doris多租户资源隔离及权限管理
Doris 的多租户和资源隔离方案,主要目的是为了多用户在同一 Doris 集群内进行数据操作时,减少相互之间的干扰,能够将集群资源更合理的分配给各用户。
该方案主要分为两部分,一是集群内节点级别的资源组划分,二是针对单个查询的资源限制。
下面实验使用的doris版本为: doris-1.2.2-rc01
可以从这里查看doris的各版本及发布日期
https://doris.apache.org/zh-CN/download

一、节点资源划分
首先,简单介绍一下 Doris 的节点组成。一个 Doris 集群中有两类节点:Frontend(FE) 和 Backend(BE)。
FE 主要负责元数据管理、集群管理、用户请求的接入和查询计划的解析等工作。
BE 主要负责数据存储、查询计划的执行等工作。
FE 不参与用户数据的处理计算等工作,因此是一个资源消耗较低的节点。而 BE 负责所有的数据计算、任务处理,属于资源消耗型的节点。因此,本文所介绍的资源划分及资源限制方案,都是针对 BE 节点的。FE 节点因为资源消耗相对较低,并且还可以横向扩展,因此通常无需做资源上的隔离和限制,FE 节点由所有用户共享即可。
**节点资源划分**,是指将一个 Doris 集群内的 BE 节点设置标签(Tag),标签相同的 BE 节点组成一个资源组(Resource Group)。资源组可以看作是数据存储和计算的一个管理单元。下面我们通过一个具体示例,来介绍资源组的使用方式。
1. 为 BE 节点设置标签
当前 Doris 集群有 3个 BE 节点。在初始情况下,所有节点都属于一个默认资源组(Default)。
mysql -h 192.168.129.124 -P 9030 -uroot -ptydic123
mysql> select ip,HeartbeatPort,Tag from information_schema.backends order by ip;
+-----------------+---------------+--------------------------+
| ip | HeartbeatPort | Tag |
+-----------------+---------------+--------------------------+
| 192.168.129.124 | 9050 | {"location" : "default"} |
| 192.168.129.125 | 9050 | {"location" : "default"} |
| 192.168.129.126 | 9050 | {"location" : "default"} |
+-----------------+---------------+--------------------------+
3 rows in set (0.87 sec)
我们可以使用以下命令将这3个节点划分成3个资源组:group_a、group_b、group_c
mysql> alter system modify backend "192.168.129.124:9050" set ("tag.location" = "group_a");
Query OK, 0 rows affected (0.05 sec)
mysql> alter system modify backend "192.168.129.125:9050" set ("tag.location" = "group_b");
Query OK, 0 rows affected (0.01 sec)
mysql> alter system modify backend "192.168.129.126:9050" set ("tag.location" = "group_c");
Query OK, 0 rows affected (0.01 sec)
mysql> select ip,HeartbeatPort,Tag from information_schema.backends order by ip;
+-----------------+---------------+--------------------------+
| ip | HeartbeatPort | Tag |
+-----------------+---------------+--------------------------+
| 192.168.129.124 | 9050 | {"location" : "group_a"} |
| 192.168.129.125 | 9050 | {"location" : "group_b"} |
| 192.168.129.126 | 9050 | {"location" : "group_c"} |
+-----------------+---------------+--------------------------+
3 rows in set (0.28 sec)
每个BE节点只能设置一个Tag,多个BE节点可以设置相同的Tag。
2. 按照资源组分配数据分布
-- replication_allocation指定表副本分布在哪些资源组,以及每个资源组的副本数(小于等于资源组内BE个数)。
create table UserTable
(k1 int, k2 int)
distributed by hash(k1) buckets 1
properties(
"replication_allocation"="tag.location.group_a:1, tag.location.group_b:1, tag.location.group_c:1"
);
-- 每个资源组下会保存指定数量的副本
insert into UserTable values(1,7);
┌────────────────────────────────┐
│ │
│ ┌──────────────────┐ │
│ │ host124 │ │
│ │ ┌─────────────┐ │ │
│ group_a │ │ replica1 │ │ │
│ │ └─────────────┘ │ │
│ │ │ │
│ └──────────────────┘ │
│ │
├────────────────────────────────┤
├────────────────────────────────┤
│ │
│ ┌──────────────────┐ │
│ │ host125 │ │
│ │ ┌─────────────┐ │ │
│ group_b │ │ replica2 │ │ │
│ │ └─────────────┘ │ │
│ │ │ │
│ └──────────────────┘ │
│ │
├────────────────────────────────┤
├────────────────────────────────┤
│ │
│ ┌──────────────────┐ │
│ │ host126 │ │
│ │ ┌─────────────┐ │ │
│ group_c │ │ replica3 │ │ │
│ │ └─────────────┘ │ │
│ │ │ │
│ └──────────────────┘ │
│ │
└────────────────────────────────┘
3. 使用不同资源组进行数据查询
可以通过设置用户的资源使用权限,来限制某一用户的查询,只能使用指定资源组中的节点来执行。
比如,我们可以通过以下语句,限制 user1 只能使用 group_a 资源组中的节点进行数据查询,user2 只能使用 group_b 资源组,而 user3 可以同时使用 3 个资源组:
-- 创建用户
CREATE USER 'user1' IDENTIFIED BY 'tydic123';
CREATE USER 'user2' IDENTIFIED BY 'tydic123';
CREATE USER 'user3' IDENTIFIED BY 'tydic123';
-- 赋权
GRANT ALL ON example_db TO user1;
GRANT ALL ON example_db TO user2;
GRANT ALL ON example_db TO user3;
-- 分配资源组
set property for 'user1' 'resource_tags.location' = 'group_a';
set property for 'user2' 'resource_tags.location' = 'group_b';
set property for 'user3' 'resource_tags.location' = 'group_a, group_b, group_c';
设置完成后,user1 在发起对 UserTable 表的查询时,只会访问 group_a 资源组内节点上的数据副本,并且查询仅会使用 group_a 资源组内的节点计算资源。而 user3 的查询可以使用任意资源组内的副本和计算资源。

 在125机器使用bin/stop-be.sh停止125的BE(tag:group_b)节点之后, 只能使用该节点的user2查询失败,而user1和user3可以正常使用各自指定的BE节点查询不受影响。
在125机器使用bin/stop-be.sh停止125的BE(tag:group_b)节点之后, 只能使用该节点的user2查询失败,而user1和user3可以正常使用各自指定的BE节点查询不受影响。
select * from UserTables;

4. 导入作业的资源组分配
导入作业(包括insert、broker load、routine load、stream load等)的资源使用可以分为两部分:
- 计算资源:负责读取数据源、数据转换和分发。
- 写入资源:负责数据编码、压缩并写入磁盘。
其中写入资源必须是数据副本所在的节点,而计算资源理论上可以选择任意节点完成。所以对于导入作业的资源组的分配分成两个步骤:
- 使用用户级别的 resource tag 来限定计算资源所能使用的资源组。
- 使用(目标表)副本的 resource tag 来限定写入资源所能使用的资源组。
所以如果希望导入操作所使用的全部资源都限定在数据所在的资源组的话,只需将用户级别的 resource tag 设置为和副本的 resource tag 相同即可。
二、单查询资源限制
资源组方法是节点级别的资源隔离和限制。而在资源组内的资源抢占问题,可以使用对单查询的资源限制功能来解决。
目前 Doris 对单查询的资源限制主要分为 CPU 和 内存限制两方面。
-
内存限制
Doris 可以限制一个查询被允许使用的最大内存开销。以保证集群的内存资源不会被某一个查询全部占用。我们可以通过以下方式设置内存限制:
# 设置会话变量 exec_mem_limit。则之后该会话内(连接内)的所有查询都使用这个内存限制。 set exec_mem_limit=1G; # 设置全局变量 exec_mem_limit。则之后所有新会话(新连接)的所有查询都使用这个内存限制。 set global exec_mem_limit=1G; # 在 SQL 中设置变量 exec_mem_limit。则该变量仅影响这个 SQL。 select /*+ SET_VAR(exec_mem_limit=1G) */ id, name from tbl where xxx;因为 Doris 的查询引擎是基于全内存的 MPP 查询框架。因此当一个查询的内存使用超过限制后,查询会被终止。因此,当一个查询无法在合理的内存限制下运行时,我们就需要通过一些 SQL 优化手段,或者集群扩容的方式来解决了。
-
CPU 限制
用户可以通过以下方式限制查询的 CPU 资源:
# 设置会话变量 cpu_resource_limit。则之后该会话内(连接内)的所有查询都使用这个CPU限制。 set cpu_resource_limit = 2 # 设置用户的属性 cpu_resource_limit,则所有该用户的查询情况都使用这个CPU限制。该属性的优先级高于会话变量 cpu_resource_limit set property for 'user1' 'cpu_resource_limit' = '3';cpu_resource_limit的取值是一个相对值,取值越大则能够使用的 CPU 资源越多。但一个查询能使用的CPU上限也取决于表的分区分桶数。原则上,一个查询的最大 CPU 使用量和查询涉及到的 tablet 数量正相关。极端情况下,假设一个查询仅涉及到一个 tablet,则即使cpu_resource_limit设置一个较大值,也仅能使用 1 个 CPU 资源。
通过内存和CPU的资源限制。我们可以在一个资源组内,将用户的查询进行更细粒度的资源划分。比如我们可以让部分时效性要求不高,但是计算量很大的离线任务使用更少的CPU资源和更多的内存资源。而部分延迟敏感的在线任务,使用更多的CPU资源以及合理的内存资源。
- 用户级别的资源限制
-- cpu资源限制,数值越大可以使用的cpu越多,默认值-1代表不限制
set property for 'user1' 'cpu_resource_limit' = '1';
-- 内存使用限制, 单位为byte,下面是设置最大内存使用1G
set property for 'user1' 'exec_mem_limit' = '1073741824';
-- 查看内存资源限制
show property for 'user1' like "exec_mem_limit";
show session variables like "exec_mem_limit";
show global variables like "exec_mem_limit";
示例:
设置用户user1的内存使用为最小值1,然后使用user1执行查询,user1因为没有足够的内存导致查询阻塞,加大user1的内存限制后,再次查询快速完成;
#使用root设置user1的单次查询内存使用限制,最小是1byte
set property for 'user1' 'cpu_resource_limit' = '1';
#使用user1用户登录查询
select * from UserTable;

超级用户权限:
max_user_connections: 最大连接数。
max_query_instances: 用户同一时间点执行查询可以使用的instance个数。
sql_block_rules: 设置 sql block rules。设置后,该用户发送的查询如果匹配规则,则会被拒绝。
cpu_resource_limit: 限制查询的cpu资源。详见会话变量 cpu_resource_limit 的介绍。-1 表示未设置。
exec_mem_limit: 限制查询的内存使用。详见会话变量 exec_mem_limit 的介绍。-1 表示未设置。
resource.cpu_share: cpu资源分配。(已废弃)
load_cluster.{cluster_name}.priority: 为指定的cluster分配优先级,可以为 HIGH 或 NORMAL
resource_tags:指定用户的资源标签权限。
query_timeout:指定用户的查询超时权限。
注:`cpu_resource_limit`, `exec_mem_limit` 两个属性如果未设置,则默认使用会话变量中值。
普通用户权限:
quota.normal: normal级别的资源分配。
quota.high: high级别的资源分配。
quota.low: low级别的资源分配。
load_cluster.{cluster_name}.hadoop_palo_path: palo使用的hadoop目录,需要存放etl程序及etl生成的中间数据供Doris导入。导入完成后会自动清理中间
数据,etl程序自动保留下次使用。
load_cluster.{cluster_name}.hadoop_configs: hadoop的配置,其中fs.default.name、mapred.job.tracker、hadoop.job.ugi必须填写。
load_cluster.{cluster_name}.hadoop_http_port: hadoop hdfs name node http端口。其中 hdfs 默认为8070,afs 默认 8010。
default_load_cluster: 默认的导入cluster。
WORKLOAD GROUP(开发中)
workload group 可限制组内任务在单个be节点上的计算资源和内存资源的使用, 支持query绑定到workload group。
三、grant权限管理
Doris 的权限管理系统参照了 Mysql 的权限管理机制,做到了表级别细粒度的权限控制,基于角色的权限访问控制,并且支持白名单机制。
grant命令进行赋权,支持:
(1). 将指定的权限或资源授予某用户或角色。
GRANT privilege_list ON priv_level TO user_identity [ROLE role_name]
GRANT privilege_list ON RESOURCE resource_name TO user_identity [ROLE role_name]
(2). 在2.0及之后版本支持将指定角色授予某用户( 2.0之前的版本不支持)。
GRANT role_list TO user_identity
准备工作:
-- 在demo库下创建表
create table demo.table_abc
(k1 int, k2 int)
distributed by hash(k1) buckets 1
properties(
"replication_allocation"="tag.location.group_a:1, tag.location.group_b:1, tag.location.group_c:1"
);
insert into table_abc values(1,7);
create table demo.table_abc_copy like demo.table_abc;
insert into table_abc_copy values(1,77);
create database test;
1. 单表赋权
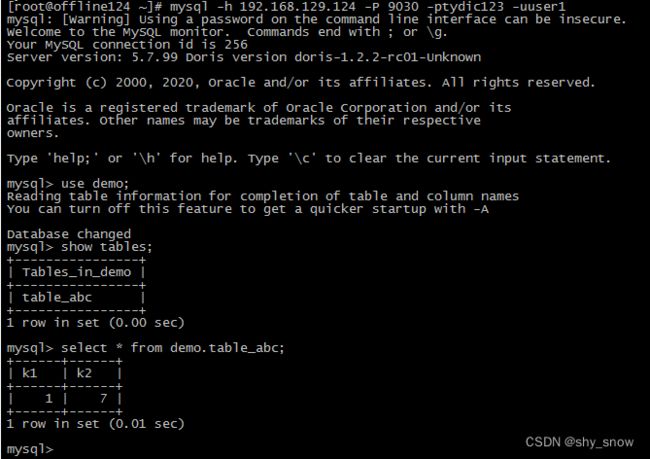
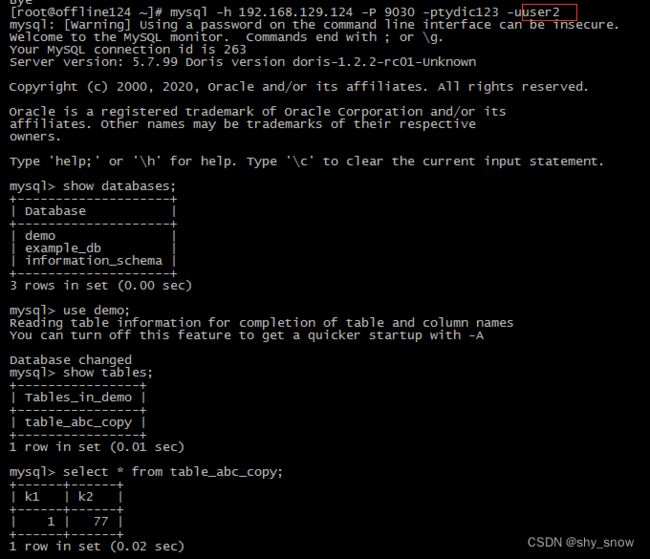
将两个表table_abc,table_abc_copy分别赋权给user1和user2
GRANT SELECT_PRIV ON demo.table_abc TO 'user1'@'%';
-- REVOKE SELECT_PRIV on demo.table_abc from 'user1'@'%';
GRANT SELECT_PRIV ON demo.table_abc_copy TO 'user2'@'%';
-- REVOKE SELECT_PRIV on demo.table_abc_copy from 'user2'@'%';
使用user1,user2登录只能查看到各自赋权的表
2. 对指定库的所有表进行授权
GRANT SELECT_PRIV ON demo.* TO 'user1'@'%';
show grants for user1;
-- revoke SELECT_PRIV on demo.* from 'user1'@'%';

3. 授予所有库表的权限
GRANT SELECT_PRIV,ALTER_PRIV,LOAD_PRIV ON *.* TO 'user1'@'%';
-- revoke SELECT_PRIV on *.* from 'user1'@'%';

4. 资源赋权
-- 授予指定资源的使用权限给用户
GRANT USAGE_PRIV ON RESOURCE 'spark_resource' TO 'user1'@'%';
-- 授予指定资源的使用权限给角色,since2.0
GRANT USAGE_PRIV ON RESOURCE 'spark_resource' TO ROLE 'my_role';
5. 导入赋权
使用用户级别的 resource tag 来限定计算资源所能使用的资源组。
-- 设置user3可以使用的3个group
set property for 'user3' 'resource_tags.location' = 'group_a, group_b, group_c';
使用(目标表)副本的 resource tag 来限定写入资源所能使用的资源组。
-- 设置表只可以使用其中2个group来写入保存副本
create table UserTable
(k1 int, k2 int)
distributed by hash(k1) buckets 1
properties(
"replication_allocation"="tag.location.group_a:1, tag.location.group_c:1"
);
四、grant语法及2.0之后的权限框架介绍
名词解释
-
用户标识 user_identity
在权限系统中,一个用户被识别为一个 User Identity(用户标识)。用户标识由两部分组成:username 和 userhost。其中 username 为用户名,由英文大小写组成。userhost 表示该用户链接来自的 IP。user_identity 以 username@’userhost’ 的方式呈现,表示来自 userhost 的 username。
user_identity 的另一种表现方式为 username@[‘domain’],其中 domain 为域名,可以通过 DNS 或 BNS(百度名字服务)解析为一组 ip。最终表现为一组 username@’userhost’,所以后面我们统一使用 username@’userhost’ 来表示。
-
权限 Privilege
权限作用的对象是节点、数据目录、数据库或表。不同的权限代表不同的操作许可。
-
角色 Role
Doris可以创建自定义命名的角色。角色可以被看做是一组权限的集合。新创建的用户可以被赋予某一角色,则自动被赋予该角色所拥有的权限。后续对角色的权限变更,也会体现在所有属于该角色的用户权限上。
-
用户属性 user_property
用户属性直接附属于某一用户,而不是用户标识。即 cmy@’192.%’ 和 cmy@[‘domain’] 都拥有同一组用户属性,该属性属于用户 cmy,而不是 cmy@’192.%’ 或 cmy@[‘domain’]。
用户属性包括但不限于: 用户最大连接数、导入集群配置等等。
支持的操作
- 创建用户:CREATE USER
- 删除用户:DROP USER
- 授权:GRANT
- 撤权:REVOKE
- 创建角色:CREATE ROLE
- 删除角色:DROP ROLE
- 查看当前用户权限:SHOW GRANTS
- 查看所有用户权限:SHOW ALL GRANTS
- 查看已创建的角色:SHOW ROLES
- 查看用户属性:SHOW PROPERTY
关于以上命令的详细帮助,可以通过 mysql 客户端连接 Doris 后,使用 help + command 获取帮助。如 HELP CREATE USER。
权限类型
Doris 目前支持以下几种权限
-
Node_priv
节点变更权限。包括 FE、BE、BROKER 节点的添加、删除、下线等操作。
Root 用户默认拥有该权限。同时拥有 Grant_priv 和 Node_priv 的用户,可以将该权限赋予其他用户。
该权限只能赋予 Global 级别。
-
Grant_priv
权限变更权限。允许执行包括授权、撤权、添加/删除/变更 用户/角色 等操作。
但拥有该权限的用户能不赋予其他用户 node_priv 权限,除非用户本身拥有 node_priv 权限。
-
Select_priv
对数据库、表的只读权限。
-
Load_priv
对数据库、表的写权限。包括 Load、Insert、Delete 等。
-
Alter_priv
对数据库、表的更改权限。包括重命名 库/表、添加/删除/变更 列、添加/删除 分区等操作。
-
Create_priv
创建数据库、表、视图的权限。
-
Drop_priv
删除数据库、表、视图的权限。
-
Usage_priv
资源的使用权限。
权限层级
同时,根据权限适用范围的不同,我们将库表的权限分为以下四个层级:
- GLOBAL LEVEL:全局权限。即通过 GRANT 语句授予的
*.*.*上的权限。被授予的权限适用于任意数据库中的任意表。 - CATALOG LEVEL:数据目录(Catalog)级权限。即通过 GRANT 语句授予的
ctl.*.*上的权限。被授予的权限适用于指定Catalog中的任意库表。 - DATABASE LEVEL:数据库级权限。即通过 GRANT 语句授予的
ctl.db.*上的权限。被授予的权限适用于指定数据库中的任意表。 - TABLE LEVEL:表级权限。即通过 GRANT 语句授予的
ctl.db.tbl上的权限。被授予的权限适用于指定数据库中的指定表。
将资源的权限分为以下两个层级:
- GLOBAL LEVEL:全局权限。即通过 GRANT 语句授予的
*上的权限。被授予的权限适用于资源。 - RESOURCE LEVEL: 资源级权限。即通过 GRANT 语句授予的
resource_name上的权限。被授予的权限适用于指定资源。
ADMIN/GRANT 权限说明
ADMIN_PRIV 和 GRANT_PRIV 权限同时拥有授予权限的权限,较为特殊。这里对和这两个权限相关的操作逐一说明。
- CREATE USER
- 拥有 ADMIN 权限,或 GLOBAL 和 DATABASE 层级的 GRANT 权限的用户可以创建新用户。
- DROP USER
- 拥有 ADMIN 权限或全局层级的 GRANT 权限的用户可以删除用户。
- CREATE/DROP ROLE
- 拥有 ADMIN 权限或全局层级的 GRANT 权限的用户可以创建角色。
- GRANT/REVOKE
- 拥有 ADMIN 权限,或者 GLOBAL 层级 GRANT 权限的用户,可以授予或撤销任意用户的权限。
- 拥有 CATALOG 层级 GRANT 权限的用户,可以授予或撤销任意用户对指定CATALOG的权限。
- 拥有 DATABASE 层级 GRANT 权限的用户,可以授予或撤销任意用户对指定数据库的权限。
- 拥有 TABLE 层级 GRANT 权限的用户,可以授予或撤销任意用户对指定数据库中指定表的权限。
- SET PASSWORD
- 拥有 ADMIN 权限,或者 GLOBAL 层级 GRANT 权限的用户,可以设置任意用户的密码。
- 普通用户可以设置自己对应的 UserIdentity 的密码。自己对应的 UserIdentity 可以通过
SELECT CURRENT_USER();命令查看。 - 拥有非 GLOBAL 层级 GRANT 权限的用户,不可以设置已存在用户的密码,仅能在创建用户时指定密码。
一些说明
-
Doris 初始化时,会自动创建如下用户和角色(查看角色可以使用 SHOW ROLES; ):
- operator 角色:该角色拥有 Node_priv 和 Admin_priv,即对Doris的所有权限。
- admin 角色:该角色拥有 Admin_priv,即除节点变更以外的所有权限。
- root@’%’:root 用户,允许从任意节点登陆,角色为 operator。
- admin@’%’:admin 用户,允许从任意节点登陆,角色为 admin。
-
不支持删除或更改默认创建的角色或用户的权限。
-
operator 角色的用户有且只有一个,即 Root。admin 角色的用户可以创建多个。
-
一些可能产生冲突的操作说明
-
域名与ip冲突:
假设创建了如下用户:
CREATE USER cmy@[‘domain’];
并且授权:
GRANT SELECT_PRIV ON . TO cmy@[‘domain’]
该 domain 被解析为两个 ip:ip1 和 ip2
假设之后,我们对 cmy@’ip1’ 进行一次单独授权:
GRANT ALTER_PRIV ON . TO cmy@’ip1’;
则 cmy@’ip1’ 的权限会被修改为 SELECT_PRIV, ALTER_PRIV。并且当我们再次变更 cmy@[‘domain’] 的权限时,cmy@’ip1’ 也不会跟随改变。
-
重复ip冲突:
假设创建了如下用户:
CREATE USER cmy@’%’ IDENTIFIED BY “12345”;
CREATE USER cmy@’192.%’ IDENTIFIED BY “abcde”;
在优先级上,’192.%’ 优先于 ‘%’,因此,当用户 cmy 从 192.168.1.1 这台机器尝试使用密码 ‘12345’ 登陆 Doris 会被拒绝。
-
-
忘记密码
如果忘记了密码无法登陆 Doris,可以在 Doris FE 节点所在机器,使用如下命令无密码登陆 Doris:
mysql-client -h 127.0.0.1 -P query_port -uroot登陆后,可以通过 SET PASSWORD 命令重置密码。
-
任何用户都不能重置 root 用户的密码,除了 root 用户自己。
-
ADMIN_PRIV 权限只能在 GLOBAL 层级授予或撤销。
-
拥有 GLOBAL 层级 GRANT_PRIV 其实等同于拥有 ADMIN_PRIV,因为该层级的 GRANT_PRIV 有授予任意权限的权限,请谨慎使用。
-
current_user()和user()用户可以通过
SELECT current_user();和SELECT user();分别查看current_user和user。其中current_user表示当前用户是以哪种身份通过认证系统的,而user则是用户当前实际的user_identity。举例说明:假设创建了
user1@'192.%'这个用户,然后以为来自 192.168.10.1 的用户 user1 登陆了系统,则此时的current_user为user1@'192.%',而user为user1@'192.168.10.1'。所有的权限都是赋予某一个
current_user的,真实用户拥有对应的current_user的所有权限。 -
密码强度
在 1.2 版本中,新增了对用户密码强度的校验功能。该功能由全局变量
validate_password_policy控制。默认为NONE/0,即不检查密码强度。如果设置为STRONG/2,则密码必须包含“大写字母”,“小写字母”,“数字”和“特殊字符”中的3项,并且长度必须大于等于8。
权限框架(2.0及之后版本支持)
Doris权限设计基于RBAC(Role-Based Access Control)的权限管理模型,用户和角色关联,角色和权限关联,用户通过角色间接和权限关联。
当角色被删除时,用户自动失去该角色的所有权限。
当用户和角色取消关联,用户自动失去角色的所有权限。
当角色的权限被增加或删除,用户的权限也会随之变更。
┌────────┐ ┌────────┐ ┌────────┐
│ user1 ├────┬───► role1 ├────┬────► priv1 │
└────────┘ │ └────────┘ │ └────────┘
│ │
│ │
│ ┌────────┐ │
│ │ role2 ├────┤
┌────────┐ │ └────────┘ │ ┌────────┐
│ user2 ├────┘ │ ┌─► priv2 │
└────────┘ │ │ └────────┘
┌────────┐ │ │
┌──────► role3 ├────┘ │
│ └────────┘ │
│ │
│ │
┌────────┐ │ ┌────────┐ │ ┌────────┐
│ userN ├─┴──────► roleN ├───────┴─► privN │
└────────┘ └────────┘ └────────┘
如上图所示:
user1和user2都是通过role1拥有了priv1的权限。
userN通过role3拥有了priv1的权限,通过roleN拥有了priv2和privN的权限,因此userN同时拥有priv1,priv2和privN的权限。
为了方便用户操作,是可以直接给用户授权的,底层实现上,是为每个用户创建了一个专属于该用户的默认角色,当给用户授权时,实际上是在给该用户的默认角色授权。
默认角色不能被删除,不能被分配给其他人,删除用户时,默认角色也自动删除。
最佳实践
这里举例一些 Doris 权限系统的使用场景。
-
场景一
Doris 集群的使用者分为管理员(Admin)、开发工程师(RD)和用户(Client)。其中管理员拥有整个集群的所有权限,主要负责集群的搭建、节点管理等。开发工程师负责业务建模,包括建库建表、数据的导入和修改等。用户访问不同的数据库和表来获取数据。
在这种场景下,可以为管理员赋予 ADMIN 权限或 GRANT 权限。对 RD 赋予对任意或指定数据库表的 CREATE、DROP、ALTER、LOAD、SELECT 权限。对 Client 赋予对任意或指定数据库表 SELECT 权限。同时,也可以通过创建不同的角色,来简化对多个用户的授权操作。
-
场景二
一个集群内有多个业务,每个业务可能使用一个或多个数据。每个业务需要管理自己的用户。在这种场景下。管理员用户可以为每个数据库创建一个拥有 DATABASE 层级 GRANT 权限的用户。该用户仅可以对用户进行指定的数据库的授权。
CREATE USER 'jack' IDENTIFIED BY 'tydic123'; create database test; create role grantdba ; show roles; GRANT GRANT_PRIV ON default_cluster.test TO ROLE 'grantdba'; -- 2.0及以上版本支持 GRANT 'grantdba' to 'jack'; show grants for 'jack'; -- jack可以赋权表给client用户 grant SELECT_PRIV on default_cluster.test TO 'client1'; -
黑名单
Doris 本身不支持黑名单,只有白名单功能,但我们可以通过某些方式来模拟黑名单。假设先创建了名为
user@'192.%'的用户,表示允许来自192.*的用户登录。此时如果想禁止来自192.168.10.1的用户登录。则可以再创建一个用户cmy@'192.168.10.1'的用户,并设置一个新的密码。因为192.168.10.1的优先级高于192.%,所以来自192.168.10.1将不能再使用旧密码进行登录。