CodeCMR:跨模态二进制代码匹配
Motivation
逆向分析任务的问题与难点:
1 伪代码可读性不如源代码,缺少变量名等重要信息。
2 需要大量专家经验设计反编译规则
因此,我们希望可以从二进制代码直接查询源代码
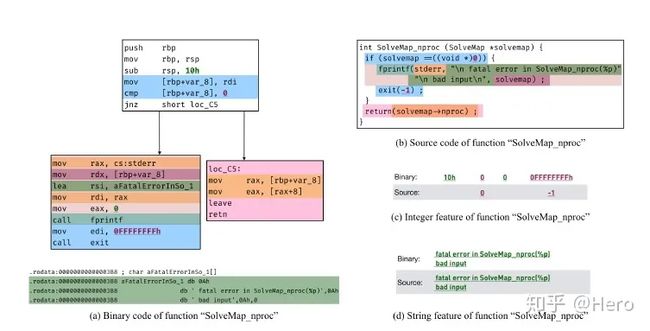
传统的二进制-源代码匹配方法是利用字符串和立即数的特征进行匹配,但其有很多缺点,比如属于粗粒度特征准确率低,且需大量专家设计特征。
因此本文采用跨模态检索框架CodeCMR,将源代码和二进制代码两种模态分别放入特定模式的编码器中,计算成两个向量然后设计损失函数来学习其相似性,进而完成对应的匹配工作。
Method
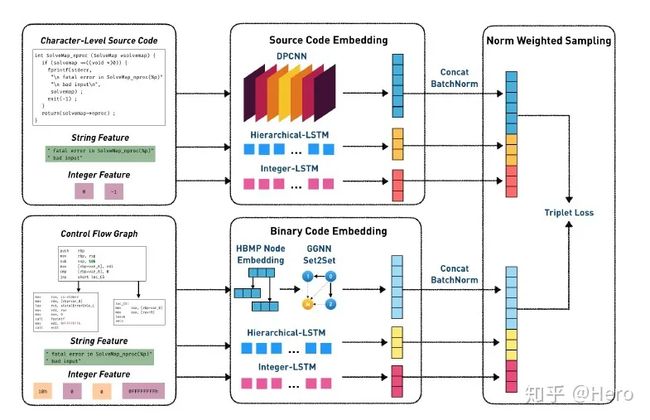
首先来看对于源代码的处理,分别将源代码、字符串、整数经过处理后concat成向量。
DPCNN【2】,DPCNN主要由三部分组成:

Region embedding层(文本区域嵌入层);两个卷积块,可以和pre-activation直接连接;Repeat结构(residual block)。其优点就是引入了Resnet中的skip结构,解决了梯度消失和梯度爆炸的问题。
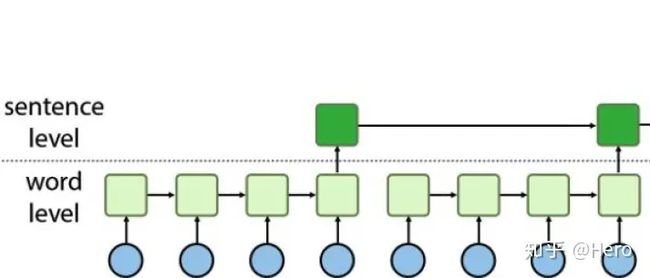
Hierarchical-LSTM【3】跟LSTM的区别是将前一层LSTM的部分节点做综合进入下一层的LSTM节点中进行运算,比如一层LSTM输入是word级别的向量,得到sentence级别的向量表示后, 将sentence级别的输出当做下一层LSTM的输入,最终得到doc级别的输出。这就相当于一个2层的Hierarchical-LSTM。
Interger-LSTM【4】是对LSTM网络针对数字形式的改进,不仅仅考虑数字的token,还考虑数值大小方面的因素。
对于二进制代码的控制流图,分别将二进制流图、字符串、整数经过处理后concat成向量。
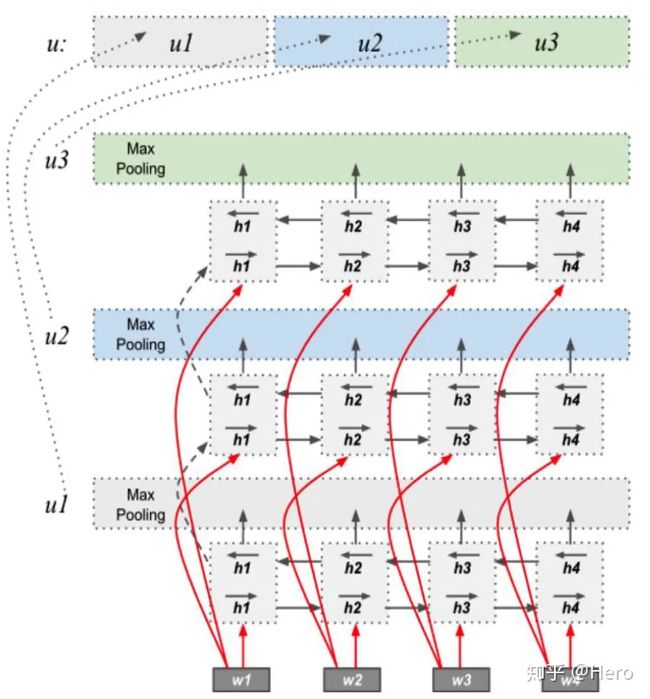
HBMP embedding【5】递归神经网络已被证明是非常有效的学习分布式表示和可以有效地训练自然语言推理任务。它建立在这样一个模型的基础上,提出了一个Bi-LSTM层和max池化层的层次结构,它实现了一个迭代的细化策略。为了提高Bi-LSTM层对输入单词的记忆能力,作者让网络的每一层重新读取输入嵌入,而不是将层堆叠在一个严格的层次模型中。通过这种方式,作者的模型充当了一个迭代的精化架构,它重新考虑每个层中的输入。
Set2set是一种attention的过程,用attention得到一部分信息,然后通过lstm,lstm会根据这次得到的信息和之前已经得到的信息去生成下一次attention的query向量,指导下一次去提取哪部分的信息。
最后解释一下,triplet loss。输入是一个三元组
a: anchorp: positive, 与a是同一类别的样本n: negative, 与a是不同类别的样本
公式是:L = max(d(a, p) - d(a, n) + margin, 0)
- 所以最终的优化目标是拉近
a, p的距离, 拉远a, n的距离 easy triplets: L = 0即d(a, p) +margina, n的距离远hard triplets:d(a, n)semi-hard triplets: d(a, p)margin
Experiment
在二进制-源代码匹配任务上评估模型。作者选择gcc-x64-O0和clang-arm-O3两种组合方法构建两个数据集,每个数据集包含30000个用于训练的源代码-二进制代码对,验证集和测试集的源代码-二进制代码对各10000个。

随机抽样法训练集损失小,验证集损失大。范数加权抽样方法训练集损失大,验证集损失小,召回分数较高。为了进一步研究随机抽样法和范数加权抽样法的比较, 作者绘制了train/valid曲线,以揭示loss的变化。较大的s(s=8和s=10)上进行实验,分数略有下降,但不会太大。所以这意味着s=5是这个任务和这个数据集的最佳选择。

Reference
【1】Yu Z, Zheng W, Wang J, et al. CodeCMR: Cross-Modal Retrieval For Function-Level Binary Source Code Matching[J]. Advances in Neural Information Processing Systems, 2020, 33.
【2】Johnson R, Zhang T. Deep pyramid convolutional neural networks for text categorization[C]//Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2017: 562-570.
【3】Zhou Z. A hierarchical model for text autosummarization[J]. 2016.
【4】Yu Z, Lian J, Mahmoody A, et al. Adaptive User Modeling with Long and Short-Term Preferences for Personalized Recommendation[C]//IJCAI. 2019: 4213-4219.
【5】Talman A, Yli-Jyrä A, Tiedemann J. Sentence embeddings in NLI with iterative refinement encoders[J]. Natural Language Engineering, 2019, 25(4): 467-482.