知识图谱学习笔记——(四)知识图谱的抽取与构建
一、知识学习
声明:知识学习中本文主体按照浙江大学陈华钧教授的《知识图谱》公开课讲义进行介绍,并个别地方加入了自己的注释和思考,希望大家尊重陈华钧教授的知识产权,在使用时加上出处。感谢陈华钧教授。
(一)B站 《浙大知识图谱完整版》——4
学识时间:2023年5月5日09:15:25
4、知识图谱的抽取与构建
4.1重新理解知识工程与知识获取
4.1.1 知识工程
- 符号主义的核心思想
– 人工智能源于数理逻辑
– 智能的本质是符号的操作和运算 - 知识工程的诞生
- Knowledge is the power in AI
AI System=Knowledge + Reasoning
人工智能系统=知识+推理


知识工程是以知识为处理对象, 研究知识系统的知识表示、 处理和应用的方法和开发工具的学科 。
4.1.2 传统知识工程的特点
规模小——成本高——知识汤

上图展示了知识工程师和领域专家与帮助构建专家系统的软件工具的交互。箭头表示信息流。
4.1.3 知识获取的瓶颈
- 成年人脑包含近1000亿神经元, 每个神经元都可能有近1000的连接。 模拟这样的人脑需要约100TB的参数。
- 假设这100TB的参数能完整的存储人脑中的知识, 靠人工编码可以获取这样规模的知识吗?
- 单个人脑中的知识仍然是有限的, 如果需要获取全体人类知识, 靠人工编码是无法完成的
4.1.4 挑战机器自主获取知识的极限

人的五官可以将世界域中的大量复杂的信息拷贝到人脑中。
4.1.5 知识图谱工程
知识图谱工程就是简化的知识工程
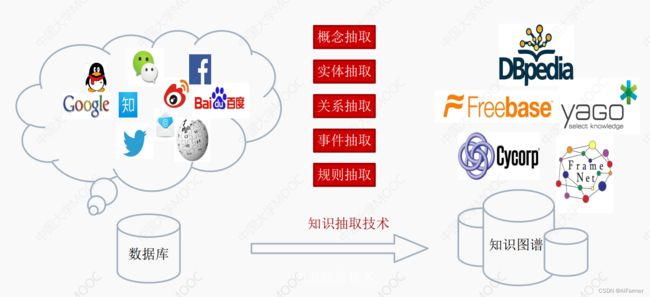 重要的知识抽取环节:概念抽取、实体抽取、关系抽取、时间抽取、规则抽取。
重要的知识抽取环节:概念抽取、实体抽取、关系抽取、时间抽取、规则抽取。
从不同来源、 不同结构的数据中进行知识提取, 形成知识存入到知识图谱。

★从关系数据库获取知识
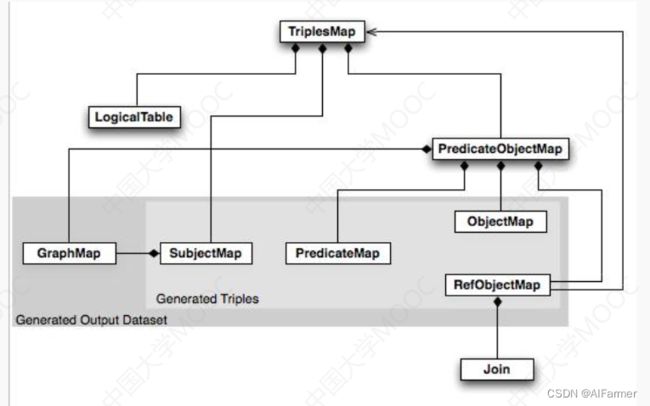
Example R2RML mapping:
@prefix rr: <http://www.w3.org/ns/r2rml#>.
eprefix ex: <http://example.com/ns#>.
<#TriplesMap1>
rr:logicalTable [ rr:tableName "EMP" ];
rr:subjectMap[
rr:template "http://data.example.com/employee/(EMPNO)";
rr:class ex:Employee;
];
rr:predicateObjectMap [
rr:predicate ex:name;
rr:objectMap [ rr:column "ENAME" ];
].
Example output data:
<http://data.example.com/employee/7369> rdf:type ex:Employee.
<http://data.example.com/employee/7369> ex:name "SMITH".
详细代码出处:从关系数据库获取知识
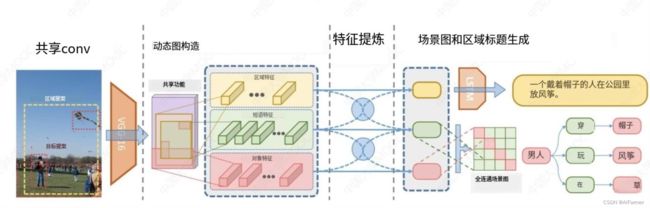
★从视觉数据获取知识
场景图构建
★从文本获取知识
● 命名实体识别
● 术语抽取( 概念抽取)
从语料中发现 多个单词组成的相关术语。
● 关系抽取
王思聪是万达集团董事长王健林的独子。 [王健林] <父子关系> [王思聪]
● 事件抽取
据路透社消息, 英国当地时间9月15日早8时15分, 位于伦敦西南地铁线District Line 的Parsons Green地铁站发生爆炸, 目前已确定有多人受伤, 具体伤亡人数尚不明确。目前, 英国警方已将此次爆炸与起火定性为恐怖袭击。

小结:
知识图谱 ≠ 专家系统,知识图谱就是新一代的知识工程


冯诺依曼曾估计单个个体的大脑中的全量知识需要 2.4*1020 字节存储, 知识工程的根本性
科学问题是知识完备性问题, 即规模化自动化知识获取与处理能力。
4.2 知识抽取——实体识别与分类
4.2.1 实体识别与分类任务定义
从文本中识别实体边界及其类型

4.2.2 实体识别的常用方法
(1) 基于模板和规则
将文本与规则进行匹配来识别出命名实体
“***说” 、 “***老师” ;“***大学” 、 “***医院”
- 优点:
准确, 有些实体识别只能依靠规则抽取; - 缺点:
■ 需要大量的语言学知识
■ 需要谨慎处理规则之间的冲突问题;
■ 构建规则的过程费时费力、 可移植性不好
(2)基于序列标注的方法

| 词本身的特征 | 描述 |
|---|---|
| 边界特征 | 边界词概率 |
| 词性 | 名词、动词、副词等 |
| 依存关系 | 父子、从属等 |
| 前后缀特征 | 描述 |
|---|---|
| 姓氏 | 李XX、 王X |
| 地名 | XX省、 XX市等 |
| 字本身的特征 | 描述 |
|---|---|
| 是否是数字 | 是、否 |
| 是否是字符 | 是、否 |
确定实体识别的序列标签体系
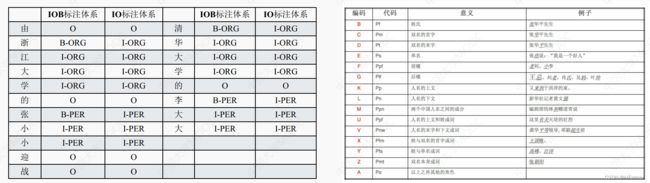
常见序列标注模型: HMM (隐马尔可夫模型)
- 有向图模型
- 基于马尔可夫性, 假设特征之间是独立的
HMM (隐马尔可夫模型)的要素定义 - 隐藏状态集合Q, 对应所有可能的标签集合, 大小为N; 观测状态集合V, 对应所有可能的词的集合, 大小为M。
- 对于一个长度为T的序列,I对应状态序列(即标签序列) , O对应观测序列(即词组成的句子) 。
- 状态转移概率矩阵: A = [ a i j ] N ∗ N A =[a_{ij}]_{N*N} A=[aij]N∗N
- 转移概率:是指某一个隐藏状态(如标签“B-Per”) 转移到下一个隐藏状态(如标签“I-Per” )的概率。 例如, B-ORG标签的下一个标签大概率是I-ORG, 但一定不可能是I-Per。
- 发射概率矩阵: B = [ b j k ] N ∗ M B =[b_{jk}]_{N*M} B=[bjk]N∗M
- 发射概率:是 指在某个隐藏状态(如标签“B-Per”) 下, 生成某个观测状态(如词“陈”) 的概率。
- 隐藏状态的初始分布Π = [π(i)]N, 这里指的是标签的先验概率分布。
编者注:关于LaTex公式可以参见LaTeX公式篇
4.2.3 HMM的计算问题
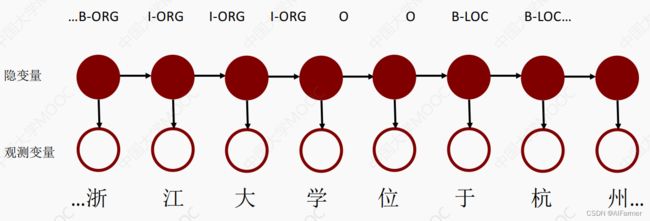
- 评估观察序列概率: 给定模型λ=(A,B,Π) 和观测序列O(如一句话“浙江大学位于杭州”) , 计算在模型λ下观测序列O出现的概率P(O|λ), 这需要用到前向后向算法。
- 模型参数学习问题: 即给定观测序列O, 估计模型λ的参数, 使该模型下观测序列的条件概率P(O|λ)最大。 这个问题的求解需要用到基于EM算法的鲍姆-韦尔奇算法。
- 预测问题: 也称为解码问题, 即给定模型λ和观测序列O, 求最可能出现的对应的隐藏状态序列( 标签序列) , 这个问题的求解需要用到基于动态规划的维特比算法。
(1) 求观测序列的概率—前向后向算法
问题: 假设模型参数全知, 要求推断某个句子出现的概率
- 前向概率(局部状态) : 定义时刻t时隐藏状态为qi, 观测状态的序列为o1,o2,…ot的概率为前向概率。 记为:
α t ( i ) = P ( o 1 , o 2 , … , o t , i t = q i ∣ λ ) α_t(i)=P(o_1,o_2,…, o_t,i_t=q_i|λ) αt(i)=P(o1,o2,…,ot,it=qi∣λ) - 递推关系式: 从t时刻递推t+1时刻:
α t + 1 ( i ) = [ ∑ j = 1... N α t ( j ) ∗ a j i ] b i ( o t + 1 ) α_{t+1}(i)=[∑_{j=1...N} α_t(j)*a_{ji}]b_i(o_{t+1}) αt+1(i)=[j=1...N∑αt(j)∗aji]bi(ot+1) - 利用递推关系式, 从t=1时刻递推算出t=T时刻, 并计算最终结果:
P ( “浙江大学位于杭州” ∣ λ ) = ∑ i = 1... N α T ( i ) P(“浙江大学位于杭州” |λ)=∑_{i=1...N} α_T(i) P(“浙江大学位于杭州”∣λ)=i=1...N∑αT(i) - 前向后向算法比起穷举搜索的指数级复杂度, 其复杂度与序列长度是线性关系

(2)模型参数的估计与学习
问题: 利用训练语料估计模型参数
假如我们已知D个长度为T的句子和对应的实体识别标签, 即{(O1,I1),(O2,I2),…(OD,ID)}是已知的, 此时我们可以很容易的用最大似然来求解模型参数。
➤ 标签转移概率矩阵 A = [ a i j ] N ∗ N A=[a_{ij}]_{N*N} A=[aij]N∗N
➤ 词的生成概率矩阵 B = [ b j ( k ) ] N ∗ M B=[b_j(k)]_{N*M} B=[bj(k)]N∗M
➤ 标签的初始分布Π = [π(i)]N
假设样本从标签 qi转移到标签qj的频率计数是Aij,那么隐藏状态转移矩阵求得:
A = [ a i j ] A=\begin{bmatrix} a_{ij} \end{bmatrix} A=[aij]
其中
a i j = A i j ∑ s = 1 A i s a_{ij} = \frac {A_{ij}}{\sum_{s=1}A_{is}} aij=∑s=1AisAij
假设样本标签为qj且对应词为vk的频率计数是Bjk,那么观测状态概率矩阵为
B = [ b j ( k ) ] B=\begin{bmatrix} b_j(k) \end{bmatrix} B=[bj(k)]
其中
b j ( k ) = B j k ∑ s = 1 M B j s b_j(k) = \frac {B_{jk}}{\sum_{s=1}^{M}B_{js}} bj(k)=∑s=1MBjsBjk
假设所有样本中初始标签为qi的频率计数为C(i),那么初始概率分布为:
Π = π ( i ) = C ( i ) ∑ s = 1 N C ( s ) \Pi=\pi(i) = \frac {C(i)}{\sum_{s=1}^NC(s)} Π=π(i)=∑s=1NC(s)C(i)
鲍姆韦尔奇算法-EM算法
很多时候我们无法得到句子对应的实体标签序列, 因为这需要大量的人工数据标注工作。 如果只有D个长度为T的句子, 即{(O1),(O2),…(OD)}是已知的, 此时可以用EM算法迭代来求解。
输入: D个观测序列样本
( O 1 ) , ( O 2 ) , . . . , ( O D ) {{(O_1),(O_2),...,(O_D)}} (O1),(O2),...,(OD)
输出: HMM模型参数
- 随机初始化所有的 π i , a i j , b j ( k ) \pi_i, a_{ij}, b_j(k) πi,aij,bj(k)
- 对于每个样本d = 1,2,…D,用前向后向算法计算 γ t d ( i ) , ζ t d ( i , j ) , t = 1 , 2 , . . . T \gamma_t^d(i),\zeta_t^d(i,j),t=1,2,...T γtd(i),ζtd(i,j),t=1,2,...T
- 更新模型参数:
π i = ∑ d = 1 D γ 1 d ( i ) D \pi_i = \frac {\sum_{d=1}^D\gamma_1^d(i)}{D} πi=D∑d=1Dγ1d(i)
a i j = ∑ d = 1 D ∑ t = 1 T − 1 ζ t d ( i , j ) ∑ d = 1 D ∑ t = 1 T − 1 γ t d ( i ) a_{ij}= \frac {\sum_{d=1}^D\sum_{t=1}^{T-1}\zeta_t^d(i,j)}{\sum_{d=1}^D\sum_{t=1}^{T-1}\gamma_t^d(i)} aij=∑d=1D∑t=1T−1γtd(i)∑d=1D∑t=1T−1ζtd(i,j)
b j ( k ) = ∑ d = 1 D ∑ t = 1 , o t d = v k T γ t d ( i ) ∑ d = 1 D ∑ t = 1 T γ t d ( i ) b_j(k)= \frac {\sum_{d=1}^D\sum_{t=1,o_t^d=v_k}^T\gamma_t^d(i)}{\sum_{d=1}^D\sum_{t=1}^T\gamma_t^d(i)} bj(k)=∑d=1D∑t=1Tγtd(i)∑d=1D∑t=1,otd=vkTγtd(i) - 如果i, aij, bj(k)的值已经收敛,则算法结束,否则回到第2) 步继续迭代
解码隐藏状态序列—维特比算法
问题: 给定训练好的模型, 给定一句话, 预测每个词对应的实体标签
输入: 模型λ=(A,B,Π), 观测序列O=(浙, 江, 大, 学, 位, 于, 杭, 州)
输出: 最有可能的隐藏状态序列I={i1,i2,…iT}, 即实体标签序列
这里的优化目标是使P(I|O)最大化

- 初始化局部状态
δ 1 ( i ) = π i b i ( o 1 ) , i = 1 , 2 , . . . , N \delta_1(i) =\pi_ib_i(o_1),i=1,2,...,N δ1(i)=πibi(o1),i=1,2,...,N
ψ 1 ( i ) = 0 , i = 1 , 2 , . . . , N \psi_1(i)=0,i=1,2,...,N ψ1(i)=0,i=1,2,...,N
时刻1,输出为O1时,各个隐藏状态的可能性。 - 进行动态规划递推时刻t=2,3,…T时刻的局部状态
δ t ( i ) = max 1 ≤ j ≤ N [ δ t − 1 ( j ) a j i ] b i ( o t ) , i = 1 , 2 , . . . , N \delta_t(i) =\max_{1≤j≤N}[\delta_{t-1}(j)a_{ji}]b_i(o_t),i=1,2,...,N δt(i)=1≤j≤Nmax[δt−1(j)aji]bi(ot),i=1,2,...,N
在t时刻, 所有从t-1时刻的状态j中, 取最大概率。
ψ t ( i ) = a r g max 1 ≤ j ≤ N [ δ t − 1 ( j ) a j i ] , i = 1 , 2 , . . . , N \psi_t(i)=arg\max_{1≤j≤N}[\delta_{t-1}(j)a_{ji}],i=1,2,...,N ψt(i)=arg1≤j≤Nmax[δt−1(j)aji],i=1,2,...,N
从t-1时刻的状态中, 选择使t时刻概率最大的那个隐藏状态的编号。 - 如此递推, 可计算最后时刻T最大的δT(i),即为最可能隐藏状态序列出现的概率
P ∗ = max 1 ≤ j ≤ N δ T ( i ) P*= \max_{1≤j≤N}\delta_T(i) P∗=1≤j≤NmaxδT(i) - 计算时刻T最大的Ψt(i),即为时刻T最可能的隐藏状态
i T ∗ = a r g max 1 ≤ j ≤ N [ δ T ( i ) ] i_T^*= arg\max_{1≤j≤N}[\delta_T(i)] iT∗=arg1≤j≤Nmax[δT(i)] - 利用局部状态Ψ(i)开始回溯, 最终得到解码的序列, 如: “ …B-ORG, I-ORG, I-ORG, I-ORG , O, O, B-LOC , B-LOC…”
常见序列预测模型: CRF条件随机场
CRF是无向图模型

- 随机场包含多个位置, 每个位置按某种分布随机赋予一个值, 其全体就叫做随机场。 马尔科夫随机场假设 随机场中某个位置的赋值仅与和它相邻位置的赋值有关, 和不相邻位置的赋值无关。
- 条件随机场进一步假设马尔科夫随机场中只有X和Y两种变量, X一般是给定的, 而Y一般是在给定X的条件下的输出。 例如: 实体识别任务要求对一句话中的十个词做实体类型标记, 这十个词可以从可能实体类型标签中选择, 这就形成了一个随机场。 如果假设某个词的标签只与其相邻的词的标签有关, 则形成马科夫随机场, 同时由于这个随机场只有两种变量, 令X为词, Y为实体类型标签, 则形成一个条件随机场, 即, 我们的目标时求解P(Y|X)。
CRF的机器学习模型
通过定义 特征函数和权重系数转化为一个机器学习问题
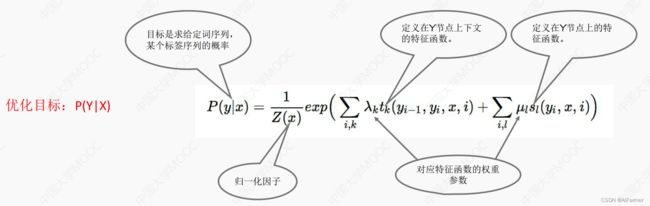
- 训练—Training: 给定训练数据集X和Y, 学习CRF的模型参数wk ( θ \theta θ)和条件概率分布Pw(y|x), 采用最大化对数似然函数和SGD即可。
O ( θ ) = ∑ t = 1... N l o g P θ ( y t ∣ x t ) O(\theta)=\sum_{t=1...N}logP_\theta(y^t|x^t) O(θ)=t=1...N∑logPθ(yt∣xt) - 解码—Decoding: 给定CRF条件概率分布P(y|x)和输入序列x, 计算使条件概率最大的输出序列y, 可用维特比算法很方便解决这一问题。
4.2.4 基于深度学习的实体识别方法

A Survey on Deep Learning for Named Entity Recognition. (TKDE2020)
(1)常见实现方法: BiLSTM+CRF

BiLSTM+CRF: CRF层
- CRF层的参数是一个 (k+2)×(k+2)的矩阵 A;
- Aij表示的是从第 i个标签(如B-LOC) 到第 j个标签(如B-Org) 的转移得分;
- 加2是因为要为句子首部添加一个起始状态以及为句子尾部添加一个终止状态。

BiLSTM+CRF: 模型训练
Score Function:
s c o r e ( x , y ) = ∑ i = 1 n P i , y i + ∑ i = 1 n + 1 A y ( i − 1 ) , y i score(x,y)=\sum_{i=1}^nP_{i,y_i}+\sum_{i=1}^{n+1}A_{y_{(i-1)},y_i} score(x,y)=i=1∑nPi,yi+i=1∑n+1Ay(i−1),yi
Softmax:
P ( y ∣ x ) = e x p ( s c o r e ( x , y ) ) ∑ y , e x p ( s c o r e ( x , y , ) ) P(y|x)=\frac{exp(score(x,y))}{\sum_{y^,}exp(score(x,y^,))} P(y∣x)=∑y,exp(score(x,y,))exp(score(x,y))
最大化对数似然函数:
l o g P ( y x ∣ x ) = s c o r e ( x , y x ) − l o g ( ∑ y , e x p ( s c o r e ( x , y , ) ) ) logP(y^x|x)=score(x,y^x)-log(\sum_{y^,}exp(score(x,y^,))) logP(yx∣x)=score(x,yx)−log(y,∑exp(score(x,y,)))
预测过程:
y ∗ = a r g max y , s c o r e ( x , y , ) y^*=arg \max_{y^,}score(x,y^,) y∗=argy,maxscore(x,y,)
(2)基于预训练语言模型的实体识别
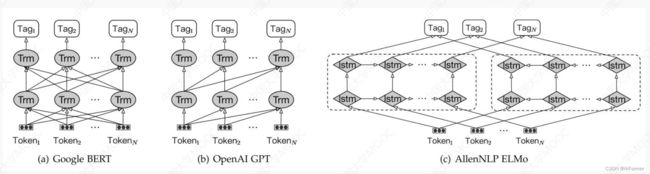
实体识别解码策略

A Survey on Deep Learning for Named Entity Recognition. (TKDE2020)
小结
- 实体识别仍面临着 标签分布不平衡, 实体嵌套等问题, 制约了现实应用;
- 中文的实体识别面临一些特有的问题, 例如: 中文没有自然分词、 用字变化多、 简化表达现象严重等等;
- 实体识别是语义理解和构建知识图谱的重要一环, 也是 进一步抽取三元组和关系分类的前提基础
4.3 知识抽取——关系抽取与属性补全
4.3.1 实体关系抽取
(1)实体关系抽取的任务定义:
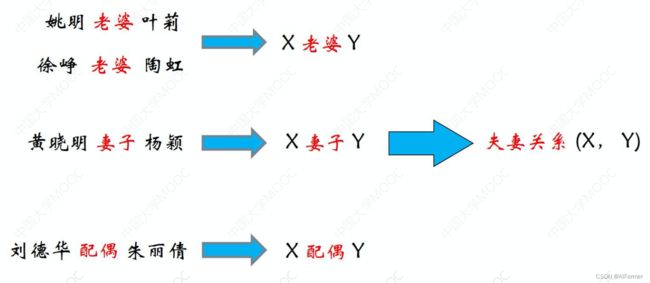
从文本中抽取出两个或者多个实体之间的语义关系;从文本获取知识图谱三元组的主要技术手段, 通常被用于知识图谱的补全。
美丽的西湖坐落于浙江省的省会城市杭州的西南面。
(2)实体关系抽取方法概览

1)基于模板的方法
基于触发词匹配的关系抽取
基于依存句法匹配的关系抽取

- 基于依存句法分析句子的句法结构
- 以动词为基点,构建规则,对节点上的词性和边上的依存关系进行限定
■1. 对句子进行分词、 词性标注、 命名实体识别、 依存分析等处理
■2. 根据句子依存语法树结构上匹配规则, 每匹配一条规则就生成一个三元组
■3. 根据扩展规则对抽取到的三元组进行扩展
■4. 对三元组实体和触发词进一步处理抽取出关系

优缺点
- 优点
▲在小规模数据集上容易实现
▲构建简单 - 缺点
▲特定领域的模板需要专家构建
▲难以维护
▲可移植性差
▲规则集合小的时候, 召回率很低
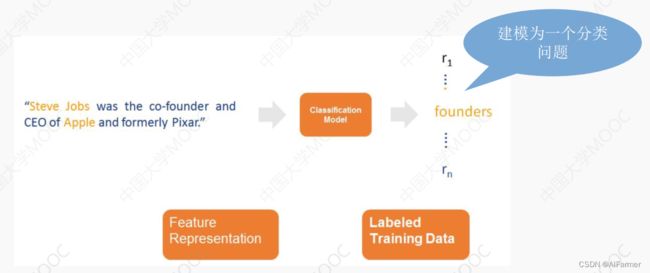
2) 基于监督学习的关系抽取
At-least-one Hypothesis
At-least-one Hypothesis
If two entities participate in a relation, at least one sentence that mentions these two entities might express that relation
• 预先定义好关系的类别
• 人工标注一些数据
• 设计特征表示
• 选择一个分类方法 (SVM、 NN等)
• 评估结果
特征设计

- 实体特征
▲ 实体前后的词
▲ 实体的类型、 语法、 语义信息
▲ 实体词的共现特征, e.g., dog and cat
▲ 引入外部语义关系, e.g.,
– ACE entity types
– WordNet features - 关系特征
▲实体之间的词
▲窗口及Chunk序列
▲ 实体间的依存关系路径
▲ 实体间树结构的距离
▲特定的结构信息, 如最小子树
3) 机器学习框架
机器学习框架——特征函数+最大熵模型
同关系句子具有类似的文本特征
| Words | Mention词及中间所有词 |
|---|---|
| Entity Type | PER / ORG / LOC |
| Mention Level | NAME/ NOMINAL PRONOUN |
| Overlap | Mention词间隔的词数、中间含有mention词的个数是否在同一短语中 |
| Dependency | Mention在parse tree中依赖的词的POS/chunk/word |
| Parse Tree | 两个mention词中的依赖路径 |
- 目标是求在知道X的条件下使熵H最大的条件概率P(y|x)
H ( P ) = − ∑ x , y P ‾ ( x ) P ( y ∣ x ) l o g P ( y ∣ x ) H(P)=- \sum_{x,y}\overline P(x)P(y|x)logP(y|x) H(P)=−x,y∑P(x)P(y∣x)logP(y∣x)
需要满足的约束条件:
E P ‾ ( f i ) − E P ( f i ) = 0 , ( i = 1 , 2 , . . . , M ) E_ {\overline P}(f_i)-E_P(f_i)=0,(i=1,2,...,M) EP(fi)−EP(fi)=0,(i=1,2,...,M)
∑ y P ( y ∣ x ) = 1 \sum_{y}P(y|x)=1 y∑P(y∣x)=1
其中,fi即是需要针对句子样本定义的特征函数。
机器学习框架——核函数
- 在关系抽取任务中, 给定句子空间X, 核函数K: X * X —> [0, ∞)表示一个二元函数, 它以X中的两个句子x,y为输入, 返回二者之间的相似度得分K(x,y)。
- 例如, 我们可以为句子定义一个特征向量计算函数Ø(·), 那么句子x和y对应特征向量的点积K(x, y)=Ø(x)T ·Ø(y)(编者注:原文是点集K(x, y)=Ø(x)T ·Ø(y)),这里我觉得应该是点积,不知修改是否正确 )可以作为核函数的一种实现形式。
具体而言, 给定输入文本T中的两个实体e1和e2, 核函数方法采用下述方法计算它们之间满足关系r的置信度。
▲首先从标注数据中找到文本T’, 且T’中包含满足关系r的e1’和e2’。 然后基于核函数计算T和T’之间的相似度, 作为e1和e2满足关系r的置信度。
▲该做法背后体现的思想是: 如果两个实体对同时满足某个关系r, 这两个实体对分别所在的文本上下文也应该相似, 该相似通过核函数计算得到。 (编者注:这段没有想清楚,谁给解释一下,谢谢!)
▲ 计算相似度的方法有基于字符串核(Sequence kernel) 和基于树核函数(Tree kernel)等多种方法。
机器学习框架——字符串核举例
- 给定带有关系标注的训练样本集合, 该方法首先基于每个样本中出现的实体e1和e2将该样本切分为左端上下文left、 中间上下文middle和右端上下文right三部分。
- 给定测试样本, 根据其中出现的实体e1’和e2’对其进行同样的切分, 生成left’、 middle’和right’。
- 基于字符串核函数计算该样本与每个训练样本在上述三个上下文上的相似度
- 最后对三个相似度得分进行加和, 并用于分类模型的训练与预测

机器学习框架——句法树核函数
句法树核, 增加节点特征 - 用句法依赖树代替浅层分析。
- 每个节点加入NER,POS等多个Tag
K ( T 1 , T 2 ) = { 0 , i f m ( r 1 , r 2 ) = 0 s ( r 1 , r 2 ) + K c ( r 1 [ c ] , r 2 [ c ] ) , o t h e r w i s e K(T_1,T_2)= \begin{cases} 0, & if m(r_1,r_2)=0 \\ s(r_1,r_2)+K_c(r_1[c],r_2[c]),& otherwise \\ \end{cases} K(T1,T2)={0,s(r1,r2)+Kc(r1[c],r2[c]),ifm(r1,r2)=0otherwise
m ( t i , t j ) = { 1 , i f ϕ m ( t i ) = ϕ m ( t j ) 0 , o t h e r w i s e m(t_i,t_j)= \begin{cases} 1, & if \phi_m(t_i)=\phi_m(t_j) \\ 0,& otherwise \\ \end{cases} m(ti,tj)={1,0,ifϕm(ti)=ϕm(tj)otherwise
s ( t i , t j ) = ∑ υ q ϵ ϕ s ( t i ) ∑ υ r ϵ ϕ s ( t j ) C ( υ q , υ r ) s(t_i,t_j)= \sum_{\upsilon_q \epsilon\phi_s(t_i)} \sum_{\upsilon_r \epsilon\phi_s(t_j)}C(\upsilon_q,\upsilon_r) s(ti,tj)=υqϵϕs(ti)∑υrϵϕs(tj)∑C(υq,υr)
Troops advanced near Tikrit
| Feature | Example |
|---|---|
| word | troops, Tikrit |
| part-of-speech (24 values) | NN,NNP |
| general-pos (5 values) | noun, verb, adi |
| chunk-tag | NP, VP,ADJP |
| entity-type | person, geo-political-entity |
| entity-level | name,nominal,pronoun |
| Wordnet hypernyms | social group, city |
| relation-argument | ARG_A,ARGB |
机器学习框架——最短依赖路径树核函数
最短依赖路径树(SPT) 内核:

A shortest path dependency kernel for relation extraction(EMNLP 2005)
上下文相关最短路径依赖树核函数:
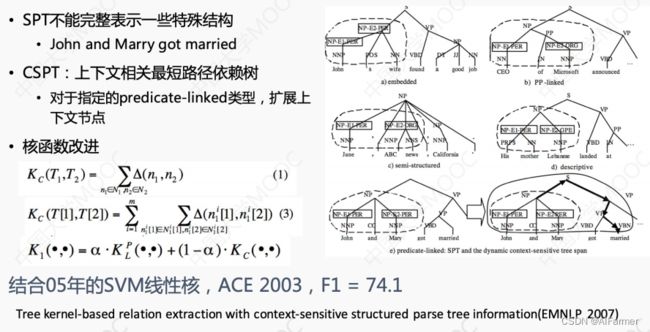
Tree kernel-based relation extraction with context-sensitive structured parse tree information(EMNLP 2007)
机器学习框架—深度学习方法
-
基于特征的方法需要人工设计特征, 这类方法适用于标注数量较少, 精度要求较高, 人工能够胜任的情况。
-
基于核函数的方法能够从字符串或句法树中自动抽取大量特征, 但这类方法始终是在衡量两段文本在子串或子树上的相似度, 并没有从语义的层面对两者做深入比较。
-
此外, 上述两类方法通常都需要做词性标注和句法分析, 用于特征抽取或核函数计算, 这是典型的pipeline做法, 会把前序模块产生的错误传导到后续的关系抽取任务, 并被不断放大 。
-
深度学习技术不断发展, 端到端的抽取方法能 大幅减少特征工程, 并减少对词性标注等预处理模块的依赖 , 成为当前关系抽取技术的主流技术路线。

机器学习框架——基于递归神经网络的关系抽取 -
RNN(递归)可以抽取词组之间的修饰关系和逻辑关系
-
每个节点都由一个向量和矩阵组成
– 向量表示本身词汇语义,采用词向量初始化
– 矩阵表示该词对邻词的作用,采用高斯函数初始化 -
父子节点递归
p = f A , B ( a , b ) = f ( B a , A b ) = g ( W [ B a A b ] ) p=f_{A,B}(a,b)=f(Ba,Ab)=g(W \begin{bmatrix} Ba\\ Ab \end{bmatrix} ) p=fA,B(a,b)=f(Ba,Ab)=g(W[BaAb])
P = f M ( A , B ) = W M [ A B ] P=f_M(A,B)=W_M\begin{bmatrix} A\\B \end{bmatrix} P=fM(A,B)=WM[AB]
-输出层
d ( p ) = s o f t m a x ( W l a b e l p ) d(p)=softmax(W^{label}p) d(p)=softmax(Wlabelp)
∂ J ∂ θ = 1 N ∑ ( x , t ) ∂ E ( x , t ; θ ) ∂ θ + λ θ \frac{\partial J}{\partial \theta }= \frac{1}{N} \sum_{(x,t)} \frac{\partial E(x,t;\theta)}{\partial \theta}+\lambda \theta ∂θ∂J=N1(x,t)∑∂θ∂E(x,t;θ)+λθ
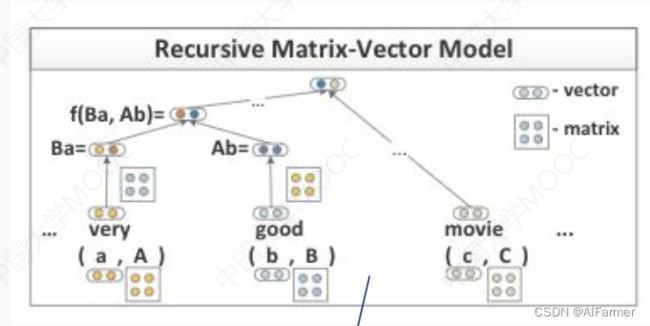
| 1.对于输入句子中待分类的实体e1和e2,在句法树中找到能覆盖这两个实体的最小子树; |
|---|
| 2.然后从该子树对应的叶节点开始,通过自底向上的方式两两合并相邻的两个单词或短语对应的向量和矩阵,直到遍历至该子树的根节点结束。 |
| 3.最后基于根节点对应的向量p,使用softmax对关系集合中的关系候选进行打分和排序。 |
| 4.该方法基于词向量和句法树本身的结构,有效的考虑了句法和语义信息,但并未考虑实体本身在句子中的位置和语义信息。 |
机器学习框架—基于CNN的关系抽取
- 神经网络可以直接encode句子特征
– Lexical level features
实体、实体周边词、实体同义词的连接
| Features | Remark |
|---|---|
| L1 | Noun 1 |
| L2 | Noun 2 |
| L3 | Left and right tokens of noun 1 |
| L4 | Left and right tokens of noun 2 |
| L5 | WordNet hypernyms of nouns |
Sentence level features [WF,PF]T
WF(word features):窗口词,窗口大小为3;
PF(position features) :[d1, d2]
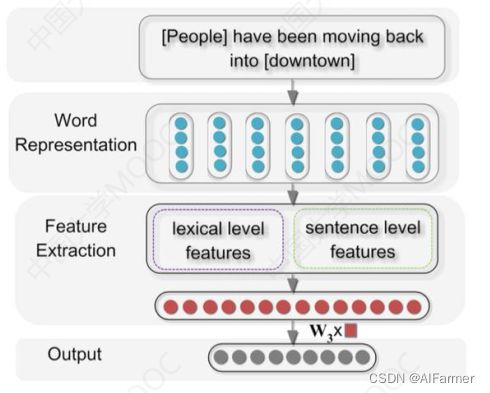
句子级别特征(Sentence Level Feature):
仅用词级别的特征提取, 是会丢失语序、 上下文、 句子整体的信息,而使用seq_length方向的词卷积,可以尽量提取些句子级别的信息。

-
对sentence level特征进行线性变换(卷积)
Z = W 1 X , W 1 ∈ R n 1 × n 0 , X ∈ R n 0 × t Z= W_1X ,W_1\in R^{n_1×n_0}, X\in R^{n_0×t} Z=W1X,W1∈Rn1×n0,X∈Rn0×t
n1为卷积核维度(隐藏层节点数),n0为特征维度,t词数 -
池化
m i = max Z ( i , ⋅ ) , 0 ≤ i ≤ n 1 , Z ∈ R n 1 × t m_i=\max Z(i,·) ,0≤i≤n_1, Z\in R^{n_1×t} mi=maxZ(i,⋅),0≤i≤n1,Z∈Rn1×t -
非线性变换
g = t a n h ( W 2 m ) , W 2 ∈ R n 2 × n 1 , m ∈ R n 1 × 1 g=tanh(W_2m),W_2\in R^{n_2×n_1},m\in R^{n_1×1} g=tanh(W2m),W2∈Rn2×n1,m∈Rn1×1 -
输出层+ softmax
o = W 3 f , f = [ l , g ] ⋅ , W 3 ∈ R n 4 × n 3 , f ∈ R n 3 × 1 o=W_3f,f=[l,g]·,W_3\in R^{n_4×n_3},f\in R^{n_3×1} o=W3f,f=[l,g]⋅,W3∈Rn4×n3,f∈Rn3×1
p ( i ∣ x , θ ) = e o i ∑ k = 1 n 4 e o k p(i|x,\theta)=\frac{e^{o_i}}{ \sum_ {k=1}^{n_4}e^{o_k}} p(i∣x,θ)=∑k=1n4eokeoi
J ( θ ) = ∑ i = 1 T l o g p ( y ( i ) ∣ x ( i ) , θ ) J(\theta)=\sum_{i=1}^Tlogp(y^{(i)}|x^{(i)},\theta) J(θ)=i=1∑Tlogp(y(i)∣x(i),θ)
SemEval-2010 Task 8 ,F1 = 82.7
机器学习框架—Piece-wise CNN Model
位置敏感的CNN模型

机器学习框架—基于BiLSTM的关系抽取
Attention + BiLST
·CNN不能处理长线依赖,RNN有梯度消失
·LSTM层:编码句子
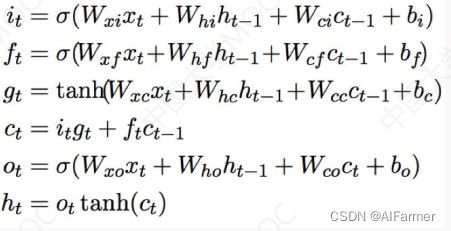
- Attention层:学习权重
M = t a n h ( H ) M=tanh(H) M=tanh(H)
α = s o f t m a x ( ω T M ) \alpha =softmax(\omega ^TM) α=softmax(ωTM)
r = H α T r=H \alpha^T r=HαT
h ∗ = t a n h ( r ) h^*=tanh(r) h∗=tanh(r)
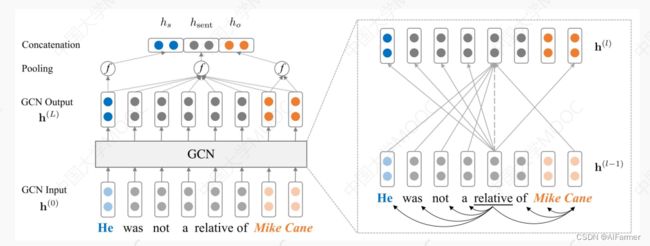
机器学习框架—基于图神经网络的关系抽取 - 图神经网络在图像领域的成功应用证明了 以节点为中心的局部信息聚合同样可以有效的提取图像信息。
- 利用句子的依赖解析树构成图卷积中的邻接矩阵, 以句子中的每个单词为节点做图卷积操作。 如此就可以抽取句子信息, 再经过池化层和全连接层即可做关系抽取的任务
基于预训练语言模型的关系抽取

Simple BERT Models for Relation Extraction and Semantic Role LabelinglJ], 2019
Matching the Blanks : Distributional Similarity for Relation Learning. (ACL2019)
拓展问题—实体关系联合抽取
误差传播问题:

实体识别和关系抽取任务之间的关联:
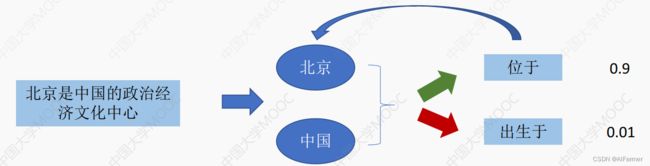
定义一种新颖的实体关系联合抽取的序列标注规范:

Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme. (ACL2017)
级联三元组抽取:
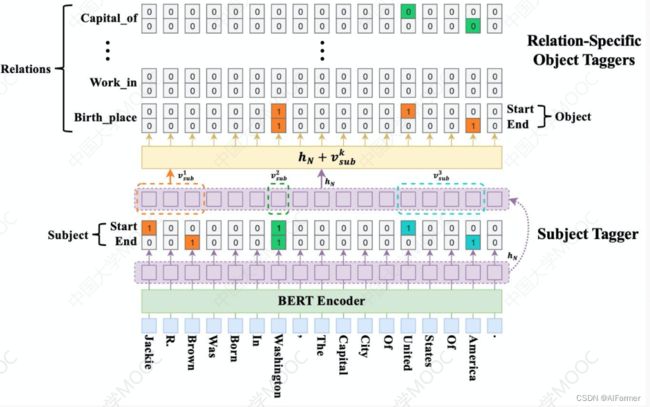
A Novel Cascade Binary Tagging Framework for Relational Triple Extraction. (ACL2020)
拓展问题—基于胶囊神经网络多标签关系抽取
- 传统模型主要关注单标签关系抽取, 但同一个句子可能包含多个关系。 采用胶囊神经网络可以帮助实现多标签的关系抽取。
- 如图所示, 模型首先通过预训练的 embedding 将句子中的词转化为词向量; 随后使用BiLSTM 网络得到粗粒度的句子特征表示, 再将所得结果输入到胶囊网络, 首先构建出primary capsule, 经由动态路由的方法得到与分类结果相匹配的输出胶囊。 胶囊的模长代表分类结果的概率大小。

Attention-based capsule networks with dynamic routing for relation extraction. (EMNLP2018)
拓展问题—多元关系抽取 - 传统的二元关系扩展的缺点
▲产生C(n,2)种特征组合
▲拆分成多个binary会丧失多元语义联系 - 学习出所有实体的表示,连接后分类
▲能表示所有实体对的全局关系 - Graph LSTM
▲Chain LSTM:按照time-step输入后一个词。
▲Tree LSTM:按照time-step输入当前语法依赖词
▲Graph LSTM:节点同时依赖上一时刻不同的语法依赖词和线性输入词,重新定义一个维度表示当前依赖种类。


| Model | Single-Sent | Cross-sent |
|---|---|---|
| Feature-Based | 74.7 | 77.7 |
| CNN | 77.5 | 78.1 |
| BiLSTM | 75.3 | 80.1 |
| Graph LSTM - EMBED | 76.5 | 80.6 |
| Graph LSTM - FULL | 77.9 | 80.7 |
拓展问题—跨句推理
提取不同句子中单实体间的关系
A是B的爸爸,B的妈妈是C -> A和C是夫妻
判断同一个句子中所有实体对的关系:
CNN encoder 得到模型:
E ( h , t ∣ S ) = m a x p ( r ∣ θ , s i ) E(h,t|S)=maxp(r|\theta,s_i) E(h,t∣S)=maxp(r∣θ,si)
找到和h,t均存在关系的实体,判断间接关系:
G ( h , r , t ∣ p i ) = E ( h , r A , e ) E ( e , r B , t ) p ( r ∣ r A , r B ) G(h,r,t|p_i)=E(h,r_A,e)E(e,r_B,t)p(r|r_A,r_B) G(h,r,t∣pi)=E(h,rA,e)E(e,rB,t)p(r∣rA,rB)
训练关系间relation path:
path encoder,得到r1 和r2 能推出关系r的概率
p ( r ∣ r A , r B ) = e x p ( O r ) ∑ i = 1 n r e x p ( O i ) p(r|r_A,r_B)=\frac{exp(O_r)}{\sum_{i=1}^{n_r}exp(O_i)} p(r∣rA,rB)=∑i=1nrexp(Oi)exp(Or)
O i = − ∣ ∣ r i − ( r A + r B ) ∣ ∣ L 1 O_i=-||r_i-(r_A+r_B)||L_1 Oi=−∣∣ri−(rA+rB)∣∣L1
定义(h,t)总关系
L ( h , r , t ) = E ( h , r , t ∣ S ) + α G ( h , r , t ∣ P ) L(h,r,t)=E(h,r,t|S)+\alpha G(h,r,t|P) L(h,r,t)=E(h,r,t∣S)+αG(h,r,t∣P)
J ( θ ) = ∑ ( h , r , t ) l o g ( L ( h , r , t ) ) J(\theta)=\sum_{(h,r,t)}log(L(h,r,t)) J(θ)=(h,r,t)∑log(L(h,r,t))
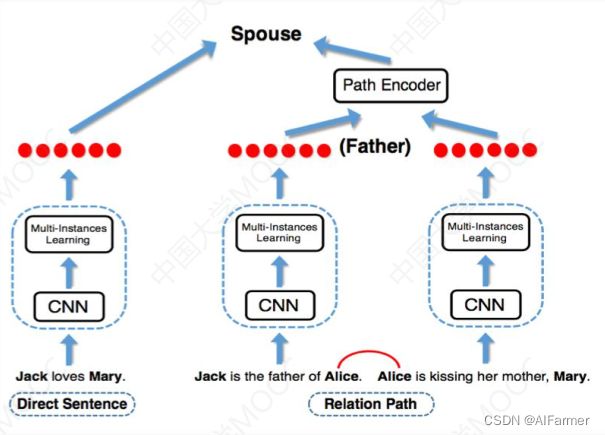

Incorporating Relation Paths in Neural Relation Extraction(EMNLP 2017)
4)半监督学习
半监督学习—基于远程监督的关系抽取
远程监督的基本假设: 两个实体如果在知识库中存在某种关系, 则包含该两个实体的非结构化句子均可能表示出这种关系.
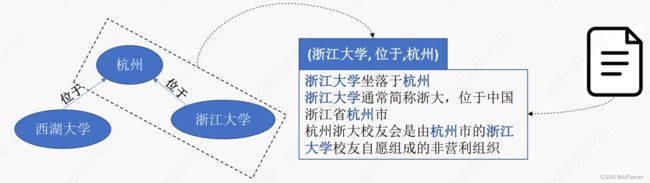
Distant supervision for relation extraction without labeled data. (ACL2009)
远程监督-基于多实例学习(降噪学习)
-
包含相同实体对的句子组成一个Bag
-
基于注意力机制选择样本
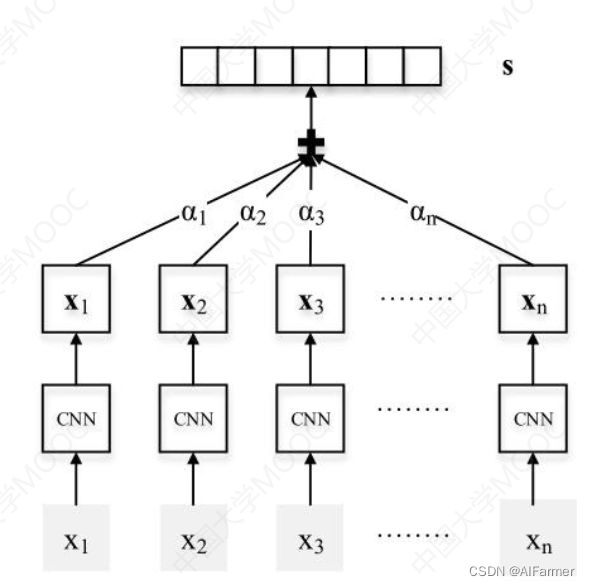
Neural Relation Extraction with Selective Attention over Instances. (ACL2016)
远程监督-强化学习(降噪学习) -
采取强化学习方式在考虑当前句子的选择状态下选择样例
-
关系分类器向样例选择器反馈,改进选择策略
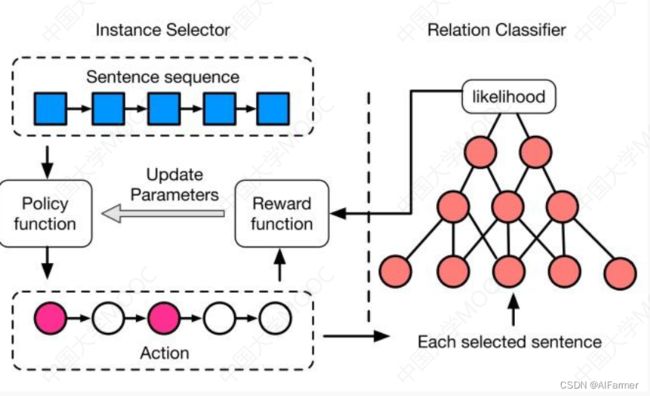
Reinforcement Learning for Relation Extraction from Noisy Data. (AAAI2018)
半监督学习—基于Bootstrapping的关系抽取

Bootstrap-Neural Snowball:
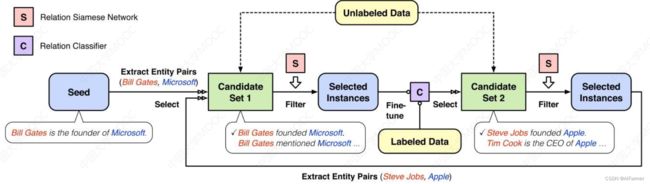
Bootstrapping的语义漂移问题

新增加的实例与种子实例不相关或不属于同一类型, 称为Bootstraping的语义漂移问题
语义漂移问题的一些解决方法:
- 限制迭代次数
- 采用语义类型Semantic Type对样本进行过滤和约束
–⟨ Organization⟩ ’s headquarters in ⟨ Location⟩ ⟨ Location⟩ -based ⟨ Organization⟩ ⟨ Organization⟩ , ⟨ Location⟩ - 对抽取结果进行类型检查
- 耦合训练

5)属性补全
属性补全: 任务定义
- 属性知识
▲一个事物若干属性的取值来对这个事物进行多维度的描述 - 属性补全
▲对实体拥有的属性及属性值进行补全 - 方法
▲抽取式
–基于模板
–基于机器学习模型
▲生成式
–基于机器学习模型
属性补全的方法:
- 抽取式属性补全:抽取输入文本中的字词, 组成预测的属性值。 预测出的属性值一定要在输入侧出现过

- 生成式属性补全:直接生成属性值, 而这个属性值不一定在输入文本中出现, 只要模型在训练数据中见过即可
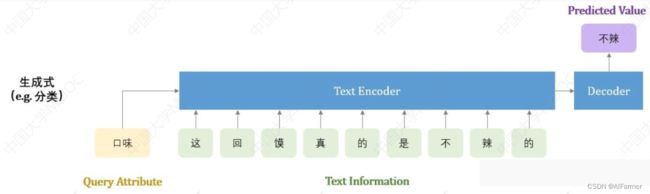
属性补全方法比较 - 抽取式
▲只能抽取在输入文本中出现过的属性值
▲预测属性值一定在输入中出现过, 具有一定可解释性, 准确性也更高 - 生成式
▲可以预测不在文本中出现的属性值
▲只能预测可枚举的高频属性, 导致很多属性值不可获取
▲预测出来的属性值没有可解释性
属性补全应用-商品属性补全
- 商品关键属性补全
▲利于买家选择
▲利于提升导购
▲利于优质选品 - 方法
▲借助算法的图文识别能力, 通过商品图片预测商品的类目、 同款、品牌
小结:
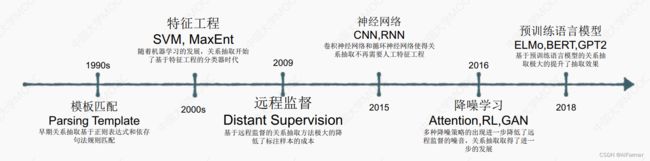
关系抽取方法的演变
一个基于深度学习的开源中文关系抽取框架学习地址
一个基于深度学习的开源中文关系抽取框架
4.4 知识抽取——概念抽取
4.4.1 构建概念知识图谱
(1)任务定义
- 概念知识图谱的组成
▲isA关系、 subclassOf关系
▲通常用于本体构建 - 实体
▲比如“浙江大学” - 概念
▲比如“高校” - 实体和概念之间的关系(isA)
▲比如“浙江大学” isA“高校” - 概念与概念之间的关系(subClassOf)
▲比如“高校” isA“学校”
(2)概念知识的价值
- 概念是认知的基石
▲概念认知同类实体,例如, 昆虫这一概念使得我们能够认知各种各样的昆虫, 无需纠缠细节的不同 - 概念可以更好的理解自然语言
▲用小号试探男朋友。 小号 isA 辅助账号 - 概念可以用于解释现象
▲遇到老虎为什么要跑? 老虎是食肉动物

(3)概念的上下位关系
-
实体、 概念通常基于词汇进行表达
-
实体与概念, 概念与概念之间的关系属于自然语言处理中的语言上下位关系
例如:A isA B, 通常称A是B的下位词, B是A的上位词 -
概念抽取并构建成无环图的过程又被称为Taxonomy
(4)概念抽取的方法

1)概念抽取的方法: 基于模板 -
Hearst Patterns: 基于固定的句型可以抽取isA关系
下面的左图列出了一些Hearst pattern的例子,右图举了一些符合Hearst pattern的例子

2) 概念抽取的方法: 基于模板 -
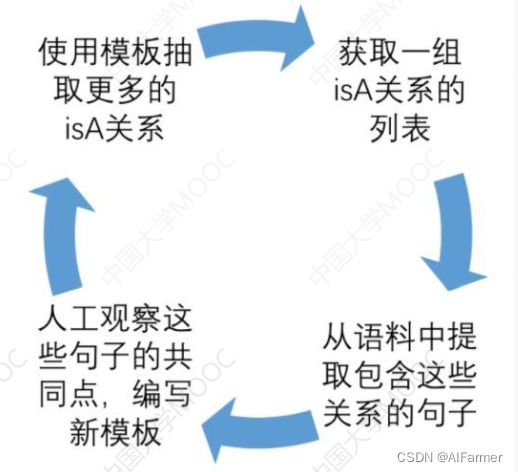
由于构造和维护模板的成本都比较高, 人们又发明了Boostrapping的方法,通常由专家构造种子Hearst Pattern, 然后基于Boostrapping半自动产生新模板。
3)概念抽取的方法: 基于百科 -
概念知识抽取
从半结构化数据中获取上下文关系,验证抽取的结果

-
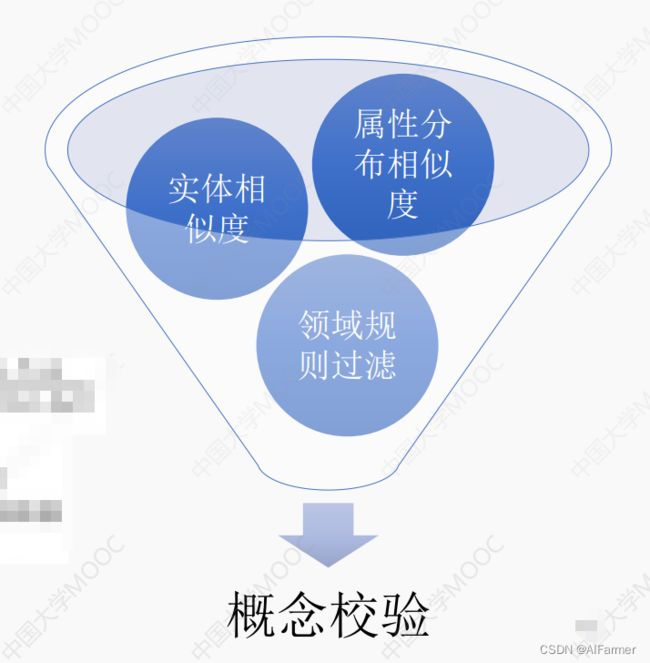
概念知识验证
▲目标:输入概念知识, 判断是否合法
▲方法:互斥概念发现,例如e.g., 刘德华 isA 香港演员 V.S. 内地演员
▲实体相似度
▲属性分布相似度
▲领域规则过滤

4) 概念抽取的方法: 基于机器学习 -
从大量文本中获取概念知识
▲基于序列标注模型
▲需要大量标注样本
▲基于模板匹配的弱监督
4.4.2 中文概念知识图谱
- OpenConcept: 浙江大学知识引擎实验室开发和维护
▲一个大规模的中文开放领域概念知识图谱
▲400万概念核心实体和1200万实体-概念三元组
▲赋能推荐、 问答、 对话等应用
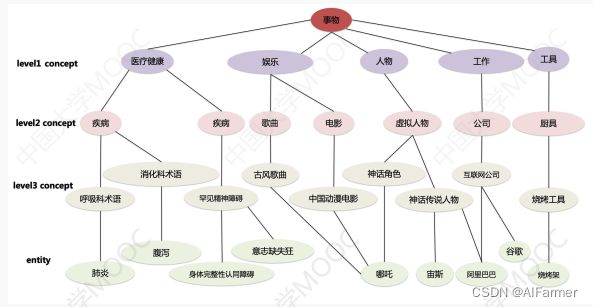
(1) 概念知识的应用:自然语言理解 - 概念知识可以帮助机器理解自然语言

(2)概念知识的应用: 搜索
概念知识可以帮助理解搜索意图, 获得更加准确的结果
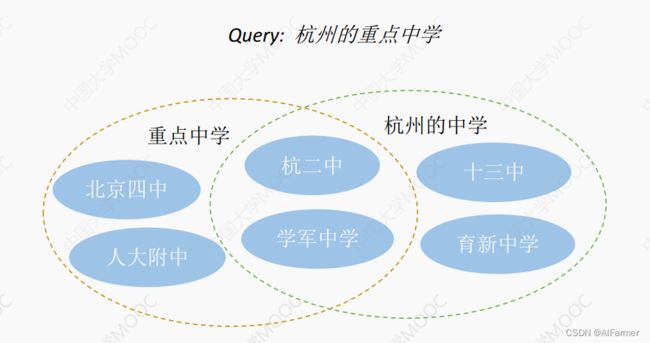
小结
- 概念(Concept)是人类在认识过程中, 从感性认识上升到理性认识, 把所感知的事物的共同本质特点抽象出来的一种表达
- 概念知识一般可以通过基于模板、 基于百科和基于序列标注等方法进行获取
- 概念知识可以帮助自然语言理解, 促进搜索、 推荐等应用的效果
4.5 知识抽取——事件识别与抽取
4.5.1 事件的定义
事件是发生在某个特定的时间点或时间段、 某个特定的地域范围内, 由一个或者多个角色参与的一个或者多个动作组成的事情或者状态的改变 。
- 不同的动作或者状态的改变代表不同类型的事件
- 同一个类型的事件中不同的要素代表了不同的事件实例
- 同一个类型的事件中不同粒度的要素代表不同粒度的事件实例
4.5.2 事件抽取的定义
从无结构文本中自动抽取结构化事件知识:什么人/组织, 什么时间, 在什么地方, 做了什么事等等。

4.5.3 事件抽取: 事件发现和分类
- 事件发现和分类
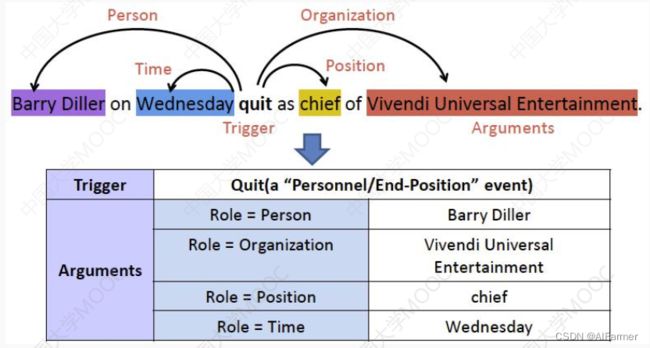
▲识别触发词(Trigger) : 体现发生事件的核心词语, 比如这里的quit
▲分类事件类型(Event Type) : 比如“离职” 事件

4.5.4 事件抽取:事件要素抽取
- 识别事件要素(Event Argument) : 参与事件的实体
- 分类要素的角色(Argument Role) : 参与事件的实体在事件所扮演的角色
(1)事件抽取的方法: 模式匹配 - 基于人工标注语料的模式匹配:模板的产生完全基于人工标注语料, 学习效果高度依赖于人工标注质量
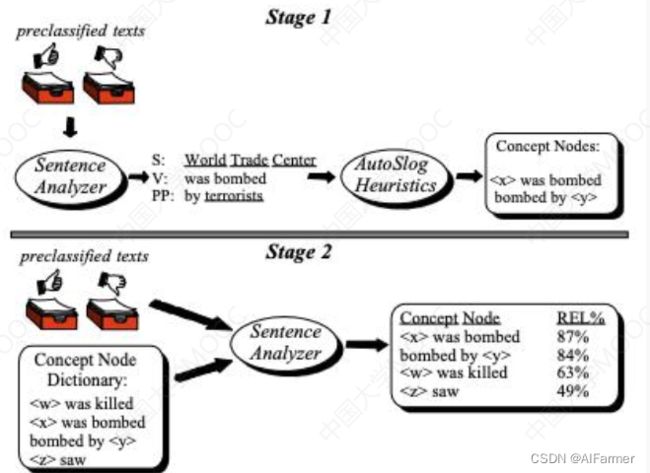
- AutoSlog
a. 事件元素首次提及之处即可确定该元素与事件间的关系
b. 事件元素周围的语句中包含了事件元素在事件中的角色描述

- 基于弱监督的模式匹配
▲人工标注耗时耗力, 且存在一致性问题
▲弱监督方法不需要对语料进行完全标注 - AutoSlog-TS
▲核心思想: 在相关文本中更常出现的抽取规则更有可能是好的抽取规则
基于模式匹配的方法小结 - 基于模式匹配的方法在特定领域中性能较好, 便于理解和后续应用, 但对于语言、 领域和文档形式都有不同程度的依赖, 覆盖度和可移植性较差
- 模式匹配的方法中, 模板准确性是影响整个方法性能的重要因素, 主要特点是高准确率低召回率
(2)事件抽取的方法:机器学习
1) 基于特征的方法
▲词性
▲实体类型
▲依存树
▲N元组

Joint event extraction via structured prediction with global features. (ACL2013)
2)基于结构预测的方法
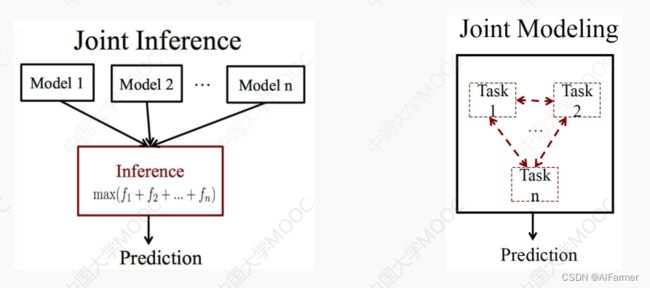
- Joint Inference 将各模型通过整体优化目标整合起来, 可以通过整数规划等方法进行优化。
- Joint Modeling (Structured) 将事件结构看作依存树, 抽取任务相应转化为依存树结构预测问题
3)基于神经网络的事件抽取模型: DMCNN

Event Extraction via Dynamic Multi-Pooling Convolutional Neural Networks. (ACL2015)
4) 基于机器学习方法的挑战 - 基于神经网络的事件抽取需要大量标注样本
▲样本难标注
▲远程监督困难
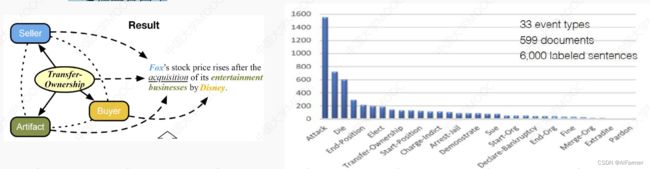
- FrameNet和事件抽取有着很高的相似性
- ACE 语料训练的分类器去判定FrameNet中句子的事件类别, 再利用全局推断将FrameNet的语义框架和ACE中的事件类别进行映射
| 框架名 | FrameNet 例句 | 类型 |
|---|---|---|
| Attack | AeroPlane Bombed London | Attack |
| Fining | The court fined her 40 | Fine |
| Execution | He was executed yesterday | Execute |

Leveraging FrameNet to Improve Automatic Event Detection. (ACL 2016)
4.5.5 中文事件抽取
中文事件抽取数据集

- 中文事件抽取特有的问题
▲不同的分词策略
▲中文词汇特征
▲形态时态没有明显变化
小结
- 事件抽取主要分为 事件的发现与分类 和 事件要素抽取 两部分, 又可以细分为触发词识别与事件分类 和要素检测与要素角色分类
- 与关系抽取相比, 事件抽取是一个更加困难和复杂的任务
- 事件结构远比实体关系三元组复杂, 事件的Schema结构对事件抽取有很强的约束作用
4.6知识抽取技术前沿

4.6.1 少样本知识抽取
- 我们需要更加高效的学习算法, 仅需少量样本便可以学会新知识
- 少样本学习
▲N-way-K-shot
▲原型网络
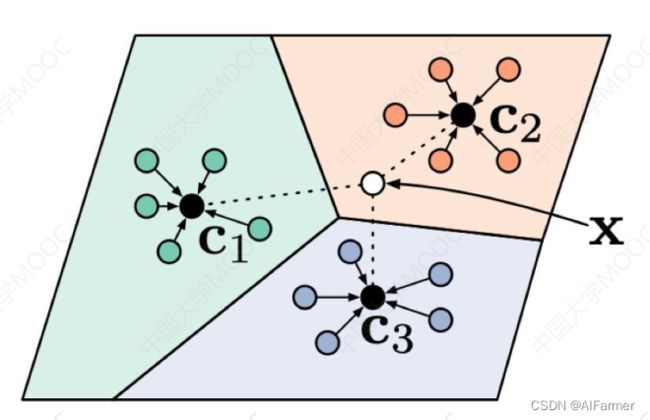
Prototypical networks for few-shot learning. (NeurIPS2017)
(1)基于混合注意力原型网络的少样本关系抽取 - 少样本问题特性容易受到噪声干扰
- 引入混合注意力机制
▲Instance-Level Attention
▲Feature-Level Attention

Hybrid Attention-based Prototypical Networks for Noisy Few-Shot Relation Classification. (AAAI2019)
(2)基于实体关系原型网络的少样本知识抽取
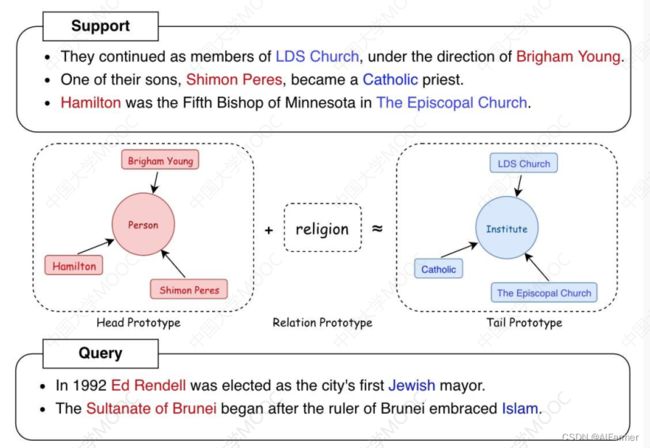

Bridging Text and Knowledge with Multi-Prototype Embedding for Few-Shot Relational Triple Extraction. (COLING2020)
4.6.2 零样本知识抽取
- 零样本学习(ZSL)
▲基于可见标注数据集及可见标签集合,学习并预测不可见数据集结果 - 方法
▲转换问题设定
▲学习输入特征空间到类别描述的语义空间的映射

(1)基于阅读理解的零样本关系抽取 - 将零样本关系抽取问题转换成阅读理解
已知实体对中的一个实体以及它们之间的关系, 去抽取另一个实体
| Relation | Question | Sentence & Answers |
|---|---|---|
| educated_at | What is Albert Einstein’s alma mater? | Albert Einstein was awarded a PhD by the Universityof Ziirich, with his dissertation titled… |
| occupation | What did Steve Jobs do for a living? | Steve Jobs was an American businessman.inventorand industrial designer. |
| spouse | Who is Angela Merkel married to? | Angela Merkel’s second and current husband is quantumchemist and professor Joachim Sauer, who has largely… |
Zero-Shot Relation Extraction via Reading Comprehension. (CONLL2017)
(2)基于规则引导的零样本关系抽取
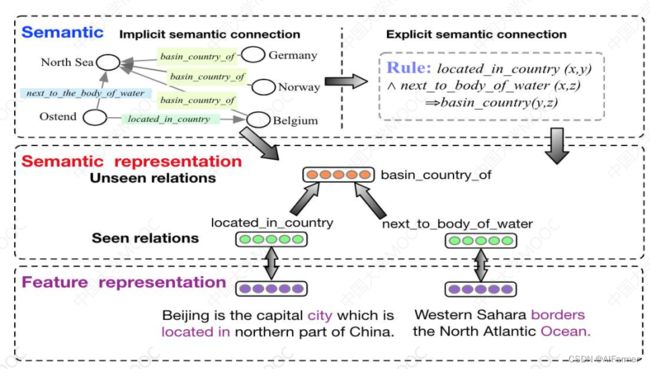
Logic-guided Semantic Representation Learning for Zero-Shot Relation Classification. (COLING2020)
(3)终身知识抽取
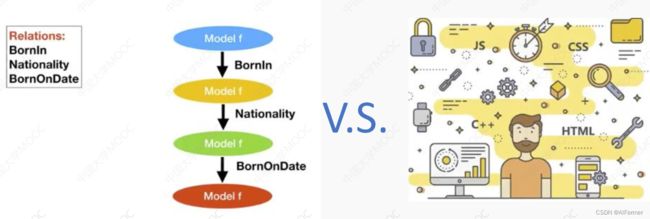
基于表示对齐的终身关系抽取
- 如何避免灾难性遗忘:对齐句子表示, 减少向量的变化
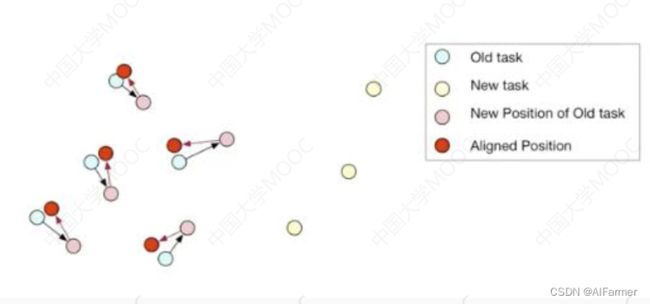

Sentence Embedding Alignment for Lifelong Relation Extraction. (NAACL2019)
小结 – 知识抽取的未来展望
- 举一反三, 面对低资源少样本场景, 我们需要更加智能的少样本零样本知识抽取方法
- 与时俱进, 知识是不断变化的, 我们需要能够终身学习知识的框架
更新时间:2023年5月16日15:30:41