【计算机视觉 | CNN】Image Model Blocks的常见算法介绍合集(四)
文章目录
-
- 一、Dilated Bottleneck with Projection Block
- 二、NVAE Generative Residual Cell
- 三、NVAE Encoder Residual Cell
- 四、Bottleneck Transformer Block
- 五、Spatial Feature Transform
- 六、Big-Little Module
- 七、Scale Aggregation Block
- 八、Multiscale Dilated Convolution Block
- 九、XCiT Layer
- 十、Local Patch Interaction
- 十一、MLP-Mixer Layer
- 十二、Style-based Recalibration Module
- 十三、Two-Way Dense Layer
- 十四、SqueezeNeXt Block
- 十五、Extremely Efficient Spatial Pyramid of Depth-wise Dilated Separable Convolutions
- 十六、CSPResNeXt Block
- 十七、Elastic Dense Block
- 十八、DVD-GAN GBlock
- 十九、DVD-GAN DBlock
- 二十、Local Relation Network
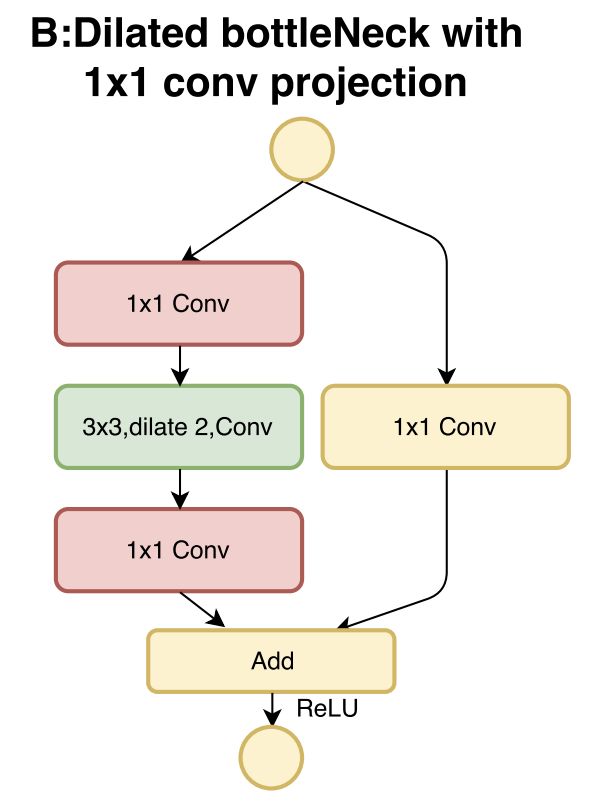
一、Dilated Bottleneck with Projection Block
Dilated Bottleneck with Projection Block 是 DetNet 卷积神经网络架构中使用的图像模型块。 它采用带有扩张卷积的瓶颈结构来有效地扩大感受野。 它使用 1x1 卷积来确保空间大小保持固定。
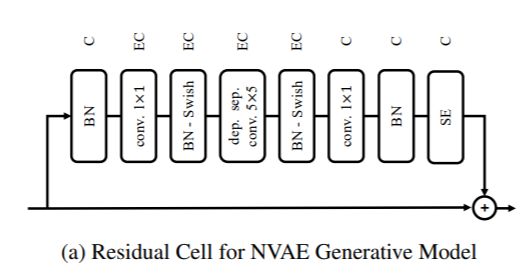
二、NVAE Generative Residual Cell
NVAE 生成残差单元是一个跳跃连接块,用作生成器 NVAE 架构的一部分。 残存细胞扩大通道数E应用深度可分离卷积之前的时间,然后将其映射回C渠道。 设计动机是通过增加网络的感受野来帮助对数据中的远程相关性进行建模,这解释了扩展路径,同时也解释了使用深度卷积来控制参数计数。
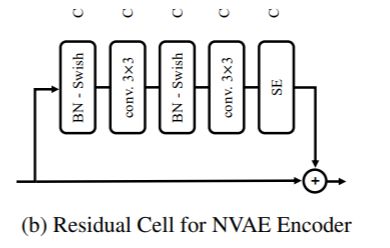
三、NVAE Encoder Residual Cell
NVAE 编码器残差单元是编码器 NVAE 架构中使用的残差连接块。 它应用了两个系列的 BN-Swish-Conv 层,而不改变通道数。
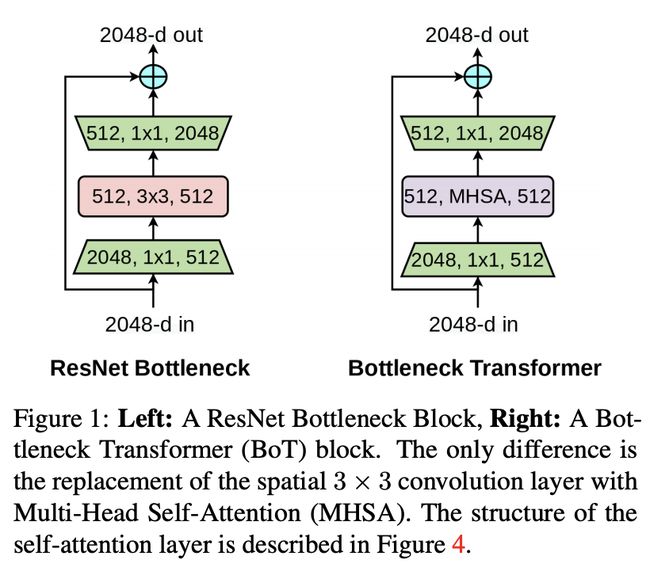
四、Bottleneck Transformer Block
Bottleneck Transformer Block 是 Bottleneck Transformer 中使用的块,它用多头自注意力 (MHSA) 替换残差块中的空间 3 × 3 卷积层。
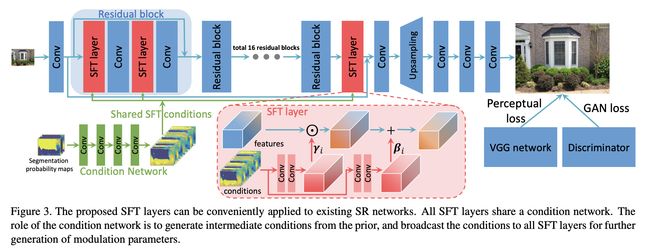
五、Spatial Feature Transform

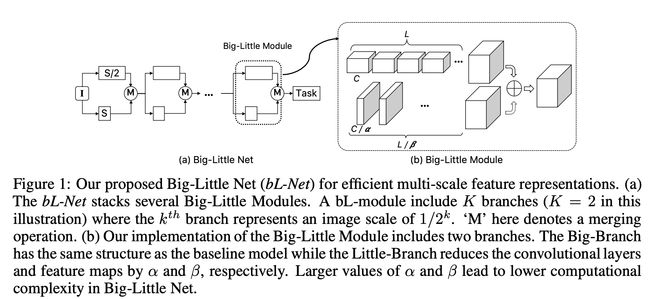
六、Big-Little Module
Big-Little 模块是具有两个分支的图像模型块:每个分支代表一个来自深度模型的单独块和一个不太深的对应块。 它们被提议作为 BigLittle-Net 架构的一部分。 这两个分支通过线性组合和单位权重融合。 这两个分支被称为大分支(低分辨率下更多层和通道)和小分支(高分辨率下更少层和通道)。
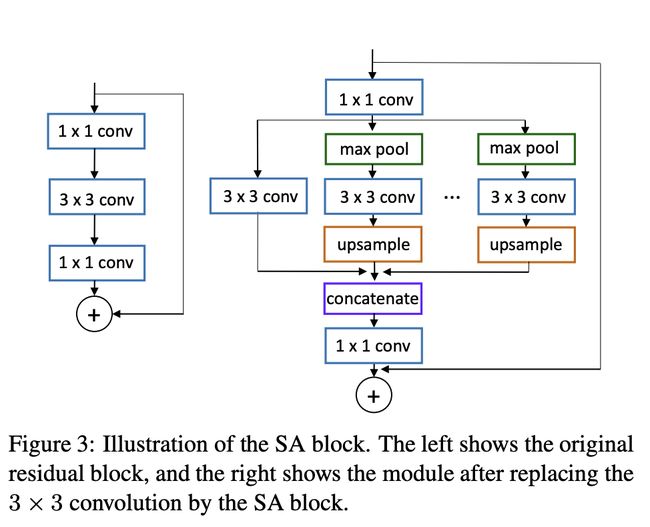
七、Scale Aggregation Block

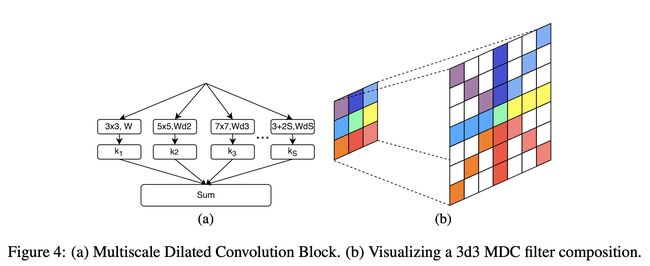
八、Multiscale Dilated Convolution Block
多尺度扩张卷积块是一种 Inception 风格的卷积块,其动机是图像特征自然地出现在多个尺度上,网络的表达能力与它可以表示的函数范围除以参数总数成正比,再除以 希望有效地扩展网络的感受野。 多尺度扩张卷积 (MDC) 块应用单个 F × F F \times F F×F在多个扩张因子下进行过滤,然后对每个扩张过滤器的输出执行加权元素求和,从而允许网络以最小的参数增加同时学习一组特征以及这些特征出现的相关尺度。 这也快速扩展了网络的感受野,而无需增加深度或参数数量。
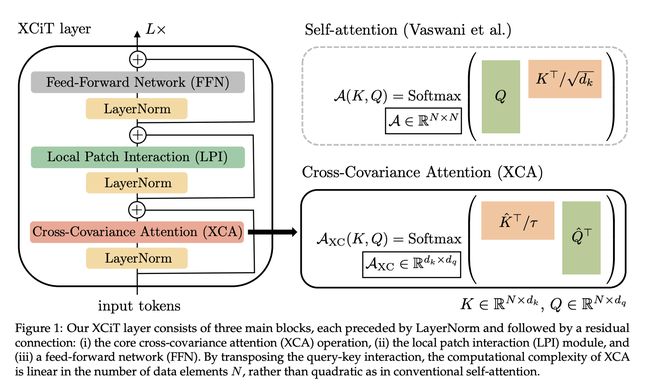
九、XCiT Layer
XCiT 层是 XCiT 架构的主要构建块,它使用交叉协方差注意算子作为其主要操作。 XCiT 层由三个主要块组成,每个块前面都有 LayerNorm,后面跟着一个残差连接:(i) 核心交叉协方差注意 (XCA) 操作,(ii) 局部补丁交互 (LPI) 模块,以及 (iii) 前馈网络(FFN)。 通过转置查询-键交互,XCA 的计算复杂度与数据元素的数量 N 呈线性关系,而不是像传统的自注意力机制那样呈二次方关系。
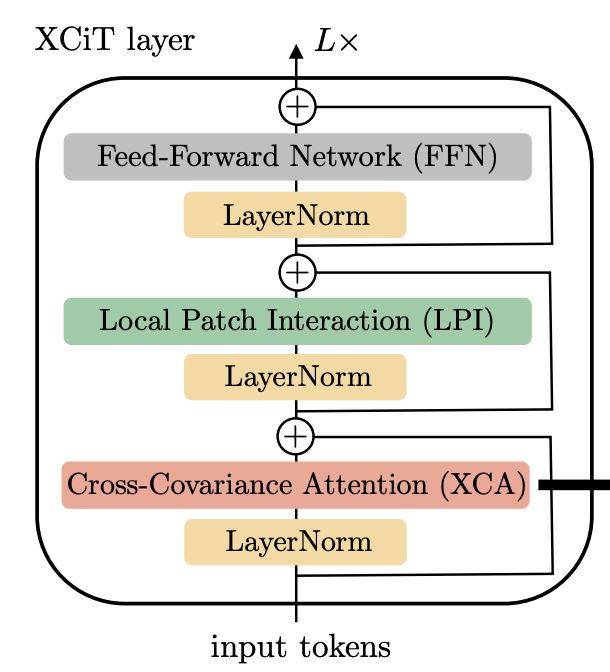
十、Local Patch Interaction
本地补丁交互(LPI)是一个用于 XCiT 层的模块,用于实现补丁之间的显式通信。 LPI 由两个深度方向的 3×3 卷积层组成,其间具有 Batch Normalization 和 GELU 非线性。 由于其深度结构,LPI 块在参数方面的开销可以忽略不计,并且在推理期间的吞吐量和内存使用方面的开销也有限。
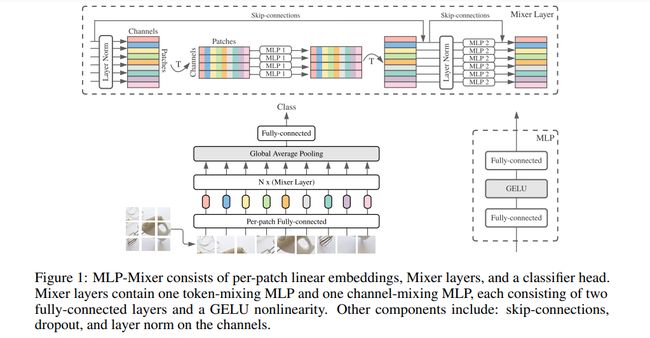
十一、MLP-Mixer Layer
Mixer 层是 Tolstikhin 等人提出的 MLP-Mixer 架构中使用的层。 al (2021) 用于计算机视觉。 混合器层纯粹由 MLP 组成,没有卷积或注意力。 它接受嵌入图像块(令牌)的输入,其输出与其输入具有相同的形状,类似于 Vision Transformer 编码器。 正如其名称所示,Mixer 层通过其包含该层的“令牌混合”和“通道混合”MLP 来“混合”令牌和通道。 它利用了其他架构先前的技术,例如层归一化、跳跃连接和正则化方法。
十二、Style-based Recalibration Module
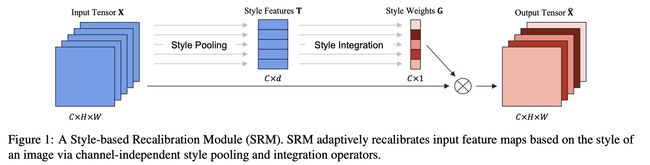
基于风格的重新校准模块 (SRM) 是一个用于卷积神经网络的模块,它通过利用中间特征图的风格来自适应地重新校准中间特征图。 SRM首先通过风格池化从特征图的每个通道中提取风格信息,然后通过与通道无关的风格集成来估计每个通道的重新校准权重。 通过将个体风格的相对重要性纳入特征图中,SRM 旨在增强 CNN 的表示能力。
SRM的整体结构如右图所示。 它由两个主要组件组成:样式池和样式集成。 风格池算子通过总结跨空间维度的特征响应来从每个通道提取风格特征。 接下来是风格集成运算符,它通过通道操作利用风格特征来生成特定于示例的风格权重。 样式权重最终重新校准特征图以强调或抑制其信息。
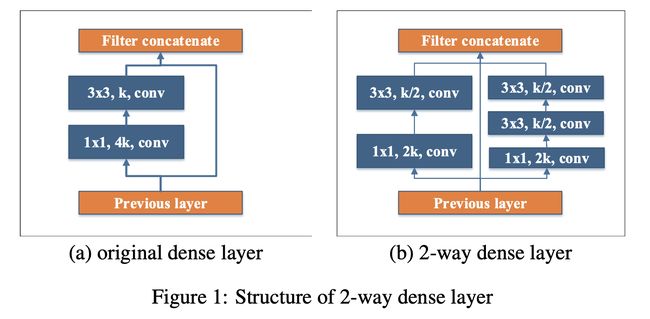
十三、Two-Way Dense Layer
双向密集层是 PeleeNet 架构中使用的图像模型块。 受 GoogLeNet 的启发,使用 2 路密集层来获得不同尺度的感受野。 该层的一种方式使用 3x3 内核大小。 该层的另一种方式使用两个堆叠的 3x3 卷积来学习大型物体的视觉模式。
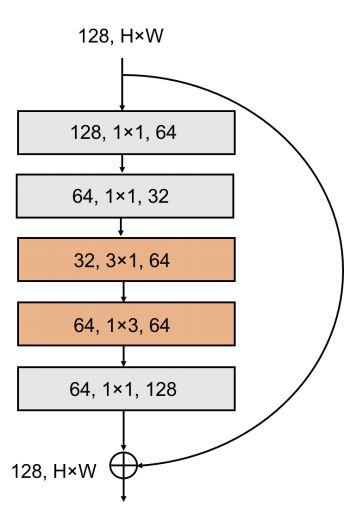
十四、SqueezeNeXt Block
SqueezeNeXt 块是 SqueezeNeXt 架构中使用的两级瓶颈模块,用于减少 3 × 3 卷积的输入通道数。 我们用可分离卷积进行分解,以进一步减少参数数量(橙色部分),然后是 1 × 1 扩展模块。
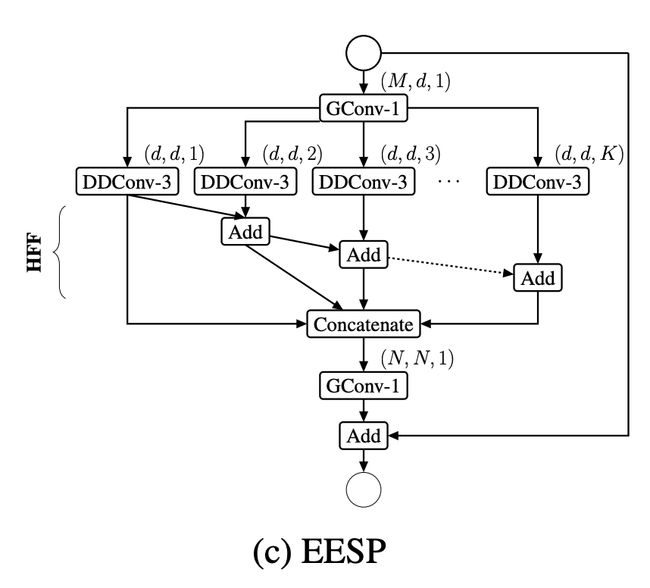
十五、Extremely Efficient Spatial Pyramid of Depth-wise Dilated Separable Convolutions
EESP 单元(即深度方向扩张可分离卷积的极其高效空间金字塔)是专为边缘设备设计的图像模型块。 它被提议作为 ESPNetv2 CNN 架构的一部分。
该构建块基于减少-拆分-转换-合并策略。 EESP 单元首先使用分组逐点卷积将高维输入特征图投影到低维空间,然后使用具有不同扩张率的深度扩张可分离卷积并行学习表示。 每个分支中不同的扩张率允许 EESP 单元从大的有效感受野中学习表示。 为了消除扩张卷积引起的网格伪影,EESP 使用分层特征融合 (HFF) 来融合特征图。
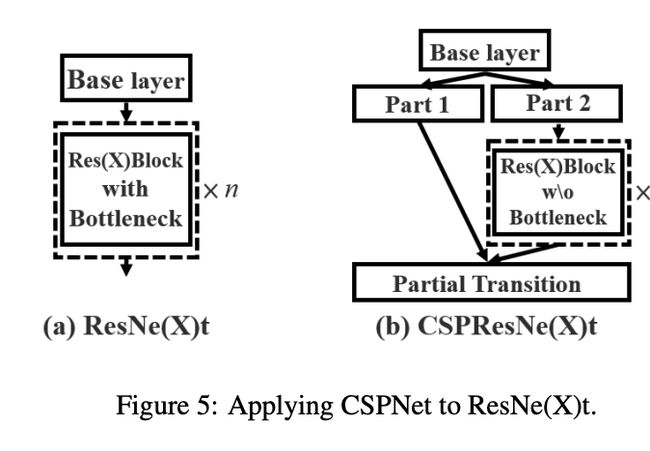
十六、CSPResNeXt Block
CSPResNeXt Block 是一个扩展的 ResNext Block,我们将基础层的特征图划分为两部分,然后通过跨阶段层次结构将它们合并。 使用拆分和合并策略允许更多的梯度流通过网络。
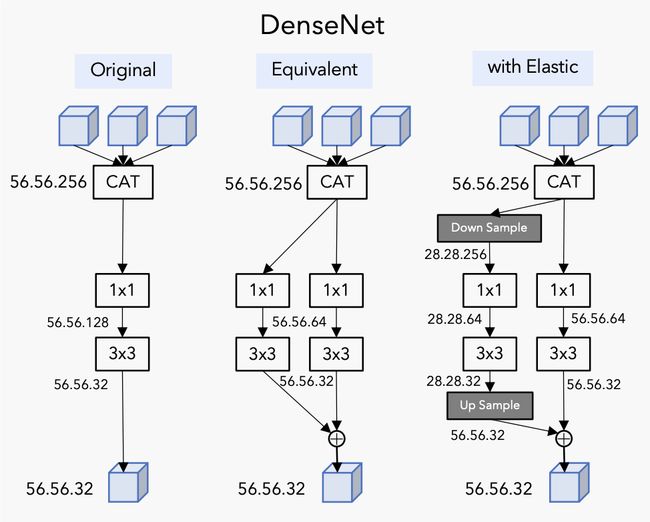
十七、Elastic Dense Block
弹性密集块是一个跳过连接块,它通过在每一层的并行分支中进行下采样和上采样来修改密集块,以便让网络从数据缩放策略中学习,其中输入在每层中以不同的分辨率进行处理。 之所以称为“弹性”,是因为网络中的每一层都可以通过软策略灵活选择最佳规模。
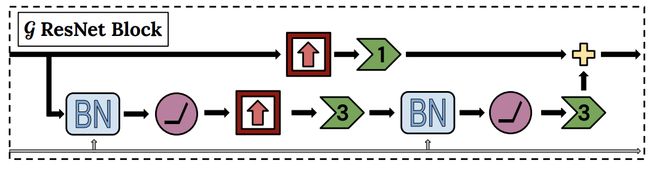
十八、DVD-GAN GBlock
DVD-GAN GBlock 是 DVD-GAN 架构中用于视频生成的生成器的残差块。
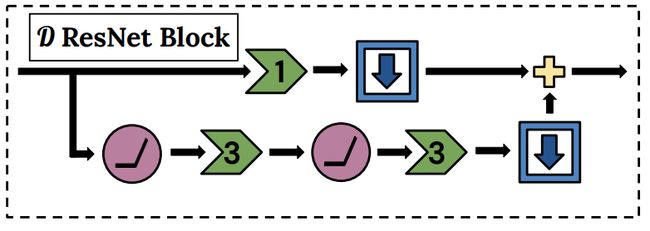
十九、DVD-GAN DBlock
DVD-GAN DBlock 是 DVD-GAN 架构中用于视频生成的鉴别器的残差块。 与常规残差块不同,由于应用于视频中的多个帧,因此采用 3D 卷积。
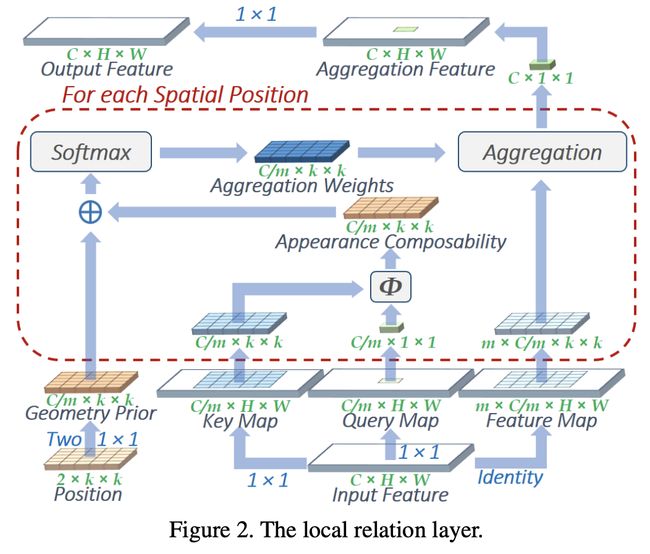
二十、Local Relation Network
局部关系网络(LR-Net)是一个用局部关系层构建的网络,代表特征图像提取器。 该特征提取器根据局部像素对的组成关系自适应地确定聚合权重。