【ShardingSphere】单实例模式创建分片表、广播表、单表
文章目录
- 1、简介
- 2、ShardingSphere-Proxy 默认行为
-
- 2.1 安装
- 2.2 启动
- 3、设计测试环境
-
- 3.1 架构
- 3.2 数据映射关系
- 4、 准备工作
-
- 4.1 配置 `server.yaml`
- 4.2 配置 `config-logic_db.yaml`
- 4.3 创建数据源所配置的物理库
-
- 4.3.1 `ds_0`、`ds_1`
- 4.3.2 `ds_2`
- 4.4 启动
- 4.5 (可选)准备测试数据
-
- 4.5.1 创建逻辑表
- 4.5.2 插入测试数据
- 5、测试
-
- 5.1 分片表
-
- 5.1.1 逻辑表 `ss_s_db_tb`
- 5.1.2 物理表
-
- 1) `ds_0` 数据源内的物理表
- 2) `ds_1` 数据源内的物理表
- 3) `ds_2` 数据源内的物理表
- 5.1.3 小结
- 5.2 广播表
-
- 5.2.1 逻辑表 `ss_g0`
- 5.2.2 物理表
-
- 1) `ds_0` 数据源内的物理表
- 2) `ds_1` 数据源内的物理表
- 3) `ds_2` 数据源内的物理表
- 5.2.3 小结
- 5.3 普通表(单表)
-
- 5.3.1 逻辑表 `ss_n0`、`ss_n1`
-
- 1) 在逻辑库创建的 `ss_n0`
- 2) 在物理库创建的 `ss_n1`
- 5.3.2 物理表
-
- 1) `ds_0` 数据源内的物理表
- 2) `ds_1` 数据源内的物理表
- 3) `ds_2` 数据源内的物理表
- 5.3.3 小结
- 6、结论
-
- 6.1 总览
- 6.2 分片算法
1、简介
Apache ShardingSphere 作为近年来比较流行的数据库分库分表中间件,发展相当出色,社区、生态建设更新迭代速度很快,由最初的基于 JDBC 驱动的数据分片轻量级 Java 框架,演变为如今的 5.x 版本的面向可插拔的、微内核,支持多种异构数据库、编程语言的,遵循 Database Plus 设计哲学的分布式数据库生态系统。
笔者在之前的工作中,曾尝试使用 ShardingSphere 4.x 分库分表解决业务瓶颈,后因一些业务 SQL 支持等问题,放弃了该方案。在该过程中,笔者体验后的感觉是, 4.x 版本的配置便捷性、SQL 支持程度、分片算法方面做得并不是很好。
因当时订阅了该开发团队的 GitHub ,经常收到更新相关邮件,一直没有加以理会,最近想要研究一下现有分库分表、分布式中间件方面的东西,于是打算实践测试一下 ShardingSphere 5.x 版本,遂成此文。
本测试仅用到了 ShardingSphere-Proxy 。下面我会先测试它的默认行为。随后,设计一个测试环境架构,然后记录真实测试过程,最后进行总结。
软件安装包相关链接参见:ShardingSphere 官网资源链接 。
2、ShardingSphere-Proxy 默认行为
注释
以下简称 ShardingSphere-Proxy 为 Proxy 。
2.1 安装
上传二进制包到服务器。

验证一下签名。
$ gpg --import KEYS
$ gpg --verify apache-shardingsphere-5.4.0-shardingsphere-proxy-bin.tar.gz.asc apache-shardingsphere-5.4.0-shardingsphere-proxy-bin.tar.gz

如不考虑安全,可忽略下载 .asc 和 KEYS 文件。
将其解压到安装目录 /var/lib 下,并创建软连接(也可以直接重命名)。
$ tar -zxvf apache-shardingsphere-5.4.0-shardingsphere-proxy-bin.tar.gz -C /var/lib/
$ cd /var/lib
$ ln -s apache-shardingsphere-5.4.0-shardingsphere-proxy-bin/ shardingsphere
查看安装目录及其下的配置目录。
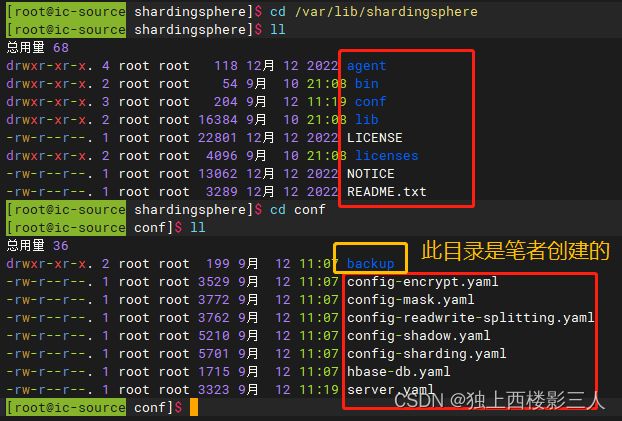
2.2 启动
Linux/macOS 操作系统请运行 bin/start.sh,默认监听端口 3307,默认配置目录为 Proxy 内的 conf 目录。启动脚本可以指定监听端口、配置文件所在目录,命令如下:
$ bin/start.sh [port] [/path/to/conf]
所以,我们先检查一下端口 3307 是否被占用。
$ lsof -i:3307
没有占用,直接执行 bin/start.sh 启动。

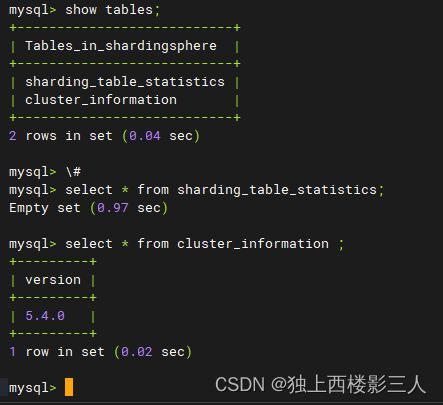
日志没有报错,使用 mysql 客户端验证一下。默认数据库用户为 root ,密码为 root 。

查看 shardingsphere 库的表信息。
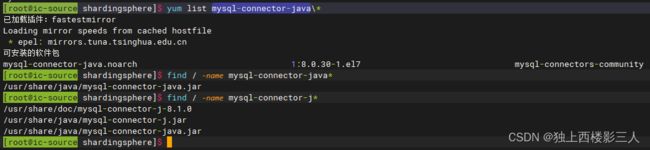
注释
后端数据库使用 MySQL 时,应提前安装mysql-connector-java.jar。
笔者是使用 Yum 安装的,因而可直接启动 Proxy。
如果你没有安装mysql-connector-java.jar,请按照官方指引下载它并将其放入ext-lib(或lib)目录。

上面可以看出,虽然 Proxy 默认提供了多个 config-*.yaml 逻辑数据库配置,实际默认并未生成。原因很简单,因为它把所有.yaml 文件的内容全注释了。
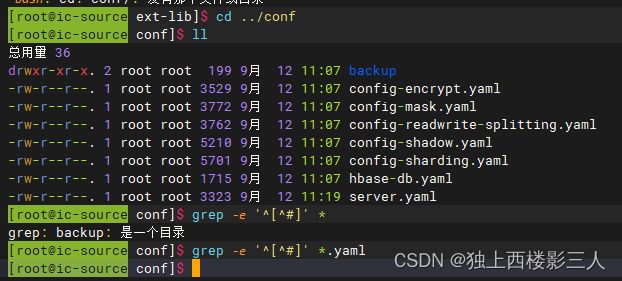
我们可以参考这些示例 .yaml 文件创建自己的配置文件,也可通过学习官网资料进行更明确、规范的配置。
3、设计测试环境
3.1 架构
| 应用 | 实例 | 主机 | IP | 端口 | 说明 |
|---|---|---|---|---|---|
| ShardingSphere-Proxy | source | 192.168.52.3 | 3407 | ShardingSphere-Proxy 单实例模式服务器实例 | |
| MySQL | rep01Src | source | 192.168.52.3 | 3308 | 数据源 ds1、ds2 所属物理 MySQL 实例,主从复制架构中的主节点 |
| MySQL | rep01Rep01 | replica1 | 192.168.52.4 | 3308 | 实例 rep01Src 的从(副本)节点,不参与数据分片 |
| MySQL | part2 | replica2 | 192.168.52.6 | 3308 | 数据源 ds3 所属物理 MySQL 实例 |
3.2 数据映射关系
| 逻辑库 | 逻辑表 | 数据源 | 物理实例 | 物理库 | 物理表 | 说明 |
|---|---|---|---|---|---|---|
| logic_db | ss_s_db_tb | ds_0 | rep01Src | db0 | ss_s_db_tb_0 | 数据分片既分库又分表,id%6 = 0 |
| logic_db | ss_s_db_tb | ds_0 | rep01Src | db0 | ss_s_db_tb_1 | 数据分片既分库又分表,id%6 = 1 |
| logic_db | ss_s_db_tb | ds_1 | rep01Src | db1 | ss_s_db_tb_0 | 数据分片既分库又分表,id%6 = 2 |
| logic_db | ss_s_db_tb | ds_1 | rep01Src | db1 | ss_s_db_tb_1 | 数据分片既分库又分表,id%6 = 3 |
| logic_db | ss_s_db_tb | ds_2 | part2 | db0 | ss_s_db_tb_0 | 数据分片既分库又分表,id%6 = 4 |
| logic_db | ss_s_db_tb | ds_2 | part2 | db0 | ss_s_db_tb_1 | 数据分片既分库又分表,id%6 = 5 |
| logic_db | ss_g0 | ds_[0-2] | [rep01Src,rep01Src,part2] | [db0, db1, db0] | ss_g0 | 全局表,数据源、物理实例、库一一对应 |
| logic_db | ss_n0 | ds_0 | rep01Src | db0 | ss_n0 | 普通表,位于 MySQL 主从复制架构,在逻辑库中创建 |
| logic_db | ss_n1 | ds_2 | part2 | db0 | ss_n1 | 普通表,位于 MySQL 单实例,在物理库中创建后加载到逻辑库 |
说明:
- 分库分表的表
ss_s_db_tb在数据源下标设计上从0开始计数,同一实例内的物理库(方案、模式)同样也从0开始计数。不同实例允许物理库名相同,表下标和表完整名称库内唯一,不同库允许存在同名的表。每个库内分两张表。如此设计是为了测试分片下标的各种策略。(更复杂的分片策略后续会另起一文) - 普通表分别测试位于 MySQL 主从复制架构和单实例架构的表现。
4、 准备工作
4.1 配置 server.yaml
mode:
type: Standalone
repository:
type: JDBC
authority:
users:
- user: root
password: 'Root@123'
- user: test
password: 'test'
privilege:
type: ALL_PERMITTED
logging:
loggers:
- loggerName: ShardingSphere-SQL
additivity: true
level: INFO
props:
enable: true
sqlParser:
sqlCommentParseEnabled: true
sqlStatementCache:
initialCapacity: 2000
maximumSize: 65535
parseTreeCache:
initialCapacity: 128
maximumSize: 1024
props:
proxy-default-port: 3407
4.2 配置 config-logic_db.yaml
databaseName: logic_db
dataSources:
ds_0:
#url: jdbc:mysql://source:3308/db0?allowPublicKeyRetrieval=true&useSSL=false
url: jdbc:mysql://source:3308/db0?useSSL=false
username: root
password: 'Ro123ot$'
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
ds_1:
url: jdbc:mysql://source:3308/db1?allowPublicKeyRetrieval=true&useSSL=false
username: root
password: 'Ro123ot$'
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
ds_2:
url: jdbc:mysql://replica2:3308/db0?allowPublicKeyRetrieval=true&useSSL=false
username: root
password: 'Ro123ot$'
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
rules:
- !SHARDING
tables:
ss_s_db_tb:
actualDataNodes: ds_${0..2}.ss_s_db_tb_${0..1}
tableStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: ss_s_db_tb_inline
keyGenerateStrategy:
column: id
keyGeneratorName: snowflake
defaultDatabaseStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: database_inline
defaultTableStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: ss_s_db_tb_inline
shardingAlgorithms:
database_inline:
type: INLINE
props:
algorithm-expression: ds_${id % 3}
ss_s_db_tb_inline:
type: INLINE
props:
algorithm-expression: ss_s_db_tb_${id % 2}
keyGenerators:
snowflake:
type: SNOWFLAKE
- !BROADCAST
tables:
- ss_g0
- !SINGLE
tables:
- ds_0.ss_n0
- ds_2.ss_n1
defaultDataSource: ds_0
- !SQL_TRANSLATOR
type: NATIVE
useOriginalSQLWhenTranslatingFailed: true
4.3 创建数据源所配置的物理库
在使用 config-*.yaml 配置文件启动之前,需要先确保所配置的数据源对应的物理库存在。因而,需要先直连 MySQL 创建这些物理库。
4.3.1 ds_0、ds_1
ds_0、ds_1 分别对应位于同一 MySQL 物理实例上的两个物理库。
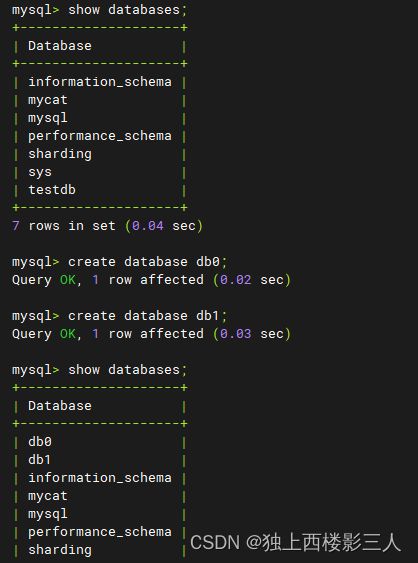
4.3.2 ds_2

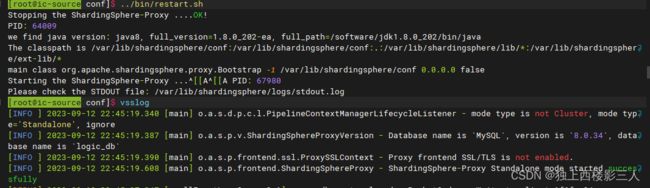
4.4 启动
进入到 Proxy 的安装目录,执行:
$ bin/start.sh
4.5 (可选)准备测试数据
此处按 SQL 语句类型将测试过程用到的 SQL 进行分类。读者可选择下载本文提供的脚本按注释引导执行,或跳过此步按 [5、测试] 中的步骤执行。
一定要注意 SQL 脚本中的注释。
4.5.1 创建逻辑表
本文页首的绑定资源中的 ddl.sql 。
4.5.2 插入测试数据
本文页首的绑定资源中的 insert.sql 。
5、测试
创建 Proxy 会话连接:
$ mysql -utest -ptest -P3407 -hsource -c -Dlogic_db
再分别创建三个直连 MySQL 的会话连接。
5.1 分片表
在逻辑库 logic_db 中执行:
create table if not exists ss_s_db_tb(id int primary key, name varchar(10));
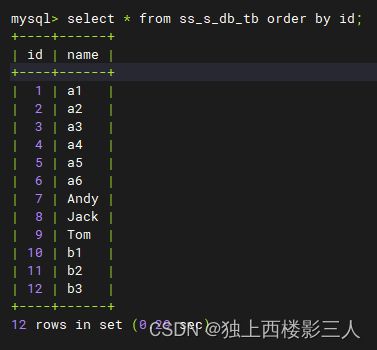
5.1.1 逻辑表 ss_s_db_tb
mysql> select * from ss_s_db_tb order by id;
5.1.2 物理表
1) ds_0 数据源内的物理表
select * from db0.ss_s_db_tb_0 order by id;
select * from db0.ss_s_db_tb_1 order by id;

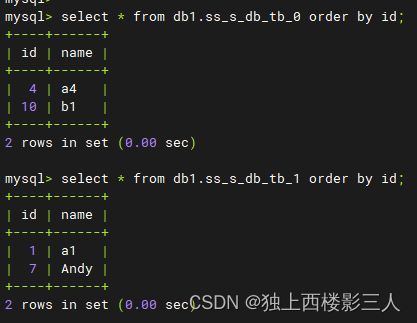
2) ds_1 数据源内的物理表
select * from db1.ss_s_db_tb_0 order by id;
select * from db1.ss_s_db_tb_1 order by id;
3) ds_2 数据源内的物理表
select * from db0.ss_s_db_tb_0 order by id;
select * from db0.ss_s_db_tb_1 order by id;
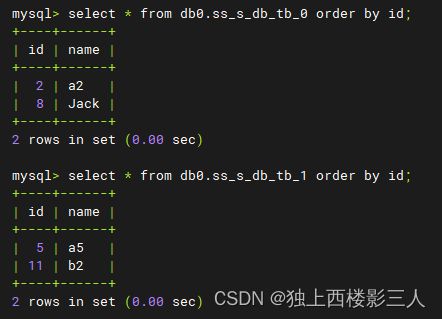
5.1.3 小结
通过以上测试结果可以看出,一共插入12条数据,分库规则为 id%3 ,库内分表规则为 id%2 ,即分3个库,每个库分2张表。总共3*2=6个分片,因而总分片规则等价于 id%6 。所以:
id in (6,12)因id%6 = 0而存储在了ds_0的第一张分片表ss_s_db_tb_0中;id in (1,7)因id%6 = 1而存储在了ds_0的第二张分片表ss_s_db_tb_0中;- 依次类推……
- 最后一个分片,
id in (5,11)因id%6 = 5而存储在了ds_2的第二张分片表ss_s_db_tb_1中。
5.2 广播表
create table if not exists ss_g0(m_id int primary key auto_increment, m_name varchar(40), m_value varchar(40), m_desc varchar(1000));
insert into ss_g0 values(null,'metric 1','1','指标1');
insert into ss_g0(m_name,m_value,m_desc) values('metric 2','2','指标2');
insert into ss_g0 values(3,'metric 3','3','指标3'),(4,'metric 4','4','指标4');
5.2.1 逻辑表 ss_g0
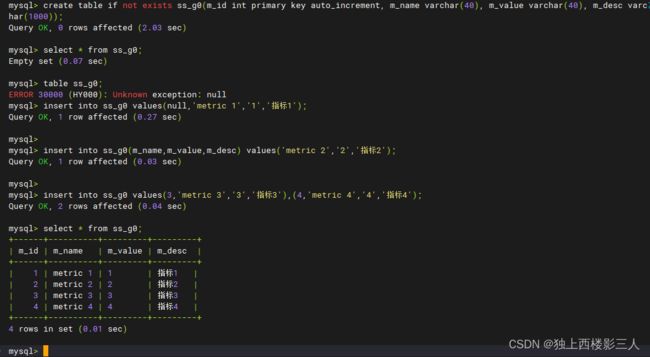
5.2.2 物理表
1) ds_0 数据源内的物理表
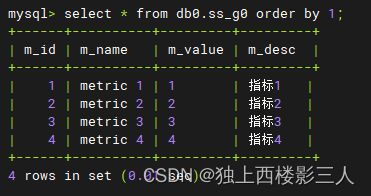
2) ds_1 数据源内的物理表
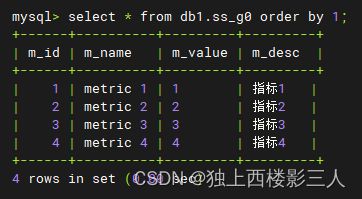
3) ds_2 数据源内的物理表
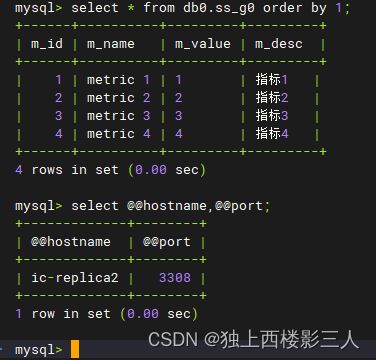
5.2.3 小结
由上可知,广播表符合预期结果,在每个数据源都生成了该表及数据,全局一致。
5.3 普通表(单表)
在 Proxy 实例的逻辑库 logic_db 中执行:
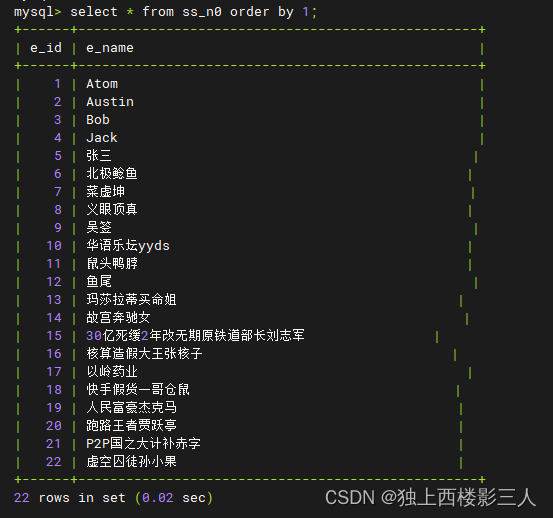
create table if not exists ss_n0(e_id int unique key, e_name varchar(40));
insert into ss_n0 values(1,'Atom'),(2,'Austin'), (3,'Bob'), (4,'Jack'),(5,'张三'), (6,'北极鲶鱼'), (7,'菜虚坤'), (8,'义眼顶真'), (9,'吴签'), (10,'华语乐坛yyds'), (11,'鼠头鸭脖'),\
(12,'鱼尾'), (13,'玛莎拉蒂买命姐'), (14,'故宫奔驰女'), (15,'30亿死缓2年改无期原铁道部长刘志军'), (16,'核算造假大王张核子'), (17,'以岭药业'), (18,'快手假货一哥仓鼠'), (19,'人民富豪杰克马'),\
(20,'跑路王者贾跃亭'), (21,'P2P国之大计补赤字'), (22,'虚空囚徒孙小果');
在 ds_2 对应的 MySQL 实例中执行:
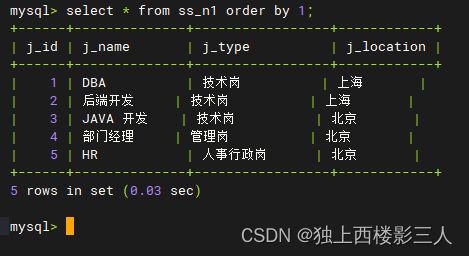
create table if not exists db0.ss_n1(j_id int primary key auto_increment, j_name varchar(40), j_type varchar(20),j_location varchar(200));
insert into db0.ss_n1(j_name,j_type,j_location) values('DBA','技术岗','上海'),('后端开发','技术岗','上海');
insert into db0.ss_n1 values(null,'JAVA 开发','技术岗','北京'), (null,'部门经理','管理岗','北京'), (null,'HR','人事行政岗','北京');
然后,需要执行如下 DistSQL 的 RDL 语句 将该表加载进逻辑库:
load single table ds_2.ss_n1;
5.3.1 逻辑表 ss_n0、ss_n1
1) 在逻辑库创建的 ss_n0
2) 在物理库创建的 ss_n1
5.3.2 物理表
1) ds_0 数据源内的物理表
select * from db0.ss_n0 order by 1;
select * from db0.ss_n1 order by 1;
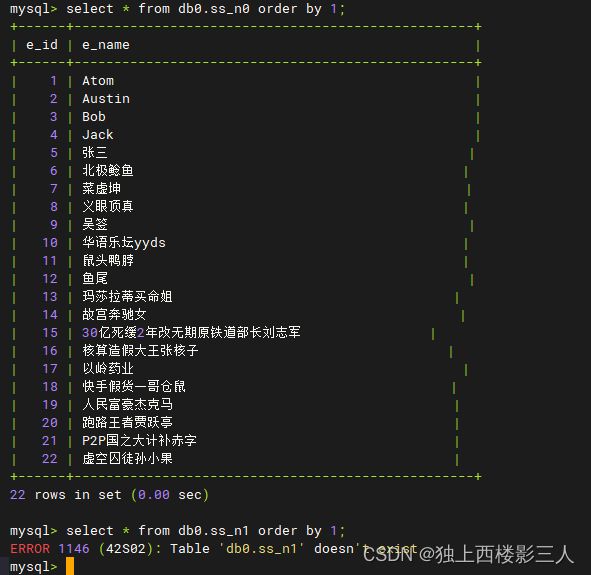
2) ds_1 数据源内的物理表
select * from db1.ss_n0 order by 1;
select * from db1.ss_n1 order by 1;
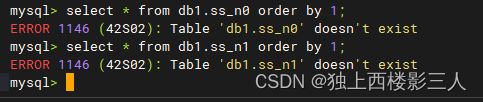
3) ds_2 数据源内的物理表
select * from db0.ss_n0 order by 1;
select * from db0.ss_n1 order by 1;

5.3.3 小结
由上可知,普通表分按创建方式为两种:
- 在逻辑库内创建,存储在默认数据源,例如
ss_n0表,存储在配置的默认数据源ds_0中; - 在某一数据源对应的物理库创建,后加载进逻辑库,例如
ss_n1表。
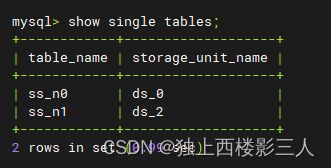
测试结果如预期一样在 ds_0 中创建了 ss_n0 ,在 ds_2 中创建了 ss_n1 ,ds_1 中没有普通表。
show single tables;
6、结论
6.1 总览
ShardingSphere 在数据分片方面支持分片表、广播表、普通表。配置方式支持 YAML 配置文件、DistSQL ,得益于官方文档的完善规范,较 Mycat 2 更容易配置,但在 SQL 解析方面不如 Mycat 2 ,不具备在逻辑库中直接建库、建表,不支持一些 DDL SQL 下发、透传。最简单、最常用的行表达式分片算法不如 Mycat 灵活,无法直接实现分片表的全局唯一下标需求,即每张分片表下标都不一样。
笔者总体使用体验感觉 ShardingSphere 在便捷性方面优于 Mycat 2 。
6.2 分片算法
ShardingSphere 内置提供了多种分片算法,按照类型可以划分为自动分片算法、标准分片算法、复合分片算法和 Hint 分片算法,能够满足用户绝大多数业务场景的需要。此外,考虑到业务场景的复杂性,内置算法也提供了自定义分片算法的方式,用户可以通过编写 Java 代码来完成复杂的分片逻辑。
行表达式分片算法使用 Groovy 的表达式,提供对 SQL 语句中的 = 和 IN 的分片操作支持,只支持单分片键。