SIM卡联系人代码分析
1、SIM卡读取 ADN SDN FDN
ADN :Abbreviated Dialling numbers
FDN :Fixed Dialling numbers
SDN : Service Dialling Numbers
PBR : Phone Book Reference file
2、USIM卡读取 PBR SDN FDN
详见IccPhoneBookInterfaceManager.java
protected int updateEfForIccType(int efid) {
// Check if we are trying to read ADN records
if (efid == IccConstants.EF_ADN) {
if (mPhone.getCurrentUiccAppType() == AppType.APPTYPE_USIM) {
return IccConstants.EF_PBR;
}
}
return efid;
}3、SDN格式
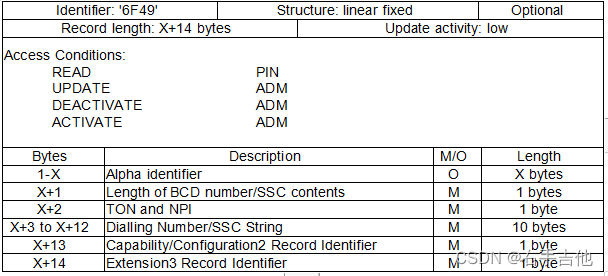
Alpha indentifier 名字
如果包含中文等字符,则正常采用80编码格式,即整个姓名字符以80开头,后面跟上UCS2数据,但有些情况下又会采用81或者82开头。
80 开头:
80开头的为ucs2格式(注意:后面的字符必须有中文才行,否则可能是以80开头的纯ASCII字符串),大头在前,小头在后。
例1:中国 UNICODE编码为:4E2D56FD
用ucs2的80方案表示是:804E2D56FD
例2:杜10娘
UNICODE编码为:675C003100305A18
用ucs2的80方案表示是:80675C003100305A18 显然只要有中文,数字也得占用两个字节
81 开头:
81开头的格式中,包含一个基址(一个字节)。有这个基址,就可以用一个字节表示一个ucs2字符了。 在格式上,81是标识,后一个字节表示整个字符串长度,再后面一个字节是基址,再往后的就都是数据了。
例3:杜杜杜
UNICODE编码为:675C675C675C
用ucs2的80方案表示是:80675C675C675C
用ucs2的81方案表示是:8103CEDCDCDC
分析一下UCS2的81方案:8103CEDCDCDC
81:为标记
03:表示整个字符串为3个字符
CE:一个字节为基址。解析的方法为:将基址(CE)左移七位,并将最高位置为0,最低位再补一个0(这样就16位啦)。
此时基址变为0x6700,然后再判断后面的数据字节。 DCDCDC:3个数据字节 DC, DC, DC 。
如果数据字节的最高位为0,则认为此字节是一个ASCII字符。
如果数据字节的最高位为1,则低7位为基址的一个偏移,实际的UCS2字符为基址加上这个偏移值。由于此处三个数据字节最高位都为1,则实际的3个字符的偏移值为:5C, 5C, 5C。实际的UCS2编码为: 0x675C 0x675C 0x675C
82 开头: 82开头的格式中,包含一个基址(两个字节)。有这个基址,就可以用一个字节表示一个ucs2字符了。 在格式上,81是标识,后一个字节表示整个字符串长度,再后面两个字节是基址,再往后的就都是数据了。先举一例:
例4:8025EF芳
UNICODE编码为:00380030003200350045004682B3
用ucs2的80方案表示是:8000380030003200350045004682B3
用ucs2的81方案表示是:(因为格式的限制,最多容纳128个中文和127个英文,所以此处无法用81格式表示) 用ucs2的82方案表示是:82078280383032354546B3
分析一下UCS2的82方案:82078280383032354546B3
82:为标记
07:表示整个字符串为7个字符
8280:两个字节为基址。
383032354546B3:7个数据字节 38,30,32,35,45,46,B3。
如果数据字节的最高位为0,则认为此字节是一个ASCII字符。
如果数据字节的最高位为1,低7位为基址的一个偏移,实际的UCS2字符为基址加上这个偏移值。由于此处七个数据字节的前六个字节最高位为0,所以表示6个ASCII字符0x38,0x30,0x32,0x35,0x45,即8,0,2,5,E,F。第七个字节的最高位为1,则此数据的偏移值为0x33,需要加上基址 0x8280,UCS2编码为0x82B3(芳)
详见IccUtils.java
public static String
adnStringFieldToString(byte[] data, int offset, int length) {
if (length == 0) {
return "";
}
if (length >= 1) {
if (data[offset] == (byte) 0x80) {
int ucslen = (length - 1) / 2;
String ret = null;
try {
ret = new String(data, offset + 1, ucslen * 2, "utf-16be");
} catch (UnsupportedEncodingException ex) {
Rlog.e(LOG_TAG, "implausible UnsupportedEncodingException",
ex);
}
if (ret != null) {
// trim off trailing FFFF characters
ucslen = ret.length();
while (ucslen > 0 && ret.charAt(ucslen - 1) == '\uFFFF')
ucslen--;
return ret.substring(0, ucslen);
}
}
}
boolean isucs2 = false;
char base = '\0';
int len = 0;
if (length >= 3 && data[offset] == (byte) 0x81) {
len = data[offset + 1] & 0xFF;
if (len > length - 3)
len = length - 3;
base = (char) ((data[offset + 2] & 0xFF) << 7);
offset += 3;
isucs2 = true;
} else if (length >= 4 && data[offset] == (byte) 0x82) {
len = data[offset + 1] & 0xFF;
if (len > length - 4)
len = length - 4;
base = (char) (((data[offset + 2] & 0xFF) << 8) |
(data[offset + 3] & 0xFF));
offset += 4;
isucs2 = true;
}
if (isucs2) {
StringBuilder ret = new StringBuilder();
while (len > 0) {
// UCS2 subset case
if (data[offset] < 0) {
ret.append((char) (base + (data[offset] & 0x7F)));
offset++;
len--;
}
// GSM character set case
int count = 0;
while (count < len && data[offset + count] >= 0)
count++;
ret.append(GsmAlphabet.gsm8BitUnpackedToString(data,
offset, count));
offset += count;
len -= count;
}
return ret.toString();
}
Resources resource = Resources.getSystem();
String defaultCharset = "";
try {
defaultCharset =
resource.getString(com.android.internal.R.string.gsm_alphabet_default_charset);
} catch (NotFoundException e) {
// Ignore Exception and defaultCharset is set to a empty string.
}
return GsmAlphabet.gsm8BitUnpackedToString(data, offset, length, defaultCharset.trim());
}BCD码(Binary-Coded Decimal),用4位二进制数来表示1位十进制数中的0~9这10个数码
8421 BCD码是最基本和最常用的BCD码,它和四位自然二进制码相似,各位的权值为8、4、2、1,故称为有权BCD码。和四位自然二进制码不同的是,它只选用了四位二进制码中前10组代码,即用0000~1001分别代表它所对应的十进制数,余下的六组代码不用。
5421 BCD码和2421 BCD码为有权BCD码,它们从高位到低位的权值分别为5、4、2、1和2、4、2、1。
TON Type-of-Number
Bits 7: 始终为1 Bits 6,5,4:Type-of-Number(号码类型):
001,代表Internation Number。也即是号码前加“+”。注意:对某些比较特殊的号码,例如手机与小灵通的互通时,这里不能设置为001,而要设置成000,代表号码前没有 “+”,否则无法接收。 下面是GSM03.40协议号码类型的解释:
0 0 0 Unknown
0 0 1 International number
0 1 0 National number
0 1 1 Network specific number
1 0 0 Subscriber number
1 0 1 Alphanumeric(coded according to TS03.38 7-bit default alphabet)
1 1 0 Abbreviated number
1 1 1 Reserved for extension
NPI Numbering-plan-identification
Bits 3,2,1,0:Numbering-plan-identification(号码鉴别),
0000—未知,0001—ISDN/电话号码(E.164 /E.163),
1111—留作扩展;一般默认为0001,表示电话号码类型的。
下面是GSM03.40号码鉴别的解释:
Bits4 3 2 1
0 0 0 0 Unknown
0 0 0 1 ISDN/telephone numbering plan (E.164/E.163)
0 0 1 1 Data numbering plan (X.121)
0 1 0 0 Telex numbering plan
1 0 0 0 National numbering plan
1 0 0 1 Private numbering plan
1 0 1 0 ERMES numbering plan (ETSI DE/PS 3 01-3)
1 1 1 1 Reserved for extension All other values are reserved.
Dialing Number号码,使用BCD编码解析
SIM卡联系人记加载过程如下

要了解详细代码加载流程,需要对SIM卡相关协议有所了解,比如EF文件头
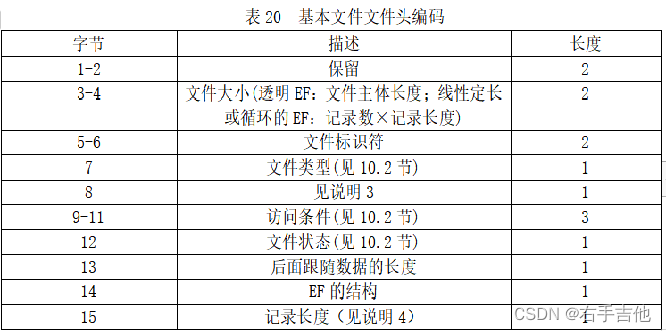
其中
文件大小-------------第3-4字节
文件类型 -------------第7字节
00’:保留
‘01’:MF
‘02’:DF
‘04’:EF
的结构 -------------第14字节
‘00’:透明文件
‘01’:线性定长文件
‘03’:循环文件;
记录长度-------------第15字节
这些文件在Android代码中都有相关定义,参考IccFileHandler.java,由于数组字节数是从0开始的,因此相关定义在协议基础上-1.
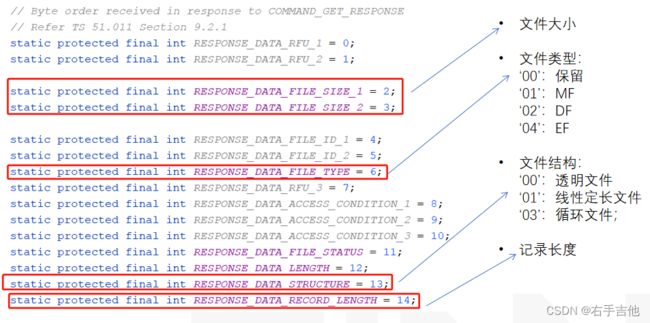
线性定长文件会先获取文件头确定总记录数后,轮询记录

相关Log打印如下
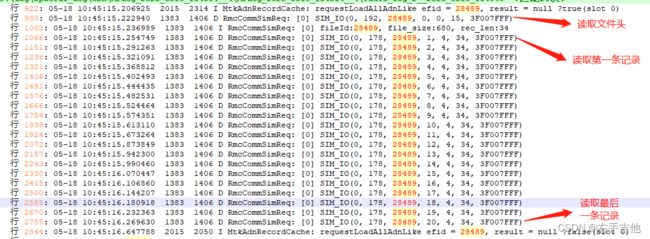
4 PBR介绍
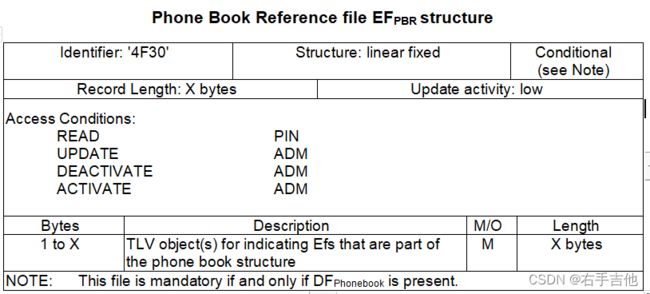
PBR每条记录使用TLV格式记录,分别有3种不TAG

A8 主文件,比如ADN,联系人组件
A9 通过EFIAPl连接,非公用的,比如联系人有100条,Email只能50条,但是每个联系人有不同Email
AA 通过主文件连接,公用的,多条联系人用一个,比如群组
PBR中的TLV属于嵌套TLV格式


如下
举个例
相关Log打印

抓取PBR Log
MtkUsimPhoneBookManager: PBR rec:
A81E
C0034F3A0A
C4034F5B0D
C6034F520C
C5034F420B
C9034F6213
C1034F3210
A905
CA034F7211
AA14
C2034F4A08
C7034F4B14
C8034F4C15
CB034F4F1D
FFFFFFFFFFFFFFFFFFFFFFFFFFFFFF(slot 0)
仅A8 AA PBR图示

A9 EFIAP图示

PBR解析详见UsimPhoneBookManager.java中的PbrRecord类
void parseTag(SimTlv tlv) {
SimTlv tlvEfSfi;
int tag;
byte[] data;
do {
tag = tlv.getTag();
switch (tag) {
case USIM_TYPE1_TAG: // A8
case USIM_TYPE3_TAG: // AA
case USIM_TYPE2_TAG: // A9
data = tlv.getData();
tlvEfSfi = new SimTlv(data, 0, data.length);
parseEfAndSFI(tlvEfSfi, tag);
break;
default:
break;
}
} while (tlv.nextObject());
mSliceCount++;
}
void parseEfAndSFI(SimTlv tlv, int parentTag) {
int tag;
byte[] data;
int tagNumberWithinParentTag = 0;
do {
tag = tlv.getTag();
// log("parseEf tag is " + tag);
switch (tag) {
case USIM_EFEMAIL_TAG:
case USIM_EFADN_TAG:
case USIM_EFEXT1_TAG:
case USIM_EFANR_TAG:
case USIM_EFPBC_TAG:
case USIM_EFGRP_TAG:
case USIM_EFAAS_TAG:
case USIM_EFGSD_TAG:
case USIM_EFUID_TAG:
case USIM_EFCCP1_TAG:
case USIM_EFIAP_TAG:
case USIM_EFSNE_TAG:
/** 3GPP TS 31.102, 4.4.2.1 EF_PBR (Phone Book Reference file)
*
* The SFI value assigned to an EF which is indicated in EF_PBR shall
* correspond to the SFI indicated in the TLV object in EF_PBR.
* The primitive tag identifies clearly the type of data, its value
* field indicates the file identifier and, if applicable, the SFI
* value of the specified EF. That is, the length value of a primitive
* tag indicates if an SFI value is available for the EF or not:
* - Length = '02' Value: 'EFID (2 bytes)'
* - Length = '03' Value: 'EFID (2 bytes)', 'SFI (1 byte)'
*/
int sfi = INVALID_SFI;
data = tlv.getData();
if (data.length < 2 || data.length > 3) {
Rlog.w(LOG_TAG, "Invalid TLV length: " + data.length);
break;
}
if (data.length == 3) {
sfi = data[2] & 0xFF;
}
int efid = ((data[0] & 0xFF) << 8) | (data[1] & 0xFF);
//M:
if (tag == USIM_EFANR_TAG) { //for handle multiple ANR, we should modify tag
tag += 0x100 * mAnrIndex;
mAnrIndex++;
}
File object = new File(parentTag, efid, sfi, tagNumberWithinParentTag);
object.mTag = tag; //TODO: add to constructor
object.mPbrRecord = mSliceCount;
logi("pbr " + object);
mFileIds.put(tag, object);
break;
default:
break;
}
tagNumberWithinParentTag++;
} while (tlv.nextObject());
}
}相关缩写
EFAAS (Additional number Alpha String)
EFADN(Abbreviated dialling numbers)
EFANR (Additional Number)
EFEMAIL (e-mail address)
EFEXT1 (Extension1)
EFGAS (Grouping information Alpha String)
EFGRP (Grouping file)
EFIAP (Index Administration Phone book)
EFPBC (Phone Book Control)
EFSNE (Second Name Entry)
EFUID (Unique Identifier)
EFCCP1 (Capability Configuration Parameters 1)
EFPURI (Phonebook URIs)
由于相关文件均为线性定长文件加载过程与SDN类似只是联系人A9 AA相关映射需要做出一些处理,增加了加载难度。