Python入门教学——多进程和多线程
目录
一、线程和进程
二、创建多个线程
三、锁
四、线程间通讯
五、创建多个进程
六、进程间通讯
七、总结
一、线程和进程
1、线程和进程的基本概念
- 进程是资源分配的最小单位,线程是CPU调度的最小单位。
- 进程:相当于是公司的老板,他自己本身不干活,但为干活的员工提供资源、平台。
- 线程:相当于是公司的员工,真正干活的人就是这些员工。
2、线程和进程的关系
- 一个线程只能属于一个进程,一个进程可以有多个进程,每个进程至少有一个线程(主线程)。
- 资源分配给进程,一个进程中的所有线程将共享该进程中所有资源。
- 线程在执行过程中,需要协作同步,不同进程间的线程需要利用消息向步机制来实现通讯。
- 真正执行任务的是线程,它是进程内可调度的实体。
- 创建进程要比创建线程消耗更多的计算机资源。
- 进程间不会相互影响,而相同进程内部如果有一个线程出现异常,则其他所有线程将全部被阻塞。
- 同一进程内不同线程使用同一个资源时需要加锁。
3、串行、并行和并发
- 串行:做完一件事再完成另一件事。完成任务时间是所有单个任务完成时间的总和。
- 并行:两个或多个事件在同一时刻发生,相当于多个人同时完成多件事,是物理意义上的并行。
- 并发:两个或多个事件在同一时间间隔内发生相当于一个人同时做多件事,是逻辑意义上的并行。
二、创建多个线程
1、线程相关的模块
- _thread:该模块是在python3之前thread模块的重命名,它是比较底层的模块,所以一般不会在代码中直接使用。
- threading:python3 之后的线程模块,编程中一般都使用这个模块来创建线程。
2、创建线程
2.1、通过Thread类构造器来创建新线程
- 使用threading.Thread直接生成一个线程,并且定义一个函数传给target,其中包含了该线程要完成的任务。
- 创建两个线程,分别去访问百度和搜狐的网站。
-
import threading import urllib.request # 访问网站 def get_web(url): # 访问网站 user_agent = '在从自己的浏览器里找' headers = { "User-Agent": user_agent } # 构造Request对象,以便我们设置http请求中的header信息 req = urllib.request.Request(url, headers=headers) resp = urllib.request.urlopen(req) print(resp.read().decode()[:50]) if __name__ == '__main__': t1=threading.Thread(target=get_web,args=('https://www.baidu.com/',)) # target是需要做的事情,利用args传参(元组形式) t2=threading.Thread(target=get_web,args=('https://www.sohu.com/',)) t1.start() # 启动线程,就会执行target的内容 t2.start() t1.join() # 等待子线程结束后,才执行主线程 t2.join() print("程序运行结束!") # 主线程的代码 - 【注】join方法:让子线程阻塞主线程的执行过程,也就是说使用了join之后,主线程会等待使用了join方法的子线程结束后再往下执行。
-
- 运行结果:

2.2、通过继承于Thread类来创建新线程
- 通过继承Thread类,重写__init__和run方法,__init__中可以添加许多自定义属性,run中是该线程要完成的任务。线程启动后,会自动执行__init__和run方法。
-
import threading import urllib.request # 新的线程类 class MyThread(threading.Thread): # 继承Thread def __init__(self,name,url): super().__init__() # 调用父类的初始化方法 self.name=name # 线程的名字 self.url=url # 启动线程后,run会被自动调用 def run(self): # 重写父类的run方法,定义在新的线程类里面要完成的任务 print(f"我是{self.name}") user_agent = '在从自己的浏览器里找' headers = { "User-Agent": user_agent } # 构造Request对象,以便我们设置http请求中的header信息 req = urllib.request.Request(self.url, headers=headers) resp = urllib.request.urlopen(req) print(resp.read().decode()[:50]) if __name__ == '__main__': t1=MyThread("线程1","https://www.baidu.com/") t2=MyThread("线程2","https://www.sohu.com/") t1.start() # 启动线程 t2.start() t1.join() # 等待子线程结束后,才执行主线程 t2.join() print("程序运行结束!") # 主线程的代码 - 运行结果:

三、锁
1.1、锁的概念
- 锁是多线程模块里的一个对象,只有拥有这个对象(锁),才能对共享资源进行操作。
- 作用:为了避免多个线程使用同一资源时产生错误。
1.2、GIL锁
- GIL锁:全局解释器锁,在同一个进程中只要有一个线程获取了全局解释器(cpu)的使用权限,那么其他的线程就必须等待该线程的全局解释器(cpu)使用权消失后才能使用全局解释器(cpu),即使多个线程直接不会相互影响在同一个进程下也只有一个线程使用cpu。
- GIL锁释放条件:
- 当前的执行线程在执行IO操作时,会主动放弃GIL。
- 当前执行的线程执行了100条字节码的时候,会自动释放GIL锁。
- 【注】GIL全局解释器锁是粗粒度的锁,必须配合线程模块中的锁才能对每个原子操作(不可再拆分的操作)进行锁定。
1.3、如何加锁
-
import threading num=0 lock=threading.Lock() # 创建锁 def deposit(): for i in range(1000000): lock.acquire() # 获取锁 global num num+=1 lock.release() # 释放锁 def withdraw(): for i in range(1000000): with lock: # 自动获取锁和释放锁 global num num-=1 if __name__ == '__main__': t1=threading.Thread(target=deposit) t2=threading.Thread(target=withdraw) t1.start() t2.start() t1.join() t2.join() print(num) - 【注】获取锁和释放锁必须成对出现。
四、线程间通讯
- 线程间的通信方式有很多,最常用的是利用消息队列进行通讯。
1.1、消息队列
- 消息队列是在消息的传输过程中保存消息的容器,主要用于不同线程间任意类型数据的共享。
- 消息队列最经典的用法就是消费者和生成者之间通过消息管道来传递消息,消费者和生成者是不同的线程。生产者往管道中写消息,消费者从管道中读消息,且一次只允许一个线程访问管道。
1.2、常用接口
-
from queue import Queue q =Queue(maxsize=0) # 初始化,maxsize=0表示队列的消息个数不受限制;maxsize>0表示存放限制 q.get() # 提取消息,如果队列为空会阻塞程序,等待队列消息 q.get(timeout=1) # 阻塞程序,设置超时时间 q.put() # 发送消息,将消息放入队列
1.3、演示
- 使用生产者和消费者的案例进行演示。
-
from queue import Queue import threading import time def product(q): # 生产者 kind = ('猪肉','白菜','豆沙') for i in range(3): print(threading.current_thread().name,"生产者开始生产包子") time.sleep(1) q.put(kind[i%3]) # 放入包子 print(threading.current_thread().name,"生产者的包子做完了") def consumer(q): # 消费者 while True: print(threading.current_thread().name,"消费者准备吃包子") time.sleep(1) t=q.get() # 拿出包子 print("消费者吃了一个{}包子".format(t)) if __name__=='__main__': q=Queue(maxsize=1) # 启动两个生产者线程 threading.Thread(target=product,args=(q, )).start() threading.Thread(target=product,args=(q, )).start() # 启动一个消费者线程 threading.Thread(target=consumer,args=(q, )).start()
-
- 运行结果:

五、创建多个进程
1、以指定函数作为参数创建进程
- 与通过Thread类构造器来创建新线程的方法类似,只不过使用的模块不同。
-
import multiprocessing # 引入多进程模块 import urllib.request # 访问网站 def get_web(url): # 访问网站 user_agent = '在自己的浏览器里找' headers = { "User-Agent": user_agent } # 构造Request对象,以便我们设置http请求中的header信息 req = urllib.request.Request(url, headers=headers) resp = urllib.request.urlopen(req) print(resp.read().decode()[:50]) if __name__ == '__main__': p1=multiprocessing.Process(target=get_web,args=('https://www.baidu.com/',)) p2=multiprocessing.Process(target=get_web,args=('https://www.sohu.com/',)) p1.start() # 启动进程 p2.start() p1.join() # 等待子进程结束后,才执行主进程 p2.join() print("进程操作全部执行完毕!") # 主进程的代码
-
- 运行结果:
-

2、继承Process类创建进程
- 与通过继承于Thread类来创建新线程的方法类似。通过继承Process类,重写__init__和run方法,__init__中可以添加许多自定义属性,run中是该进程要完成的任务。进程启动后,会自动执行__init__和run方法。
-
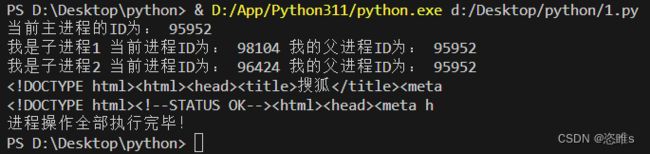
import multiprocessing import urllib.request import os # 拿到进程id # 新的进程类 class MyProcess(multiprocessing.Process): # 继承Process def __init__(self,name,url): super().__init__() # 调用父类的初始化方法 self.name=name # 进程的名字 self.url=url # 启动进程后,run会被自动调用 def run(self): # 重写父类的run方法,定义在新的进程类里面要完成的任务 print(f"我是{self.name}","当前进程ID为:",os.getpid(),"我的父进程ID为:",os.getppid()) user_agent = '在自己的浏览器里找' headers = { "User-Agent": user_agent } # 构造Request对象,以便我们设置http请求中的header信息 req = urllib.request.Request(self.url, headers=headers) resp = urllib.request.urlopen(req) print(resp.read().decode()[:50]) if __name__ == '__main__': print("当前主进程的ID为:",os.getpid()) p1=MyProcess("子进程1","https://www.baidu.com/") p2=MyProcess("子进程2","https://www.sohu.com/") p1.start() # 启动进程 p2.start() p1.join() # 等待子进程结束后,才执行主进程 p2.join() print("进程操作全部执行完毕!") # 主进程的代码
-
- 运行结果:
六、进程间通讯
- 进程间也可以使用消息队列进行通讯。
-
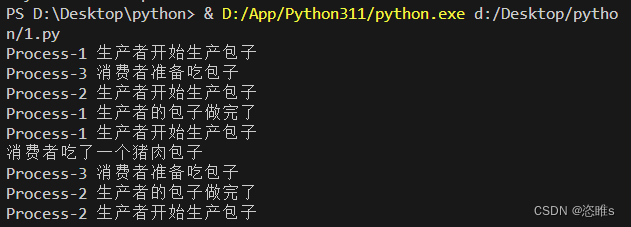
import multiprocessing import time def product(q): # 生产者 kind = ('猪肉','白菜','豆沙') for i in range(3): print(multiprocessing.current_process().name,"生产者开始生产包子") time.sleep(1) q.put(kind[i%3]) # 放入包子 print(multiprocessing.current_process().name,"生产者的包子做完了") def consumer(q): # 消费者 while True: print(multiprocessing.current_process().name,"消费者准备吃包子") time.sleep(1) t=q.get() # 拿出包子 print("消费者吃了一个{}包子".format(t)) if __name__=='__main__': q=multiprocessing.Queue(maxsize=1) # 创建多进程队列对象 # 启动两个生产者进程 p1=multiprocessing.Process(target=product,args=(q,)) p2=multiprocessing.Process(target=product,args=(q,)) p1.start() p2.start() # 启动一个消费者进程 p3=multiprocessing.Process(target=consumer,args=(q,)) p3.start()
-
- 运行结果:
七、总结
1、多线程和多进程的优缺点
- 多进程的优点:独立运行,互不影响。
- 多进程缺点:创建进程的代价非常大。
- 多线程优点:效率比较高,不会耗费大量资源。
- 多线程缺点:稳定性较差,一个崩溃后会影响整个进程。
2、使用场景
- 多进程适用场景:适合计算密集型任务。
- 多线程适用场景:适合 IO 密集型任务,如文件读取以及爬虫等操作。