web自动化测试python+selenium+数据驱动
python中的selenium库可以用于网页UI自动化测试,在网上关于selenium中方法的介绍有很多。这里我就不再一个一个的去介绍了,有一些方法我们根本用不到,如果你会JavaScript的话只用execute_script()方法都可以完成很多操作了。在这里我着重说一下selenium的封装,以及如何在测试框架中使用数据驱动。
selenium框架
安装指令:pip3 install selenium
安装好selenium后,我们就可以使用selenium创建webdriver执行网页的UI自动化测试了。但要创建webdriver还需要一个浏览器驱动,用来完成python代码和浏览器之间的信息交流。通常都是我们自己根据浏览器的类型和版本自己到网上下载浏览器驱动,但现在我们有了一个更简单的方法来完成浏览器驱动的下载。
自动匹配浏览器驱动
webdriver_manager库可以自动下载当前浏览器的驱动程序,我们就不用根据浏览器的版本自己到网上去下载了。
安装指令:pip3 install webdriver_manager
源项目地址:https://github.com/SergeyPirogov/webdriver_manager
使用webdriver_manager可以轻松根据不同的浏览器类型创建浏览器驱动,使用方式如下:
from webdriver_manager.microsoft import EdgeChromiumDriverManager # 导入Edge浏览器管理
from selenium.webdriver.edge.service import Service
path = EdgeChromiumDriverManager().install() # 使用Edge浏览器管理下载浏览器驱动程序并返回驱动程序路径
print(path) # 打印出驱动程序路径
# selenium 4.0
driver = webdriver.Edge(service=Service(executable_path=path)) # 创建webdriverwebdriver_manager会通过执行终端指令查询当前浏览器的版本,再根据浏览器的版本去下载对应的浏览器驱动程序。但使用这种方式有个缺陷,就是需要连接网络,如果是在公司的限制性网络中运行就会有问题。因此我们做web自动化时最好只用一个版本的浏览器,需要禁止浏览器自动升级。
创建webdriver
selenium中的webdriver模块可以根据不同的浏览器来创建webdriver对象。例如我们要创建一个Edge浏览器的webdriver对象,使用如下代码:
from selenium import webdriver
from selenium.webdriver.edge.service import Service
driver = webdriver.Edge(service=Service(executable_path='msedgedriver.exe'))这里用的是selenium 4.0以上的版本,跟3.0的版本不同。3.0可以直接传入executeable_path,4.0以后变成了在Serveice中传入executeable_path。另外我们把上面webdriver_manager下载的浏览器驱动复制到了当前目录下,就可以直接使用了,不更新浏览器时不需要每次都下载。
打开网页
使用get()方法访问某个网页,需要传入网页的url。例如打开百度页面:
from selenium import webdriver
from selenium.webdriver.edge.service import Service
driver = webdriver.Edge(service=Service(executable_path='msedgedriver.exe'))
driver.get('http://www.baidu.com') # 打开百度网页刷新页面
使用refresh方法可以刷新当前页面。
from selenium import webdriver
from selenium.webdriver.edge.service import Service
from selenium.webdriver.edge.options import Options
import time
option = Options() # 实例化Options
option.add_experimental_option('detach', True) # 定义detach为True防止浏览器自动关闭
driver = webdriver.Edge(options=option, service=Service(executable_path='msedgedriver.exe')) # 添加option
driver.get('http://www.baidu.com') # 打开百度网页
time.sleep(5) # 停止5秒钟
driver.refresh() # 刷新当前页面如果想要在程序结束后浏览器不被关闭,需要在实例化webdriver时传入自定义的options,并且options的'detach'为True。
关闭页面
使用close方法可以关闭当前页面,当我们同时打开了多个页面时可以使用close关闭某些页面,前提是要先把窗口切换到需要关闭的窗口。
from selenium import webdriver
from selenium.webdriver.edge.service import Service
driver = webdriver.Edge(service=Service(executable_path='msedgedriver.exe'))
driver.get('http://www.baidu.com') # 打开百度网页
driver.close() # 关闭页面关闭webdriver
当我们不想再使用webdriver时,可以使用quit方法关闭webdriver,释放内存资源。
from selenium import webdriver
from selenium.webdriver.edge.service import Service
driver = webdriver.Edge(service=Service(executable_path='msedgedriver.exe'))
driver.get('http://www.baidu.com') # 打开百度网页
driver.quit() # 关闭driver切换页面窗口
当我们想从一个页面窗口切换到另一个窗口时,可以使用是switch_to.window方法。使用switch_to方法可以得到一个SwitchTo类的实例,SwitchTo类专门用于切换各种窗口,SwitchTo类中的window方法用于切换页面窗口。想要切换窗口还须得到窗口句柄,使用window_handles可以得到所有窗口句柄组成的句柄列表。
from selenium import webdriver
from selenium.webdriver.edge.service import Service
import time
driver = webdriver.Edge(service=Service(executable_path='msedgedriver.exe'))
driver.get('http://www.baidu.com') # 打开百度网页
driver.execute_script('window.open("https://www.csdn.com")') # 使用JavaScript在新窗口打开csdn网页
time.sleep(5) # 添加延时利于观察
window_list = driver.window_handles # 得到页面窗口句柄列表
driver.switch_to.window(window_list[1]) # 切换到第二个页面窗口
driver.close() # 关闭第二个窗口
time.sleep(5) # 添加延时利于观察查看元素属性
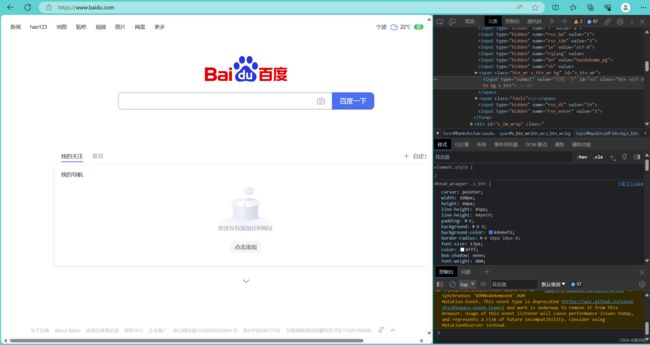
我们可以在浏览器中按键盘的F12打开浏览器开发工具,在开发工具左上角点击选择元素的箭头,然后到网页中选择一个元素,元素的属性就会显示在开发工具界面。
定位元素
定位元素的方法有很多,但最适合用于数据驱动的方法是find_element()和find_elements()。
find_element方法
find_element方法接收两个参数,第一个参数为查找页面元素的方式(id、name、class name、tag name、link text、partial link text、xpath、css selector),第二个参数为各个查找方式所对应的值,id就对应元素的id属性值、name就对应元素的name属性值、class name就对应元素的class属性值、tag name就对应元素的标签、link text、partial link text就对应元素的文本内容、xpath就对应元素在界面中的绝对路径、css selector就对应元素在界面中的相对路径。
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.edge.service import Service
driver = webdriver.Edge(service=Service(executable_path='msedgedriver.exe'))
driver.get('http://www.baidu.com')
element = driver.find_element(By.ID, 'su')
print(element)find_elements方法
find_elements方法跟find_element方法用法一样,不同点是find_elements会返回一个元素列表,列表中包含一个或多个某种属性相同的元素。例如name属性都为editor的元素、class都为el-form的元素、tag name都为a的元素。通常我们要找出多个某种属性相同的元素时才会使用find_elements方法。
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.edge.service import Service
driver = webdriver.Edge(service=Service(executable_path='msedgedriver.exe'))
driver.get('http://www.baidu.com')
elements = driver.find_elements(By.ID, 'su')
print(elements)等待元素
等待元素可以分为隐式等待、显示等待和强制等待。
隐式等待
查找元素的隐式等待通过webdriver实例的implicitly_wait方法设置一个全局的等待时间,设置后所有元素的查找操作都会以这个等待时间为准。等待时间内元素被找到就立即执行后面的代码,如果超出等待时间还未找到就会抛出错误。使用方式如下:
from selenium import webdriver
from selenium.webdriver.edge.service import Service
driver = webdriver.Edge(service=Service(executable_path='msedgedriver.exe'))
driver.implicitly_wait(5) # 设置查找元素隐式等待为5秒页面加载的隐式等待通过webdriver实例的set_page_load_timeout方法设置一个全局的等待时间,设置后所有的页面加载都会以这个等待时间为准。等待时间内页面加载成功就立即执行后面的代码,如果超出等待时间页面未加载出来就会抛出错误。使用方式如下:
from selenium import webdriver
from selenium.webdriver.edge.service import Service
driver = webdriver.Edge(service=Service(executable_path='msedgedriver.exe'))
driver.set_page_load_timeout(5) # 设置页面加载隐式等待为5秒JavaScript脚本异步执行隐式等待通过webdriver实例的set_script_timeout方法设置一个全局的等待时间,设置后所有的JavaScript脚本异步执行都会以这个等待时间为准。如果超出等待时间脚本执行未执行则抛出错误。使用方式如下:
from selenium import webdriver
from selenium.webdriver.edge.service import Service
driver = webdriver.Edge(service=Service(executable_path='msedgedriver.exe'))
driver.set_script_timeout(5) # 设置JavaScript脚本异步执行隐式等待为5秒(execute_async_script)显示等待
显示等待元素的出现或消失,我们通常使用WebDriverWait类的实例。WebDriverWait是一个很简单的类,只有4个方法,一个用于初始化的__init__方法、一个用于输出调试信息的__repr__方法、一个用于等待元素出现的until方法、一个用于等待元素消失的until_not方法。until和until_not的逻辑也非常的简单清晰,因为它们主要是为了实现函数回调。WebDriverWait在实例化时可以接收4个参数,第一个参数driver为webdriver;第二个参数timeout为等待元素出现或消失的时间,超出时间任未出现或消失则抛出超时错误;第三个参数poll_frequency为查找元素的频率,每间隔多久就检查一下元素是否出现或消失,默认0.5秒;第四个参数ignored_exceptions为在执行查找元素的函数时要捕获的错误类型,可以传入列表、元组这种可序列化的数据,默认为NoSuchElementException。如果觉得WebDriverWait太麻烦,我们也可以不使用WebDriverWait,自己定义等待函数也很简单。(其实整个selenium确实有点臃肿和冗余)
until方法
until方法主要用于等待元素的出现,可以接收两个参数。第一个参数为用于查找元素的函数,在until的while循环中会变成回调函数;第二个参数为查找元素超时后要抛出的错误描述,告诉别人为什么要抛出错误。使用方式如下:
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.edge.service import Service
driver = webdriver.Edge(service=Service(executable_path='msedgedriver.exe'))
driver.get('http://www.baidu.com')
element = WebDriverWait(driver, 10).until(lambda x: x.find_element(By.ID, "su"), '查找元素超时')until_not方法
until_not方法主要用于等待元素消失,可以接收两个参数。第一个参数为用于查找元素的函数,在until的while循环中会变成回调函数;第二个参数为查找元素超时后要抛出的错误描述,告诉别人为什么要抛出错误。使用方式如下:
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.edge.service import Service
driver = webdriver.Edge(service=Service(executable_path='msedgedriver.exe'))
driver.get('http://www.baidu.com')
state = WebDriverWait(driver, 30, 1, (ElementNotVisibleException)).until_not(lambda x: x.find_element(By.ID, "su").is_displayed(), '元素未消失')自定义方法
除了上面两个方法外,我们还可以自定义等待元素的方法。
def wait(driver: webdriver, by: str, value: str, timeout: float, *, frequency=0.5, display=True):
"""
等待元素出现或消失
:param driver: webdriver
:param by: ["id", "xpath", "link text", "partial link text", "name", "tag name", "class name", "css selector"]
:param value: 跟by对应的属性值
:param timeout: 查找元素的时间
:param frequency: 查找元素的频率
:param display: 出现或消失 -> True: 出现, False: 消失
:return: 元素或bool值
"""
end_time = time.monotonic() + timeout # 得到查找元素的截至时间
while True:
if time.monotonic() > end_time: # 判断当前时间是否大于截至时间
break
try:
element = driver.find_element(by, value) # 查找元素
if element.is_displayed() == display: # 判断元素是否出现或消失
return element if display is True else True # 返回元素或bool值
except Exception: # 捕获大多数错误
if not display:
return True
time.sleep(frequency)
raise TimeoutError(f'元素{by}={value}在{timeout}秒内未{"出现" if display else "消失"}')强制等待
强制等待就是使用time中的sleep函数,使后面的代码延迟执行。
操作元素
当我们定位到一个元素后,就可以对这个元素做一些操作。例如点击、拖动、输入文本、双击等等。
click方法
click方法用于点击元素,当我们定位到一个可点击元素后。就可以对它使用click方法,使它产生被鼠标左键点击后的效果。使用方式如下:
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.edge.service import Service
driver = webdriver.Edge(service=Service(executable_path='msedgedriver.exe'))
driver.get('http://www.baidu.com')
driver.find_element(By.ID, 's-top-loginbtn').click()send_keys方法
send_keys方法用于模拟键盘输入,当我们定位到一个输入框时。就可以对它使用send_keys方法,往这个输入框中输入文本内容,输入的文本内容是通过模拟键盘按键一个一个敲上去的。当然我们也可以使用send_keys方法模拟按键事件,例如按回车键、Ctrl+C、Ctrl+V等,selenium中的Keys类为我们提供了不能用文本表示的键值。使用方式如下:
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium import webdriver
from selenium.webdriver.edge.service import Service
import time
driver = webdriver.Edge(service=Service(executable_path='msedgedriver.exe'))
driver.get('http://www.baidu.com')
driver.find_element(By.ID, 'kw').send_keys('hello world') # 输入文本
time.sleep(1) # 延迟执行便于观察
driver.find_element(By.ID, 'kw').send_keys(Keys.CONTROL, 'a') # 按Ctrl+A全选
time.sleep(1) # 延迟执行便于观察
driver.find_element(By.ID, 'kw').send_keys(Keys.CONTROL, 'c') # 按Ctrl+C复制
time.sleep(1) # 延迟执行便于观察
driver.find_element(By.ID, 'kw').send_keys(Keys.CONTROL, 'v') # 按Ctrl+V粘贴清除文本内容
clear方法用于清除输入框中的文本内容,当我们定位到一个输入框时,就可以使用clear方法清除输入框中的内容。使用方式如下:
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.edge.service import Service
import time
driver = webdriver.Edge(service=Service(executable_path='msedgedriver.exe'))
driver.get('http://www.baidu.com')
driver.find_element('id', 'kw').send_keys('hello world') # 输入文本
time.sleep(1) # 延迟执行便于观察
driver.find_element(By.ID, 'kw').clear() # 清除文本获取文本内容
text方法可以获取元素的文字描述,例如点击跳转,对这个元素使用text方法就可以获得点击跳转文本。使用方式如下:
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.edge.service import Service
driver = webdriver.Edge(service=Service(executable_path='msedgedriver.exe'))
driver.get('http://www.baidu.com')
text = driver.find_elements(By.ID, 's-top-loginbtn').text
print(text)移动鼠标
我们通常使用ActionChains类中的move_to_element方法把鼠标移动到某个元素的上方。ActionChains类中提供了很多操作鼠标的方法,我这里只列举几个常用的。使用方式如下:
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium import webdriver
from selenium.webdriver.edge.service import Service
driver = webdriver.Edge(service=Service(executable_path='msedgedriver.exe'))
driver.get('http://www.baidu.com')
element = driver.find_elements(By.ID, 's-top-loginbtn')
ActionChains(driver).move_to_element(element).perform() # perform方法用于执行鼠标的动作右键单击
ActionChains类中的context_click方法可以实现鼠标右击某个元素,使用方式如下:
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium import webdriver
from selenium.webdriver.edge.service import Service
driver = webdriver.Edge(service=Service(executable_path='msedgedriver.exe'))
driver.get('http://www.baidu.com')
element = driver.find_elements(By.ID, 's-top-loginbtn')
ActionChains(driver).context_click(element).perform()双击
ActionChains类中的double_click方法可以实现鼠标双击某个元素,使用方式如下:
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium import webdriver
from selenium.webdriver.edge.service import Service
driver = webdriver.Edge(service=Service(executable_path='msedgedriver.exe'))
driver.get('http://www.baidu.com')
element = driver.find_elements(By.ID, 's-top-loginbtn')
ActionChains(driver).double_click(element).perform()拖拽
ActionChains类中的drag_and_drop方法可以实现把某个元素从当前位置拖动到另一个元素的位置。使用方式如下:
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.edge.service import Service
driver = webdriver.Edge(service=Service(executable_path='msedgedriver.exe'))
driver.get('http://xxx.com')
source = driver.find_elements(By.ID, 'xxx')
target = driver.find_elements(By.ID, 'xxx')
ActionChains(driver).drag_and_drop(source, target).perform()我在百度上没找到可拖拽的元素,你们自己找一个网页来尝试吧。
滚动页面
ActionChains类中的scroll_to_element方法可以实现鼠标滚轮滚动,使当前页面滚动到某个元素的位置。使用方式如下:
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium import webdriver
from selenium.webdriver.edge.service import Service
import time
driver = webdriver.Edge(service=Service(executable_path='msedgedriver.exe'))
driver.get('https://blog.csdn.net/qq_40148262/article/details/132191795')
element = driver.find_element('name', 't23')
ActionChains(driver).scroll_to_element(element).perform() # 滚动到完整代码位置
time.sleep(5)执行JavaScript脚本
使用execute_script方法可以执行JavaScript脚本,使用execute_async_script方法可以异步执行JavaScript脚本。你要是会JavaScript的话,上面的很多方法都可以被JavaScript脚本替代。使用JavaScript的好处是我们定位元素的时候根本不需要元素显示在界面上(电脑显示器中不可见),只要网页HTML文本加载完成我们就可以操作界面中的任意元素,JavaScript脚本还可以帮助我们实现更多的操作方式。
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.edge.service import Service
import time
driver = webdriver.Edge(service=Service(executable_path='msedgedriver.exe'))
driver.get('http://www.baidu.com')
driver.execute_script("var input = document.getElementById('kw');if(kw != null) {input.value = 'hello world';}")
time.sleep(5)封装基本测试类
根据上面介绍的方法来封装一个基本的测试类。
base.py
import time
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
class WebBase:
def __init__(self, web_driver: webdriver.Firefox):
self.driver = web_driver
self.wait_time = 10
def into_url(self, url: str):
"""
通过url访问网页\n
:param url: 网页的url
:return:
"""
self.driver.get(url)
def locate_element(self, by: str, value: str):
"""
定位一个元素\n
:param by: ["id", "xpath", "link text", "partial link text", "name", "tag name", "class name", "css selector"]
:param value: 跟by对应的属性值
:return: 一个网页元素(WebElement)
"""
element = self.wait(by, value)
return element
def locate_elements(self, by: str, value: str):
"""
定位一组元素\n
:param by: ["id", "xpath", "link text", "partial link text", "name", "tag name", "class name", "css selector"]
:param value: 跟by对应的属性值
:return: 一组网页元素(list[WebElement])
"""
return self.driver.find_elements(by, value)
def input_key(self, by: str, value: str, *args):
"""
给可输入的元素输入值\n
:param by: ["id", "xpath", "link text", "partial link text", "name", "tag name", "class name", "css selector"]
:param value: 跟by对应的属性值
:param args: 要输入的字符
:return:
"""
element = self.locate_element(by, value)
element.send_keys(*args)
def wait(self, by: str, value: str, *, timeout=None, frequency=0.5, display=True):
"""
等待元素出现或消失\n
:param by: ["id", "xpath", "link text", "partial link text", "name", "tag name", "class name", "css selector"]
:param value: 跟by对应的属性值
:param timeout: 查找元素的时间
:param frequency: 查找元素的频率
:param display: 出现或消失 -> True: 出现, False: 消失
:return: 元素或bool值
"""
if timeout is None:
timeout = self.wait_time
end_time = time.monotonic() + timeout
while True:
if time.monotonic() > end_time:
break
try:
element = self.driver.find_element(by, value)
if element.is_displayed() == display:
return element if display is True else True
except Exception:
if not display:
return True
time.sleep(frequency)
raise TimeoutError(f'元素{by}={value}在{timeout}秒内未{"出现" if display else "消失"}')
def wait_gone(self, by: str, value: str, timeout=None):
"""
等待元素消失\n
:param by: ["id", "xpath", "link text", "partial link text", "name", "tag name", "class name", "css selector"]
:param value: 跟by对应的属性值
:param timeout: 查找元素的时间
:return:
"""
try:
return self.wait(by, value, timeout=timeout, frequency=0.5, display=False)
except TimeoutError:
return False
def click_left(self, by: str, value: str):
"""
鼠标左键单击元素\n
:param by: ["id", "xpath", "link text", "partial link text", "name", "tag name", "class name", "css selector"]
:param value: 跟by对应的属性值
:return:
"""
element = self.locate_element(by, value)
element.click()
def click_right(self, by: str, value: str):
"""
鼠标右键单击元素\n
:param by: ["id", "xpath", "link text", "partial link text", "name", "tag name", "class name", "css selector"]
:param value: 跟by对应的属性值
:return:
"""
element = self.locate_element(by, value)
ActionChains(self.driver).context_click(element).perform()
def double_click(self, by: str, value: str):
"""
鼠标双击元素\n
:param by: ["id", "xpath", "link text", "partial link text", "name", "tag name", "class name", "css selector"]
:param value: 跟by对应的属性值
:return:
"""
element = self.locate_element(by, value)
ActionChains(self.driver).double_click(element).perform()
def move_mouse_to(self, by: str, value: str):
"""
移动鼠标到某个元素上方\n
:param by: ["id", "xpath", "link text", "partial link text", "name", "tag name", "class name", "css selector"]
:param value: 跟by对应的属性值
:return:
"""
element = self.locate_element(by, value)
ActionChains(self.driver).move_to_element(element).perform()
def drag_element(self, by1: str, value1: str, by2: str, value2: str):
"""
把第一个元素拖拽到第二个元素的位置\n
:param by1: ["id", "xpath", "link text", "partial link text", "name", "tag name", "class name", "css selector"]
:param value1: 跟by1对应的属性值
:param by2: ["id", "xpath", "link text", "partial link text", "name", "tag name", "class name", "css selector"]
:param value2: 跟by2对应的属性值
:return:
"""
source = self.locate_element(by1, value1)
target = self.locate_element(by2, value2)
ActionChains(self.driver).drag_and_drop(source, target).perform()
def swipe(self, by: str, value: str):
"""
滑动界面到某个元素\n
:param by: ["id", "xpath", "link text", "partial link text", "name", "tag name", "class name", "css selector"]
:param value: 跟by对应的属性值
:return:
"""
element = self.locate_element(by, value)
self.driver.execute_script("arguments[0].scrollIntoView();", element)
def clear_text(self, by: str, value: str):
"""
清除文本内容\n
:param by: ["id", "xpath", "link text", "partial link text", "name", "tag name", "class name", "css selector"]
:param value: 跟by对应的属性值
:return:
"""
element = self.locate_element(by, value)
element.clear()
def get_text(self, by: str, value: str):
"""
获取文本内容\n
:param by: ["id", "xpath", "link text", "partial link text", "name", "tag name", "class name", "css selector"]
:param value: 跟by对应的属性值
:return: 文本内容(str)
"""
element = self.locate_element(by, value)
return element.text
def script(self, js):
"""
执行js脚本\n
:param js:
:return:
"""
return self.driver.execute_script(js)
def refresh(self):
"""
刷新页面\n
:return:
"""
self.driver.refresh()
def switch_window(self, index: int):
"""
切换页面窗口\n
:param index: 窗口索引
:return:
"""
window_list = self.driver.window_handles
self.driver.switch_to.window(window_list[index])
def close(self):
"""
关闭当前窗口\n
:return:
"""
self.driver.close()
def quit(self):
"""
关闭webdriver\n
:return:
"""
self.driver.quit()
if __name__ == '__main__':
pass
使用数据驱动
在测试用例文件中我们可以使用数据驱动来来简化测试用例。当存在多个操作步骤相同测试参数不同的测试用例时,我们就可以只写一个测试方法来执行多个测试用例。我们可以把测试数据放到excel、json、py等文件中,然后使用对应的方法去读取文件中的数据,如果是放在excel中可以使用openpyxl或者pandas来读取数据,如果是放在json中可以使用json来读取数据,如果是放在py文件中直接导入py文件就行了。
假设我们在json文件中存放了3个登录网站的用户数据(用户名、密码),现在我们用数据驱动来实现一个测试方法执行3条用例。
login.json
{
"element": {
"name": [
"id",
"username"
],
"password": [
"id",
"password"
],
"login": [
"id",
"login"
],
"logout": [
"id",
"logout"
]
},
"data": [
[
"xiaoming",
"123456"
],
[
"baoxiaowa",
"666666"
],
[
"limei",
"654321"
]
]
}ddt原理分析
python中的ddt库专门用来实现unittest.TestCase类的数据驱动,使用ddt库中的ddt函数装饰unittest.TestCase的子类,ddt函数会遍历检查被装饰类中的所有方法。如果有方法中拥有%values属性时,ddt函数会把%values属性对应的值遍历出来,在遍历过程中使用此方法的逻辑创建多个相同逻辑不同名称的测试方法,并把遍历出来的数据传入到创建出来的方法中,最后把创建出来的方法加入到被装饰的类中。如果有方法中拥有%file_path属性时,ddt函数会打开%file_path属性中文件路径对应的文件,如果该文件是反序列化文件将使用yaml来读取文件,如果该文件是json文件直接使用json来读取文件,读取出数据后再遍历这些数据,在遍历过程中使用此方法的逻辑创建多个相同逻辑不同名称的测试方法,并把遍历出来的数据传入到创建出来的方法中,最后把创建出来的方法加入到被装饰的类中。
import unittest
import ddt
@ddt.ddt
class TestCase(unittest.TestCase):
...ddt库中的data函数用来装饰unittest.TestCase子类中的测试用例方法,需要给data函数中传入测试数据。data函数会使用python内置的setattr()函数,把传入的测试数据设置为被装饰方法的%values属性。setattr(被装饰函数, '%values', 测试数据)
import unittest
import ddt
@ddt.ddt
class TestCase(unittest.TestCase):
@ddt.data(1, 2, 3)
def test_1(self, data):
print(data)
if __name__ == '__main__':
suit = unittest.TestSuite()
suit.addTest(unittest.TestLoader().loadTestsFromTestCase(TestCase))
runner = unittest.TextTestRunner(verbosity=2)
runner.run(suit)执行结果如下:

从执行结果中我们可以发现执行了3个测试方法,ddt.data把一个测试方法变成了3个测试方法,并且把data中的1、2、3分别传入了第一个、第二个、第三个方法中。
ddt库中的file_data函数用来装饰unittest.TestCase子类中的测试用例方法,需要给file_data函数中传入一个用于存放测试数据的json文件路径。file_data函数会使用python内置的setattr()函数,把传入的json文件路径设置为被装饰方法的%file_path属性。setattr(被装饰函数, '%file_path', json文件路径)
import unittest
import ddt
@ddt.ddt
class TestCase(unittest.TestCase):
@ddt.file_data('login.json')
def test_1(self, *args, **kwargs):
for i in args:
print(i)
for key, value in kwargs.items():
print(f'{key}: {value}')
print('-'*100)
if __name__ == '__main__':
suit = unittest.TestSuite()
suit.addTest(unittest.TestLoader().loadTestsFromTestCase(TestCase))
runner = unittest.TextTestRunner(verbosity=2)
runner.run(suit)执行结果如下:

从执行结果中我们可以发现,ddt.file_data把login.json文件中的数据读取出来按字典的键把一个测试方法变成了两个方法,从方法名test_1_1_element和test_1_2_data就能看出字典的键element和data被融入到了测试方法名中,键对应的值当作测试数据放到了测试方法中。
使用ddt
根据ddt的工作原理,我们可以在unittest.TestCase子类中使用ddt,来到达数据驱动的目的。
login_test.py
import json
from selenium import webdriver
import unittest
from base import WebBase
import ddt
with open('login.json', 'r') as f:
data = json.load(f)
@ddt.ddt
class LoginTest(unittest.TestCase):
@classmethod
def setUpClass(cls) -> None:
driver = webdriver.Firefox(executable_path="geckodriver")
cls.web = WebBase(driver)
def setUp(self) -> None:
self.web.into_url('https://xxx.com')
def tearDown(self) -> None:
self.web.close()
@classmethod
def tearDownClass(cls) -> None:
cls.web.quit()
@ddt.data(*data['data'])
def test_login(self, n):
"""登录xxx网站"""
name = data['element']['name']
password = data['element']['password']
login = data['element']['login']
logout = data['element']['logout']
self.web.input_key(*name, n[0])
self.web.input_key(*password, n[1])
self.web.click_left(*login)
self.web.click_left(*logout)通过这种方式,我们就可以把测试数据跟测试方法分离,不管多少个数据都只用一个方法实现。同时也把元素和方法分离,不管后期会怎样修改元素的属性,我们只需更新json文件中的内容就行了。
测试用例跟测试方法完全分离
如果遇到操作步骤都会经常变化的测试用例,我们还可以把测试方法都放到json文件中,使测试方法跟测试用例完全分离。
data.json
{
"login": [
[
"input_key",
"id",
"username",
"xiaoming"
],
[
"input_key",
"id",
"password",
"123456"
],
[
"click_left",
"id",
"login"
],
[
"click_left",
"id",
"logout"
]
]
}login_test.py
from selenium import webdriver
import unittest
from base import WebBase
class LoginTest(unittest.TestCase):
@classmethod
def setUpClass(cls) -> None:
driver = webdriver.Firefox(executable_path="geckodriver")
cls.web = WebBase(driver)
def setUp(self) -> None:
self.web.into_url('https://xxx.com')
def tearDown(self) -> None:
self.web.close()
@classmethod
def tearDownClass(cls) -> None:
cls.web.quit()
@ddt.file_data('data.json')
def test_login(self, data):
"""登录xxx网站"""
for i in data:
getattr(self.web, i[0])(*i[1:])通过这种方式,我们可以实现测试用例和测试方法完全分离,不管测试步骤怎么变化、元素怎么变化,只需修改json文件就行了。