挖个坑。
- T.axis.remap也是个比较好用的语法糖,可以快速绑定块轴,轴类型有spatial,reduce代表空间轴和归约轴,理解为有在输出对应的轴是空间轴,没有对应的,会被归约减少的轴是归约轴
-
vi = T.axis.spatial(128, i) vj = T.axis.spatial(128, j) vk = T.axis.reduce(128, k) # 等价于 # SSR means the properties of each axes are "spatial", "spatial", "reduce" # 计算块在 Y 的空间位置 (Y[vi, vj]) 处生成一个点值,该点值独立于 Y 中的其他位置(具有不同的vi, vj 值的位置)。我们可以称 vi、vj 为空间轴,因为它们直接对应于块写入的缓冲区空间区域的开始。 涉及归约的轴(vk)被命名为归约轴。 vi, vj, vk = T.axis.remap("SSR", [i, j, k])
- 至此,一个T.prim_func就可以写出来了,transform可以看这个:python/tvm/tir/schedule/schedule.py
练习 1:广播加法
- 题目:请编写一个 TensorIR 函数,将两个数组以广播的方式相加。
- 练习1就是练一个加法,这很简单(仅仅针对用例的输入来说)
- 首先用numpy写个模拟版本,lnumpy_tadd,然而我在调用numpy本身方法的时候发现这个东西其实满足交换律,按道理也应该满足最后一维相等这类的条件,但这里不是很清楚TVM中如何判断这种情况(挖坑+1),于是干脆在后边就先不考虑这个了,直接按照输入先写。
- 然后是T.prim_func,用了T.grid和T.axis.remap这种语法糖(见上文)三两行就表示完了
from tvm.script import tir as T import tvm import numpy as np # 广播加法 # init data a = np.arange(16).reshape(-1, 4) b = np.arange(4, 0, -1).reshape(4) # numpy version c_np = a + b c_np2 = b + a print(c_np) print(c_np2) def lnumpy_tadd(A:np.ndarray, B:np.ndarray, C:np.ndarray): # 需要保证A是(x, y)或者(y) B是(1, y)或者(y)的shape才行 # assert AB的合法性 # 最后一维是相等的,有一个数必须是维度 assert A.shape[-1] == B.shape[-1], "shape err!" assert A.shape == C.shape, "shape err!" B = B.reshape(B.shape[-1]) for i in range(A.shape[0]): for j in range(B.shape[-1]): C[i][j] = A[i][j] + B[j] lnumpy_tadd_c = np.empty_like(a) lnumpy_tadd(a, b, lnumpy_tadd_c) print(lnumpy_tadd_c) @tvm.script.ir_module class MyAdd: @T.prim_func def add(A: T.Buffer((4, 4), "int64"), B: T.Buffer((4), "int64"), C: T.Buffer((4, 4), "int64") ): T.func_attr({"global_symbol": "add", "tir.noalias": True}) # TODO for i, j in T.grid(4, 4): with T.block("C"): vi, vj = T.axis.remap("SS", [i,j]) C[vi, vj] = A[vi, vj] + B[vj] rt_lib = tvm.build(MyAdd, target="llvm") a_tvm = tvm.nd.array(a) b_tvm = tvm.nd.array(b) c_tvm = tvm.nd.array(np.empty((4, 4), dtype=np.int64)) rt_lib["add"](a_tvm, b_tvm, c_tvm) np.testing.assert_allclose(c_tvm.numpy(), c_np, rtol=1e-5)
练习 2:二维卷积
- 题目:

- 对于卷积计算想必都或多或少有些了解,常用的实现是im2col+gemm,其中gemm可以被tvm中的调度优化替代,因此主要实现im2col和col2im基本就好了(当然本题可以用原始定义写,我想作者原意可能也是用定义写,不过anyway,都一样)
- 这份代码顺便复习了一下卷积的实现,缺点就是代码通用性不够,还是偷懒了
# torch version import torch import numpy as np from tvm.script import tir as T import tvm N, CI, H, W, CO, K = 1, 1, 8, 8, 2, 3 OUT_H, OUT_W = H - K + 1, W - K + 1 data = np.arange(N*CI*H*W).reshape(N, CI, H, W) weight = np.arange(CO*CI*K*K).reshape(CO, CI, K, K) data_torch = torch.Tensor(data) weight_torch = torch.Tensor(weight) conv_torch = torch.nn.functional.conv2d(data_torch, weight_torch) conv_torch = conv_torch.numpy().astype(np.int64) print(conv_torch) print(data.shape) print(weight.shape) print(conv_torch.shape) @tvm.script.ir_module class MyConv: @T.prim_func def conv(data:T.buffer((1, 1, 8, 8), "int64"), weight:T.buffer((2, 1, 3, 3), "int64"), output:T.buffer((1, 2, 6, 6), "int64")): T.func_attr({"global_symbol": "conv", "tir.noalias": True}) # TODO mat_w = T.alloc_buffer((2, 9), "int64") # (8 - 3)/1 + 1 = 6 mat_d = T.alloc_buffer((1, 6*6, 9), "int64") mat_o = T.alloc_buffer((1, 36, 2), "int64") # data_im2col: for i, sx, sy, c, w, h in T.grid(1, 6, 6, 1, 3, 3): with T.block("d_im2col"): vi, vx, vy, vc, vw, vh = T.axis.remap("SSSSSS", [i, sx, sy, c, w, h]) with T.init(): mat_d[vi, vx*6+vy, vc*3*3 + vw*3 + vh] = T.int64(0) mat_d[vi, vx*6+vy, vc*3*3 + vw*3 + vh] = data[vi, vc, vx+vw, vy+vh] # weight_im2col for i, j, w, h in T.grid(2, 1, 3, 3): with T.block("w_im2col"): vi, vj, vw, vh = T.axis.remap("SSSS", [i, j, w, h]) with T.init(): mat_w[vi, vj*3*3 + w*3 + h] = T.int64(0) mat_w[vi, vj*3*3 + w*3 + h] = weight[vi, vj, vw, vh] # matmul for b, h, i, j in T.grid(1, 36, 2, 9): with T.block("matmul"): vb, vh, vi, vj = T.axis.remap("SSSR", [b, h, i, j]) with T.init(): mat_o[vb, vh, vi] = T.int64(0) mat_o[vb, vh, vi] = mat_o[vb, vh, vi] + mat_d[vb, vh, vj] * mat_w[vi, vj] # col2img: for b, c, w, h in T.grid(1, 2, 6, 6): with T.block("col2img"): vb, vc, vw, vh = T.axis.remap("SSSS", [b, c, w, h]) output[vb, vc, vw, vh] = mat_o[vb, vw*6+vh, vc] rt_lib = tvm.build(MyConv, target="llvm") data_tvm = tvm.nd.array(data) weight_tvm = tvm.nd.array(weight) conv_tvm = tvm.nd.array(np.empty((N, CO, OUT_H, OUT_W), dtype=np.int64)) rt_lib["conv"](data_tvm, weight_tvm, conv_tvm) np.testing.assert_allclose(conv_tvm.numpy(), conv_torch, rtol=1e-5) print(conv_tvm) f_timer = rt_lib.time_evaluator("conv", tvm.cpu()) print("Time cost of conv %g sec" % f_timer(data_tvm, weight_tvm, conv_tvm).mean)
练习 3:变换批量矩阵乘法程序
-
题目

-
我们回到mm_relu,这次需要实现的是bmm_relu,是多batch版的mm_relu,这很简单,多加一个轴就行
import numpy as np import tvm from tvm.ir.module import IRModule from tvm.script import tir as T import IPython dtype = "float32" @tvm.script.ir_module class MyBmmRelu: @T.prim_func def bmm_relu( A: T.Buffer((16, 128, 128), dtype), B: T.Buffer((16, 128, 128), dtype), C: T.Buffer((16, 128, 128), dtype), ): # 这里的 global_symbol 对应函数名,tir.noalias 是一个属性,表示所有的缓冲存储器不重叠。 T.func_attr({"global_symbol": "bmm_relu", "tir.noalias": True}) Y = T.alloc_buffer((16, 128, 128), dtype) for n, i, j, k in T.grid(16, 128, 128, 128): with T.block("Y"): # SSR means the properties of each axes are "spatial", "spatial", "reduce" vn, vi, vj, vk = T.axis.remap("SSSR", [n, i, j, k]) with T.init(): Y[vn, vi, vj] = T.float32(0) Y[vn, vi, vj] = Y[vn, vi, vj] + A[vn, vi, vk] * B[vn, vk, vj] for n, i, j in T.grid(16, 128, 128): with T.block("C"): vn, vi, vj = T.axis.remap("SSS", [n, i, j]) C[vn, vi, vj] = T.max(Y[vn, vi, vj], T.float32(0)) -
这份代码出来的程序是这个:
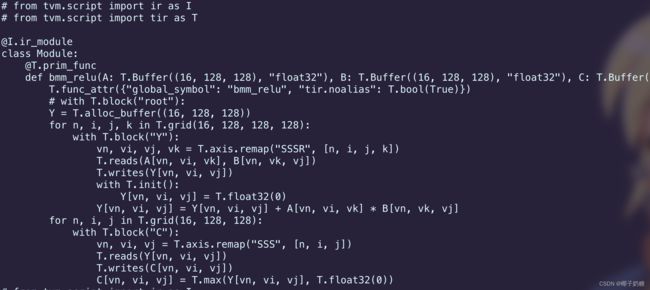
-
我们的目标程序是:
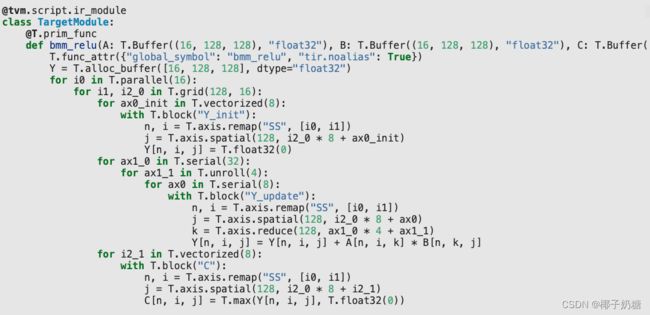
-
分析一下目标程序,原始的块轴是(16, 128, 128, 128),我们需要将第一个batch的16抽出来合并并设置为T.parallel,第二维128的i抽出来合并,第三维128拆分成168,block(“Y”)中的最后一维需要拆分成324,剩下就是一些T.vectorized,T.unroll以及reorder等操作。各种转换方法的说明可以直接看源代码,注释写的很清楚了:python/tvm/tir/schedule/schedule.py
-
于是我的思路是这样的
- 先把两个block中的j轴拆成16*8,然后将拆出来的cj0和j0以外的循环合并成一个循环,并按照target设置vectorize和parallel,
- 接下来就是拆分block Y,目的是吧init拆出来,这用到了sch.decompose_reduction,他会拆分出Y_init和Y_update
- 最后对init部分设置T.vectorized,对update部分拆分32*4,reorder+unroll一下即可得到相似的结果:
def transform(mod): sch = tvm.tir.Schedule(mod) # split j block_Y = sch.get_block("Y", func_name="bmm_relu") n, i, j, k = sch.get_loops(block_Y) j0, j1 = sch.split(j, factors=[None, 8]) block_C = sch.get_block("C", func_name="bmm_relu") cn, ci, cj = sch.get_loops(block_C) cj0, cj1 = sch.split(cj, factors=[None, 8]) # compute_at cj0 && vectorize cj1 sch.compute_at(block_Y, cj0, preserve_unit_loops=False) sch.vectorize(cj1) # parallel n block_Y = sch.get_block("Y", func_name="bmm_relu") n, i, j0, j1, k = sch.get_loops(block_Y) sch.parallel(n) # # split Y_init Y_update sch.decompose_reduction(block_Y, j1) block_Y_init = sch.get_block("Y_init", func_name="bmm_relu") n, i, j_0, ax0_init = sch.get_loops(block_Y_init) sch.vectorize(ax0_init) block_Y_update = sch.get_block("Y_update", func_name="bmm_relu") n, i, j0, jax0, jax1 = sch.get_loops(block_Y_update) ax1_0, ax1_1 = sch.split(jax1, factors=[None, 4]) sch.reorder(ax1_0, ax1_1, jax0) sch.unroll(ax1_1) return sch.mod -
转换完之后的程序如下所示,可以看到已经十分接近了:
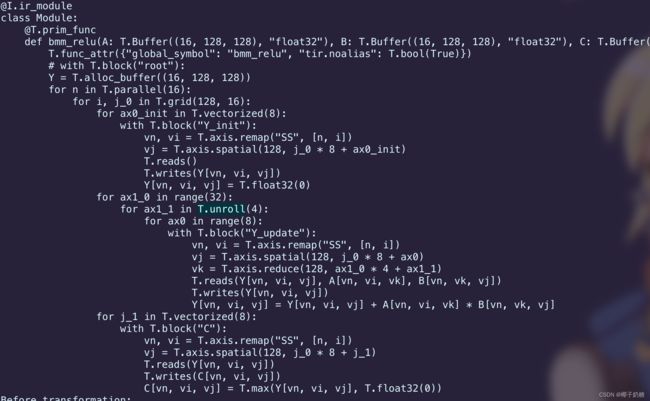
-
最后展示一下优化之后的时间测试,这里并没有尝试更多的优化方法,主要是想把原始程序变为目标程序:
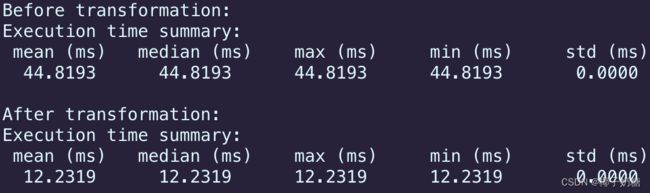
-
贴一下这个作业的完整代码:
import numpy as np import tvm from tvm.ir.module import IRModule from tvm.script import tir as T import IPython dtype = "float32" @tvm.script.ir_module class MyBmmRelu: @T.prim_func def bmm_relu( A: T.Buffer((16, 128, 128), dtype), B: T.Buffer((16, 128, 128), dtype), C: T.Buffer((16, 128, 128), dtype), ): # 这里的 global_symbol 对应函数名,tir.noalias 是一个属性,表示所有的缓冲存储器不重叠。 T.func_attr({"global_symbol": "bmm_relu", "tir.noalias": True}) Y = T.alloc_buffer((16, 128, 128), dtype) for n, i, j, k in T.grid(16, 128, 128, 128): with T.block("Y"): # SSR means the properties of each axes are "spatial", "spatial", "reduce" vn, vi, vj, vk = T.axis.remap("SSSR", [n, i, j, k]) with T.init(): Y[vn, vi, vj] = T.float32(0) Y[vn, vi, vj] = Y[vn, vi, vj] + A[vn, vi, vk] * B[vn, vk, vj] for n, i, j in T.grid(16, 128, 128): with T.block("C"): vn, vi, vj = T.axis.remap("SSS", [n, i, j]) C[vn, vi, vj] = T.max(Y[vn, vi, vj], T.float32(0)) def transform(mod): sch = tvm.tir.Schedule(mod) # split j block_Y = sch.get_block("Y", func_name="bmm_relu") n, i, j, k = sch.get_loops(block_Y) j0, j1 = sch.split(j, factors=[None, 8]) block_C = sch.get_block("C", func_name="bmm_relu") cn, ci, cj = sch.get_loops(block_C) cj0, cj1 = sch.split(cj, factors=[None, 8]) # compute_at j0, vectorize cj1 sch.compute_at(block_Y, cj0, preserve_unit_loops=False) sch.vectorize(cj1) # parallel n block_Y = sch.get_block("Y", func_name="bmm_relu") n, i, j0, j1, k = sch.get_loops(block_Y) sch.parallel(n) # # split Y_init Y_update sch.decompose_reduction(block_Y, j1) block_Y_init = sch.get_block("Y_init", func_name="bmm_relu") n, i, j_0, ax0_init = sch.get_loops(block_Y_init) sch.vectorize(ax0_init) block_Y_update = sch.get_block("Y_update", func_name="bmm_relu") n, i, j0, jax0, jax1 = sch.get_loops(block_Y_update) ax1_0, ax1_1 = sch.split(jax1, factors=[None, 4]) sch.reorder(ax1_0, ax1_1, jax0) sch.unroll(ax1_1) return sch.mod # organize the loops sch = tvm.tir.Schedule(MyBmmRelu) print(IPython.display.Code(sch.mod.script(), language="python")) mod = transform(MyBmmRelu) sch = tvm.tir.Schedule(mod) print(IPython.display.Code(sch.mod.script(), language="python")) # test data a_tvm = tvm.nd.array(np.random.rand(16, 128, 128).astype("float32")) b_tvm = tvm.nd.array(np.random.rand(16, 128, 128).astype("float32")) c_tvm = tvm.nd.array(np.random.rand(16, 128, 128).astype("float32")) # runtime before_rt_lib = tvm.build(MyBmmRelu, target="llvm") after_rt_lib = tvm.build(sch.mod, target="llvm") # after_rt_lib["bmm_relu"](a_tvm, b_tvm, c_tvm) # time_evaluator before_timer = before_rt_lib.time_evaluator("bmm_relu", tvm.cpu()) print("Before transformation:") print(before_timer(a_tvm, b_tvm, c_tvm)) f_timer = after_rt_lib.time_evaluator("bmm_relu", tvm.cpu()) print("After transformation:") print(f_timer(a_tvm, b_tvm, c_tvm))总结
- 练习了一下tir怎么手动构造,以及sch的transform,我个人认为这个玩意实际业务上不会用到,但是得会看(不然你报错都不知道怎么看),所以这个基础练习还是有点必要看看。
- 接下来的计划:
- 1.总结TVM的总体链路
- 2.对比TVM与竞品的区别、优劣势
- 3.分析TVM C++与Python相互调用的机制
- 4.尝试记录Pass的构造过程,如何新增pass
- 5.尝试记录runtime codegen的过程
- 6.分析TVM中的设计模式