【Java应用】使用Java实现机器学习算法:聚类、分类、预测
一、引言
1、机器学习算法概述
机器学习是一种人工智能技术,旨在通过使用数据和统计分析来让计算机系统自动改进性能。机器学习算法可分为三大类:聚类、分类和预测。聚类算法用于将数据集分成不同的群组;分类算法用于将数据分为不同的类别;预测算法用于预测未来事件或趋势。
机器学习算法广泛应用于各种领域,例如金融、医疗、教育、自然语言处理、计算机视觉等。随着数据量的不断增加和数据分析需求的不断提高,机器学习技术在各行各业都得到了广泛的应用。
2、Java语言在机器学习领域的优势
Java是一种广泛应用的编程语言,在机器学习领域也有其独特的优势。
- 广泛的使用:Java是一种广泛应用的编程语言,在各行各业都有广泛的应用。使用Java实现机器学习算法可以让更多的人参与到机器学习技术的研究和应用中来。
- 丰富的类库:Java语言有着丰富的类库,这些类库提供了许多机器学习所需的功能,如矩阵运算、数据处理、图形绘制等。这些类库可以大大简化机器学习算法的实现过程。
- 跨平台性:Java是一种跨平台的编程语言,可以在不同的操作系统和硬件平台上运行。这使得使用Java实现机器学习算法更具灵活性和可移植性。
- 安全性:Java语言有着高度的安全性,可以避免常见的安全漏洞和错误。这对于机器学习算法的实现和应用来说是非常重要的。
- 大型项目支持:Java语言适合开发大型项目,可以方便地管理大量的代码和数据。这对于大规模机器学习项目来说非常有用。
Java语言在机器学习领域有着独特的优势,可以帮助开发人员更加轻松地实现各种机器学习算法,并应用于不同的领域和行业中。
二、聚类算法
1、聚类算法概述
聚类算法是一种无监督学习算法,用于将数据集分成不同的群组。聚类算法通常基于相似性度量来决定数据点之间的距离,从而将数据点分成不同的群组。聚类算法在许多领域中都有广泛的应用,如市场营销、社交网络、天文学等。
2、K-Means算法
原理
K-Means算法是聚类算法中最常用的一种算法。K-Means算法的基本思想是将数据点分成K个群组,每个群组称为一个簇。K-Means算法通过最小化每个数据点到其所属簇中心的距离来确定簇中心,从而将数据点分成不同的簇。
K-Means算法的实现过程如下:
- 随机选择K个数据点作为初始簇中心。
- 将每个数据点分配给距离最近的簇中心。
- 根据簇中所有数据点的均值重新计算每个簇的中心。
- 重复第2和第3步,直到簇中心不再发生变化或达到最大迭代次数。
Java实现
下面是一个K-Means算法的Java实现示例,包括点(Point)、簇(Cluster)、以及主程序(KMeansDemo):
Point.java:
public class Point {
private double x;
private double y;
public Point(double x, double y) {
this.x = x;
this.y = y;
}
public double getX() {
return x;
}
public double getY() {
return y;
}
public double distanceTo(Point other) {
double dx = x - other.getX();
double dy = y - other.getY();
return Math.sqrt(dx * dx + dy * dy);
}
@Override
public String toString() {
return "(" + x + ", " + y + ")";
}
}Cluster.java:
import java.util.ArrayList;
import java.util.List;
public class Cluster {
private Point center;
private List points;
public Cluster(Point center) {
this.center = center;
this.points = new ArrayList<>();
}
public Point getCenter() {
return center;
}
public List getPoints() {
return points;
}
public void addPoint(Point point) {
points.add(point);
}
public void clearPoints() {
points.clear();
}
public void recalculateCenter() {
double sumX = 0;
double sumY = 0;
for (Point point : points) {
sumX += point.getX();
sumY += point.getY();
}
double centerX = sumX / points.size();
double centerY = sumY / points.size();
center = new Point(centerX, centerY);
}
@Override
public String toString() {
return "Cluster[center=" + center + ", points=" + points + "]";
}
} KMeansDemo.java:
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
public class KMeansDemo {
public static void main(String[] args) {
// 生成随机点
List points = generatePoints(100, 10, 10, 90, 90);
// 初始化K-Means算法
int k = 3;
KMeans kMeans = new KMeans(points, k);
// 运行K-Means算法
int maxIterations = 10;
kMeans.run(maxIterations);
// 打印结果
List clusters = kMeans.getClusters();
System.out.println("Points:");
for (Point point : points) {
System.out.println(point);
}
System.out.println("Clusters:");
for (Cluster cluster : clusters) {
System.out.println(cluster);
}
}
// 生成随机点
private static List generatePoints(int numPoints, double minX, double minY, double maxX, double maxY) {
List points = new ArrayList<>();
Random random = new Random();
for (int i = 0; i < numPoints; i++) {
double x = minX + (maxX - minX) * random.nextDouble();
double y = minY + (maxY - minY) * random.nextDouble();
Point point = new Point(x, y);
points.add(point);
}
return points;
}
} 在运行KMeansDemo.java后,会生成100个随机点,然后使用K-Means算法将这些点分成3个簇,最后打印出每个簇的中心点和包含的点。
三、分类算法
1、分类算法概述
分类算法是机器学习领域中最常用的一种算法,它的主要任务是将数据集中的数据根据其特征分成不同的类别。分类算法可以应用于多种应用领域,例如垃圾邮件分类、图像识别、自然语言处理、医学诊断等。
下面是常见的分类算法概述:
- 决策树:决策树是一种基于树形结构的分类方法。它通过对数据进行逐步划分,最终生成一颗决策树,使得对新的数据进行分类时,可以根据其特征值在决策树上进行推理,从而确定其类别。
- 朴素贝叶斯:朴素贝叶斯是一种基于概率统计的分类方法。它假设所有特征之间相互独立,并且通过贝叶斯公式计算每个类别的概率,然后选择概率最大的类别作为分类结果。
- 支持向量机:支持向量机是一种基于最大间隔原则的分类方法。它通过寻找数据点中距离分类边界最近的点,从而确定分类边界,并使分类边界与不同类别的数据点之间的距离最大化,从而提高分类的准确性。
- k-近邻算法:k-近邻算法是一种基于距离度量的分类方法。它将新的数据点与已有数据集中的最近邻数据点进行比较,并根据最近邻数据点的类别确定新数据点的类别。
- 神经网络:神经网络是一种模拟人脑神经网络结构的分类方法。它通过训练神经网络模型,将输入数据与目标输出之间的映射关系进行建模,并通过反向传播算法不断调整网络权值,从而提高分类的准确性。
2、决策树算法
算法
算法中用到的公式包括:
熵的计算公式:

信息增益的计算公式:
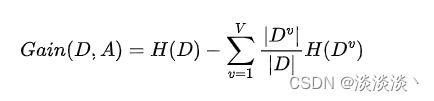
Java实现
import java.util.*;
public class DecisionTree {
private Node root;
// 决策树节点
private static class Node {
private final String attribute; // 节点对应的属性
private final Map children; // 子节点
private final String result; // 叶节点对应的结果
// 内部类的构造函数
private Node(String attribute) {
this.attribute = attribute;
this.children = new HashMap<>();
this.result = null;
}
private Node(String result, boolean isLeaf) {
this.attribute = null;
this.children = null;
this.result = result;
}
private boolean isLeaf() {
return result != null;
}
}
// 训练决策树
public void train(List> data) {
List attributes = new ArrayList<>(data.get(0).keySet()); // 获取数据中所有属性的列表
attributes.remove("label"); // 移除类别属性
root = buildTree(data, attributes);
}
// 递归地构建决策树
private Node buildTree(List> data, List attributes) {
if (data.isEmpty()) {
return new Node(null, true);
}
// 所有样本属于同一类别
String firstClass = data.get(0).get("label");
boolean allSameClass = data.stream().allMatch(d -> d.get("label").equals(firstClass));
if (allSameClass) {
return new Node(firstClass, true);
}
// 没有属性可分裂
if (attributes.isEmpty()) {
return new Node(majorityClass(data), true);
}
// 选择最佳分裂属性
String splitAttribute = selectBestAttribute(data, attributes);
Node node = new Node(splitAttribute);
// 递归构建子节点
Map>> splits = splitData(data, splitAttribute);
for (Map.Entry>> entry : splits.entrySet()) {
String value = entry.getKey();
List> subset = entry.getValue();
List remainingAttributes = new ArrayList<>(attributes);
remainingAttributes.remove(splitAttribute);
Node child = buildTree(subset, remainingAttributes);
node.children.put(value, child);
}
return node;
}
// 预测单个样本
public String predict(Map instance) {
Node node = root;
while (!node.isLeaf()) {
String attribute = node.attribute;
String value = instance.get(attribute);
node = node.children.get(value);
}
return node.result;
}
// 获取数据集中类别最多的类
private String majorityClass(List> data) {
Map counts = new HashMap<>();
for (Map instance : data) {
String cls = instance.get("label");
counts.put(cls, counts.getOrDefault(cls, 0) + 1);
}
return Collections.max(counts.entrySet(), Map.Entry.comparingByValue()).getKey();
}
//
// 计算信息熵
private double entropy(List> data) {
int n = data.size();
if (n <= 1) {
return 0;
}
Map counts = new HashMap<>();
for (Map instance : data) {
String cls = instance.get("label");
counts.put(cls, counts.getOrDefault(cls, 0) + 1);
}
double entropy = 0;
for (int count : counts.values()) {
double p = (double) count / n;
entropy -= p * Math.log(p) / Math.log(2);
}
return entropy;
}
// 计算信息增益
private double informationGain(List> data, String attribute) {
double entropyBeforeSplit = entropy(data);
Map>> splits = splitData(data, attribute);
double entropyAfterSplit = 0;
int n = data.size();
for (List> subset : splits.values()) {
double p = (double) subset.size() / n;
entropyAfterSplit += p * entropy(subset);
}
return entropyBeforeSplit - entropyAfterSplit;
}
// 选择信息增益最大的属性
private String selectBestAttribute(List> data, List attributes) {
String bestAttribute = null;
double maxInformationGain = -1;
for (String attribute : attributes) {
double informationGain = informationGain(data, attribute);
if (informationGain > maxInformationGain) {
maxInformationGain = informationGain;
bestAttribute = attribute;
}
}
return bestAttribute;
}
// 根据属性分裂数据
private Map>> splitData(List> data, String attribute) {
Map>> splits = new HashMap<>();
for (Map instance : data) {
String value = instance.get(attribute);
List> subset = splits.getOrDefault(value, new ArrayList<>());
subset.add(instance);
splits.put(value, subset);
}
return splits;
}
public static void main(String[] args) {
// 训练集
List> data = new ArrayList<>();
// 添加训练数据
Map instance1 = new HashMap<>();
instance1.put("outlook", "sunny");
instance1.put("temperature", "hot");
instance1.put("humidity", "high");
instance1.put("windy", "false");
instance1.put("label", "no");
data.add(instance1);
//自己编数据吧。。。
//构建决策树
DecisionTree decisionTree = new DecisionTree();
decisionTree.train(data);
// 进行预测
Map instance = new HashMap<>();
instance.put("outlook", "sunny");
instance.put("temperature", "cool");
instance.put("humidity", "high");
instance.put("windy", "false");
String prediction = decisionTree.predict(instance);
System.out.println("Prediction: " + prediction);
}
} 四、预测算法
1、预测算法概述
预测算法是一种机器学习算法,用于预测未来的事件或趋势。这些算法基于历史数据和统计分析,从中学习并推断出可能的未来情况。以下是几种常见的预测算法:
- 线性回归:线性回归是一种用于建立线性模型的算法,它将自变量与因变量之间的关系拟合为一条直线。
- 逻辑回归:逻辑回归是一种分类算法,它将输入特征映射到输出类别的概率上。
- 决策树:决策树是一种基于树形结构的算法,它通过将样本分割成不同的子集,最终输出预测结果。
- 随机森林:随机森林是一种集成学习算法,它通过组合多个决策树来进行预测,从而提高预测精度和鲁棒性。
- 神经网络:神经网络是一种模拟人脑的算法,它通过训练多层神经元来学习输入和输出之间的非线性映射关系。
2、线性回归算法
算法
线性回归是一种用于建立线性模型的算法,它可以用于预测因变量和自变量之间的关系。该算法的基本原理是建立一个线性方程,通过寻找最佳拟合线,来解决回归问题。
下面是线性回归的基本原理:
- 线性方程:线性回归假设因变量y和自变量x之间存在一个线性关系。该关系可以表示为y = β0 + β1*x + ε,其中β0和β1是回归系数,ε是误差项。
- 最小二乘法:最小二乘法是一种常用的求解线性回归系数的方法。该方法的目标是最小化误差平方和,即找到最佳拟合线,使得所有数据点到该线的距离之和最小化。
- 模型评估:线性回归的模型评估通常使用R方值和均方误差(MSE)来衡量模型的准确性。R方值表示模型解释的变异性占总变异性的比例,而MSE则表示模型预测值和真实值之间的平均偏差程度。
- 多元线性回归:当自变量不止一个时,可以使用多元线性回归模型。该模型可以表示为y = β0 + β1x1 + β2x2 + ... + βn*xn + ε,其中x1, x2, ..., xn是自变量,β1, β2, ..., βn是回归系数,ε是误差项。
Java实现
以下是一个基于Java语言实现的线性回归算法的示例代码,其中使用最小二乘法求解回归系数,以预测房价为例:
import java.util.ArrayList;
import java.util.List;
public class LinearRegressionDemo {
public static void main(String[] args) {
// 创建训练数据
List x = new ArrayList<>();
List y = new ArrayList<>();
x.add(2.0); y.add(10.0);
x.add(4.0); y.add(20.0);
x.add(5.0); y.add(22.0);
x.add(7.0); y.add(30.0);
x.add(8.0); y.add(33.0);
// 训练模型
double[] coefficients = train(x, y);
// 预测房价
double price = predict(coefficients, 6.0);
System.out.println("预测房价:" + price);
}
// 训练模型
public static double[] train(List x, List y) {
int n = x.size();
double xSum = 0.0, ySum = 0.0, xySum = 0.0, xxSum = 0.0;
for (int i = 0; i < n; i++) {
xSum += x.get(i);
ySum += y.get(i);
xySum += x.get(i) * y.get(i);
xxSum += x.get(i) * x.get(i);
}
double xMean = xSum / n;
double yMean = ySum / n;
double beta1 = (xySum - n * xMean * yMean) / (xxSum - n * xMean * xMean);
double beta0 = yMean - beta1 * xMean;
double[] coefficients = new double[2];
coefficients[0] = beta0;
coefficients[1] = beta1;
return coefficients;
}
// 预测房价
public static double predict(double[] coefficients, double x) {
double beta0 = coefficients[0];
double beta1 = coefficients[1];
return beta0 + beta1 * x;
}
} 该示例代码中,train方法用于训练模型,使用最小二乘法求解回归系数;predict方法用于预测房价,根据已训练好的回归系数来计算预测值。最后,在main方法中,我们可以通过train方法训练模型,然后使用predict方法来预测房价。当然,这里的训练数据只是一个简单的示例,实际应用中需要更多和更准确的数据来训练和测试模型。
五、结论
Java在机器学习领域具有广泛的应用前景。
1、适合大型应用程序:Java具有卓越的内存管理和处理能力,这使得它非常适合处理大型数据集和复杂的机器学习算法。Java中的JVM和垃圾回收机制可以保证大型程序的性能和稳定性。
2、应用程序的开发和部署:Java具有良好的跨平台性,可以轻松地在不同的操作系统和设备上进行开发和部署。Java的许多机器学习框架也可以方便地进行部署和管理。
3、强大的机器学习库:Java生态系统中有很多强大的机器学习库,如Weka、DL4J、Mallet、H2O等,这些库提供了许多有用的工具和算法,以帮助开发人员轻松地实现机器学习应用程序。
4、Java与大数据:Java在大数据领域也非常流行,它可以轻松地与大数据框架(如Hadoop、Spark和Flink)和其他大数据技术(如Kafka和Cassandra)集成,以进行分布式数据处理和分析。
5、Java与云计算:Java的跨平台性和强大的内存管理使其成为云计算领域的首选语言之一。许多云服务提供商都支持Java应用程序的部署和运行,如AWS、Azure和Google Cloud。
因此,Java在机器学习领域具有广泛的应用前景,尤其是在大规模数据处理、云计算和大数据分析等方面。