数据结构与算法:树
目录
树
定义
结构
二叉树
定义
结构
形式
满二叉树
完全二叉树
存储
链式存储结构
数组
孩子节点
父节点
应用
查找
维持相对顺序
遍历
深度优先遍历
前序遍历
中序遍历
后序遍历
广度优先遍历
层序遍历
二叉堆
定义
自我调整
操作
插入加点
删除节点
构建二叉堆
代码实现
优先队列
特点
实现
入队操作
出队操作
树
在实际场景中,有许多逻辑关系并不是简单的线性关系,常常存在一对多、多对多的关系;其中树和图就是典型的非线性数据结构。
定义
树是n(n >=0)个节点的有序集合。当n=0时,称为空树,空树特点:有且仅有一个特定的称为根的节点;当n>1时,其余节点可分为m(m>0)个互不相交的有限集,每一个集合本身又是一个树,并称为根的子树
结构

节点1是根节点;节点5、6、7、8、9是树的末端,没有“孩子”,被称为叶子节点。图中的虚线部分,是根节点1的其中一个子树。
树的结构从根节点到叶子节点,分为不同的层级。从一个节点的角度来看,它的上下级和同级节点关系如下:

节点4的上一级节点,是节点4的父节点;从节点4衍生出来的节点,是节点4的孩子节点;和节点4同级,由同一个父节点衍生出来的节点,是节点4的兄弟节点;
树的最大层级数,称为树的高度或深度。
二叉树
定义
二叉树是数的一种特殊形式。这种树的每个节点最多有两个孩子节点(最多两个,可以是1个或者0个)。
结构

二叉树节点的两个孩子节点,一个被称为左孩子,一个被称为右孩子。这两个孩子节点的顺序是固定的,就像人的左手就是左手,右手就是右手,不能够颠倒或混淆。
形式
二叉树还有两种特殊形式,一个叫作满二叉树,另一个叫作完全二叉树
满二叉树
一个二叉树的所有非叶子节点都存在左右孩子,并且所有叶子节点都在同一层级上,那么这个树就是满二叉树;满二叉树的每一个分支都是满的。

完全二叉树
对一个有n个节点的二叉树,按层级顺序编号,则所有节点的编号为从1到n。如果这个树所有节点和同样深度的满二叉树的编号为从1到n的节点位置相同,则这个二叉树为完全二叉树

二叉树编号从1到12的12个节点,和前面满二叉树编号从1到12的节点位置完全对应。因此这个树是完全二叉树。
完全二叉树的条件没有满二叉树那么苛刻:满二叉树要求所有分支都是满的;而完全二叉树只需保证最后一个节点之前的节点都齐全即可
存储
数据结构可以分为物理结构和逻辑结构。二叉树属于逻辑结构,它可以通过多种物理结构来表达;
二叉树可以用到链式存储结构和数组两种物理存储结构来表达
链式存储结构
链式存储是二叉树最直观的存储方式;
链表是一对一的存储方式,每一个链表节点拥有data变量和一个指向下一节点的next指针;二叉树稍微复杂一些,一个节点最多可以指向左右两个孩子节点,所以二叉树的每一个节点包含3部分:
1.存储数据的data变量
2.指向左孩子的left指针
3.指向右孩子的right指针

数组
使用数组存储时,会按照层级顺序把二叉树的节点放到数组中对应的位置上。如果某一个节点的左孩子或右孩子空缺,则数组的相应位置也空出来,可以更方便地在数组中定位二叉树的孩子节点和父节点

使用数组存储时,会按照层级顺序把二叉树的节点放到数组中对应的位置上。如果某一个节点的左孩子或右孩子空缺,则数组的相应位置也空出来。这样可以更方便地在数组中定位二叉树的孩子节点和父节点。
孩子节点
计算:一个父节点的下标是parent,那么它的左孩子节点下标就是2×parent +1;右孩子节点下标就是2×parent + 2。
父节点
计算:一个左孩子节点的下标是leftChild,那么它的父节点下标就是(leftChild-1)/ 2;
对于一个稀疏的二叉树来说,用数组表示法是非常浪费空间的
应用
二叉树包含了很多的特殊形式,每一种形式都有自己的作用,但是最主要的应用还在于查找操作和维持相对顺序两方面。
查找
二叉树的树形结构使它很适合扮演索引的角色。
特殊的二叉树:二叉查找树,主要的作用就是进行查找操作,在二叉树的基础上增加了条件:
1.如果左子树不为空,则左子树上的所有节点的值均小于根节点的值
2.如果右子树不为空,则右子树上的所有节点的值均大于根节点的值
3.左、右子树也都是二叉查找树
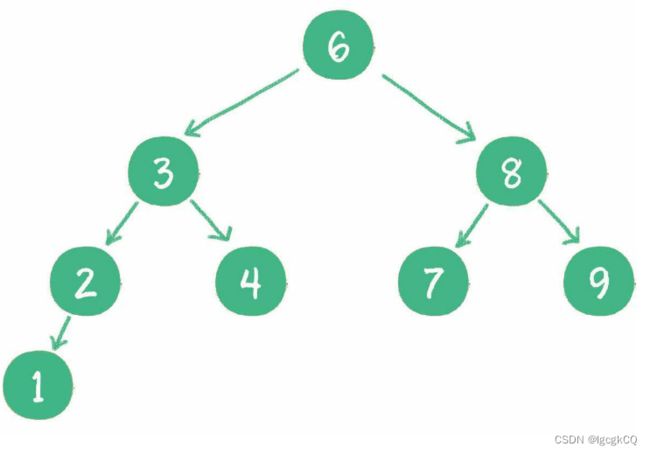
对于一个节点分布相对均衡的二叉查找树来说,如果节点总数是n,那么搜索节点的时间复杂度就是O(logn),和树的深度是一样的。
这种依靠比较大小来逐步查找的方式,和二分查找算法非常相似
维持相对顺序
二叉查找树要求左子树小于父节点,右子树大于父节点,正是这样保证了二叉树的有序性,所以又叫:二叉排序树。
新插入的节点,同样要遵循二叉排序树的原则

插入新元素5,由于5<6,5>3,5>4,所以5最终会插入到节点4的右孩子位置
遍历
在计算机程序中,遍历本身是一个线性操作。所以遍历同样具有线性结构的数组或链表,是一件轻而易举的事情;

反观二叉树,是典型的非线性数据结构,遍历时需要把非线性关联的节点转化成一个线性的序列,以不同的方式来遍历,遍历出的序列顺序也不同
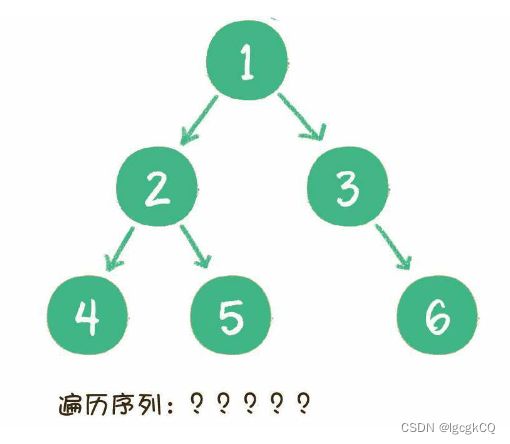
从节点之间位置关系的角度来看,二叉树的遍历分为4种。
1. 前序遍历。
2. 中序遍历。
3. 后序遍历。
4. 层序遍历
从更宏观的角度来看,二叉树的遍历归结为两大类。
1. 深度优先遍历(前序遍历、中序遍历、后序遍历)。
2. 广度优先遍历(层序遍历)
深度优先遍历
深度优先和广度优先这两个概念不止局限于二叉树,它们更是一种抽象的算法思想,决定了访问某些复杂数据结构的顺序。
所谓深度优先,顾名思义,就是偏向于纵深,“一头扎到底”的访问方式
前序遍历
二叉树的前序遍历,输出顺序是根节点、左子树、右子树

中序遍历
二叉树的中序遍历,输出顺序是左子树、根节点、右子树

后序遍历
二叉树的后序遍历,输出顺序是左子树、右子树、根节点。

广度优先遍历
层序遍历
顾名思义,就是二叉树按照从根节点到叶子节点的层次关系,一层一层横向遍历各个节点

二叉树同一层次的节点之间是没有直接关联的,需要借助一个数据结构来辅助工作,这个数据结构就是队列。
public static void levelOrderTraversal(TreeNode root){
Queue queue = new LinkedList();
queue.offer(root);
while(!queue.isEmpty()){
TreeNode node = queue.poll();
System.out.println(node.data);
if(node.leftChild != null){
queue.offer(node.leftChild);
}
if(node.rightChild != null){
queue.offer(node.rightChild);
}
}
} 二叉堆
定义
二叉堆本质是一种完全二叉树,分为两个类型:
1.最大堆:任何一个父节点的值,都大于或等于它左、右孩子节点的值

2.最小堆:最小堆的任何一个父节点的值,都小于或等于它左、右孩子节点的值

二叉堆的根节点叫作堆顶
特点:
最大堆的堆顶是整个堆中的最大元素;最小堆的堆顶是整个堆中的最小元素
自我调整
堆的自我调整,就是把一个不符合堆性质的完全二叉树,调整成一个堆;
操作
操作都基于堆的自我调整,以最小堆为例,看一看二叉堆如何进行自我调整
插入加点
当二叉堆插入节点时,插入位置是完全二叉树的最后一个位置。例如插入一个新节点,值是 0;与父节点进行比较,如果更大,让新节点“上浮”,和父节点交换位置,持续比较,直到0到达堆顶。

删除节点
二叉堆删除节点的过程和插入节点的过程正好相反,所删除的是处于堆顶的节点。例如删除最小堆的堆顶节点1;

为了继续维持完全二叉树的结构,会把堆的最后一个节点10临时补到原本堆顶的位置;让暂处堆顶位置的节点10和它的左、右孩子进行比较,如果左、右孩子节点中最小的一个(显然是节点2)比节点10小,那么让节点10“下沉”,这样一来,二叉堆重新得到了调整

构建二叉堆
构建二叉堆,也就是把一个无序的完全二叉树调整为二叉堆,本质就是让所有非叶子节点依次“下沉”
从最后一个非叶子节点开始,也就是从节点10开始。如果节点10大于它左、右孩子节点中最小的一个,则节点10“下沉”

经过上述几轮比较和“下沉”操作,最终每一节点都小于它的左、右孩子节点,一个无序的完全二叉树就被构建成了一个最小堆

代码实现
二叉堆虽然是一个完全二叉树,但它的存储方式并不是链式存储,而是顺序存储。换句话说,二叉堆的所有节点都存储在数组中。

在数组中没有左右指针的情况下,可以依靠数组下标来计算定位一个父节点的左孩子和右孩子:
假设父节点的下标是parent:
左孩子下标: 2×parent+1
右孩子下标: 2×parent+2
1. /**
2. * “上浮”调整
3. * @param array 待调整的堆
4. */
5. public static void upAdjust(int[] array) {
6. int childIndex = array.length-1;
7. int parentIndex = (childIndex-1)/2;
8. // temp 保存插入的叶子节点值,用于最后的赋值
9. int temp = array[childIndex];
10. while (childIndex > 0 && temp < array[parentIndex])
11. {
12. //无须真正交换,单向赋值即可
13. array[childIndex] = array[parentIndex];
14. childIndex = parentIndex;
15. parentIndex = (parentIndex-1) / 2;
16. }
17. array[childIndex] = temp;
18. }
19.
20.
21. /**
22. * “下沉”调整
23. * @param array 待调整的堆
24. * @param parentIndex 要“下沉”的父节点
25. * @param length 堆的有效大小
26. */
27. public static void downAdjust(int[] array, int parentIndex,
int length) {
28. // temp 保存父节点值,用于最后的赋值
29. int temp = array[parentIndex];
30. int childIndex = 2 * parentIndex + 1;
31. while (childIndex < length) {
32. // 如果有右孩子,且右孩子小于左孩子的值,则定位到右孩子
33. if (childIndex + 1 < length && array[childIndex + 1] <
array[childIndex]) {
34. childIndex++;
35. }
36. // 如果父节点小于任何一个孩子的值,则直接跳出
37. if (temp <= array[childIndex])
38. break;
39. //无须真正交换,单向赋值即可
40. array[parentIndex] = array[childIndex];
41. parentIndex = childIndex;
42. childIndex = 2 * childIndex + 1;
43. }
44. array[parentIndex] = temp;
45. }
46.
47. /**
48. * 构建堆
49. * @param array 待调整的堆
50. */
51. public static void buildHeap(int[] array) {
52. // 从最后一个非叶子节点开始,依次做“下沉”调整
53. for (int i = (array.length-2)/2; i>=0; i--) {
54. downAdjust(array, i, array.length);
55. }
56. }
57.
58. public static void main(String[] args) {
59. int[] array = new int[] {1,3,2,6,5,7,8,9,10,0};
60. upAdjust(array);
61. System.out.println(Arrays.toString(array));
62.
63. array = new int[] {7,1,3,10,5,2,8,9,6};
64. buildHeap(array);
65. System.out.println(Arrays.toString(array));
66. }优先队列
队列特点:先进先出、后进后出;入队列,将新元素置于队尾,出队列,队头元素最先被移出
特点
最大优先队列,无论入队顺序如何,都是当前最大的元素优先出队
最小优先队列,无论入队顺序如何,都是当前最小的元素优先出队

实现
最大堆的堆顶是整个堆中的最大元素,可以用最大堆来实现最大优先队列,这样的话,每一次入队操作就是堆的插入操作,每一次出队操作就是删除堆顶节点
入队操作
1.插入新节点

2.新节点上浮到合适位置

出队操作
1.让原堆顶节点10出队

2.把最后一个节点1替换到堆顶位置

3.节点1“下沉”,节点9成为新堆顶
