计算机组成原理--数据表示
目录
1、机器数及特点
1.1 机器内的数据表示
1.1.1.原码
1.1.2. 反码
1.1.3. 补码
1.2 常见机器数的特点
2、定点数与浮点数据表示
2.1 定点数据表示
2.2 浮点数据表示
2.3 补充:小数的二进制表示
3、数据校验的基本原理
3.1 必要性:
3.2 基本原理
3.2.1 码距:
3.2.2 码距与检错或纠错能力的关系
3.2.3 选择码距要考虑的因素
4、奇偶校验
4.1 基本原理
4.2 特点
4.3 改进的奇/偶校验
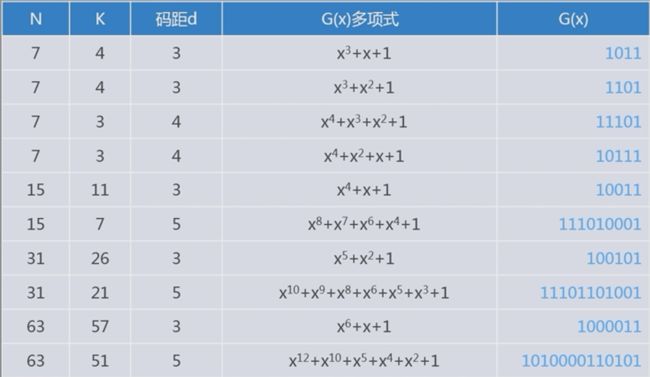
5、CRC校验及实现
5.1 基本原理
5.2 模2运算规则
5.3 CRC的编码方法
5.4 CRC的检错与纠错
6、海明校验及实现
6.1 基本原理
6.2 举例
1、机器数及特点
目的:组织数据,方便计算机硬件直接使用
因素:
- 支持的数据类型;
- 能表示的数据范围;
- 能表示的数据精度;
- 存储和处理的代价;
- 是否有利于软件的移植等……
1.1 机器内的数据表示
真值: 符号用“ + ”、“ - ”表示的数据表示方法。
机器数: 符号数值化的数据表示方法,用0、 1表示符号。
三种常见的机器数: 设定点数的形式为X0,X1 X2 X3... Xn
1.1.1.原码
原码就是符号位加上真值的绝对值,即用第一位表示符号,其余位表示值。比如:如果是8位二进制:
[+1]原= 0000 0001
[-1]原= 1000 0001
第一位是符号位,因为第一位是符号位,所以8位二进制数的取值范围就是:(即第一位不表示值,只表示正负。)
[1111 1111 , 0111 1111]
即
[-127 , 127]
原码是人脑最容易理解和计算的表示方式。
1.1.2. 反码
反码的表示方法是:
正数的反码是其本身;
负数的反码是在其原码的基础上,符号位不变,其余各个位取反。
[+1] = [0000 0001]原= [0000 0001]反
[-1] = [1000 0001]原= [1111 1110]反
可见如果一个反码表示的是负数,人脑无法直观的看出来它的数值。通常要将其转换成原码再计算。
1.1.3. 补码
补码的表示方法是:
正数的补码就是其本身;
负数的补码是在其原码的基础上,符号位不变,其余各位取反,最后+1。(也即在反码的基础上+1)
[+1] = [0000 0001]原= [0000 0001]反= [0000 0001]补
[-1] = [1000 0001]原= [1111 1110]反= [1111 1111]补
对于负数,补码表示方式也是人脑无法直观看出其数值的。通常也需要转换成原码再计算其数值。
1.2 常见机器数的特点
原码:
- 表示简单:[X]原 = 2^n - X
- 运算复杂 运算位不参加运算,要设置加法、减法
- 0的表示不唯一
反码:
- 表示相对原码复杂 [X]反 = 2^(n+1) + X - 1
- 运算相对简单:符号位参加运算,只需设置加法器,但符号位的进位为需要加到最低位
- 0 的表示不唯一
补码:
- 表示相对原码复杂: [X]补=2^(n+1)+X
- 运算简单:只需设置加法器。
- 0的表示唯一
- 补码中模的概念( 符号位进位后所在位的权值)
移码:
- 移码表示浮点数的阶码, IEEE754中阶码用移码表示。
- 设定点整数X的移码形式为XoX1Xx2X...Xn则移码的定义是:
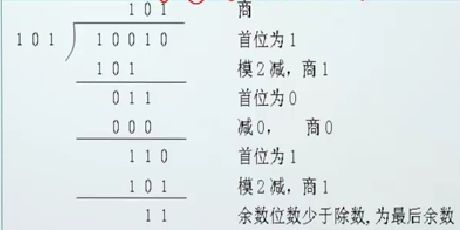
[X]移 = 2"+ X -2^n 具体实现:不管正负数,只要将其补码的符号位取反即可 把数的范围和精度分别表示的一种数据表示方法。 浮点数的使用场合 当数的表示范围超出了定点数能表示的范围时。 (1)格式(一般格式) 不足:不同系统可能根据自己的浮点数格式从中提取不同位数的阶码 (2)IEEE 754格式 与上述IEEE754格式相对应的32位浮点数的真值可表示为: N = (-1)^5 x 2(E - 127) x 1.M 随E和M的取值不同,IEEE754浮点数据表示具有不同的意义 例:将十进制数 -12.75转换成32位IEEE754格式浮点数的二进制格式。 求解思路: 将它们组合起来,得到IEEE 754表示的单精度浮点数为:11000001010011000000000000000000 以0.75为例: 0.75 x 2 = 1.5 …… 1 0.5 x 2 = 1.0 …… 1 直到小数部分为0. 所以(0.75)10 = (0.11)2 同理,计算二进制数 0.11 的进制数: 1 * 2^(-1) + 1 * 2(-2) = 0.75 小数第一位从2^(-1)次方开始,依次类推。 奇校验检错码:(1的个数为奇数个) 偶校验检错码:(1的个数为偶数个) 双向奇偶校验 方块校验 垂直水平校验 a) 加/减运算(异或运算,加不进位,减不借位) 0+0=0,0+1=1, 1+0=1,1+1 =0 b) 模2除法 按模2减,求部分余数,不借位。 c) 上商原则 ①部分余数首位为1时,商为1 ,减除数; ②部分余数首位为0时,商为0 ,减0 ③当部分余数的位数小于除数的位数时,该余数即为最后余数。 (1) 根据待校验信息的长度k,按照k+r≤2^r- 1确定校验位r的位数 如对4位信息1100进行CRC编码,根据4+r≤2^r- 1 得 rmin= 3 (2) 根据r和生成多项式的选择原则,选择位数为r +1的生成多项式G(X)= 1011 (3) 进行下列变化 即: 将待校验的二进制信息Q(X)逻辑左移r位得到Q(X)' (4)对Q(X)'按模2运算法则除G(x) ,求CRC编码中的r位校验信息 (5)用得到的余数替换Q(X)' 的最后r位即可得到对应的CRC编码 接收方利用G(X)对收到的编码多项式做模2除运算 余数为0,表示没出错 余数不为0,说明出错 编码不同数位出错对应的余数 例题 1 假定要传输的数据长度为10位,对每个数据块进行CRC校验,根据CRC校验规则,要能检测并纠正一位错误,对应的CRC码的总位数为( D )(单选) 2 假定要传输的数据长度为10位,对每个数据块进行CRC校验,根据CRC校验规则,要能检测并纠正一位错误,对应的CRC码的总位数为( C )(单选) 3 设计待校验的信息为8位,假定传输中最多只发生一位错误,采用CRC校验时,生成多项式的二进制位数至少需要 (C) (单选) 4 设待校验的信息长度为 K 位, 生成多项式为G(X),下列关于CRC校验的描述中正确的是( BD ) (多选) 1) 设k + r位海明码从左到右依次为第1 , 2 , 3 , ....,k+r位 1 r位校验位记Pi(i=1,2,, ..,r) ,分别位于k +r位海明编码的第2^(i-1) (i=1, 2, ..r)位上,其余位依次放置被校验的数据位; 2)(7 , 4)海明校验码中校验位和被校验信息位的排列如下: 3)Hj位的数据被编号小于j的若干个海明位号之和等于j的校验位所校验,如: 由此可采用偶校验计算出P1 -- P4四个校验位的值! 4)设置指错字G4G3G2G1 G4G3G2G1为0则表明无错误,反之指出出错位的海明码位号。 设被传送的信息b1b2b3b4b5b6b7 = 101 1000,采用偶校验; 则: P1=b1⊕b2⊕b4⊕b5⊕b7=1⊕0⊕1⊕0⊕0=0 P2=b1⊕b3⊕b4⊕b6⊕b7=1⊕1⊕1⊕0⊕0=1 P3=b2⊕b3⊕b4=0⊕1⊕1=0 P4=b5⊕b6⊕b7=0⊕0⊕0=0 得到的海明编码为H = 01 1001 1 000 0 特点:2、定点数与浮点数据表示
2.1 定点数据表示
. 可表示定点小数和整数.表现形式:
2.2 浮点数据表示

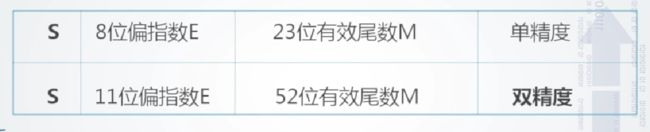
127 ,双精度为1023,将浮点数的阶码值变成非负整数,便于浮点数的比较和排序。
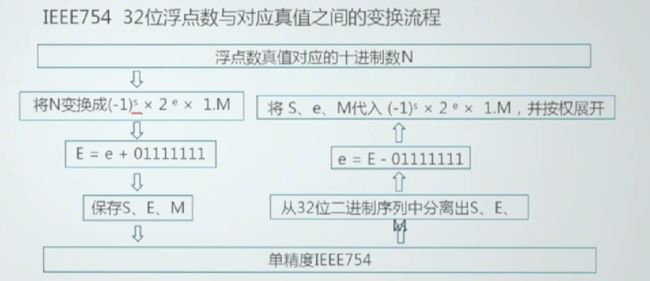
2.3 补充:小数的二进制表示
3、数据校验的基本原理
3.1 必要性:
3.2 基本原理
3.2.1 码距:
3.2.2 码距与检错或纠错能力的关系
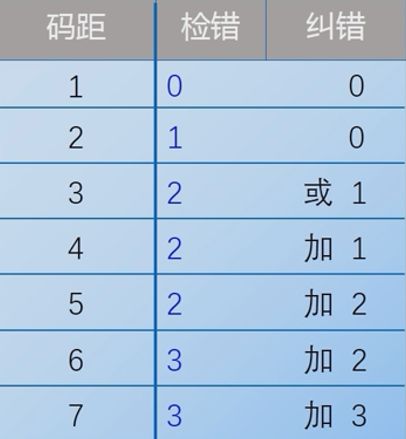
3.2.3 选择码距要考虑的因素

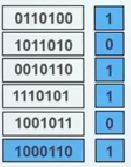
4、奇偶校验
4.1 基本原理

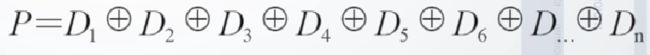

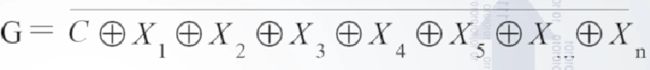
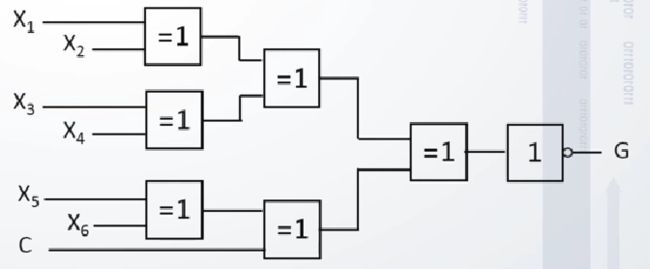
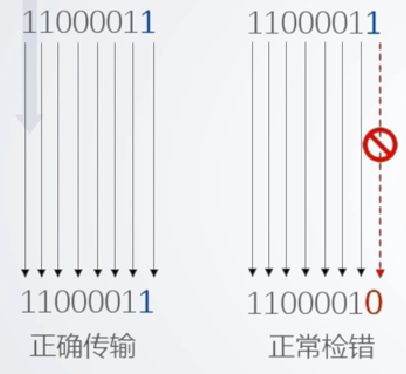
![]()
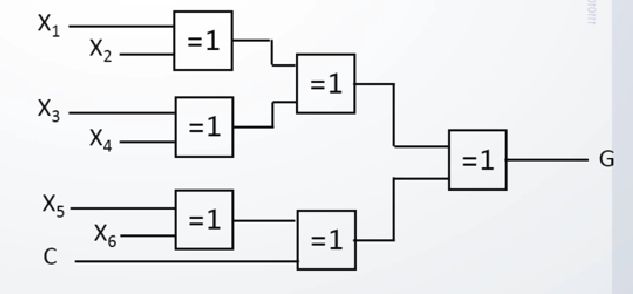
4.2 特点

4.3 改进的奇/偶校验

5、CRC校验及实现
5.1 基本原理

5.2 模2运算规则
5.3 CRC的编码方法
![]()
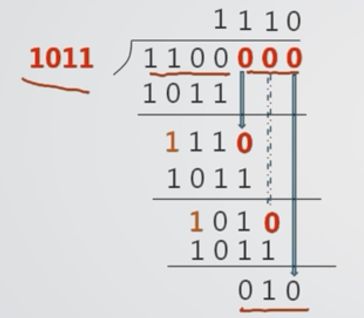

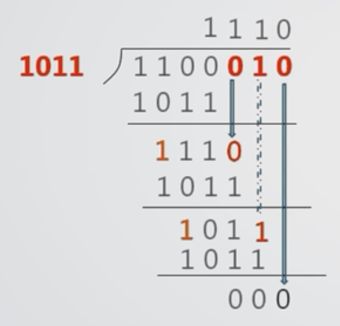
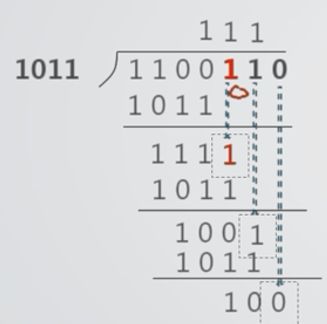
5.4 CRC的检错与纠错
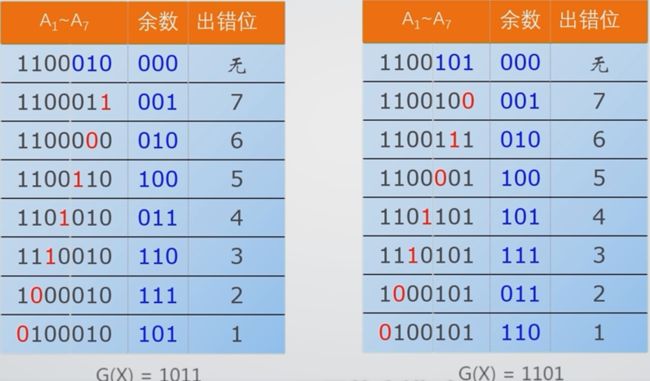
6、海明校验及实现
6.1 基本原理





6.2 举例
