负载均衡算法介绍及应用连接池负载不均问题分析
在分布式系统架构下,为了满足高并发和高扩展性的要求,负载均衡设备得以广泛的使用。结合应用连接池的配置,在实际使用过程中可能会出现负载不均的问题。本文简单介绍了负载均衡算法、Druid连接池配置以及连接池负载不均的问题分析及优化方法。
1、负载均衡基本概念
1.1 负载均衡介绍
在分布式架构下随着逻辑业务的快速发展,系统架构也随之变得庞大复杂,这中间对系统模块的高并发、高可用、高扩展性也提出了新的要求,比如服务路由、负载均衡等。
负载均衡是指将负载(如计算任务、数据流量等)分摊到多个操作单元(如服务器、网络设备等)上进行执行,以共同完成工作任务的一种技术。它建立在现有网络结构之上,提供了一种廉价、有效和透明的方法,可以扩展网络设备和服务器的带宽、增加吞吐量、加强网络数据处理能力,并提高网络的灵活性和可用性。
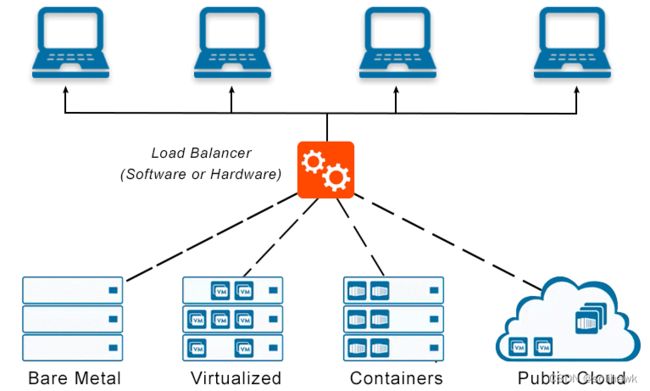
负载均衡在实现上有硬件和软件两种方式:硬件负载均衡器功能强大、稳定性高,适合吞吐量大、高并发的流量负载,但是成本相对较高,并且扩展性差;软件负载部署上更加灵活,扩展性高,但是性能和稳定性相对较差。
1)硬件负载均衡设备
- F5负载均衡器(LTM):F5 BIG-IP负载均衡设备,支持4-7层负载均衡,具备负载均衡、应用交换、状态监控等功能
- CDN负载均衡设备:专门用于CDN的负载均衡设备,通常采用多层架构设计,包括全局负载均衡设备、局部负载均衡设备和缓存服务器等
2)软件负载均衡
- LVS:LVS软件工作在网络四层,通过vrrp协议转发,有着高可用性、高性能、扩展性的优点,是Linux内核的一款负载均衡软件。
- Nginx:Nginx软件工作在网络七层,它属于反向代理服务器,并且能够支持虚拟主机,是开源的负载均衡软件。
- HAProxy:HAProxy支持TCP和HTTP两种代理模式,它是一个反向代理服务器,支持虚拟主机,也可以用作HTTPS代理、基于内容的负载均衡等。
1.2 负载均衡常用的算法
负载均衡是将业务流量负载到不同的服务器,而负载均衡算法就是实现在不同服务器之间分配网络流量的逻辑。负载均衡算法的选择会影响负载的分配机制,从而影响到性能和业务连续性,下面将介绍几种常用的负载均衡算法。
1)Round Robin(轮询算法)
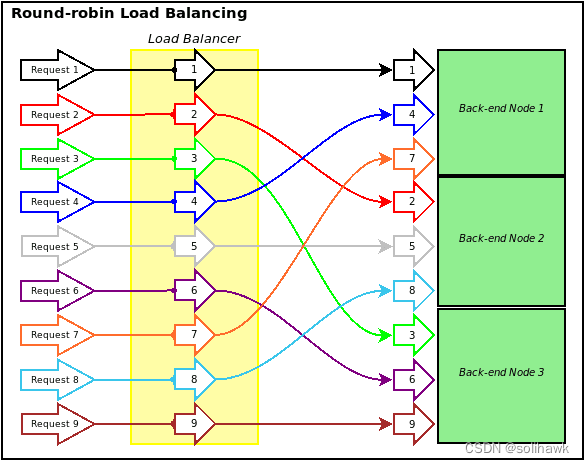
轮询算法很简单,将前端请求按照顺序轮流分配到后台服务器上,不用关心后台服务器的负载和实际连接情况。轮询算法适用于后端服务器性能大致相当的情况,如果某台机器性能异常承载不了这么多的流量,会造成业务访问异常。当然在实际的运维工作中,会采用标准化的配置相同的服务器,以减少维护成本。如下图所示流量请求安装顺序分发到后台三个节点中,保证了流量均衡。
2)Weighted Round Robin(加权轮询算法)
加权轮询算法是对轮询算法的优化,因为后台服务器在配置和性能上有差异,在负载配置上将配置高、负载低的机器分配更高的权重,使其能处理更多的请求,而配置低、负载高的机器,则给其分配较低的权重,降低其系统负载。加权轮询算法适用于后端具备不同负载容量的服务器,但是配置上更为复杂,也不利于标准化的配置。
3)Fastest Response Time(最快响应算法)
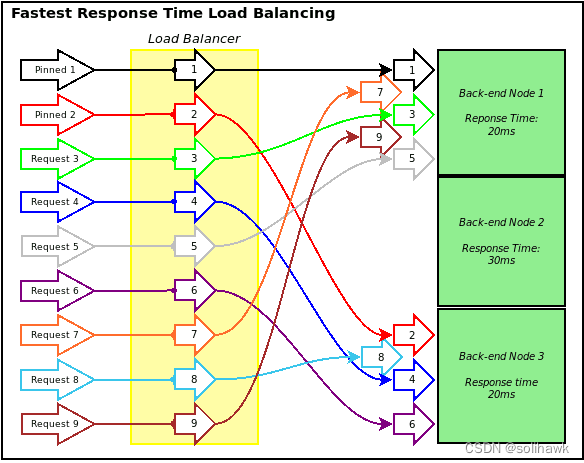
最快响应算法根据负载均衡器到每一个后端服务器节点的网络响应时间(RTT时延),并将下一个到达的连接请求动态分配给响应时间最短的节点。该算法能够实现应用请求的快速响应,提高业务请求的响应时间,但是会出现请求集中在几个响应最快的节点上。如下图所示,节点1和节点3的响应时间为20ms、节点2为30ms,根据最快响应算法,连接请求负载分发到节点1和节点3中。
4)Least Connections(最小连接算法)
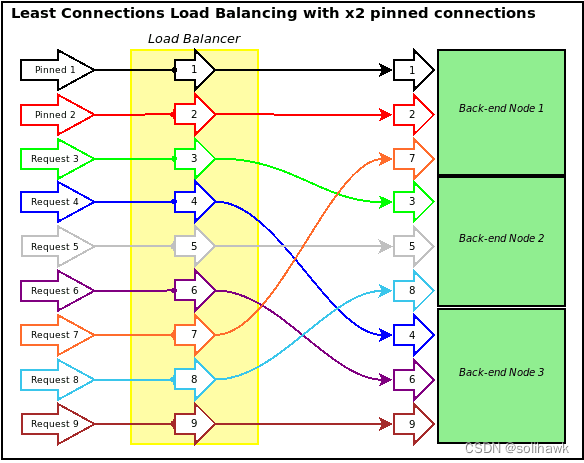
像前面的轮询算法按照前端的请求次数均衡分配,实现后端服务器的负载均衡,但是实际上连接请求并不能真实反应服务器的负载情况。因此引入了最小连接算法,根据后端服务器当前的连接情况,动态的选取其中当前积压连接数最少的一台服务器来处理当前请求,尽可能的提高后台服务器利用率。最小连接算法在本质上是从后端服务器的角度来观察系统的负载,能够最大限度的利用后端服务器的资源,不足之处是负载均衡需要更多的资源来判断后端服务的连接情况。如下图所示最小连接算法的实现:
除了上面4种,负载均衡算法还有随机法、加权随机法、源地址哈希法等不多介绍,实际应用中轮询算法和最小连接算法应用的较多。
2、Druid连接池介绍
2.1 Druid连接概览
Druid是开源的数据库连接池,它结合了C3P0、DBCP、Proxool等DB池的优点,同时加入了日志监控,可以很好的监控DB池连接和SQL的执行情况。
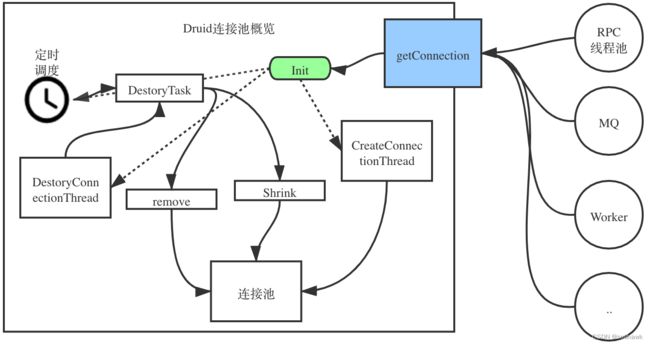
- 在druidDataSource中有一个重入锁和衍生的两个condition:一个监控连接池是否为空,一个监控连接池不为空。
- 在druidDataSource中有两个线程,一个生成连接CreateConnectionThread,一个回收连接DestoryConnectionThread。在创建、获取、回收的时候都会使用这些锁和condition。
- 每次获取Connection都会调用init,内部使用inited标识DataSource是否已经初始化OK。
- 每次获取 Connection 都会需要进行加锁保证线程安全,所有操作都在加锁后执行。
- 如果连接池内没有连接了,则调用empty.signal(),通知CreateThread创建连接,并且等待指定的时间,被唤醒之后再去查看是否有可用连接。
2.2 Druid参数配置说明
1)基本属性
- name:配置这个属性的意义在于,如果存在多个数据源,监控的时候可以通过名字来区分开来。如果没有配置,将会生成一个名字,格式是:“DataSource-” + System.identityHashCode(this).
- url:连接数据库的url,不同数据库不一样。例如:mysql : jdbc:mysql://10.20.153.104:3306/druid2、oracle : jdbc:oracle:thin:@10.20.149.85:1521:ocnauto
- username:连接数据库的用户名
- password:连接数据库的密码
- driverClassName:这一项可配可不配,如果不配置druid会根据url自动识别dbType,然后选择相应的driverClassName
2)连接池大小
- initialSize:初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时。缺省值为0
- maxActive:最大连接池数量。缺省值为8
- minIdle:最小连接池数量。缺省值为0
- maxWait:获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。缺省值为-1
3)连接检测
- testOnBorrow:申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。缺省值为true
- testOnReturn:归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。缺省值为false
- testWhileIdle:建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。缺省值为false
- timeBetweenEvictionRunsMillis:有两个含义:1) Destroy线程会检测连接的间隔时间,如果连接空闲时间大于等于minEvictableIdleTimeMillis则关闭物理连接。2) testWhileIdle的判断依据。缺省值为60s
- maxEvictableIdleTimeMillis:连接空闲时间大于该值,不管minidle是多少都关闭这个连接。缺省值为7小时
- minEvictableIdleTimeMillis:连接空闲时间大于该值并且池中空闲连接数大于minidle则关闭这个连接。缺省值为30分钟
- maxPoolPreparedStatementPerConnectionSize:要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100。缺省值为-1
- PhyTimeoutMillis:物理连接打开的时间超过这个超时时间,并且不再使用时会关闭这个物理连接,一般不建议打开
- validationQuery:用来检测连接是否有效的sql,要求是一个查询语句,常用select ‘x’。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会起作用。缺省值为null
- validationQueryTimeout:单位:秒,检测连接是否有效的超时时间。底层调用jdbc Statement对象的void setQueryTimeout(int seconds)方法。缺省值为-1
- keepAlive:连接池中的minIdle数量以内的连接,并且连接的空闲时间大于keepAliveBetweenTimeMillis但小于minEvictableIdleTimeMillis,则会执行validationQuery来保持连接的有效性。缺省值为false
- keepAliveBetweenTimeMillis:打开KeepAlive时,当连接的空闲时间超过该值,会使用validationQuery执行一次查询,检查连接是否可用。缺省值为120s
4)缓存语句
- poolPreparedStatements:是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。缺省值为false
- sharePrepareStatements
- maxPoolPreparedStatementPerConnectionSize:要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100。缺省值为-1
2.3 连接保活和回收机制
2.3.1 连接保活
为了防止一个数据库连接太久没有使用,而被其它下层的服务关闭,druid中定义了KeepAlive选项,机制上与TCP中的类似。保活机制能够保证连接池中的连接是真实有效的连接,假如遇到特殊情况导致连接不可用时,keepAlive机制将无效连接进行驱逐。保活机制是由守护线程DestroyConnectionThread发起的,启动后守护线程会进入无线循环,根据心跳间隔时间timeBetweenEvictionRunsMillis循环调用DestoryTask线程,默认时间为60s。
1)开启KeepAlive
// 一个连接在连接池中最小生存的时间
dataSurce.setMinEvictableIdleTimeMillis(60 * 1000);单位毫秒
// 开启keepAlive
dataSource.setKeepAlive(true);
有两个参数KeepAlive和MinEvictableIdleTimeMillis
2)DruidDataSource中的两个成员变量
// 存放检查需要抛弃的连接
private DruidConnectionHolder[] evictConnections;
// 用来存放需要连接检查的存活连接
private DruidConnectionHolder[] keepAliveConnections;
如果KeepAlive打开,当一个连接的空闲时间超过keepAliveBetweenTimeMillis时,则会将此连接放入此连接放入keepAliveConnections数组,然后使用validationQuery执行一次查询。
if (keepAlive && idleMillis >= keepAliveBetweenTimeMillis) {
keepAliveConnections[keepAliveCount++] = connection;
}
…
if (keepAliveCount > 0) {
// keep order
for (int i = keepAliveCount - 1; i >= 0; --i) {
DruidConnectionHolder holer = keepAliveConnections[i];
Connection connection = holer.getConnection();
holer.incrementKeepAliveCheckCount();
boolean validate = false;
try {
this.validateConnection(connection);
validate = true;
} catch (Throwable error) {
if (LOG.isDebugEnabled()) {
LOG.debug("keepAliveErr", error);
}
// skip
}
如果本次validationQuery执行失败,则关闭该链接,并丢弃。
2.3.2 数据源收缩
在Druid数据源初始化的时候,会创建一个定时运行的DestroyTask,该任务的主要目的是将已空闲时间满足关闭条件的连接关闭。
1)当前连接存活时长 > 配置的物理连接时间时长,则放入evictConnections
if (phyConnectTimeMillis > phyTimeoutMillis) {
evictConnections[evictCount++] = connection;
continue;
}
2)空闲时间 > 最小驱逐时间
if (idleMillis >= minEvictableIdleTimeMillis) {
if (checkTime && i < checkCount) {
evictConnections[evictCount++] = connection;
continue;
} else if (idleMillis > maxEvictableIdleTimeMillis) {
evictConnections[evictCount++] = connection;
continue;
}
}
…
if (evictCount > 0) {
for (int i = 0; i < evictCount; ++i) {
DruidConnectionHolder item = evictConnections[i];
Connection connection = item.getConnection();
JdbcUtils.close(connection);
destroyCountUpdater.incrementAndGet(this);
}
Arrays.fill(evictConnections, null);
}
从代码逻辑中可以看到,对于要关闭的空闲连接选择逻辑如下:
- 对于空闲时间> minEvictableIdleTimeMillis的连接,仅会关闭poolingCount-minIdle个,后面的连接不受影响;
- 处于> maxEvictableIdleTimeMillis的空闲连接则会直接关闭;
- timeBetweenEvictionRunsMillis即为该定时任务运行的间隔;
- minEvictableIdleTimeMillis为可关闭连接的最小空闲时间
2.4 Druid连接生命周期
Druid连接的生命周期从两个维度去看:一个是应用使用方,包括连接的申请、使用和关闭;一个是Druid自己管理的连接池,包括连接的创建和回收、保活机制等。具体如下所示:
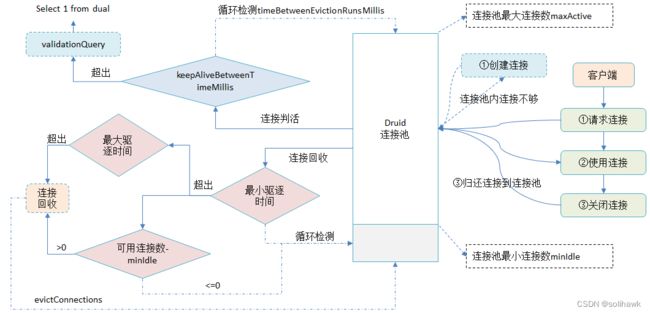
1)客户端连接管理
- 客户端发起连接请求从Druid连接池申请连接,如果连接池内连接不够会调用CreateThread创建连接;
- 客户端拿到连接后,访问数据库进行操作;
- 连接操作完成后,释放数据库资源并close连接,这一步通常是由应用主动去做的,连接关闭后会回收,归还给Druid连接池。
2)Druid连接池管理
- Druid连接池设置最小连接数minIdle和最大连接数maxActive,最小连接数支持预热功能,应用每次申请连接的时候不需要重新初始化,高并发下可以提升性能;
- 连接池会定时进行连接保活,KeepAlive的周期由timeBetweenEvictionRunsMillis控制(默认值60s),当发现连接的空闲时长超过keepAliveBetweenTimeMillis(默认值120s)时,会主动发起链路保活,一般是向数据库发起SQL查询,这个SQL语句可以自定义,通常为“select 1 from dual”
- 为了防止连接泄露,会定时回收空闲的连接,对于连接空闲时间大于minEvictableIdleTimeMillis(默认为30分钟)并且连接池中空闲连接数大于minIdle则关闭这个连接;如果连接空闲时间大于maxEvictableIdleTimeMillis(默认值为7小时)则直接关闭连接
- 从上可以看出,如果没有连接保活,当设置minIdle后会有一部分在最小连接内的连接因为空闲连接超时被关闭;当然如果设置了KeepAlive并且当保活的检测频率和keepAliveBetweenTimeMillis小于minEvictableIdleTimeMillis时,就不会出现空闲连接被关闭的情况。
3、Druid连接池下数据库负载不均问题
3.1 负载均衡后端成员启动先后问题
在日常应用系统架构中,应用->负载均衡->数据库链路如下图所示,应用侧配置连接池以提升性能、负载均衡如F5设备实现后端成员的管理,如后端成员UP/DOWN状态监测、流量负载分发等。负载均衡通过定时检测机制如TCP监听或者SQL语句探测,以监测后端成员的状态,记录到负载均衡设备中进行管理。

在上图中部署了3个应用服务器,每个上面配置最小空闲连接minIdle=20,总的初始化连接数有60个。当后端成员维护或者升级等原因集体处于DOWN状态然后再变成UP,但是对于负载均衡检测到后端成员的UP状态是有先后顺序的,比如DB1最先处于UP状态,后面其它DB陆续起来,这样大量的连接最先到DB1节点,后面的DB节点也陆续有流量。整个过程可能很快,1~2s的时间,但是反应在后端成员的流量负载上已经不均匀了(DB1=30、DB2=16、DB3=8、DB4=6)。如果此时DB1节点的资源和性能不足以支撑50%的业务流量,业务运行会变慢或者数据库请求失败,造成业务连续性影响。
上述问题的一个优化方法是,如果是计划内的操作,在实施流程上进行优化,在后端成员都就绪以后再将业务负载接入,这样会将流量请求相对均衡的负载到各个后端实例上。
3.2 负载均衡后端成员故障后接入
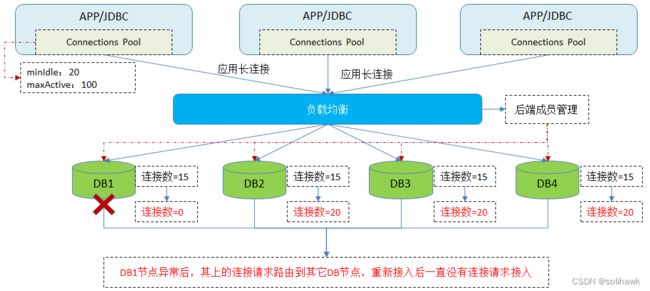
另一个场景是负载均衡后端成员故障后再重新接入的问题,如上图所示,3个应用初始化连接为60,在负载均衡4个后端DB实例中平均为15。当后端成员DB1故障后,其中的连接请求会均发到其它3个成员上,每个DB实例连接平均为20。但是当DB1实例重新接入负载均衡设备后,长时间没有连接请求接入,因为如果有新的连接请求过来,根据负载均衡算法新接入的后端成员肯定会有负载流量的。为什么会出现这样的问题,也是下面将介绍的连接池最小连接过大的问题。
3.3 Druid连接池最小连接过大
在前文Druid连接池生命周期管理中介绍到,Druid连接池设置最小连接数minIdle支持预热功能,应用每次申请连接的时候不需要重新初始化,高并发下可以提升性能。但是对于有些应用来说,初始化连接会设置过大,可能比业务峰值的连接还大。比如A应用有20台应用服务器,每一台最小连接配置为20,这样总的最小连接支持400,但应用在业务峰值时候的Active连接不到350个,对应用来说性能是最佳的,因为不需要新建连接。
但是这样就会出现负载均衡后端成员故障后再加入时候长时间没有连接的问题,因为连接池中连接的销毁释放和新建是有个生命周期的。如何优化这个问题,让连接尽可能快速的销毁新建,并分发流量到新接入的成员中。一种是应用侧轮流启动以释放连接重新分发负载流量,这种机制对业务无感,但是不友好,每次涉及到后端成员的变更维护都要应用侧重启是不现实的。另一种是减少应用连接池的minIdle配置,降低最小连接数,让前端及时的创建新的连接并负载到后端服务中,但这种对性能肯定有影响。最终还是要从连接池的回收机制上出发,有两个参数minEvictableIdleTimeMillis(默认为30分钟)和maxEvictableIdleTimeMillis(默认值为7小时),maxEvictableIdleTimeMillis表示如果连接空闲时间大于设定的值则会关闭连接。

如上图所示应用连接池中最小连接和Active连接随着每天业务变化情况,可以看到在凌晨业务低峰期Active连接并不高,当maxEvictableIdleTimeMillis参数设置较小比如1小时,能够将连接池中的idle连接关闭销毁并建立新的连接。这部分新建的连接又可以分发到负载均衡后端成员中,让新加入的节点能够接入流量。但这种连接的销毁建立对应用来说是有性能开销的,具体设置多少合适,需要根据实际的性能压测结果进行评估。
参考资料:
- https://www.liquidweb.com/kb/load-balancing-techniques-optimizations/
- https://github.com/alibaba/druid/wiki/
- Druid连接池断链分析