Postgresql事务和Greenplum中的两阶段提交
PostgreSQL是当今最广泛应用的数据库系统(DBMS)之一。除了由于其具有优秀的性能、良好的兼容性之外,其完全开源的特性、完整的事务能力也是其中重要的原因。PostgreSQL支持完整的ACID特性,支持RC/RR/SSI等隔离级别。
Greenplum是一种广泛使用的,基于PG进行开发的MPP架构的分布式数据库。GP不仅高度兼容PG生态,还保持了PG包含支持完整事务的优点。GP本地事务的实现与PG基本一致,但为了保证多节点之间的事务状态一致性,GP引入两阶段提交协议来实现分布式事务。
本文主要简化的介绍PG的事务模型和Greenplum基于两阶段提交的分布式事务。具体地,本文会首先介绍单机事务、ACID特性,以及PG中的事务实现;然后介绍一种分布式事务协议——两阶段提交协议,分析其实现、优点和局限性,并简单介绍以3PC为代表的两阶段提交协议优化。
事务
ACID

nothing or all atomic
befor or after atomic看不到其他事务未提交的信息。
PG中的事务实现
事务总体实现
PG是进程模型,当postmaster接收到外部连接后,会fork出一个postgres进程,以处理外部请求。
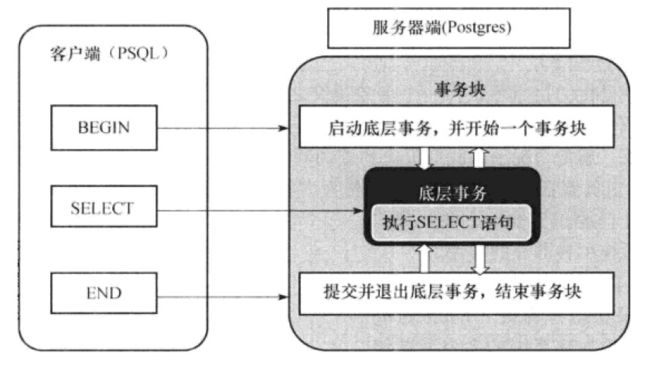
每个Postgres进程会创建一个事务块(TransactionBlock)以处理这个进程中的所有事务。一个事务块处理多个事务。PG基于状态机去管理事务块和事物的状态,而状态转换往往是由外部命令(BEGIN/END/ROLLBACK/COMMIT/ABORT/DDL/DML)所触发的。
事务块状态转换
事务块的基本操作函数包括StartTransactionCommand、CommitTransactionCommand和AbortCurrentTranscation。这些函数可能会在我们手动执行BEGIN、END、ROLLBACK命令时候显式调用,或者我们执行某些增删改查、使用某些UDF,或者使用某些数据库功能(分层存储、数据共享)的时候会自动调用。
当数据库开发者认为某些操作需要在一个事务中进行,就可能会添加一条StartTransactionCommand/CommitTransactionCommand指令让事务块进入开启/提交事务的状态。这些事务块进行状态转移的时候也会对应调用事务处理函数(StartTransaction、CommitTransaction等)对具体事务进行实际的处理。
事务状态转换:
上述事务块操作主要是修改全局的状态量,并不会做日志持久化、文件IO等具体工作,这些具体工作是由事务操作函数StartTransaction、CommitTransaction、AbortTransaction等实际操作的。
事务也包含多种状态:
TRANS_DEFAULT, /* idle */
TRANS_START, /* transaction starting */
TRANS_INPROGRESS, /* inside a valid transaction */
TRANS_COMMIT, /* commit in progress */
TRANS_ABORT, /* abort in progress */
TRANS_PREPARE
我们以事务提交(CommitTransaction)为例,介绍PG在一次事务提交的时候做了些什么:
1)检查当前事务状态,确保处于TRAN_INPROGRESS阶段;
2)触发所有延迟的触发器(AfterTriggerFireDeferred+AfterTriggerEndXact);
3)关闭所有大对象并释放内存(AtEOXact_LargeObject);
4)将事务状态修改为TRANS_COMMIT状态;
5)执行RecordTransactionCommit,记录xid、pendingdeletes信息、subtransaction到xlog、clog(记录事务状态日志)等;
6)释放资源,清理状态;
7)将事务状态改为TRANS_DEFAULT。
当我们在执行一次BEGIN/SELECT/INSERT/END的时候会做哪些事务相关的事情
这里我们以一个最简单的场景:
1) BEGIN
2) SELECT * FROM foo
3) INSERT INTO foo VALUES (...)
4) COMMIT
为例,介绍过程中进程会对事务和事务块进行哪些处理:
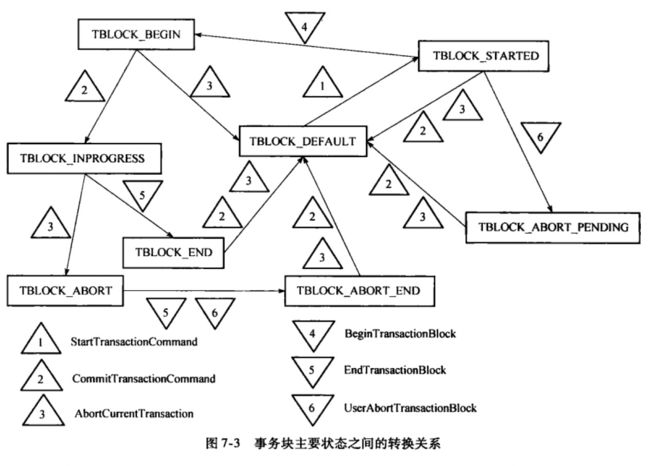
事务块默认状态为TRANS_DEFAULT
/ StartTransactionCommand; 修改事务块状态为TBLOCK_STARTED;
/ StartTransaction; 修改事务状态为TRANS_START;
1) < ProcessUtility; << BEGIN
\ BeginTransactionBlock; 设置事务块状态为TBLOCK_BEGIN;
\ CommitTransactionCommand; 设置事务块状态为TBLOCK_INPROGRESS;
/ StartTransactionCommand; 当前事务块状态为TBLOCK_INPROGRESS,无需处理,直接返回;
2) / ProcessQuery; << SELECT ...
\ CommitTransactionCommand; 当前事务块状态为TBLOCK_INPROGRESS,无需处理,直接返回;
\ CommandCounterIncrement; cid+1;
/ StartTransactionCommand; 当前事务块状态为TBLOCK_INPROGRESS,无需处理,直接返回;
3) / ProcessQuery; << INSERT ...
\ CommitTransactionCommand; 当前事务块状态为TBLOCK_INPROGRESS,无需处理,直接返回;
\ CommandCounterIncrement; cid+1;
/ StartTransactionCommand; 当前事务块状态为TBLOCK_INPROGRESS,无需处理,直接返回;
/ ProcessUtility; << COMMIT
4)
\ CommitTransactionCommand; 设置事务块状态为TBLOCK_END,并调用CommitTransaction提交事务,完全完成提交之后,将事务块状态重新设为TBLOCK_DEFAULT;
\ CommitTransaction; 设置事务状态为TRANS_COMMIT,写日志,清理资源。
分布式事务
在分布式场景下,每个数据存储节点都需要进行资源的获取与释放、日志的持久化,一阶段提交很难保证整个分布式系统的一致性,很多分布式事务协议被提出以解决分布式场景下的事务问题。两阶段提交(Two Phase Commit)协议被提出以解决分布式系统的强一致性事务问题。
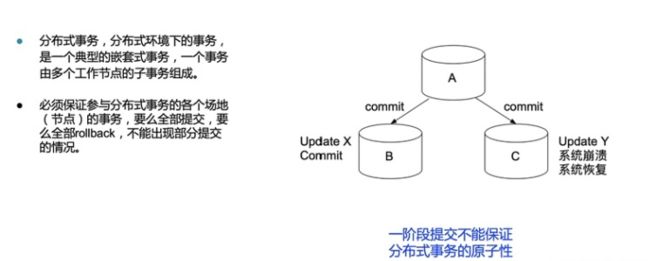
Two Phase Commit
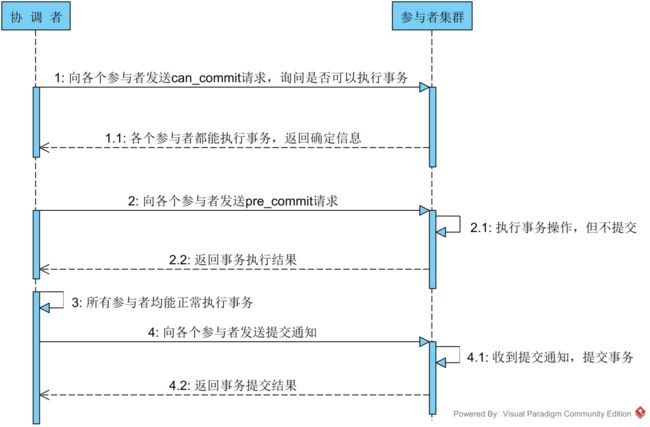
2PC是一个非常经典的强一致、中心化(协调节点、参与节点)的原子提交协议。它将事务的提交过程分成两个阶段:Prepare阶段和Commit阶段。下文中我们将实际执行具体操作的节点称为参与者,将协调事务进行的中心节点称为协调者。
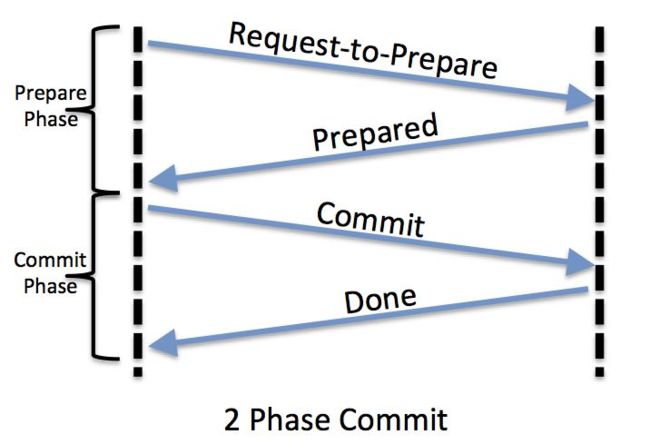
Prepare阶段
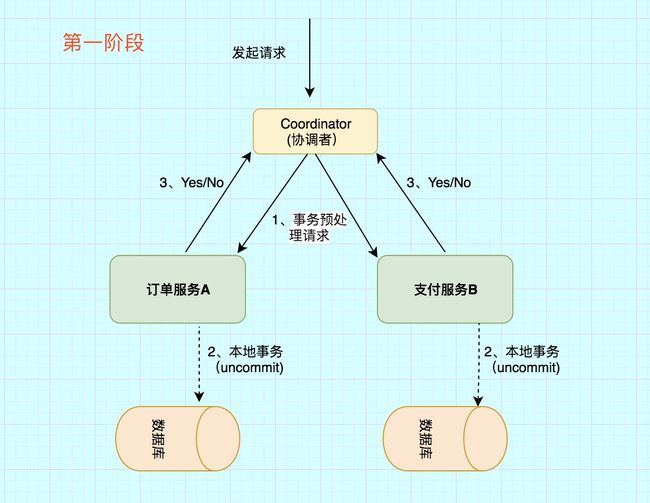
第一阶段主要分为3步
1)事务询问
协调者 向所有的 参与者 发送事务预处理请求,称之为Prepare,并开始等待各 参与者 的响应。
2)执行本地事务
各个 参与者 节点执行本地事务操作以及记录日志,但在执行完成后并不会真正提交更改并释放资源,而是先向协调者报告prepare完成情况,是否ready for commit。.
3)协调者接收响应,并决定是否继续完成提交。
第一阶段任一参与者没有正确回复将导致事务abort,协调者需要记录日志。
Commit阶段

第二阶段主要分为三步:
1)协调者发出COMMIT请求
协调者 向 所有参与者 节点发出Commit请求.
2)事务提交
参与者 收到Commit请求之后,就会正式执行本地事务Commit操作并记录日志,在完成提交之后释放整个事务执行期间占用的事务资源。
3)协调者接收到所有节点的回复之后,记录日志并释放资源。
故障恢复
(1)参与者故障
由于 协调者 无法收集到所有 参与者 的反馈,会陷入阻塞情况。协调者等参与者恢复后,根据处于的阶段决定进行abort或者retry commit;
(2)协调者故障
无论处于哪个阶段,由于协调者宕机,无法发送提交请求,所有处于执行了操作但是未提交状态的参与者都会陷入阻塞情况。通常的解决方法是引入高可用机制(high availability),引入流复制、Raft或者Paxos以在单个协调者发生故障时快速转移和接管。
3)网络错误: coordinator和participant之间出现networking partitioning, 互不可达. 普遍解决方法是: 重试+幂等+超时。
GP中的2PC
基础实现

分布式事务提交
GP采用状态机方式管理分布式事务:
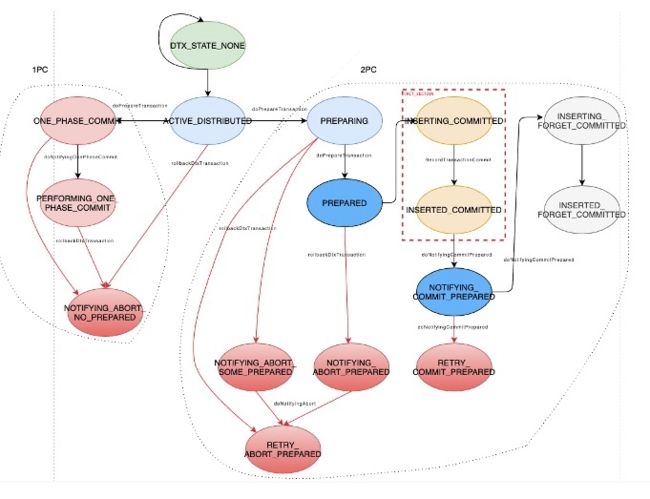
这里以提交为例,阐述分布式事务的处理过程:
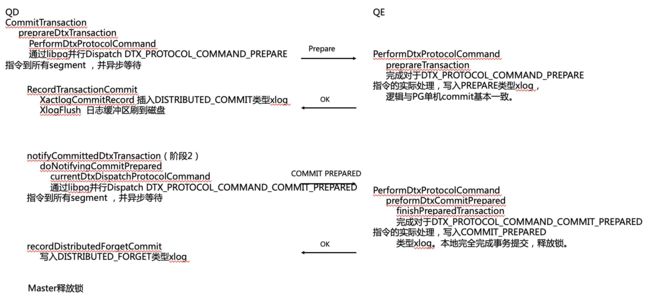
Prepare阶段:
1、QD发起分布式事务,并并行dispatach DTX_PROTOCOL_COMMAND_PREPARE指令,并等待结果;
2、QE接收到指令,写入PREPARE类型xlog;
3、QE发送回复给QD;
4、QD接收到QE发来的prepare回复,本地写入一条DISTRIBUTED_COMMIT类型xlog;PREPARE阶段完成。
COMMIT阶段:
1、QD向所有QE并行dispatch DispatchDTX_PROTOCOL_COMMAND_COMMIT_PREPARED指令,并等待结果;
2、QE接收到指令,写入COMMIT_PREPARED类型xlog;
3、QE向QD回复,QE释放资源;
4、QD接收到QE发来的COMMIT回复。本地写入一条DISTRIBUTED_FORGET类型xlog;
5、QD释放资源,事务完成。
分布式事务恢复
segment故障
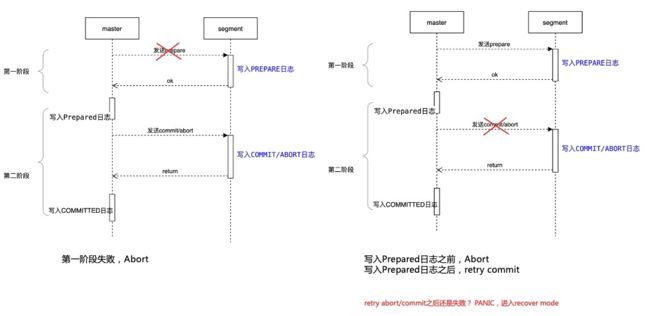
如果Segment发生不可恢复的故障怎么处理?
FTS 探测Segment,发现故障之后mirror--> 升级为primary
Master继续Commit/Abort 事务
如何保证mirror升级为primary后,事务可以继续Commit/Abort?
Prepare日志必须刷写到磁盘
Prepare日志,必须同步到mirror才完成prepare
Master故障

2PC的局限性
1、同步阻塞问题。
执行过程中,所有参与节点都是事务阻塞型的。当参与者占有公共资源时,其他第三方节点访问公共资源不得不处于阻塞状态。也就是说从投票阶段到提交阶段完成这段时间,资源是被锁住的。
2、交互延迟:协调者要持久化事务的commit/abort状态后才能发送commit/abort命令,因此全程至少2次RPC延迟(prepare+commit),和3次持久化数据延迟(prepare写日志+协调者状态持久化+commit写日志)。
2PC本身是一个非常优秀的强一致性协议,Greenplum、Spanner等很多数据库都实现了2PC。针对以上一致性,其实很多研究者也提出了一些面向特定场景的改进协议,以提升2PC的性能。下面主要介绍一下3PC。
3PC
三阶段提交(Three-phase commit),是二阶段提交(2PC)的改进版本。
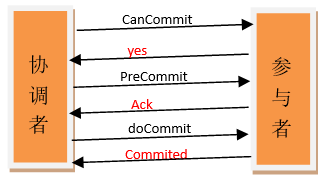
与两阶段提交不同的是,三阶段提交有两个改动点。
1、引入超时机制。同时在协调者和参与者中都引入超时机制。
2、在第一阶段和第二阶段中插入一个准备阶段,保证了在最后提交阶段之前各参与节点状态的一致。
CanCommit阶段
3PC的CanCommit阶段其实和2PC的Prepare阶段很像。协调者向参与者发送commit请求,参与者如果可以提交就返回Yes响应,否则返回No响应。
1.事务询问 协调者向参与者发送CanCommit请求。询问是否可以执行事务提交操作。然后开始等待参与者的响应。
2.响应反馈 参与者接到CanCommit请求之后,正常情况下,如果其自身认为可以顺利执行事务,则返回Yes响应,并进入预备状态。否则反馈No
这个阶段并不会加锁。
PreCommit阶段
本阶段协调者会根据第一阶段的询盘结果采取相应操作:
情况1-假如协调者从所有的参与者获得的反馈都是Yes响应,那么就会执行事务的预执行:
1.发送预提交请求 协调者向参与者发送PreCommit请求。
2.事务预提交 参与者接收到PreCommit请求后,会执行事务操作,并将undo和redo信息记录到事务日志中。
3.响应反馈 如果参与者成功的执行了事务操作,则返回ACK响应,同时开始等待最终指令。
情况2-假如有任何一个参与者向协调者发送了No响应,或者等待超时之后,协调者都没有接到参与者的响应,那么就执行事务的中断。具体步骤如下:
1.发送中断请求 协调者向所有参与者发送abort请求。
2.中断事务 参与者收到来自协调者的abort请求之后(或超时之后,仍未收到协调者的请求),执行事务的中断。
doCommit阶段
该阶段进行真正的事务提交,也可以分为以下两种情况。
情况1-执行提交
针对第一种情况,协调者向各个参与者发起事务提交请求,具体步骤如下:
1. 协调者向所有参与者发送事务commit通知
2. 所有参与者在收到通知之后执行commit操作,并释放占有的资源
3. 参与者向协调者反馈事务提交结果
情况2-中断事务
协调者没有接收到参与者发送的ACK响应(可能是接受者发送的不是ACK响应,也可能响应超时),那么就会执行中断事务。具体步骤如下:
1. 发送中断请求 协调者向所有参与者发送事务rollback通知。
2. 事务回滚 所有参与者在收到通知之后执行rollback操作,并释放占有的资源。
3. 反馈结果 参与者向协调者反馈事务提交结果。
4. 中断事务 协调者接收到参与者反馈的ACK消息之后,执行事务的中断
这一阶段中因为网络原因协调者与参与者断开通信, 参与者也会自动提交commit,这样防止了一直锁表的风险
相对于2PC,3PC主要解决的单点故障问题,并减少阻塞,因为一旦参与者无法及时收到来自协调者的信息之后,他会默认执行commit。而不会一直持有事务资源并处于阻塞状态。
在doCommit阶段,如果参与者无法及时接收到来自协调者的doCommit或者rebort请求时,会在等待超时之后,会继续进行事务的提交。