小米大模型,重铸AI能力新范式
站在科技变革的交汇点,以智能为核心的技术正掀起新一轮的科技浪潮。浪潮之下,大模型技术让AI发展看到了新的光芒,小米便是浪潮中的逐光者。
8月14日晚,雷军在年度演讲中宣布小米科技战略升级:深耕底层技术、长期持续投入,软硬深度融合,AI全面赋能,总结为公式(软件×硬件)ᴬᴵ。作为首家把AI放在次方地位的科技公司,小米将包括大模型在内的AI技术看作一种生产力,将AI真正镶嵌在业务与产品中,为生产、生活赋能。

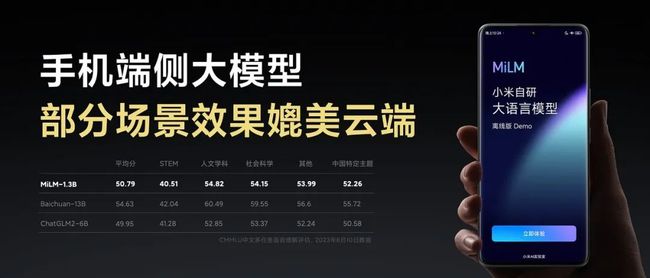
本次演讲中,小米自研大模型正式亮相,雷军宣布小米大模型技术的主力突破方向为“轻量化、本地部署”,让用户在享受安心的数据保护的同时,拥有大模型带来的先进生产力。值得一提的是,小米自研大模型在近日的权威中文评测榜单C-EVAL和CMMLU中,取得同参数量级第一的好成绩;小米自研手机端侧大模型初步跑通,部分场景效果媲美云端。

那什么是大模型?小米为什么要做大模型?小米大模型有哪些独特闪光点?今天,我们来告诉你答案。
01
解码大模型
ChatGPT出现以来,大模型优异的理解能力和生成能力令人惊艳,关于其用途的探索也越来越多。目前看来,很多传统的自然语言处理任务都可以用它来完成,比如搜索、翻译、问答、摘要、信息抽取和分类以及写作等。在日常生活中,所有基于对话的服务,如客服、教育、咨询、导游等,以ChatGPT为代表的大模型都有一定的用武之地。
大模型指参数数量巨大、层次结构复杂的机器学习模型。这些模型通常具有十亿到千亿甚至万亿个参数,通过大量的数据进行训练,提供更高的理解和生成能力。
在小米看来,大模型不仅是指模型参数多、尺寸大,更重要的是代表了一种新的训练范式。我们将其总结为:大数据、大任务、大参数。

- 大数据:指需要用海量的数据去训练,让模型从中自动挖掘出所需的信息。通常采用自监督或者无监督学习方式,无需人工标注就可以提炼规律、学习知识,从而提升模型的眼界。
- 大任务:指学习的目标足够复杂、覆盖面广。这样才能“强迫”模型按照模块化、高类聚、低耦合的方式组织知识点,实现举一反三的泛化能力。
- 大参数:指模型的知识容量。大模型的参数规模越大,模型的表达能力和学习能力也就越强。
在这个范式中,我们认为大数据和大任务是不可或缺的。如果没有大数据,模型不可能学到丰富的常识;如果没有大任务,知识点和技能点不可能在模型中有机高效地组织起来。
02
布局人工智能
全力突破大模型
▍以AI为基石,沉淀技术积累
小米基于对产业和时代的思考与理解,选择对人类文明有长期价值的战略方向,并坚持长期持续的投入。我们已经布局了12个技术领域,99个细分赛道,未来五年(2022-2026)我们至少会投1000亿以上的研发经费。由此构建核心竞争力、牢筑护城河,对人类社会未来的进步发展注入澎湃力量。

AI是未来的生产力,也是小米长期持续投入的底层赛道。小米很早就对人工智能进行布局,2016年小米AI实验室成立,并组建了第一支视觉AI团队,今年4月成立专职大模型团队,历经7年6次扩展,小米人工智能团队已经有3000多人,逐步建立了视觉、语音、声学、知识图谱、NLP、机器学习、多模态等AI技术能力。

成为浪潮之上的角逐者,必须有对技术的沉淀和积累。作为小米AI技术的“试验田”和“弹药库”,小米AI实验室会研发中长期的前沿技术,围绕小米业务做储备,在集团需要的时候输出“弹药”。小米对AI的深刻认识与掌握的技术能力,也有效地赋能了手机、机器人等各个业务板块。
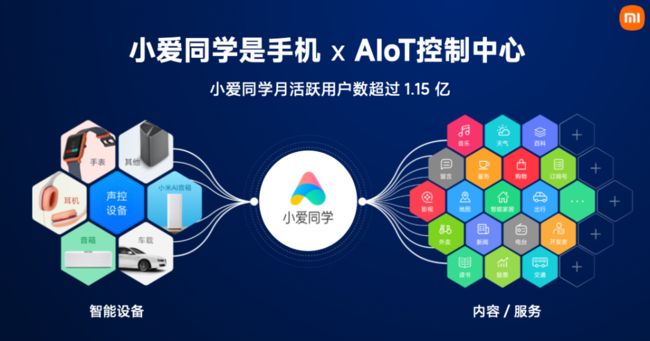
大模型是未来科技的发展趋势,更是下一个人工智能的高地。2021年开始,小米就对大模型的方向特别关注,并开展了对话大模型的预研工作。在闲聊对话场景下,依托于月活超过1.15亿的智能语音助理小爱同学,小米研发了参数规模为28亿的对话模型,达到了当时同等参数规模下业界的最佳效果。这为小米积累了多卡分布式训练的经验,为后续开展大规模语言模型训练奠定了基础。
▍小米大模型:轻量化、本地部署
通用大模型需要海量数据,和巨大的算力,使用成本也很高。面对这种情况,小米如何突围?
小米的机会在设备端。截至2023年一季度,小米AIoT平台已连接设备(不包括智能手机、平板及笔记本电脑)达6.18亿台,是全球规模领先的消费级物联网平台。设备多样,使用场景也各不相同,一个大模型难以兼顾。而我们判断在大多数场景和垂域,可能并不需要那么大的模型。在一个较小的基座模型上,使用业务数据进行深入定制,就应该能达到用户的需求。更进一步,如果把一部分大模型能力下放到端侧,不仅能更好地保护用户隐私、而且有机会在本地实现千人千面的个性化定制。
不盲目追求模型参数规模,而是综合考虑效果、效率与使用成本的均衡,软硬结合,生态连结,这是大模型技术与小米生态结合的最优方案,也是小米为用户提供独特体验的根本保证。因此,“轻量化、本地部署”是小米大模型技术的主力突破方向。

目前,我们自研的13亿参数的端侧模型已经在手机端跑通,部分场景效果媲美60亿模型在云端的运算结果。与早些时候市场上放出的手机端大模型的方案相比,小米会调整模型结构和参数大小,适配各种芯片在内存和算力上的特点,达到功耗、推理速度和生成效果的最佳平衡。
03
布局人工智能
全力突破大模型
▍自有数据更懂小米
数据上,我们自己挖掘整理的训练数据占比达到了80%,其中小米自有的产品和业务数据量达到3TB。因此我们的大模型最懂小米的产品,最懂小米的业务。
▍效率和效果的最佳平衡
结构上,我们根据对Transformer结构的理解,融合了自身的实践经验进行改良;并且充分考虑设备端芯片的特色要求,合理设置模型的宽度和深度,以达到效率和效果的最佳均衡。
▍更多策略更少浪费
训练策略上,采用小米提出的ScaledAdam优化器和Eden学习率调度器,显著提升收敛速度的同时减少了优化器中显存的浪费。由于模型的知识容量有限,需要更精巧地安排训练数据的顺序,使得模型尽可能多地掌握知识点和技能,减少参数的浪费,以此实现“轻量化”。
▍为用户隐私安全保驾护航
模型部署到端侧后,信息不用上传到云端,所有计算都在本地进行,可以从根本上保证用户隐私不被泄露。即使在端云结合的服务框架下,隐私信息会存储在端侧,涉及它们的计算也尽可能在端侧完成。即使偶尔需要使用云端的能力,信息也会经过处理和加密。
04
仰望技术星空
脚踏体验实地
截至2023年8月10日,小米自研的大规模预训练语言模型MiLM-6B,参数规模为64亿,在权威中文评测榜单C-EVAL和CMMLU中位列同等参数规模大模型第一。

在C-Eval评估中,MiLM-6B 的平均分为60.2,总榜单排名第10、同参数量级排名第1。
“C-Eval”是由上海交通大学、清华大学、爱丁堡大学共同构建的一个针对基础模型的综合中文评估套件。它由 13948 道多项选择题组成,涵盖 52 个不同学科和四个难度级别,覆盖人文、社科、理工,及其他专业四个大方向,用以帮助中文社区研发大模型。
在CMMLU评估中,MiLM-6B在Five-shot和Zero-shot 测试中的平均分分别为57.17和60.37,均位列中文向模型第1。
“CMMLU”是一个综合性的中文大模型评估基准,涵盖了从基础学科到高级专业水平的67个主题,涉及自然科学、社会科学、人文、以及常识等,专门用于评估语言模型在中文语境下的知识和推理能力。
通过打榜,验证了我们对特定垂域进行定向增强的技术能够达到怎样的效果,这也是用轻量化模型进行业务定制的必备能力。虽然小米大模型取得了优异的成绩,但我们不会把榜单排名与用户体验画上等号。好成绩的背后,更重要的还是打磨技术、沉淀方法论,将它们运用到产品,提升用户体验才是我们的终极目标。
-
科技应着眼于解决问题,以需求与应用为落点。小米大模型采用“轻量化、本地部署”的方案,能够更好地解决多场景、个性化的用户需求。一方面,大模型本地运行无需担心“弱网、无网”情况,且响应速度快,使用稳定;另一方面,在提供更加个性化服务的同时,也能够更好地保护用户隐私,让技术真正改善用户体验,让成绩真正落地有效。

未来,小米将扩大模型规模,不断探索端云结合、多模态融合的大模型解决方案,与小爱同学、手机操作系统MIUI、IoT、机器人、汽车等业务结合,提升小爱同学的理解能力与智能家居指令的识别能力等,给予用户更加个性化的智能体验,让全球每个人都能享受大模型带来的美好生活。

