Timestone: Netflix的高吞吐、低延迟优先级队列系统
队列系统是微服务系统的核心组件之一,本文介绍了Netflix内部构建的高吞吐量、低优先级队列系统。原文: Timestone: Netflix’s High-Throughput, Low-Latency Priority Queueing System with Built-in Support for Non-Parallelizable Workloads
简介
Timestone是Netflix内部构建的高吞吐、低延迟优先级队列系统,以支持Netflix媒体编码平台Cosmos的需求。在过去的2年半的时间里,Timestone的使用量一直在增加,现在还成为了Netflix通用工作流编排引擎Conductor的优先级队列引擎,以及用于大规模数据流水线的调度器(BDP Scheduler)。总而言之,Netflix内部数百万个关键工作流现在都要通过Timestone处理。
Timestone客户端可以创建队列,基于用户定义的截止日期和元数据对消息进行排队,然后以最早截止日期优先(EDF, earliest-deadline-first)的方式对消息进行出队处理,还支持通过条件(例如"属于队列X且具有元数据Y的消息")筛选EDF消息。
Timestone与其他优先级队列的不同之处在于,它支持一种称为独占队列(exclusive queues) 的结构,这是一种将工作块标记为不可并行的方法,不需要在消费者端进行任何锁定或协调,所有事情都由后台独占队列处理。我们将在接下来的小节中详细解释这个概念。
为什么用Timestone
当我们在2018年设计Reloaded(Netflix的媒体编码系统)的后继系统时(参见Netflix Cosmos Platform一文的"背景"部分),需要一个优先队列系统,用于在Cosmos的三个组件之间提供队列(图1):
- API框架(Optimus)
- 正向链式规则引擎(Plato)
- 无服务器计算层(Stratum)
 图1. 建立在Cosmos之上的视频编码应用程序。请注意三个Cosmos子系统: Optimus(将外部请求映射到内部业务模型的API层)、Plato(用于业务规则建模的工作流层)和Stratum(用于运行无状态和计算密集型功能的无服务器层)。来源:Netflix Cosmos Platform
图1. 建立在Cosmos之上的视频编码应用程序。请注意三个Cosmos子系统: Optimus(将外部请求映射到内部业务模型的API层)、Plato(用于业务规则建模的工作流层)和Stratum(用于运行无状态和计算密集型功能的无服务器层)。来源:Netflix Cosmos Platform
这个优先级队列系统需要满足的一些关键需求:
-
在任何给定时间内,一条消息只能分配给一个处理节点。在Cosmos中发生的工作往往是资源密集型的,并且可以触发数以千计的动作。假设数据存储副本之间存在复制延迟,刚刚由工作者A通过另一个节点从队列中取出的消息也会被显示为工作者B可取出的消息,这种情况会浪费大量计算周期。这一需求最终将一致的解决方案排除在外,意味着我们希望在队列级别上实现线性一致性(linearizable consistency)。
-
允许非并行工作。
假设(Given) Plato不断轮询所有工作流队列,以便执行更多的工作;
当(While) Plato为给定项目执行工作流(或者说处理给定服务的工作请求)时;
那么(Then) Plato就不能在该工作流上为该项目的工作处理额外的请求。否则,Plato推理引擎将过早评估工作流,并可能将工作流迁移到不正确的状态。
因此,在Cosmos中存在某种不应该并行的工作,要求队列系统本身支持这种类型的访问模式,这一要求催生了独占队列的概念,我们将在"关键概念"部分解释独占队列在Timestone中的工作原理。
-
允许使用过滤器(元数据键-值对)退出消息以及队列深度查询
-
允许在接收消息时自动创建队列
-
消息在进入队列一秒内可以标记为可退出
我们之所以创建Timestone,是因为无法找到满足这些需求的现成解决方案。
系统架构
Timestone是基于gRPC的服务,通过protocol buffers定义服务接口以及请求、响应消息结构。应用程序的系统关系图如图2所示。
 图2. Timestone系统图。箭头链接了典型Timestone客户端-服务器交互过程中接触到的所有组件。红色数字表示顺序步骤,相同数字表示并发步骤。
图2. Timestone系统图。箭头链接了典型Timestone客户端-服务器交互过程中接触到的所有组件。红色数字表示顺序步骤,相同数字表示并发步骤。
记录系统(System of record)
记录系统是一个持久化Redis集群。到达集群(步骤2)的每个写请求(参见步骤1,注意该步骤改变了队列状态,包括了出队列请求)在响应发送回服务器(步骤3)之前被持久化到事务日志中。
在数据库内部,我们用排序集(sorted set)来表示每个队列,根据优先级对消息id进行排序(参见"消息"一节)。我们将消息和队列配置(参见“队列”一节)作为哈希保存在Redis中。所有与队列相关的数据结构(从它包含的消息到支持按筛选器出队列所需的内存二级索引)都放在同一个Redis分片中,通过共享一个特定于相关队列的公共前缀来实现这一点。然后我们将这个前缀编码为Redis哈希标签(hash tag)。每条消息携带一个最大32KB的内容(参见"消息"一节)。
Timestone和Redis之间的几乎所有交互(参见"消息状态"一节)都被编写为Lua脚本。大多数Lua脚本中,我们倾向于更新大量数据结构。由于Redis保证每个脚本都是原子执行的,脚本成功执行可以保证系统处于一致(在ACID意义上)状态。
所有API操作都以队列为作用域,所有修改状态的API操作都是幂等的。
二级索引(Secondary indexes)
出于可观察性的目的,我们在Elasticsearch中维护的两个二级索引中维护传入消息及其状态之间转换的信息。当我们从Redis得到写响应时,同时(a)将这个响应返回给客户端,(b)将这个响应转换为发布到Kafka集群的事件,如步骤4所示。两个Flink作业(维护的每一种类型的索引都有一个)消费对应Kafka主题的事件,并更新Elasticsearch中的索引。
一个索引("current")为用户提供系统当前状态的最佳视图,而另一个索引("historic")为用户提供消息的最佳纵向视图,从而允许流经Timestone时跟踪消息,并回答诸如在某个状态中花费的时间和处理错误的数量等问题。我们为每条消息维护一个版本计数器,每次写操作都触发计数器递增,通过版本计数器对历史索引中的事件进行排序。事件在Elasticsearch集群保存特定时间。
当前在Netflix中的使用情况
系统出队列的负载很重,每秒有30K的出队列请求(RPS), P99延迟为45ms。相比之下,入队列请求是每秒1.2K和P99延迟是25ms。此外经常能看到5K RPS的入队列突发流量,P99延迟会增加到85ms。自今年初以来,有150亿(15B)消息在Timestone里排队,出队列4000亿(400B)次,待处理消息通常达到1000万(10M)条。随着我们将Reloaded(遗留媒体编码系统)的其余部分迁移到Cosmos,使用量预计将在明年(2023年)翻一番。
核心概念
消息(Message)
消息携带非透明有效负载(payload) 、用户定义优先级(参见"优先级"一节)、一组可选的(对于独占队列是必选的)元数据键-值对(set of metadata key-value pairs) ,可用于基于过滤器的出队,以及可选的不可见持续时间(invisibility duration) 。放入队列中的任何消息都可以从队列中取出有限次数,我们称之为尝试(attempts) ,消息的每一次出队列调用都会减少尝试次数。
优先级(Priority)
消息的优先级表示为整数值,该值越低,优先级越高。虽然应用程序可以自由使用它们认为合适的取值范围,但标准是使用以毫秒为单位的Unix时间戳(例如,1661990400000表示UTC时间9/1/2022午夜)。
 图3. Cosmos中的流编码流水线所用的
图3. Cosmos中的流编码流水线所用的 PriorityClass枚举代码片段,括号中的值表示以天为单位的偏移量。
也完全可以由应用程序自己定义优先级级别。例如,Cosmos中的流编码流水线使用邮件优先级类,如图3所示。属于标准类的消息使用入队时间作为其优先级,而所有其他类的优先级值按10年的倍数调整。优先级是在工作流规则级别设置的,但是如果请求带有studio标记(例如DAY_OF_BROADCAST),则可以被重写。
消息状态(Message States)
队列中的Timestone消息处于以下六种状态之一(图4):
- invisible (不可见)
- pending (待处理)
- running (处理中)
- completed (已完成)
- canceled (已取消)
- errored (已出错)
通常来说,消息可以以不可见(invisible) 或待处理(pending) 的方式进入队列,对应消息处于不可见(invisible) 或待处理(pending) 状态。当不可见窗口(invisibility window)消失时,不可见消息将变为待处理状态。工作节点可以通过指定处理该消息的时间(租期)从队列中将待处理的最早截止日期优先的消息出队列,还支持批量消息出队列,从而将消息切换到处理中(running) 状态。然后,同一工作节点可以在分配的租约窗口内发出对Timestone的完成调用,以将消息迁移到已完成(completed) 状态,或者如果希望保持对消息的控制,则发出租约展期调用。(工作节点还可以将通常处于处理中的消息迁移到已取消状态,表示不再需要处理该消息。)如果这些调用都没有按时发出,消息将再次变为可出队的,对消息的这次尝试将结束。如果消息没有任何可用的尝试次数,将被自动迁移到已出错(errored) 状态。终止状态(terminal states) (已完成、已错误和已取消)由后台进程定期进行垃圾回收。
消息可以在工作节点调用API时迁移状态,也可以在Timestone运行后台进程时迁移状态(图4,标为红色,定期运行),图4显示了完整的状态转换图。
 图4. Timestone消息的状态迁移图。
图4. Timestone消息的状态迁移图。
队列(Queues)
所有传入的消息都存储在队列中,按其优先级日期排序。Timestone可以托管任意数量用户创建的队列,并提供一组用于队列管理的API,所有操作都围绕某个队列配置对象进行。存储在这个对象中的数据包括队列类型(参见其余部分)、应用于出队消息的租期或应用于出队消息的不可见持续时间、消息可以出队的次数,以及是否暂时阻止入队或出队。注意,消息生产者可以通过在入队期间在消息级别设置默认租期或不可见持续时间来覆盖对应配置。
Timestone中的队列分为两种类型: 简单队列(simple) 和独占队列(exclusive) 。
创建独占队列(exclusive queue) 时,需要与用户定义的独占键(exclusivity key) (例如project)相关联。所有发布到该队列的消息都必须在其元数据中携带此键。例如,带有project=foo的消息将被队列接受,没有project键的消息将不会被接受。本例中,我们调用与独占键对应的值foo,即消息的独占值(exclusivity value) 。独占队列的约定是,在任何时间点,每个独占值最多只能有一个消费者。因此,如果示例中的基于project的独占队列中有两个消息,其中的键值对是project=foo,并且其中一个消息已经被一个工作节点获取,那么另一个消息是不可出队的。如图5所示。
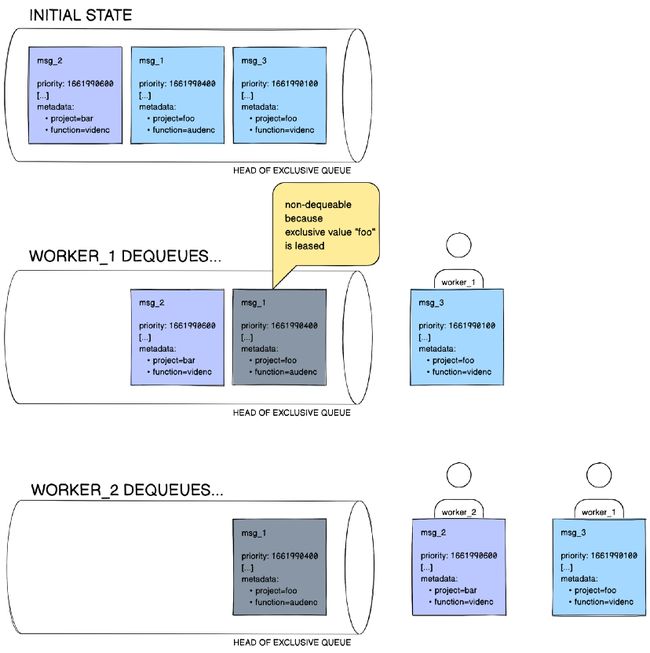 图5. 因为是独占队列,并且独占值foo已经被获取,因此即使msg_1具有更高的优先级,当worker_2发出出队调用时,也只会获取msg_2而不是msg_1。
图5. 因为是独占队列,并且独占值foo已经被获取,因此即使msg_1具有更高的优先级,当worker_2发出出队调用时,也只会获取msg_2而不是msg_1。
在简单队列中不会应用这种契约,也不与消息元数据键紧密耦合。简单队列可以作为典型优先级队列,简单的以最早截止日期优先的方式对消息进行排序。
我们在做什么
我们正在做的一些工作:
- 随着Timestone在Cosmos中使用量的增加,支持一系列队列深度查询的需求也在增加。为了解决这个问题,我们正在构建使用 不同查询模型的专用查询服务。
- 如上所述(见"记录系统"一节),一个队列及其内容目前只能占用一个Redis分片。然而,热队列可能会越来越大(特别是当计算能力不足时)。我们希望支持任意大的队列,因此促使我们构建了对队列分片的支持。
- 消息最多可以携带4个键值对,目前所有这些键值对都会用来填充按筛选器出队过程中使用的二级索引。这个运算在时间和空间上都是指数级复杂度的( )。我们正在将已排序集合切换到字典排序,以减少一半索引量,并以一种更具成本效益的方式处理元数据。
你好,我是俞凡,在Motorola做过研发,现在在Mavenir做技术工作,对通信、网络、后端架构、云原生、DevOps、CICD、区块链、AI等技术始终保持着浓厚的兴趣,平时喜欢阅读、思考,相信持续学习、终身成长,欢迎一起交流学习。
微信公众号:DeepNoMind
本文由 mdnice 多平台发布