Hadoop源码阅读(一):NameNode启动
说明:
1.Hadoop版本:3.1.3
2.阅读工具:IDEA 2023.1.2
3.源码获取:Index of /dist/hadoop/core/hadoop-3.1.3 (apache.org)
4.工程导入:下载源码之后得到hadoop-3.1.3-src.tar.gz压缩包,在当前目录打开PowerShell,使用tar -zxvf指令解压即可,然后使用IDEA打开hadoop-3.1.3-src文件夹,要注意配置好Maven或Gradle仓库,否则jar包导入会比较慢
5.参考课程:尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优,百万播放_哔哩哔哩_bilibili
首先ctrl+n,全局搜索namenode,打开namenode.java文件
然后找到main函数:
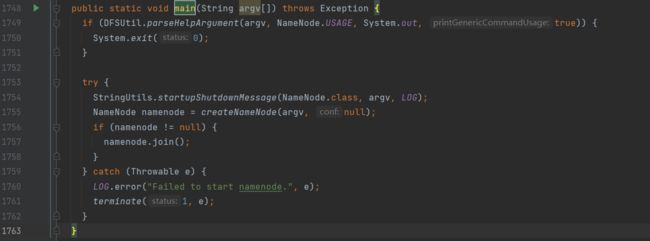
可以看到,try中通过createNameNode方法创建namenode对象:

进入createNameNode方法,可以看到一个switch case语句:

也就是根据不同的启动选项来初始化NameNode
找到default选项,返回了一个NameNode对象:

接下来进入NameNode类中,可以看到try语句中的initialize方法,对namenode进行初始化:

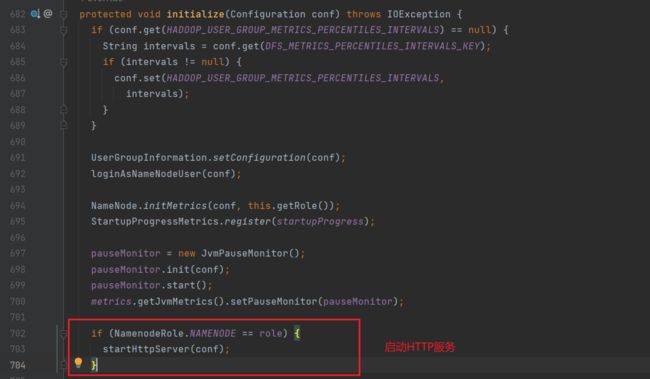
1.启动9870端口服务(startHttpServer)
进入初始化方法,可以看到首先启动了HTTP服务:startHttpServer方法
进入startHttpServer方法,实例化了NameNodeHttpServer对象,其中的参数分别为:
conf:配置信息;this:namenode对象;getHttpServerBindAddress方法:获取HTTP服务的端口号;

接下来进入getHttpServerBindAddress方法,可以看到通过getHttpServerAddress方法获取端口号

进入getHttpServerAddress方法:

进入getHttpAddress方法:

这里的DFS_NAMENODE_HTTP_ADDRESS_DEFAULT即是默认的端口号,通过不断的查找可以看到其值默认为9870:

重新回到startHttpServer方法内部:
绑定端口号完成之后HTTP服务启动:

进入start方法:
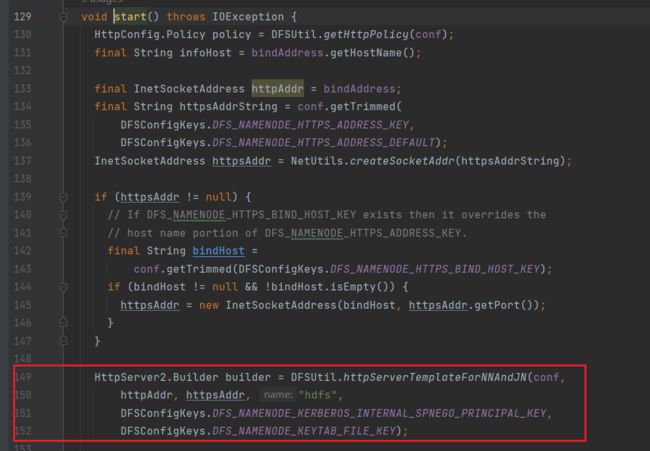
可以看到启动的是HttpServer2服务,这个服务是Hadoop官方封装的HttpServer服务,用于和JDK自带的HttpServer区分开
HttpServer 是 JDK 1.6 以后内置的一个轻量级 HTTP 服务器(在 rt.jar 包中的 com.sun.net.httpserver 包下)
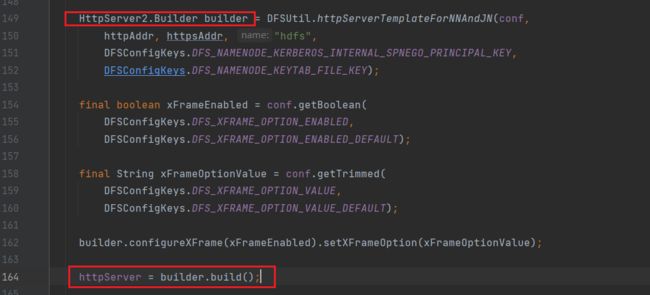
接下来通过builder来实例化httpserver对象
然后在启动之前需要执行setupServlets方法:


用处是绑定多个servlet,即hadoop服务web UI不同页面的路径;
之后即可启动httpserver:

至此NameNode的9870端口服务已经启动了
2.加载镜像文件和编辑日志(loadNamesystem)
回到initialize方法,可以看到启动HttpServer之后,通过loadNamesystem加载镜像文件
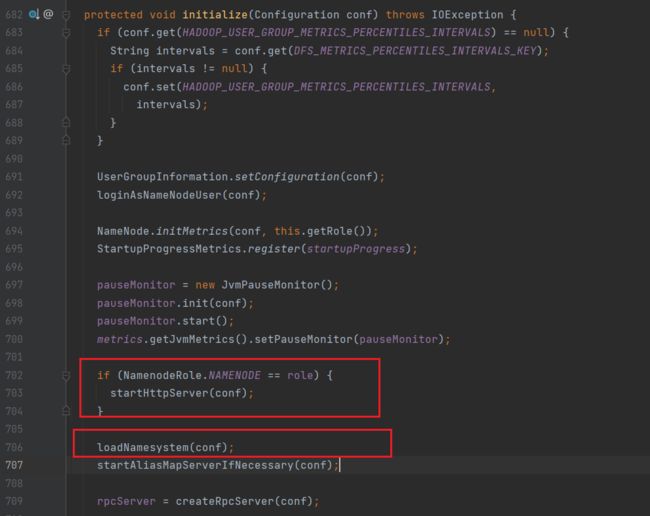
从磁盘中加载镜像文件:

创建镜像文件,指定镜像文件和编辑日志的路径:
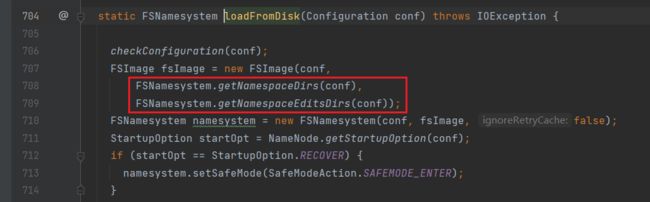

3.初始化RPC服务端(createRpcServer)
initialize方法中:
![]()
进入createRpcServer方法,可以看到创建了一个NameNodeRpcServer的实例化对象:

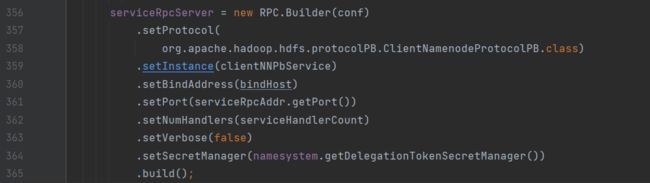
进入NameNodeRpcServer:通过new RPC.Builder创初始化RPC服务端
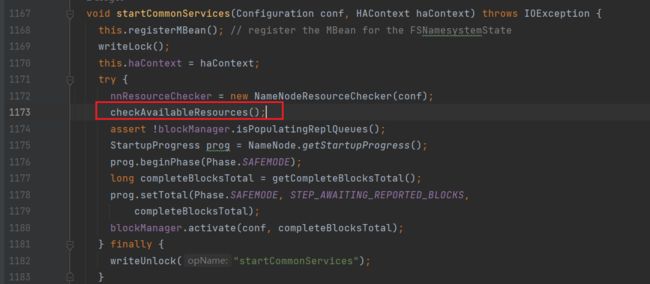
4.NameNode启动资源检查(startCommonServices)
initialize方法中:
![]()
进入startCommonServices:(FSNamesystem.java)

- 找到
NameNodeResourceChecker:(NameNodeResourceChecker.java)

该方法对于NameNode需要使用的资源进行检查:

![]()
该值即为默认的元数据存储空间(dfs.namenode.resource.du.reserved 默认值 1024 * 1024 * 100 =100m)
- 找到
checkAvailableResources方法:(FNNamesystem.java)
进入checkAvailableResources方法,查看是否有足够的存储空间,如果资源不够则返回false:
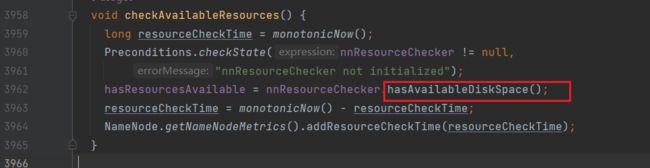
进入hasAvailableDiskSpace方法:(NameNodeResourceChecker.java)

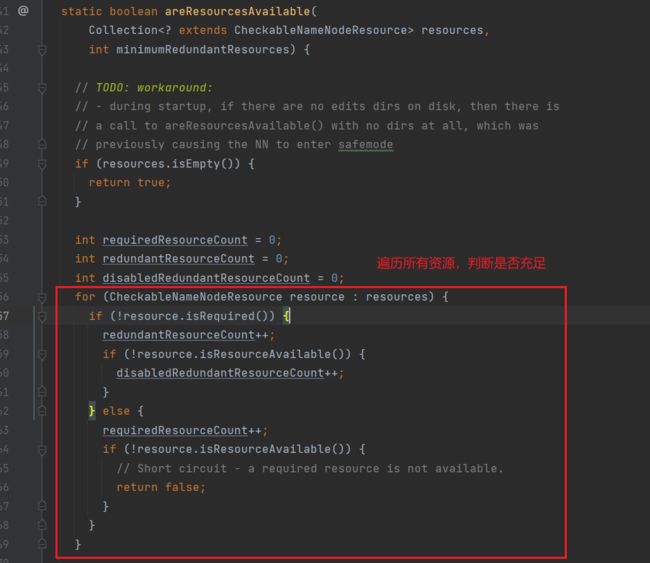
进入areResourcesAvailable方法:(NameNodeResourcePolicy.java)
进入CheckableNameNodeResource:

可以看到其是一个接口,ctrl+h查看其实现类:
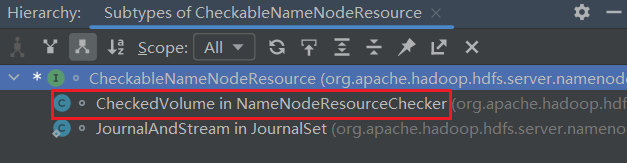
进入CheckedVolume,找到其中isResourceAvailable方法的实现:

其中duReserved的值在NameNodeResourceChecker中进行了赋值,默认是100M

5.NameNode对心跳超时判断(startCommonServices)
进入startCommonServices方法中,找到blockManager.activate方法(启动块服务)
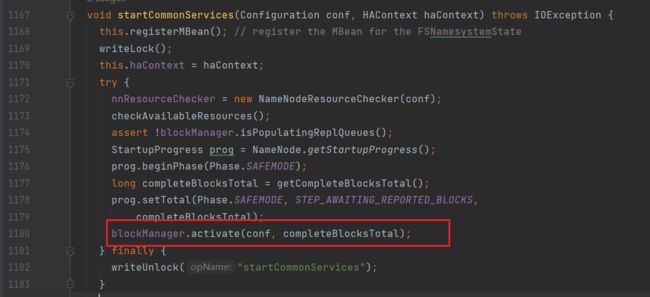
进入activate方法,找到datanodeManager.activate(conf)方法

再进入activate方法,找到heartbeatManager.activate()方法(DatanodeManager.java)

进入activate方法,可以看到该方法启动了一个线程

因此搜索run()方法,定位到其中的heartbeatCheck方法
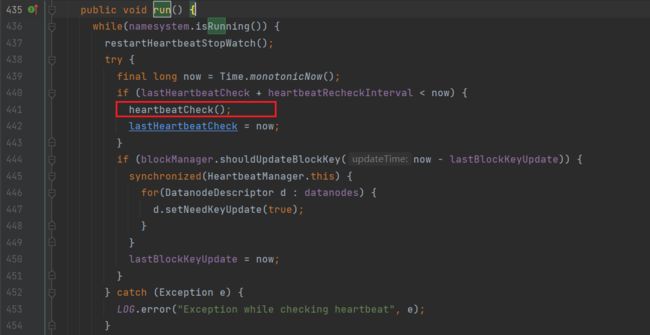
进入heartbeatCheck方法,定位到isDatanodeDead方法,该方法用于判断DataNode节点是否挂断:
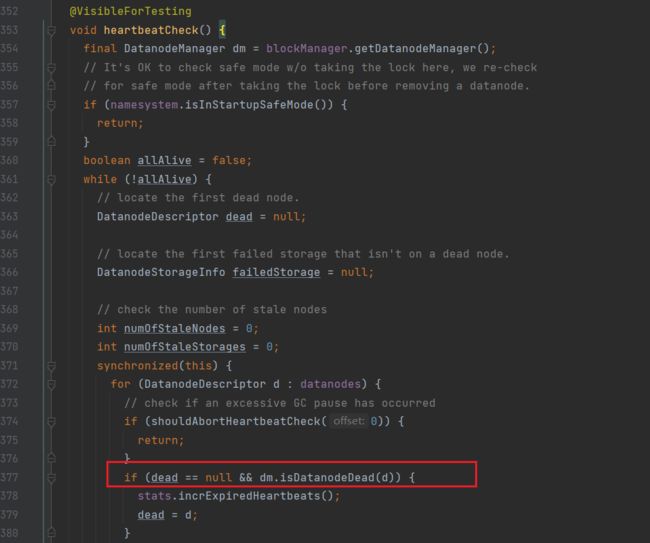
进入isDatanodeDead方法,可以看到该方法中的判断逻辑:

查看heartbeatExpireInterval的值,如下:
![]()
转而查看heartbeatRecheckInterval和heartbeatIntervalSeconds的值:
heartbeatRecheckInterval:
默认值为5min
heartbeatIntervalSeconds:

![]()
由此可见,DataNode超时时间的判定默认为10分钟 + 30秒
6.安全模式(startCommonServices)
进入startCommonServices方法:
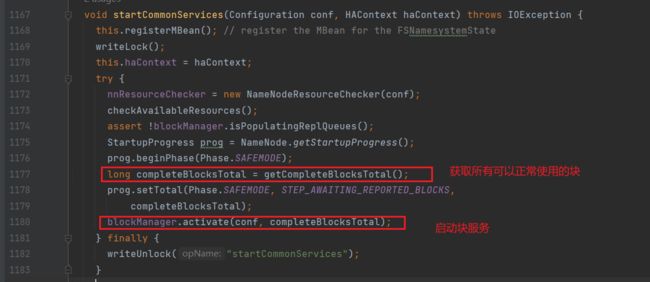
进入getCompleteBlocksTotal方法:
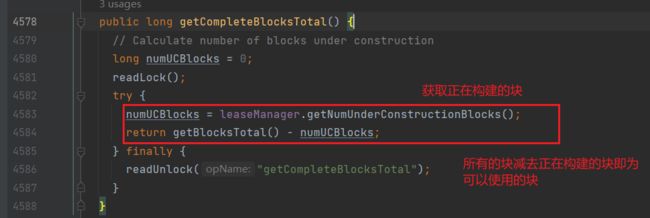
返回startCommonServices方法,进入blockManager.activate方法:

进入bmSafeMode.activate方法,

- 进入
setBlockTotal方法:
阈值的计算逻辑:正常块的总数(total) * replQueueThreshold
而replQueueThreshold的值如下:

![]()
![]()
- 进入
areThresholdsMet方法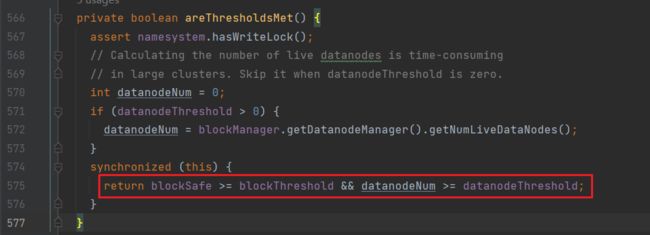
可以看到判断逻辑是:return blockSafe >= blockThreshold && datanodeNum >= datanodeThreshold;
其中blockSafe为已经正常注册的块数

blockThreshold为块的最小阈值

datanodeNum为当前可用dn数量
datanodeThreshold为最小可用dn数量

由此可见,只有满足以上判断条件,才会触发离开安全模式的逻辑