主编推荐|深度学习和强化学习在组合优化方面有哪些应用?
作者:莫思雨&王晶&王源
2017年阿里巴巴的一篇用深度强化学习求解3维装箱问题的论文引发了深度学习和强化学习在组合优化问题方面应用的深入探讨。一部分先驱的研究者尝试用深度学习和强化学习的角度去看待组合优化问题的求解,相关的前沿探索性研究也逐步展开。单纯的采用基于Search的传统数学优化方法是否有着局限性,基于深度学习和强化学习的Learning to Search方法是否能有着较好的应用前景?本文就带你简单了解一下深度学习和强化学习在组合优化方面的研究进展。
一. 深度学习和强化学习求解组合优化问题思路简介
组合优化问题由于多半属于NP-hard问题,传统的数学优化方法目前很难求到精确解。神经网络是否能帮助组合优化问题的求解一直以来都是一个非常有趣和前沿的话题。回顾神经网络发展历史,早在1982年就有采用Hopfield神经网络来求解TSP问题(旅行商问题)。Hopfield神经网络是一种递归神经网络,从输出到输入均有反馈连接,每一个神经元跟所有其他神经元相互连接,又称为全互联网络。对Hopfield神经网络的研究更是引领了八十年代人工智能研究的复兴。
近些年来深度学习在图片识别等任务上取得了前所未有的效果,强化学习也在AlphoGo上大显神通。那么深度学习和强化学习的突飞猛进的研究成果是否能够助力组合优化问题的求解呢?最近2-3年来在人工智能顶级会议NIPS, ICML 上,关于这方面的探索性的研究也逐渐展露头角。本文先做一个简单的解读,便于研究组合优化的同学深入了解这些先驱性的探索工作。
这里先从宏观上说一下深度学习和强化学习如何帮助求解组合优化问题。
1. 组合优化的序列决策可以由深度学习或强化学习来替代
组合优化问题大多数情况下都是涉及到决策顺序,即序列的决策问题,例如对于TSP问题就是决定以什么顺序访问每一个城市,例如对于Job shop问题(加工车间调度问题)就是决定以什么顺序在机器上加工工件。而深度神经网络里边的递归神经网络恰好可以完成从一个序列到另一个序列的映射问题,因此可以借用递归神经网络来直接求解组合优化问题完全是一种可行的方案。另外一套方案就是采用强化学习,强化学习天生就是做序列决策用的,那么组合优化问题里边的序列决策问题完全也可以用强化学习来直接求解,其难点是怎么定义state, reward。
2. 求解组合优化的经典算法可以由强化学习帮助指导算法策略
分支定界算法是一种最常见的求解整数规划问题的方法。关于分支定界算法可以参考这篇:【学界】混合整数规划/离散优化的精确算法--分支定界法及优化求解器 。分支定界算法的效率取决于从哪个变量 branch 和 node selection两个因素,如果branch 和 node selection的策略比较好,那么分支定界算法可以很快的剪枝或者可以很快的得到比较好的界,就可以大大提升分支定界算法的效率。目前对于 branch 和 node selection的策略还没有公认的太好的方法。传统的方法基本上都是一些简单的启发式规则,那么强化学习可以帮助我们有效的给出一个 branch 和 node selection的策略。这样的一种策略也被称为Learning to search,有别于以往单纯的基于Search的传统优化方法,Learning to search还是在优化过程中引入学习的概念帮助更加有效的搜索最优解。
2014年在NIPS会议上,文章[5]是比较早的一个用机器学习算法来学习分支定界算法里边的 branch 和 node selection的策略的。到了2017年,加拿大蒙特利尔的Andrea Lodi还写了一个survey [5],里边总结了各种关于Learning to search的研究的进展情况,写得非常全面。目前这方面的研究也处于探索中,值得我们有所期待。
二. 专为组合优化求解而诞生的神经网络 -- Pointer Network 介绍
前面谈到了组合优化问题很多时候就是进行序列决策,而Pointer Network就是非常适合求解组合优化问题的一种神经网络。Pointer Network(后面简称Ptr-Net)是基于Sequence-to-Sequence网络生成的一种新的网络架构。Ptr-Net与Sequence-to-Sequence类似,都是解决从一个序列到另一个序列的映射问题,不同的是Ptr-Net针对的序列问题更加特殊:输出序列的内容与输入序列的内容完全一致,只是序列的顺序发生了改变。这种问题在实际中常见的应用就是组合优化问题,因此Ptr-Net首次建立了神经网络与组合优化问题的联系。
下面我们简单介绍一下Ptr-Net的基本原理,这里不涉及公式推导,若感兴趣,可以参看论文:https://arxiv.org/pdf/1506.03134.pdf
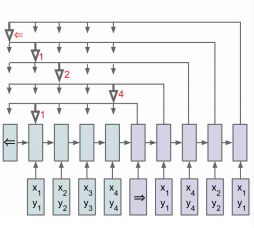
相信对深度学习有一定了解的同学对Sequence-to-Sequence模型并不陌生,它利用一个RNN将输入映射为一个嵌入(embedding),在利用另一个RNN将嵌入映射成为输出,这两个RNN我们分别称之为encoding和decoding。然而在实际这种结构忽略了一个十分重要的问题:输出序列每个元素都与输入序列的一个或多个元素存在某种联系。注意力机制(Attention Machanisim)正是为了解决这一问题而被提出,在计算输出序列时,它会通过某种方式得到该输出序列某一个位置的元素与输入序列每一个位置关联的权重,然后将输入序列与该权重以一定的方式组合来影响输出。Ptr-Net正是利用了注意力机制解决了对输入序列排序的问题。通过注意力机制,可以计算出当前输出与输入序列关系最大的元素,那么我们就将输入序列的元素作为该输出元素,每一个输出元素都像有一个指针一样指向输入元素,Pointer Network因此得名。需要注意的是,每个输入元素只能被一个输出元素所指,这样就避免了输入元素的重复出现,下图给出Ptr-Net的基本结构图:
三. 相关资料汇总与点评
关于深度学习和强化学习在组合优化的应用这里无法一一对每一种方法进行详细的介绍。相信通过前两小节的科普,您已经对这个研究领域有了初步的认识。如果想进行更深的研究和探讨,本文收集了近年来关于深度学习和强化学习在组合优化问题求解上的一些比较关键的资料,并对其进行了简单的点评和概括,方便有兴趣的童鞋进一步深入了解。
1. Pointer Network:
https://arxiv.org/abs/1506.03134
这篇是后面几篇的基础。Pointer Network是脱胎于Google提出的Sequence-to-Sequence的网络结构。先把数据导入Encoder,再通过Decoder返回指针指向Encoder输出的位置或者序号,顾名Pointer Network。
2. Neural combinatorial optimization with reinforcement learning:
https://arxiv.org/pdf/1611.09940.pdf
代码实现参考:
https://github.com/pemami4911/neural-combinatorial-rl-pytorch
higgsfield/np-hard-deep-reinforcement-learning
Google Brain的这篇借用pointer network加上attention mechanism,采用了policy gradient和actor-critic进行训练求解TSP问题,在文中也求解了knapsack的问题。以个人实现的经验来说,moving average的效果比actor-critic训练更稳定一些,actor-critic的收敛速度更快,但是沿用文中参数的训练,结果不稳定。
3. Reinforcement learning for solving vehicle routing problem:
https://arxiv.org/pdf/1802.04240.pdf
代码实现参考:
mveres01/pytorch-drl4vrp
Leigh University发的这篇的基础是前面两篇。因为TSP和VRP问题其实对输入数据的顺序不敏感,所以文中简化的pointer network的encoding过程,直接进行embedding,因此也采用了不同的Attention方式进行Decoder。该文主要延伸Pointer Network到解VRP问题,也解了TSP问题,和之前的进行了对比,结果和效率上都有所提升。
4. Learning Combinatorial Optimization Algorithms over Graphs:
https://arxiv.org/abs/1704.01665
arxiv.org https://arxiv.org/abs/1704.01665
作者的github:
Hanjun-Dai/graph_comb_opt
https://github.com/Hanjun-Dai/graph_comb_opt
这篇和之前的Pointer Network不同,作者把TSP问题当作Graph来处理,先graph embedding的思路(structure to vector),然后采用reinforce算法进行训练。从small scale training transfer到large scale表现也还不错。作者是用c++写的,后来也发了pytorch版本,但是底层还是c++。我用pytorch实现了一下,但是原文中graph embedding也是属于训练的部分,在pytorch的实现中涉及多重graph的backward。如果有深入了解的,可以交流一下。
5. Attention: Learn to solve routing problems!
https://openreview.net/pdf?id=ByxBFsRqYm
原作者的github:
wouterkool/attention-tsp
https://github.com/wouterkool/attention-learn-to-route
ICLR2019的一篇。这篇的整体思路就是大举使用了Attention机制,建立了求解组合优化问题的Attention Model。Attention的基础来源于Vaswani的Attention is all you Need. 这篇涉及的问题包罗万象,求解了各种tsp和vrp变种,以及其它组合优化问题,可谓Attention在组合优化问题上好好利用了一把。
6. 仓储优化中的beer game问题:
https://arxiv.org/pdf/1708.05924.pdf
文中用deep reinforcement learning的方法,分别对4个agent(manufacturing, distributor, warehouse, retailer) 建立network,然后用一个feedback scheme去让agent向一个目标前进。主要使用在仓储补货的一个游戏中。
当然还有很多其他学者的工作,这里只是列举一下案例。TSP和VRP问题用深度学习的求解思路主要是encoder + decoder,encoder和decoder可以结合很多Attention的机制。但是当前深度学习或者深度强化学习求解组合优化问题局限于一些简单的场景,而且训练好的模型可扩展性差,在实际运用中还有待商榷。如有相关研究的同学,可以一起交流一下。个人github: jingw2 - Overview
https://github.com/jingw2
四. 总结
关于深度学习和强化学习求解组合优化问题的研究目前还处于一个探索阶段,必须承认的是目前的这些研究思路比较新奇,但是就当下的情况来看短期内难以撼动传统数学优化和组合优化的方法。
深度学习,强化学习并非万能的灵药,但学科的交叉融合是一个必然的趋势,对于学习传统组合优化和数学优化的研究者应该持有一个乐观的态度去做一些全新的交叉研究的尝试,对于深度学习,强化学习的研究来说也可以尝试把战场从图像识别,自然语言处理上转移到组合优化问题上来,帮助组合优化问题更好的求解。
注:本文第一部分和第四部分由 运筹OR副主编 王源创作,第二部分作者 莫思雨,第三部作者 王晶(斯坦福大学硕士,现任某厂算法工程师,负责实时调度等算法和模型开发),其中第三部分来自
https://www.zhihu.com/question/43610101/answer/586741755
参考文献:
[1] Hu H, Zhang X, Yan X, et al. Solving a new 3d bin packing problem with deep reinforcement learning method[J]. arXiv preprint arXiv:1708.05930, 2017.
[2]Khalil E B. Machine Learning for Integer Programming[C]//IJCAI. 2016: 4004-4005.
[3]He H, Daume III H, Eisner J M. Learning to search in branch and bound algorithms[C]//Advances in neural information processing systems. 2014: 3293-3301.
[4]Comments on: On learning and branching: a survey
[5]Lodi A, Zarpellon G. On learning and branching: a survey[J]. TOP, 2017: 1-30.
[6]Dai H, Khalil E B, Zhang Y, et al. Learning Combinatorial Optimization Algorithms over Graphs[J]. arXiv preprint arXiv:1704.01665, 2017.