【论文阅读】通过自适应表面细化从 NeRF 恢复精细的纹理网格
【论文阅读】通过自适应表面细化从 NeRF 恢复精细的纹理网格
- Abstract
- 1. Introduction
- 2. Related Work
-
- 2.1. NeRF for Scene Reconstruction
- 2.2. Surface Mesh for Scene Reconstruction
- 2.3. Extracting Surface Mesh from NeRF
- 3. Method
-
- 3.1. Efficient NeRF Training (Stage 1)
- 3.2. Surface Mesh Refining (Stage 2)
- 3.3. Mesh Exportation
- 4. Experiment
-
- 4.1. Implementation Details
- 4.2. Comparisons
-
- 4.2.1 Mesh Quality
- 4.2.2 Rendering Quality
- 4.3. Efficiency
- 4.4. Ablation Studies
- 5. Limitations and Conclusion

paper code
Abstract
神经辐射场 (NeRF) 在基于图像的 3D 重建领域取得了重大突破。然而,它们的隐式体积表示与广泛采用的多边形网格有很大不同,并且缺乏常见 3D 软件和硬件的支持,导致它们的渲染和操作效率低下。为了克服这个限制,我们提出了一种新颖的框架,可以从图像生成纹理表面网格。我们的方法首先使用 NeRF 有效地初始化几何结构和视图依赖性分解外观。随后,提取粗网格,并开发迭代表面细化算法,以根据重新投影的渲染误差自适应调整顶点位置和面密度。我们与几何共同细化外观,并将其烘焙成纹理图像以进行实时渲染。大量的实验表明,我们的方法实现了卓越的网格质量和有竞争力的渲染质量。
1. Introduction
从 RGB 图像重建 3D 场景是计算机视觉中的一项复杂任务,具有许多实际应用。近年来,神经辐射场(NeRF)[30,2,8,31]因其重建和渲染具有真实细节的大型场景的令人印象深刻的能力而受到欢迎。然而,NeRF 表示经常使用隐式函数和专门的光线行进算法进行渲染,由于硬件支持较差,导致它们难以操作且渲染缓慢,从而限制了它们在下游应用程序中的使用。相比之下,多边形网格是 3D 应用程序中最常用的表示形式,并且得到大多数图形硬件的良好支持以加速渲染。然而,由于网格的不规则性,直接重建网格可能具有挑战性,并且大多数方法仅限于固定拓扑或对象级重建。
最近的一些工作 [32,6,11,51] 侧重于结合 NeRF 和网格表示的优点。 MobileNeRF [11] 提出在网格上优化 NeRF 并将渲染权重二值化以合并实时渲染的光栅化。然而,生成的网格与表面网格不同,并且纹理位于特征空间而不是 RGB 空间中,因此难以编辑或操作。为了获得准确的表面网格,一种流行的方法是使用有符号距离场(SDF),它可以准确地定义表面[46,50,54]。然而,这方面的研究通常会生成过度平滑的几何体,无法对薄结构进行建模,并且常常忽略渲染质量。此外,通过Marching Cubes [28]获得的网格可能具有不准确的顶点位置和大量的面。 NVdiffrec [32] 使用可微光栅器 [22] 来优化可变形四面体网格,但仅限于对象级重建,也无法恢复复杂的拓扑。表示间隙的存在使得从体积 NeRF 恢复准确的表面网格同时保持渲染质量变得具有挑战性。
本文提出了一种名为 NeRF2Mesh 的新框架,用于从 RGB 图像中提取精致的纹理表面网格,如图 1 所示。我们的主要见解是细化从 NeRF 中提取的粗网格,以实现几何和外观的联合优化。体积 NeRF 表示适用于几何和外观的高效初始化。通过从 NeRF 中提取的粗网格,我们根据 2D 渲染误差调整顶点位置和面密度,这反过来又有助于外观优化。为了启用纹理编辑,我们 将外观分解为与视图无关的漫反射项和与视图相关的镜面反射项,因此可以将漫反射颜色导出为标准 RGB 图像纹理。镜面反射颜色导出为特征纹理,可以通过将其与当前观察方向一起馈送到嵌入片段着色器中的小型 MLP 来生成与视图相关的颜色。 总体而言,我们的框架能够创建多功能且实用的网格产品,这产品可用于对体积 NeRF 具有挑战性的一系列场景。
图 1:我们的框架 NeRF2Mesh 使用来自多视图 RGB 图像的漫反射和镜面纹理重建高质量的表面网格,很好地从对象级数据集推广到场景级数据集。导出的纹理网格可立即用于常见的图形硬件和软件,从而促进各种下游应用。
我们的贡献可以概括如下:
• 我们提出了 NeRF2Mesh 框架,通过联合细化从外观分解的 NeRF 中提取的粗网格的几何形状和外观,从多视图 RGB 图像重建纹理表面网格。
• 我们提出了一种自适应网格细化算法,该算法使我们能够调整面密度,其中根据重新投影的二维图像误差对复杂表面进行细分,并对较简单的表面进行抽取。
• 与最近的方法相比,我们的方法增强了表面网格质量、拥有相对较小的网格尺寸以及具有竞争力的渲染质量。此外,生成的网格可以使用常见的 3D 硬件和软件进行实时渲染和交互编辑。
2. Related Work
2.1. NeRF for Scene Reconstruction
NeRF [30] 及其后续工作 [2, 3, 56, 36, 48, 34, 48, 1, 7, 37] 代表了从 RGB 图像重建 3D 场景的显着进步。尽管具有出色的渲染质量,普通 NeRF 仍面临几个问题。例如,由于大量的MLP评估,模型的训练和推理速度很慢,这限制了NeRF表示的广泛采用。为了解决这个问题,一些工作 [53,38,41,31,8] 提出了减小 MLP 大小或完全消除它的方法,而是优化存储密度和外观信息的显式 3D 特征网格。 DVGO[41]采用两个密集特征网格进行密度和外观编码,但密集网格导致模型尺寸较大。为了有效控制模型大小,Instant-NGP[31]提出了多分辨率哈希表。除了效率问题之外,与多边形网格等显式表示不同,NeRF 的隐式表示在几何形状和外观上都无法直接操作和编辑。尽管一些作品[23,42,49,26,45] 探索了NeRF的几何操作和组合,但它们仍然在不同方面受到限制。另一方面,其他[57,5,55,40,4,44]旨在分解未知照明下的反射率,以实现重新照明和纹理编辑。这些问题导致 NeRF 表示与下游应用中广泛使用的多边形网格之间存在差距。我们的目标是通过探索将 NeRF 重建转换为纹理网格的方法来缩小这一差距。
2.2. Surface Mesh for Scene Reconstruction
直接重建显式表面网格可能具有挑战性,特别是对于具有复杂拓扑的复杂场景。该研究领域的大多数方法都假设具有固定拓扑的模板网格[9,10,20,25]。最近的方法[32,17,24,39]已经开始解决拓扑优化问题。 NVdiffrec [32] 将可微分行进四面体 [24] 与可微分渲染相结合,以直接优化表面网格。它还可以分解材质和照明,这在 NVdiffrecMC [17] 中使用蒙特卡洛渲染得到了进一步改进。尽管如此,这些方法仍然存在局限性,因为它们仅适用于对象级网格重建,并且难以区分无界室外场景中的背景和前景网格。必须准备前景掩模[32]以使用可微渲染来优化对象边界。相比之下,我们的重点是在没有先验知识的情况下在对象和场景级别重建表面网格。
2.3. Extracting Surface Mesh from NeRF
NeRF 使用体积密度场表示几何形状,不一定形成确定的表面。为了解决这个问题,一种流行的策略是学习有符号距离场(SDF)[46,50,14,15,54,47],其中表面可以由零水平集确定。 NeuS [46] 将 SDF 应用于密度变换以实现可微渲染,并且 Marching Cubes [28] 算法通常用于从这些体积中提取表面网格。并行工作 BakedSDF [51] 优化混合 SDF 体积表面表示并将其烘焙到网格中以进行实时渲染。然而,基于 SDF 的方法往往会学习过度平滑的几何形状,并且无法处理薄结构。一些方法[43, 27]探索无符号距离场(UDF)或密度场和SDF的组合来解决这一限制,但它们仍然仅限于对象级重建。 SAMURAI [6] 旨在联合恢复未知捕获条件下单个物体的相机姿势、几何形状和外观,并导出纹理网格。 MobileNeRF [11] 提出在mesh 格网上训练 NeRF,可以实时渲染。然而,它们的mesh并不完全是表面mesh,仅将特征导出为纹理,必须使用自定义着色器进行渲染并且不方便编辑。最近的工作 [31, 35] 发现指数密度激活可以帮助集中密度并形成更好的表面。我们也采用密度场来捕获复杂的拓扑并进一步细化表面。
3. Method
在本节中,我们将介绍我们的框架,如图 2 所示,用于从与常见 3D 硬件和软件兼容的 RGB 图像集合重建纹理表面网格。训练过程包括两个阶段。首先,我们训练基于网格(grid-based)的 NeRF [31] 以有效地初始化网格的几何形状和外观(第 3.1 节)。接下来,我们提取粗糙的表面网格并微调表面几何形状和外观(第 3.2 节)。训练完成后,我们可以以标准格式(例如 wavefront OBJ (OBJ是Wavefront科技开发的一种几何体图形文件格式。该格式最初是为动画工具Advanced Visualizer开发,现已开放,很多其它三维图形软件中都有使用)和 PNG)导出纹理表面网格,这些格式可供各种下游应用程序使用(第 3.3 节)。
图 2:NeRF2Mesh 框架。几何形状最初是通过密度格网学习的,然后提取以形成粗网格。我们将其优化为具有更精确表面和自适应面密度的细网格。外观是通过颜色网格学习的,并分解为漫反射和镜面反射项。收敛后,我们可以导出精细网格,展开其 UV 坐标并烘焙纹理 (“烘焙”是将3D网格的几何特征保存到纹理文件(位图文件)的过程的名称。英文名称叫 [Bake] ,从3D物体属性上(环境光遮蔽、法线、顶点颜色、方向、曲率、位置等)把多种组合的特性(包括材质、纹理和照明)进行烘焙为单个纹理,然后又可以使用对象的UV坐标将图像纹理重新映射到模型对象)。
3.1. Efficient NeRF Training (Stage 1)
在初始阶段,我们利用体积 NeRF 表示来恢复任意场景的几何形状和外观。此阶段的主要目标是有效地建立拓扑精确的几何形状和分解的外观,为后续的表面网格细化阶段做好准备。虽然直接研究多边形网格 [32] 对学习复杂几何形状提出了挑战,但体积 NeRF [30] 提供了一种更容易访问的替代方案。
我们遵循基于格网的 NeRF [31,41,8,38] 的最新进展,通过采用两个独立的特征格网来表示 3D 空间来提高 NeRF 的效率。尽管由于密度可能分散在整个空间中,表面可能缺乏精度,但这些问题可以通过下一阶段的网格细化来解决。
Geometry. 几何学习是通过密度格网[31]和浅层 MLP 来促进的,表达如下:

其中 φ φ φ 是促进更清晰表面的指数激活 [31], E g e o E^{geo} Egeo 是可学习的多分辨率特征网格, x ∈ R 3 x ∈ \mathbb{R} ^3 x∈R3 是任何 3D 点的位置。
Appearance Decomposition. NeRF 通常在不假设照明或材料特性的情况下运行。因此,之前的工作主要采用以 3D 位置和 2D 视图方向为条件的 5D 隐式函数来对依赖于视图的外观进行建模。尽管实现了照片级真实感的性能,但这种方法将外观呈现为黑匣子,这使得用传统的 2D 纹理图像表示具有挑战性。
为了解决这个问题,我们使用颜色格网和两个浅 MLP 将外观分解为与视图无关的漫反射颜色 c d c_d cd 和与视图相关的镜面反射颜色 c s c_s cs,表示如下:

其中 ψ ψ ψ 表示 sigmoid 激活, f s f_s fs 表示位置 x x x 处镜面反射颜色的中间特征, d d d 表示视图方向。最终颜色是通过将两项相加获得的:
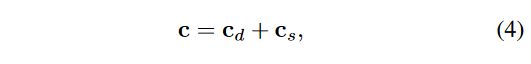
如图 3 所示,我们成功分离了漫反射项和镜面反射项。 R 3 \mathbb{R} ^3 R3中的漫反射颜色可以方便地烘焙为RGB图像纹理。同时,镜面反射特征 f s f_s fs 也可以被烘焙为纹理,并且小 M L P 2 MLP_2 MLP2 可以适合下面的片段着色器[11]。因此,镜面反射颜色也可以在以后导出和渲染(详细信息请参见第 3.3 节)。值得注意的是,我们的方法涉及将光照条件烘焙到纹理中。这是因为估计环境光照对于现实数据集来说可能具有挑战性,并且之前的研究已经观察到这可能会导致渲染质量降低 [57, 32]。

图 3:漫反射颜色和镜面反射颜色的分离。
Loss function. 为了优化我们的模型,我们遵循原始 NeRF 的渲染损失。给定一条从 o o o 发出、方向为 d d d 的射线 r r r,我们在位置 x i = o + t i d x_i = o + t_id xi=o+tid 处查询模型,沿着射线顺序采样,以获得密度 σ i σ_i σi 和颜色 c i c_i ci。最终像素颜色是通过使用以下等式进行数值求积获得的:

其中 δ i = t i + 1 − t i δ_i = t_{i+1}−t_i δi=ti+1−ti 是步长, w i = 1 − e x p ( − σ i δ i ) wi = 1−exp(−σ_iδ_i) wi=1−exp(−σiδi) 是逐点渲染权重, T i T_i Ti 是透射率。我们最小化每个像素的预测颜色 C ^ ( r ) \hat C(r) C^(r) 和地面真实颜色 C ( r ) C(r) C(r) 之间的损失:

我们通过对镜面反射颜色应用 L1 正则化来鼓励分离漫反射和镜面反射项:

为了使表面更清晰,我们对渲染权重应用熵正则化:
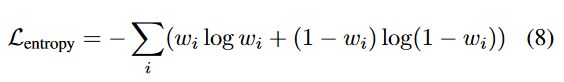
其中 w i w_i wi 是每点渲染权重。对于无界室外场景,我们还在密度场 E g e o E_{geo} Egeo 上应用全变分 (TV) 正则化来减少漂浮物 [41, 8]。
3.2. Surface Mesh Refining (Stage 2)
在第二阶段,我们从第一阶段的 NeRF 模型中提取粗糙的表面网格并进一步优化它。此过程涉及细化顶点、三角形和曲面上的外观,如图 4 所示。

图 4:mesh 细化。我们在第 2 阶段细化了粗mesh的几何形状和外观。
Appearance refining. 为了渲染图像,mesh 经过光栅化,并且 3D 位置以像素方式插值到图像空间上。由于像素颜色仍然以逐点方式查询,因此阶段 1 的外观模型可以继承到阶段 2。这消除了从头开始学习外观的需要,减少了阶段 2 收敛所需的训练步骤。公式 6 中的像素颜色损失仍然应用于第 2 阶段,以允许外观和几何形状的联合优化。
Iterative mesh refining. Marching Cubes [28] 从密度场中提取的粗网格通常存在缺陷。这些缺陷包括不准确的顶点和密集且均匀分布的面,导致磁盘存储空间巨大和渲染速度缓慢。 我们的目标是通过细化顶点位置和面密度来恢复类似于人造网格的精致网格。
给定初始粗网格 M c o a r s e = { V , F } \mathcal{M}_{coarse} = \{ \mathcal{V} ,\mathcal{F} \} Mcoarse={V,F},我们为每个顶点 v i ∈ V v_i ∈ \mathcal{V} vi∈V 分配一个可训练的偏移量 Δ v i Δv_i Δvi。我们使用可微渲染 [22],通过按照 [32] 反向传播图像空间损失梯度来优化这些偏移量。相比之下,网格面是不可微分的,并且不能以相同的方式通过反向传播进行优化。为了解决这个问题,我们提出了一种迭代网格细化算法,该算法受到迭代重加权最小二乘(IRLS)算法的启发[19]。关键思想是根据之前的训练误差自适应调整面密度。在训练期间,我们将公式 6 中的 2D 像素渲染误差重新投影到相应的网格面,并累积面误差。经过一定次数的迭代后,我们对所有面误差 E f a c e E_{face} Eface 进行排序,并确定两个阈值:

误差高于 e s u b d i v i d e e_{subdivide} esubdivide 的面将被中点细分 [12] 以增加面密度,而误差低于 e d c i m a t e e_{dcimate} edcimate 的面将被抽取并重新划分网格以降低面密度。网格更新后,我们重新初始化顶点偏移和面误差并继续训练。这个过程会重复几次,直到阶段 1 完成。
Unbounded scene. 在不失一般性的情况下,我们能够对前向[29]和大规模无界场景[3]进行建模。我们将场景划分为多个几何增长区域 [ − 2 k , 2 k ] 3 , k ∈ { 0 , 1 , 2 , ⋅ ⋅ ⋅ } [−2^k, 2^k]^3, k ∈ \{0, 1, 2, · · · \} [−2k,2k]3,k∈{0,1,2,⋅⋅⋅} 类似于 Instant-NGP [31]。每个区域导出一个单独的网格,重叠部分会自动删除以形成整个场景的几何体。由于与中心区域 (k = 0) 相比,外部区域通常缺乏细节,因此我们还会随着 k 的增加而降低行进立方体分辨率。 迭代网格细化仅考虑中心区域,因为外部区域的几何形状相对简单。Loss function. 为了防止几何形状突变,我们在网格上应用拉普拉斯平滑损失 L s m o o t h L_{smooth} Lsmooth [33]。此外,我们使用 L2 损失对顶点偏移进行正则化:

这可以确保顶点不会距离原始位置太远。
3.3. Mesh Exportation
我们框架的目标是导出具有与常用 3D 硬件和软件兼容的纹理的表面网格。目前,我们拥有第 2 阶段的表面网格 M f i n e M_{fine} Mfine,但外观仍以 3D 颜色网格进行编码。为了将外观提取为纹理图像,我们首先使用 XAtlas [52] 解包 M f i n e M_{fine} Mfine 的 UV 坐标。随后,我们将表面的漫反射颜色 c d c_d cd 和镜面反射特征 f s f_s fs 烘焙成两个单独的图像,分别为 I d I_d Id 和 I s I_s Is。
Real-time rendering. 我们导出的网格可以像传统的纹理网格一样有效地加速和实时渲染。漫反射纹理 I d I_d Id 可以解译为 RGB 纹理,并在大多数支持 OpenGL 的设备和 3D 软件包(例如 Blender [13] 和 Unity [16])中渲染。为了渲染镜面反射颜色,我们采用 MobileNeRF [11] 中提出的方法。我们导出小型 M L P 2 MLP_2 MLP2 的权重并将其合并到片段着色器中。此自定义着色器可以将镜面反射项添加到漫反射项中,从而实现实时的视点相关效果。
Mesh manipulation. 与传统的纹理网格类似,我们导出的网格可以在其几何和视觉属性方面轻松修改和编辑。此外,它还有助于组合多个导出的网格,如图 1 所示。
4. Experiment
4.1. Implementation Details
在第一阶段,我们训练 30, 000 步,每一步评估大约 2 1 8 2^18 218 个点。采用从 0.01 到 0.001 的指数衰减学习率计划。具体来说,在最初的 1, 000 步中,训练仅使用漫反射颜色来鼓励外观分解。对于第二阶段,我们基于收敛额外训练 10, 000 到 30, 000 个步,并将顶点偏移的学习率设置为 0.0001。 Adam [21] 优化器用于这两个阶段。通过 Marching Cubes 以 51 2 3 512^3 5123 的分辨率和 10 的密度阈值提取粗网格。我们剔除所有训练相机姿势中不可见的面,并将面的总数减少到 30, 000。我们遵循 Instant-NGP [31] 中提出的方法,维护一个密度网格以促进光线修剪。所有实验均在单个 NVIDIA V100 GPU 上进行。更多详情请参阅补充材料。
Datasets. 我们在三个数据集上进行实验,以验证我们方法的有效性和泛化能力:1)NeRF-Synthetic [30]数据集包含8个合成场景。 2)LLFF[29]数据集包含8个真实的前向场景。 3)Mip-NeRF 360 [3]数据集包含3个公开可用的真实无界室外场景。我们的方法可以很好地推广到不同类型的数据集,即使对于具有挑战性的无界场景也能重建真实的网格。
4.2. Comparisons
我们主要与导出纹理网格的方法进行比较,例如 MobileNeRF [11] 和 NVdiffrec [32]。由于我们的方法还涉及 NeRF 阶段,因此我们与几种体积 NeRF 方法 [30, 18] 的能力进行比较。
4.2.1 Mesh Quality
Surface reconstruction.
现实场景缺乏地面实况网格使得测量表面重建质量变得具有挑战性。因此,我们主要比较合成数据集的结果,如 NVdiffrec [32] 中所做的那样。我们对通过不同方法生成的提取网格进行定性评估,如图 5 所示。具体来说,我们重点关注密集树叶和绳网等薄结构。我们的方法成功地以高保真度重建了这些结构,而其他方法则无法准确地重建复杂的几何形状。此外,我们的方法生成的网格更加有序和整洁,类似于人造的地面实况。
图 5:NeRF 合成数据集的表面重建质量。与以前的方法相比,我们的方法实现了卓越的网格重建质量,特别是在具有复杂拓扑的薄结构上。我们将网格从 NeuS [46] 减少到原始面的 25%,因为它们太密集而无法可视化。
为了量化表面重建质量,我们采用倒角距离 (CD) 指标。然而,由于地面实况网格可能不是表面网格(例如,乐高网格实际上是由许多小砖块组成),因此我们从测试摄像机投射光线,并从每个场景的这些光线表面相交处采样 250 万个点。在表 1 中,我们展示了所有场景的平均 CD,表明我们的方法取得了最佳结果。我们注意到,我们的方法在具有复杂拓扑的场景(例如榕树、船舶和乐高)上表现特别好。然而,我们的方法在具有大量非朗伯表面的场景上表现稍差。这种限制是由于我们的外观网络的能力相对较小而产生的,因为我们的模型经常尝试通过调整网格顶点来模拟此类照明效果,从而导致几何形状不正确。

表 1:NeRF 合成数据集与地面实况网格相比的倒角距离 ↓(单位为 1 0 − 3 10^{−3} 10−3)。
Mesh size.
我们还通过比较导出网格中的顶点和面的数量来评估实际适用性,如表 2 所示。此外,我们还测量渲染导出网格所需的磁盘存储和 GPU 内存使用情况,如表 3 所示。公平比较,网格文件格式为未压缩的OBJ&MTL,纹理为PNG,其他元数据以JSON格式存储。与 NeRF 合成数据集上的真实数据和 MobileNeRF [11] 相比,我们导出的网格包含更少的顶点和面。这是因为迭代网格细化过程可以增加顶点数量以增强表面细节,同时减少面数量以控制网格尺寸。
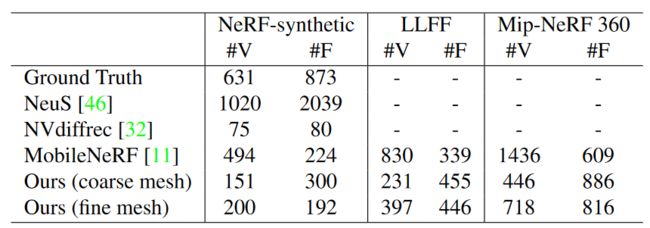
表2:顶点和面的数量↓(单位为103)。我们的方法在 NeRF 合成数据集上使用相对较少的顶点和面,并提高了网格质量。

表 3:磁盘存储和 GPU 内存使用情况 ↓(单位为 MB)。我们测量导出模型的大小和渲染中 GPU 内存的使用情况。
4.2.2 Rendering Quality

表 4:渲染质量比较。我们报告不同数据集上的 PSNR、SSIM 和 LPIPS,并与不同类别的方法进行比较。我们在体积网格和非表面网格方面实现了可比的性能,在表面网格方面实现了更好的性能。
我们在表 4 中展示了渲染质量比较的结果。我们观察到从 NeRF(体积)提取到网格时渲染质量有所下降。具体来说,我们发现平滑正则化项 L s m o o t h L_{smooth} Lsmooth 在保持表面平滑度和渲染质量之间的平衡方面起着至关重要的作用。禁用此正则化项会导致更好的渲染质量,但会牺牲表面质量(详见 4.4 节)。我们证明,与 NVdiffrec [32] 相比,我们基于网格的方法可产生卓越的渲染质量,NVdiffrec [32] 是目前表面网格重建的最先进技术。此外,我们的方法可以很好地推广到前向和无界场景,而 NVdiffrec [32] 只能重建单个对象。相比之下,MobileNeRF [11] 导出的网格状网格缺乏平滑度,并且可能无法与对象表面很好地对齐。这些网格依靠纹理透明度来雕刻表面。尽管我们的平滑网格表现出较差的渲染质量,但我们没有平滑正则化项的网格实现了可比的性能。图 6 展示了我们的网格渲染质量的可视化,并将其与相关方法进行了比较。

图 6:渲染质量的可视化。我们在不同的数据集上实现了可比较的渲染质量。
在图 7 中,我们还展示了通过不同方法导出的纹理图像。我们证明,我们的高质量表面网格产生的纹理图像比其他方法生成的纹理图像更紧凑、更直观。
图 7:纹理图像的可视化。我们表明,由于表面质量的提高,我们的纹理更加紧凑和直观。
4.3. Efficiency
我们的框架在训练和推理阶段都表现出高效率。具有 16GB 内存的单个 NVIDIA V100 GPU 大约需要 1 小时来训练两个阶段和每个场景的网格导出。相比之下,其他竞争方法通常需要几个小时[32]甚至几天[11],完成类似任务的硬件要求更高。此外,导出的网格是轻量级的,允许在支持 OpenGL 的设备(包括移动设备)上进行实时渲染。
4.4. Ablation Studies
在图 8 和表 5 中,我们进行了侧重于几何优化阶段的消融研究。具体来说,我们将完整模型与排除平滑正则化或迭代网格细化过程的变体进行比较。结果表明:1)当去除平滑度正则化时,生成的表面网格显示出更好的渲染质量,但表现出不规则性和自相交。此外,由于迭代网格细化过程无法很好地处理此类不规则表面,因此网格尺寸会增加。这些不规则的面还会导致 UV 质量差和纹理图像混乱。 2)当去除迭代网格细化时,面密度变得几乎均匀,导致网格尺寸更大并且渲染质量稍差。这是因为面部密度无法根据重新投影的渲染误差进行自适应调整。
图 8:定性消融。我们可视化不同设置下的网格结构和纹理图像。
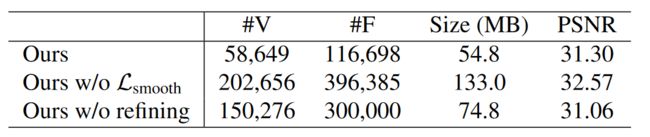
表 5:定量消融。我们报告麦克风场景的网格统计数据和 PSNR。
5. Limitations and Conclusion
尽管我们的方法已经显示出有希望的结果,但它仍然存在一些局限性。由于很难在不影响重建质量的情况下从图像中估计未知的照明条件[57],我们选择将照明烘焙到纹理中,从而限制了我们执行重新照明的能力。我们相对较小的外观网络也使得学习复杂的依赖于视图的效果变得具有挑战性,这可能导致这些区域的表面质量较低。这些选择是为了保持管道效率而有意做出的。未来,我们希望通过利用更好的外观建模技术来解决这些限制。最后,与其他基于网格的方法[32, 11]类似,我们执行单通道光栅化并且无法处理半透明对象。
总之,我们提出了一个有效的框架,可以从多视图 RGB 图像重建纹理表面网格。我们的方法利用 NeRF 进行粗略几何和外观初始化,随后提取并增强多边形网格,并最终将外观烘焙到纹理图像中以进行实时渲染。重建的网格表现出增强的表面质量,特别是对于薄结构,并且易于下游应用程序操作和编辑。