flink java 并行度_Flink并行度优先级_集群操作常用指令_运行组件_任务提交流程_数据流图变化过程...
Flink并行度优先级(从高到低)
sum(1).setParallelism(1)
env.setParallelism(1)
ApacheFlinkDashboard任务添加并行度配置
flink-conf.yaml并行度配置
注: 处理输入输出时, 并行度默认为 1
Flink集群常用指令
提交任务
run: 代表执行; c: 指定入口类; p: 并行度; host, post: 主机地址端口
flink run -c com.test.StreamWordCount -p 1 /home/Project/Flink/target/FlinkStudy-1.0-SNASHOT.jar --host localhost --port 7777
取消任务
flink cancel jobId
列出所有 jobId
flink list
Flink部署
Standalone 模式: TaskManager固定, 所有任务共享 Dispatcher 和 ResourceManager, 当任务满了, 剩余任务只能阻塞等待.
Yarn 模式:
a. Session 模式: 与Standalone模式一样, 不同点在于 TaskManager 进行动态分配, 提高集群扩展能力.
b. Job 模式: 每个提交的任务单独有一份 Dispatcher, ResourceManager, 适用于特别大的任务, 且每个任务执行耗时很长. 注: job模式下, 不用启动 yarn-session, 直接 flink run -m yarn-cluster -c提交.
Kubernetes 模式
此处具体部署方式, 未贴出, 详情可见官网说明.
Flink运行组件
JobManager: 作业管理器, 负责作业管理
控制提交的 job 执行, JobManager 向 ResourceManager 请求 TaskManager 上的 slot, 获取到足够资源, 将该任务的执行图分发到运行的 TaskManager 上, 运行中, JobManager 负责所有需要中央协调的操作(例: checkpoints 协调, 存盘, 故障检测)
TaskManager: 任务管理器, 负责干活
Flink 中会有多个 TaskManager 执行, 且每个 TaskManager 都包含一定数量的 slot, slot 限制了 TaskManager 能够执行的任务数量.
TaskManager启动后, 向 ResourceManager 注册 slot, 根据 ResourceManager 调配, 将 slot 提供给 JobManager 调用, JobManager 想 slot 分配任务执行.
任务在各个执行阶段执行可能使用不同的 slot 执行, 在同一任务下, 不同的 TaskManager 可进行数据交换.
ResourceManager: 资源管理器, 分发资源, 调配 slot
管理 TaskManager 的 slot.
在不同的环境下(Yarn, K8s, Standalone), 提供不同的 ResourceManager.
JobManager 申请资源, ResourceManager 将空闲的 slot 分配给 JobManager, 若 slot 不足, 向资源提供平台发起会话, 提供满足的容器
Dispatcher: 分发器
为应用提交提供一个 REST 接口, 也会启动一个 webUI 便于展示提交的任务, 该组件在架构中可以是非必需的. 任务被提交时, 将给任务移交给 JobManager
任务提交流程
抽象模式的任务提交流程
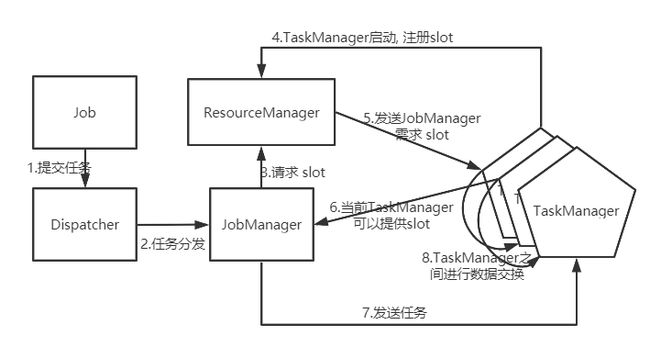
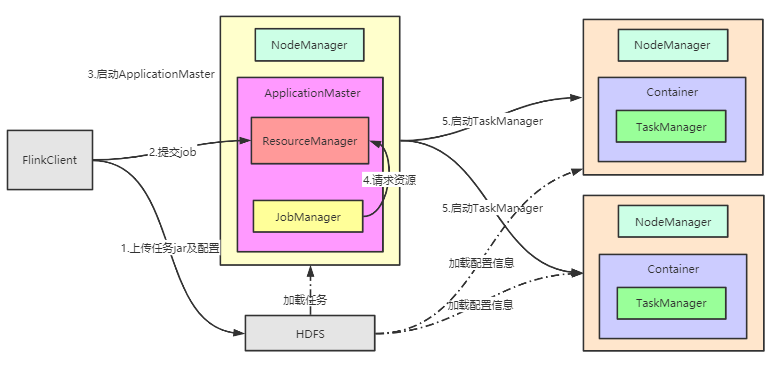
Yarn模型下的任务提交
任务调度原理
任务调度流程:
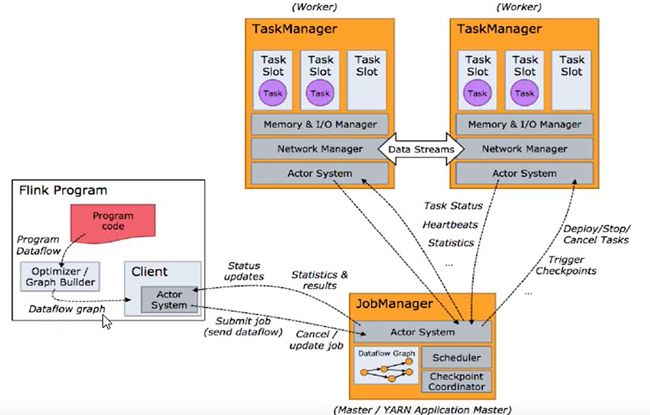
并行度(Parallelism): 执行算子的子任务个数; 所有算子中最大并行度就是整个 Stream 并行度.
TaskManager, Slots的任务调度: Flink 允许子任务共享 slot(不同任务的子任务也能共享), 由于可以共享, 一个 slot 可保存整个作业流程.
子任务不共享, 如下图:
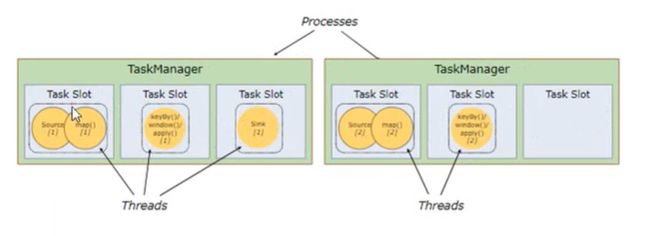
子任务共享 slot, 一个 slot 保存一个工作流程, 如下图, 这种情况可极大提高任务并行度
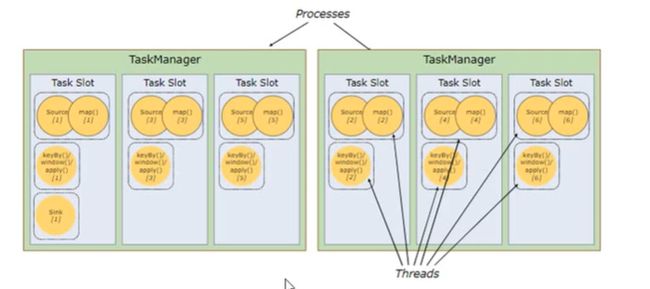
代码设置不同子任务共享一个 slot, 代码如下, 此时 有 2 个 slot, default 和 A, default 处理输入流, A 处理 flatMap 和 sum
//输入流未设置 slot 组, 使用 default.
DataStreamSource source = env.socketTextStream("localhost", 7777);
DataStream> resultStream =
source.flatMap(new FlatMapFunction>() {
public void flatMap(String value, Collector> out) throws Exception {
String[] words = value.split("\\W+");
for (String s : words) {
out.collect(new Tuple2(s, 1));
}
}
// flatMap 与 sum 求和共享一个 slot
}).slotSharingGroup("A").keyBy(0).sum(1).slotSharingGroup("A");
数据流(DataFlow)
所有的 Flink 程序都由 3 部分组成: Source(数据读取), Transformation(数据加工), Sink(输出)
Flink 上运行程序都会被映射为 DataFlow, 一个 DataFlow 由一个或多个 source 开始, sink 结束.
大部分情况, 程序中的 transformation 与 DataFlow 的 operator 一一对应.
数据流图变化过程
StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图
StreamGraph: 根据 Stream API 生成的程序拓扑结构.
JobGraph: StreamGraph 优化得到(优化措施: 将多个符合条件的节点合并为一个节点), 提交给 JobManager 的数据结构.
ExecutionGraph: JobManager 根据 JobGraph 生成 ExecutionGraph(JobGraph 的并行版本)
物理执行图: JobManager 根据 ExecutionGraph 对 Job 进行调度, 在各个 TaskManager 上部署 Task 后形成的, 非具体数据结构.
例如: 单词计数数据流执行图变化过程
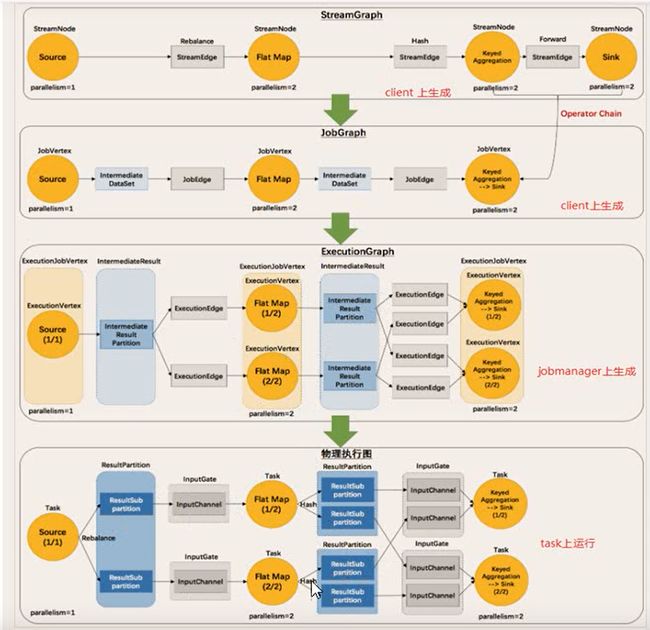
算子合并
数据传输形式
一个程序中, 不同算子存在不同并行度
算子之间传输数据模式: one-to-one, redistributing
one-to-one: 不会打乱元素, 分区顺序, 例如: map, filter, flatMap
redistributing: stream 分区会改变(数据下游存在多个并行分区, 轮询/随机方式往下游发送数据), 例如: keyBy 基于 hashCode 重分区, broadcast, rebalance 会随机重新分区.
任务链
Flink 使用任务链将多个相同并行度的 one-to-one 操作合并, 使其构成一个 task, 之前的算子操作变为 subTask
并行度相同, one-to-one 操作, 且在同一个 slot 共享组, 三者是必须的.
注: 如果不想算子合并, 可调整算子间并行度, 设置重分区, 或在算子间添加 disableChaining()方法
本文地址:https://blog.csdn.net/qq_40845344/article/details/112554351
如您对本文有疑问或者有任何想说的,请点击进行留言回复,万千网友为您解惑!