MySQL模糊查询优化,字符串精准匹配
文章目录
- 1.简介
- 2.直接使用like语句效率低的原因
- 3.模糊查询优化的方法
-
- 1.索引
- 2.LOCATE(‘substr’,str,pos)方法
- 3.POSITION(‘substr’ IN field)方法
- 4.INSTR(str,‘substr’)方法
- 5.CONTAINS(`column`,str)方法
- 4.字符串精准匹配
-
- 1.默认函数
- 2.自定义函数
1.简介
在平时使用msyql需要模糊的匹配字段的时候,我们第一反应就是使用like查询语句来模糊匹配,当数据量小的时候,我们通常感觉不到是否影响查询效率,但在数据量达到百万级,千万级的时候,like查询的低效率就很容易显现出来。这个时候查询的效率就显得很重要。
2.直接使用like语句效率低的原因
下面建立一张测试表作为所有演示的数据。

在mysql中直接使用like并不会影响查询使用索引,但在开头使用通配符后(% 或者_)索引就会失效,查询数据量较大时必然会造成性能问题。
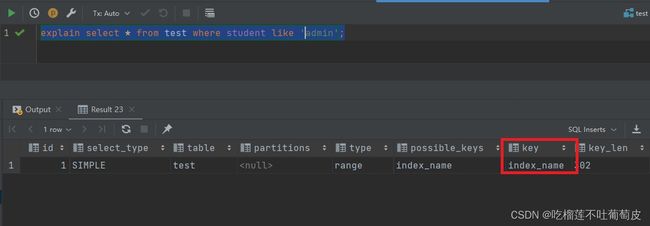
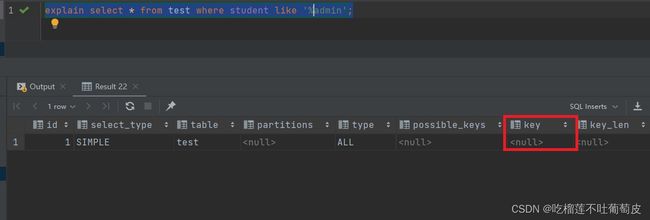
3.模糊查询优化的方法
1.索引
SELECT `column` FROM `table` WHERE `field` like 'keyword%';
没加索引情况下是全表搜索,加了索引情况下速度会大幅度提升,但不适用于全部搜索,只适用于"keywork%"关键字开头
2.LOCATE(‘substr’,str,pos)方法
SELECT `column` FROM `table` WHERE LOCATE('keyword', `field`)>0
keyword是要搜索的内容,field为被匹配的字段,查询出全部存在keyword的数据
3.POSITION(‘substr’ IN field)方法
SELECT `column` FROM `table` WHERE POSITION('keyword' IN `filed`)
position能够看作是locate的别名,功能跟locate同样
4.INSTR(str,‘substr’)方法
SELECT `column` FROM `table` WHERE INSTR(`field`, 'keyword')>0
5.CONTAINS(column,str)方法
SELECT `column` FROM `table` WHERE CONTAINS(`column`, 'keyword')
4.字符串精准匹配
如测试表中的数据所示,如果我们使用like模糊查询,%admin的查询结果会导致student字段不以admin结尾的数据都无法查出来,而使用%admin%则会导致admin1,admin12这种数据也被查出来。
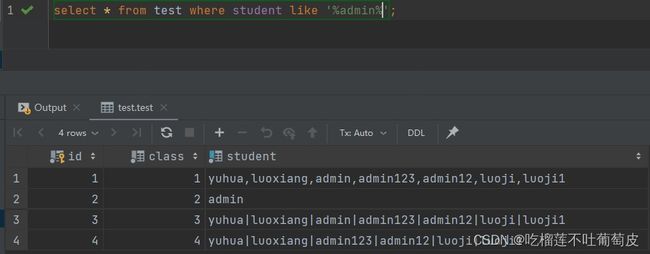
为解决这种问题,需要使用到精准匹配的函数FIND_IN_SET(‘str’,column)。
1.默认函数
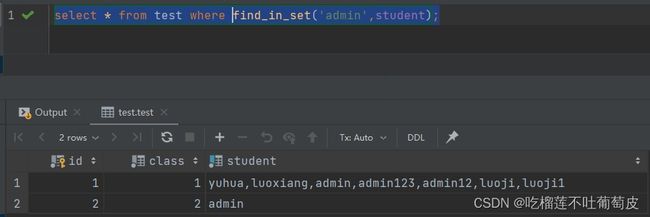
select * from test where find_in_set('admin',student);
查询结果:
2.自定义函数
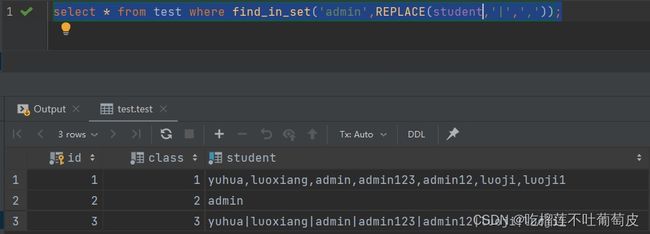
有时候分隔符不一定会按照逗号来分割,可能会有各种分隔符,如|,&等,需要自定义函数。
select * from test where find_in_set('admin',REPLACE(student,'|',','));
查询结果:
以上就是关于MySQL 模糊查询优化,以及字符串精准匹配的所有内容,希望对大家有帮助。