Python 爬虫 | 爬取股票概念数据
这段时间写了行业板块、涨跌停板数据,获取这些数据的目的就是想通过处理、分析这些数据把整个大盘的情况反馈给我,让我可以用最少的时间进行复盘(说白了就是懒得看,果然懒才是程序员的第一生产力)。这几天把这些数据给我一个大佬朋友进行分析,建议我增加多一个概念数据(让我又可以水一篇)。
目标网站:
aHR0cDovL3F1b3RlLmVhc3Rtb25leS5jb20vY2VudGVyL2JvYXJkbGlzdC5odG1sI2NvbmNlcHRfYm9hcmQ=
难度:⭐
环境配置:
requests、pandas
目标数据:

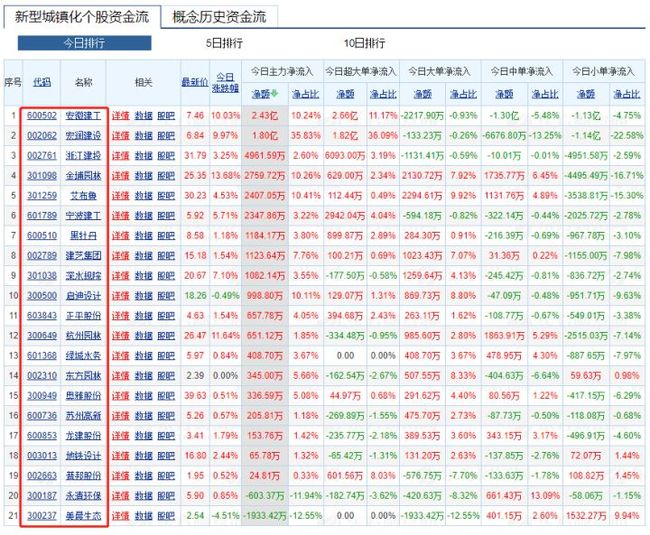
我需要获取概念、当日概念的领涨个股以及该概念下的股票。
目录:
1、分析请求
2、代码实现
1、分析请求
其实这些数据获取难度不高,掌握了爬虫基本功很快就能解决,剩下的就是存储数据。
打开开发者工具刷新请求后Ctrl+F查找关键词就能很快定位数据所在的请求。
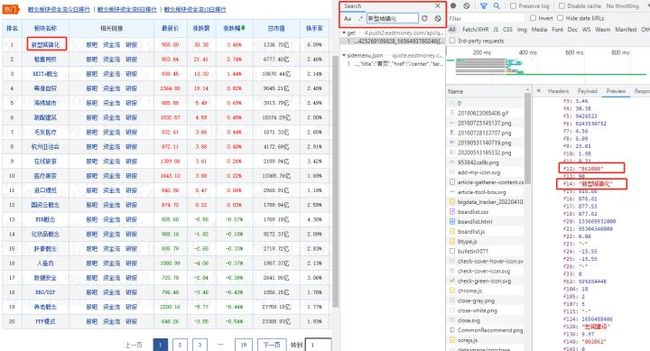
观察一下url,根据这几次的爬取我知道url中大概率是有个参数控制一次返回的数据量的。我是观察哪个参数的数值是20,因为这个网站一页展示的数据量通常是20条。
http://4.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112401376425269199828_1656493760246&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:90+t:3+f:!50&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f26,f22,f33,f11,f62,f128,f136,f115,f152,f124,f107,f104,f105,f140,f141,f207,f208,f209,f222&_=1656493760247
通过观察和测试很快就可以知道pz是控制返回数据量的关键参数。
再看看概念下所属的个股
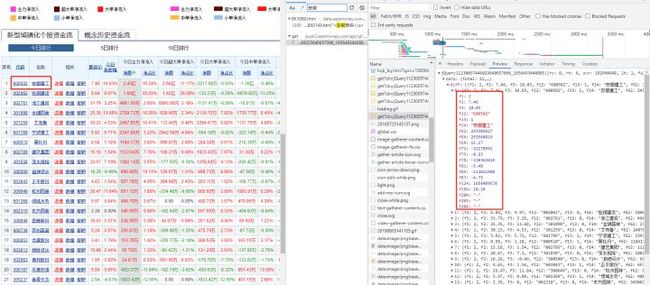
观察一下url
https://push2.eastmoney.com/api/qt/clist/get?cb=jQuery11230057446023640657096_1656493440885&fid=f62&po=1&pz=50&pn=1&np=1&fltt=2&invt=2&ut=b2884a393a59ad64002292a3e90d46a5&fs=b%3ABK1080&fields=f12%2Cf14%2Cf2%2Cf3%2Cf62%2Cf184%2Cf66%2Cf69%2Cf72%2Cf75%2Cf78%2Cf81%2Cf84%2Cf87%2Cf204%2Cf205%2Cf124%2Cf1%2Cf13
发现很多%2C,这只是url编码而已,网上随便找一个url在线解码即可。
解完码:
https://push2.eastmoney.com/api/qt/clist/get?cb=jQuery11230057446023640657096_1656493440885&fid=f62&po=1&pz=50&pn=1&np=1&fltt=2&invt=2&ut=b2884a393a59ad64002292a3e90d46a5&fs=b:BK1080&fields=f12,f14,f2,f3,f62,f184,f66,f69,f72,f75,f78,f81,f84,f87,f204,f205,f124,f1,f13
观察是哪个参数解决了返回的是哪个概念数据,很快就可以找到fs这个参数中有BK1080,这个是概念的指数代码。那想要大量获取概念数据就需要解决每个概念对应的指数代码是什么。观察图1-1中就可以很快找到概念对应的指数代码。
2、代码实现
实现思路:
一、获取概念进入数据以及对应的指数代码
二、依据一中得到的指数代码构造url拿到概念下所属的个股
三、获取个股的地区板块数据(告诉你们个好玩的)
代码我就不解释了吧?看不懂的该好好学学基础了。
一、获取概念数据
concept_url = "http://94.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112404219515748621301_1656315378776&pn=1&" \
"pz=500&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&" \
"fs=m:90+t:3+f:!50&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24," \
"f25,f26,f22,f33,f11,f62,f128,f136,f115,f152,f124,f107,f104,f105,f140,f141,f207,f208,f209,f222&_=" \
f"{int(time.time() * 1000)}"
date = get_standard_date(timestamp=time.time())
response = requests.request("GET", concept_url, headers=headers)
concept_index_list = []
concept_name, up_down, representative = [], [], []
for i in jquery_list(jquery=response.text, data_mode='{')['data']['diff']:
if i['f14'] in ('昨日连板_含一字', '昨日连板', '昨日涨停_含一字', '昨日涨停', '昨日跌停', '昨日触板', '创业板综', 'B股', '上证180_', 'AH股'):
continue
concept_index_list.append((i['f12'], i['f14']))
concept_name.append(i['f14'])
up_down.append(i['f3'])
representative.append(i['f128'])
concept_data = {'概念名称': concept_name, '概念涨跌幅': up_down, '领涨个股': representative}
save_data(data=concept_data, file_name='概念数据', header=True)
二、获取概念下所属的个股
step = 1
for i in concept_index_list:
# 概念明细
concept_detail_url = "https://push2.eastmoney.com/api/qt/clist/get?cb=jQuery112309520971118134538_1656316025491&" \
"fid=f62&po=1&pz=500&pn=1&np=1&fltt=2&invt=2&ut=b2884a393a59ad64002292a3e90d46a5&" \
f"fs=b:{i[0]}&fields=f12,f14,f2,f3,f62,f184,f66,f69,f72,f75,f78,f81,f84,f87,f102,f204,f205," \
"f124,f1,f13"
result = requests.request("GET", concept_detail_url, headers=headers)
stock_code, stock_name = [], []
try:
for x in jquery_list(jquery=result.text, data_mode='{')['data']['diff']:
code_index = judge_index(x['f12'])
stock_code.append(code_index)
stock_name.append(x['f14'])
zone_data.append((code_index, x['f14'], x['f102']))
except TypeError:
print('该概念有问题!')
data = {'概念': [i[1]] * len(stock_code), '代码': stock_code, '名称': stock_name}
if step == 1:
save_data(data=data, file_name='概念数据-所属个股')
else:
save_data(data=data, file_name='概念数据-所属个股', header=False)
step += 1
time.sleep(0.5)
三、获取地区数据
观察这些返回的数据你会发现并没有地区相关的数据,是没有,但是我们可以让接口返回地区数据。在上一篇中我就说了这个网站链接的参数是很好修改的,只要你知道地区参数是哪个就可以轻松获取地区数据,地区数据是f102,只需要在链接后加上这个参数即可获取地区数据。
数据获取到这一步也算收集的差不多了,之后可以依据这些数据先初步搭建一个分析框架(又挖坑)。