linux c 多线程 互斥锁、自旋锁、原子操作的分析与使用
情景分析
生活中,我们常常会在12306或者其他购票软件上买票,特别是春节期间或者国庆长假的时候,总会出现抢票的现象,最后总会有人买不到票而埋怨这埋怨那,其实这还好,至少不会跑去现场或者网上去找客服理论,如果出现了付款,但是却没买到票的现象,那才是真的会出现很多问题,将这里的票引入到多线程中,票就被称为临界资源。
问题引入
多线程的引入无疑是高性能服务器的必要技术之一,但是如果不控制好临界资源的使用,就会出现一些列的问题,比如会出现多个线程同时去访问同一个临界资源。就拿上面买票来说,某一张票,如果同时有多个人在多个软件上抢购,如果不对其进行控制,就会出现一张票可能被多个人购买的情况,这肯定是不合理的。
我们首先模拟一下卖票的情形,代码中模拟10个窗口卖票,也就是使用10个线程,另外票的总数为100w张,如果按照每个窗口平均下来就应该卖出10w张,最开始为1张票都没卖,然后每个线程卖出一张票,就让票的数量+1,直到数量为总共的100w张。
#include 在linux下编译:gcc -o thread_mutex thread_mutex.c -g -lpthread 后然后运行得到结果如下:
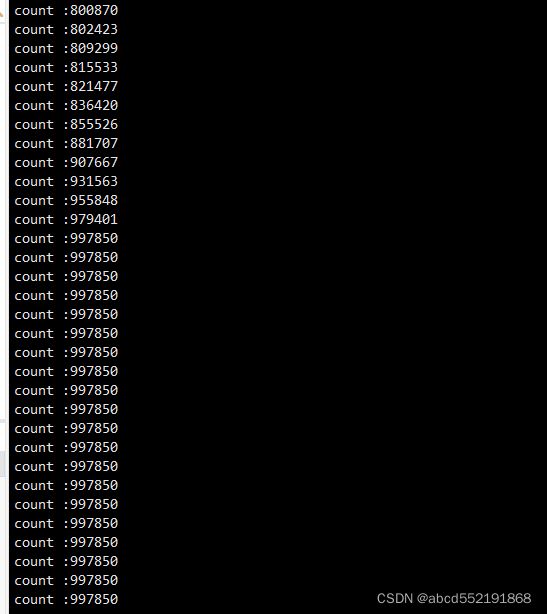
count没有增加到100w,而是到997850后数字就没有增加了。
原因分析
如果按照正常逻辑,10个线程同时对1个数进行增加,每个线程累加10w次,那么应该累加到100w次,而且线程里面的逻辑就是count++的操作,没有其他操作,即使不同线程对count的争夺,按照正常想法也是一个线程会增加了count后,然后另一个线程会在上一个线程对count增加后才会去获取count,其实不然,count++实际上不是原子操作,count++实际上在底层有3个操作。下面用图片来分析说明。
其实count++在硬件上的操作主要分为3步
mov [count], eax; //将count的值赋值给寄存器eax
inc eax; //寄存器eax自增
mov eax, [count]; //将eax的值赋值给count
上面的3句代码是count++的实际操作过程,只要有一点点汇编基础,很容易就看懂那几句的意思,多线程正常的情况下,会按照下面的情况执行
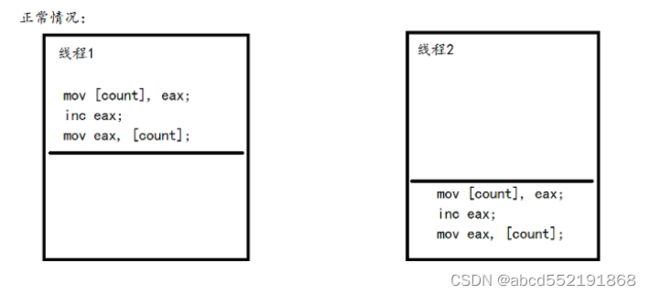
这时候线程1和线程2对count的++操作是没问题的,但是如果像下面这种情况就不对了。
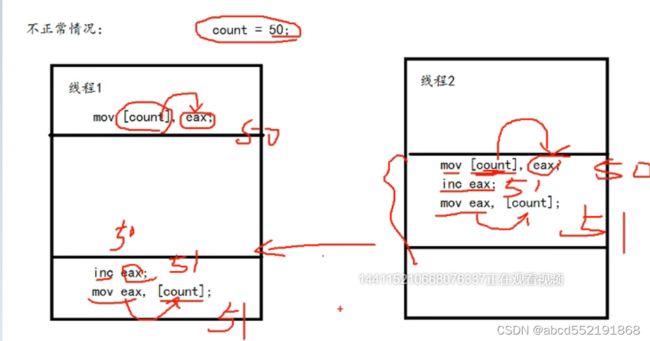
假如开始count为50,线程1去执行++操作,执行完第一步就被线程2抢夺,那么线程2执行时,count的值还是50,执行++,为51,注意,然后线程1去执行时,++时还是对自身eax获取的值50执行执行++操作,也是51,这时候2个线程都执行了++操作,但是却只增加了一次,这就是问题出现的原因。
解决办法
对临界资源的控制,在window下由临界区,锁,等,在linux下同样有锁的概念,另外,linux下还有原子操作的概念。
关于互斥锁,自旋锁网上都有很多说明,这里都不详细说了,只简单提及以下
互斥锁
从名称来看互斥锁的功能就是锁某一段时间只能有一个线程进行访问,线程释放锁之后,其他线程才可以对锁进行操作。那么我们在count++执行前加一个互斥锁,那么是不是就相当于执行到count++时,由于锁目前被一个线程使用,其他线程是不能执行count++操作的,这样就可以了
自旋锁
自旋锁的实现跟互斥锁的实现一模一样,同样也是在count++前对自旋锁加锁,执行完++操作后,在释放锁,让其他线程去获取锁,加锁,然后执行,释放锁。
虽然2种锁实现方法大同小异,但是自旋锁与互斥锁是有很大区别的,主要区别如下:
**自旋锁:**当某个线程执行到某段加锁的代码时,如果发现当前锁被其他线程占用,那么当前线程就会一直死等,等到其他线程释放锁,然后继续执行其代码
互斥锁:互斥锁恰好与自旋锁相反,当一个线程执行加锁的代码时,发现锁当前被其他线程加锁了,那么当前线程会进行休眠状态,释放相关资源,然后一段时间后再次去尝试获取资源,执行相关代码。
那么就这个例子来说,自旋锁要比互斥锁更好,因为++操作很快,互斥锁频繁的线程切换会导致消耗更多的资源。
原子操作
原子操作的实现不需要对代码进行加锁和解锁,原子操作把多条指令直接变成单条指令,然后依靠CPU去执行,就这个例子来说,原子操作比2个锁方案都好。
代码实现
#include 源码来源
腾讯课堂-零声学院king老师