关系代数的问题与尝试(5)云数据组织
摘要: 本文来自北京润乾软件技术有限公司董事长蒋步星在清华大数据产业联合会的讲座。
最后再简单说一下云计算的数据组织问题。
云数据有这样几个特征:
第一,多样性。云计算要解决多租户的问题,显然不同用户的数据结构经常是不一样的,即使同一个用户、同一块业务,数据结构在不同地域、不同时期都会不一样。象我们这样一个小公司的财务系统,数据结构都年年在变,今年没有这种销售提成,明年有了,就要增加一些字段或表来处理。
数据的多样性其实是很本质的需求,世界就是这么复杂。多样性在关系数据库的时代也存在。只不过关系数据库的时代,因为应用范围比较小,一般只在一个机构甚至一个局部,这个矛盾还不是特别严重,能对付过去。但是到了云时代就不容易对付了。你面临的用户五花八门,想在云上给各种用户提供持续的服务,这个事就避不开了。
第二,分离性。不同时段、不同地方的数据是分开的,数据管理也需要联邦制,而不是单一制。比如说北京的数据,下面有海淀、朝阳这些,但是你要换成河北省,中间多了一层石家庄、保定这些地级市,层次不一样了,非要把他们搞成一样的数据结构就会别扭的。但关系代数在理论层面就要求单一性,数据结构就会很别扭。
分离性能带来多样性,但不只是多样性。有时候即使数据不多样也需要分离。比如北京的某种数据特别多,我要给它建索引,到了上海这类数据不多,就不需要建索引。关系数据理论上没有这种机制,只能在工程上去绕,实际上很多数据库厂家都会想办法做数据分区,但不从概念上支持会导致许多实施层面上的事情很难办。
第三,易计算性。这是最关键的一点。
把数据存起来不是问题,我们还要计算,如果不能计算,这个数据没有意义。
我们需要多样和分离的数据能够合在一起随意计算,这里重要的是要支持批量数据表的高阶集合运算,所谓高阶集合,就是集合的集合,我们面对多样性数据时会大量碰到这种高阶集合的运算。
关系代数所做的运算只涉及有限的几个表,你要明确写出来这个运算是针对哪几个表,如果需要运算的表也构成一个集合,那就在关系代数中就搞不出来了。
你很难想象在一个数据库里面有几万甚至几百万个表,当然我听说北京移动他们就有上万个表,历史积累下来,谁也不敢删这些表。关系数据库肯定不会提倡你在数据库中搞几万个表,但多样性的需求是客观存在的,现实中真地会有这么多种数据结构。如果我们把表也作为一种操作数据,提供高阶集合运算,可以针对这几万个表这样的集合做运算,这个问题就不再是问题。
当前几种主要技术中,SQL的易计算性还是不错的。这几年比较时髦的NoSQL对多样性的支持更好,但严重牺牲了易计算,分离性也一般。SQL的易计算好,但是分离性和多样性比较差。直接操作文件系统,比如Hadoop这种东西,多样性、分离性都好,但是几乎没有什么易计算性。
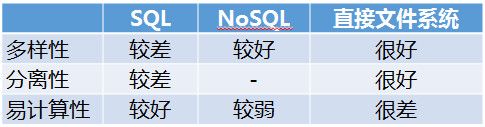
我们希望设计一个这三个指标都好的东西,这样才能够适合云计算,缺一个都很麻烦。
我的设计想法是模拟日常的纸张文档。
基本的数据单元用于保证多样性,数据结构附在这个数据单元中,不同数据单元可以有不同的数据结构,还可以有子数据结构,比如一个人除了姓名、性别这些外,还可能有家庭成员、工作履历等,可以是一条,也可以多条,都放在一起。这种数据我称为超结构化数据,这种存储试的坏处是运算效率会低一点,不过OLTP这种业务一般单个任务涉及数据量并不大,多样性带来的性能损失对现代计算机来讲还是可以容忍的。
采用树形目录的机制存储数据单元来保证分离性,就象平常大文件夹套小文件夹那样保管纸张。关系数据库实际是一种线状结构,所有表排成一条线,即使考虑模式概念,也最多有两层。
然后,这里的关键是,我们要求在树的目录上带有信息,实际上我们日常存放纸文档的时候就是这么做的,我在文件夹上写了财务部,里面的纸张就可以不再写财务部了。这样的好处是可以随意变动层次,或者搬动数据。比如北京数据就是两层,到了河北就变成三层,中间多了一个地级市。
纸张的机制用于存储是没有问题的,但纸张几乎没有任何计算能力。而我们的任务就是要加上这个能力。
这就要用到刚才说的高阶集合运算,要在这些多样的树形分离方式存储的数据单元上定义批量的数据计算,我一次可以算多个目录,包括多个数据单元,每一个数据单元不止一个记录,就像一个小表一样,我都可以计算。
分离性可以使数据之间耦合度降低,我只算北京海淀区的数据时,你把CPU累死,山东人民根本不在乎,完全感觉不到。这两个区域的数据是无关的。既可以统一计算,又是分离的。
这方面的研究我们现在也还比较初级,我们现在基于普通的文件系统并结合前面提到的自己开发的程序设计语言实现了一个数据库的原型,逻辑上多样性、分离性和易计算性都达到了,但计算效率还比较差,尚不能达到实用阶段,下面会进一步做工程上的优化。
今天讲了关系代数的这些问题,并针对每个问题也都大体提出来解决方案的设想及尝试性的产品,但现在的方案还是针对每个问题分别处理的,比如解决关联描述问题的方案中没去管多层表格的交互问题,目前我们还没能设计一个大一统的代数体系把所有问题放在一个框架内解决,这是我希望能在今后几年内能做到的事情。
最后,第一次做这么大范围交流,我想借这个机会诠释一下我们公司的这句口号,让大家更多的了解润乾公司。

我们希望推动的是应用的进步,今天讲的内容看起来很理论,但我们并不是做纯理论研究的,搞理论是为了让它能够应用,必须能够工程化才有意义。
另外,我们推动应用进步是靠技术,而不是靠资金、管理、商业模式等别的东西,那些我们都不擅长;最关键的,这个技术必须是创新的,拥有了核心技术,并且不断推陈出新,否定自我,才能够在市场中不断前进。
今天就报告这些内容,谢谢大家!