R语言&Python GEO DataSets多个Series进行差异基因表达分析以及导入Excel到R的问题
引入
GEO DataSets上,某些Series是由多个series组成的,比如GSE6834,由六个Series组成:
This SuperSeries is composed of the following SubSeries:
Less… Less…
GSE6771 Temporal Cortex Control (mesial temporal lobe epilepsy control)
GSE6773 Temporal neocortex mesial temporal lobe epilepsy
GSE6774 Temporal Cortex Control (Alzheimer’s disease control)
GSE6774 Temporal Cortex Alzheimer’s Disease
GSE6777 Cerebellum Alzheimer’s Disease
GSE6778 Cerebellum Control (Alzheimer’s disease control)
每个Series又包括10个GSM,要知道一般都是实验组对照组在同一个矩阵中才能进行差异表达分析。那么举个例子,GSE6774和GSE6774,一个对照一个实验,两个矩阵怎么分析呢?
txt转为xlsx
很多人第一反应可能是将两个TXT合二为一,这样做可以,尤其是多个Series,这样还可以利用批处理减轻工作量,但是中间涉及到对齐、插入制表符等问题,很可能出错。不如借助Excel,直接在Excel中复制粘贴即可完成(Series比较少的话)。首先将txt转为xlsx,利用Java或者Python等脚本都可以完成,下面给出Python版的:
# coding=utf-8
import xlsxwriter
import pandas as pd
workbook = xlsxwriter.Workbook(r'D:\Alzheimer\Series\GSE6834\6780.xlsx')
worksheet= workbook.add_worksheet(u'matrix')
txt=open(r'D:\Alzheimer\Series\GSE6834\6778.txt')
m=0
n=0
for m in range(1,8690):
print(m);
line=txt.readline()
data=line.split('\t')
for n in range(1,11):
worksheet.write(m-1,n-1,data[n-1])
worksheet.write(m-1,10,data[10][0:-1])
workbook.close()
注意worksheet.write(m-1,10,data[10][0:-1])这一行,由于每个数据带一个\t,但每一行最后一个还额外多一个\n,所以这一个\n要特殊处理。
转化为TXT后,直接复制粘贴便可合二为一。

xlsx到R中的数据框
xlsx做好了,怎么将其变成我们需要的数据框呢?
思路一:将其转化为txt,也就是再变回去。但是转化时,需要加入\t, \n等符号,也是比较麻烦,容易出错。
思路二:在R中直接用readxl包导入xlsx为数据框。乍一看貌似这个方法最简单,但是有一个问题:xlsx里的数据是文本格式,不能直接用于数据分析。否则,就会出现报错:
> fit=lmFit(exp_matrix, design)
Error in rowMeans(y$exprs, na.rm = TRUE) : 'x' must be numeric
要想批量将Excel中文本格式的数字转化成数字格式,一般的办法是转成csv,然后再转回来。不过,既然转成csv了,不如直接用R导入就可以了。
思路三:将xlsx转成csv,然后用read.csv()导入。
导入之后观察实验矩阵: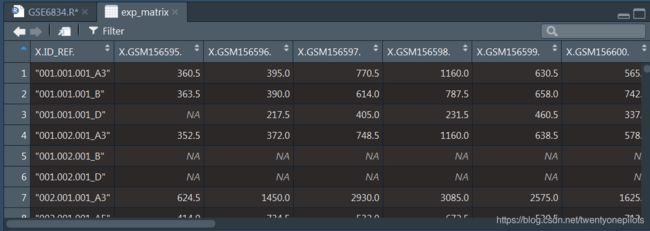
发现数据框第一列居然是探针名字,而不是想象中探针名字作为数据框的行名。所以我们还需要一步,修改下这个数据框。
更改数据框行名(rownames)
首先,我们需要知道更改数据框行名的函数是row.names()。这个函数的参数是向量,所以我们需要把数据框第一列转化成向量;如果直接将数据框或者矩阵作为行名会报错Error in `.rowNamesDF<-`(x, value = value) : 'row.names'的长度不对。那么,数据框怎么转化为向量呢?中间必要的一步是矩阵。所以正确的方法是连续用两个函数as.matrix()和as.vector()。
另外我们还需要将第一列删除,注意删除是在赋rownames之前,否则刚刚赋好的rownames也会被删除!
这一部分代码如下:
m=as.matrix(exp_matrix[, 1])
v=as.vector(m)
exp_matrix<-exp_matrix[, -1]
row.names(exp_matrix) <- v
处理后的数据框如下: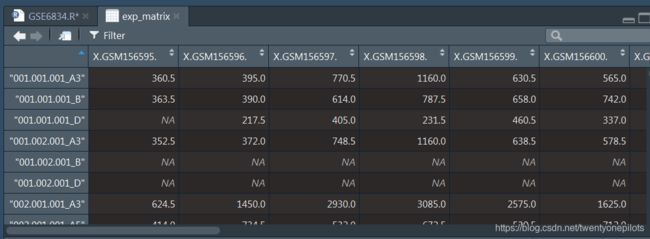
差异表达分析
最后贴一下这个例子中,从导入到差异表达分析的全过程:
library("reshape2")
library("hgu133plus2.db")
library("limma")
setwd("D:/Alzheimer/Series/GSE6834")
exp_matrix<-read.csv("6774&6775.csv",header = TRUE)
m=as.matrix(exp_matrix[, 1])
v=as.vector(m)
exp_matrix<-exp_matrix[, -1]
row.names(exp_matrix) <- v
#TC_Control Temporal Cortex Control (AD)
#TC_AD Temporal Cortex Alzheimer's disease
type <-c('TC_Control','TC_Control','TC_Control','TC_Control','TC_Control','TC_Control','TC_Control','TC_Control','TC_Control','TC_Control','TC_AD','TC_AD','TC_AD','TC_AD','TC_AD','TC_AD','TC_AD','TC_AD','TC_AD','TC_AD')
design <- model.matrix(~ -1+factor(type,levels=c('TC_Control','TC_AD'),ordered=TRUE))
colnames(design) <- c('TC_Control','TC_AD')
rownames(design)=colnames(exp_matrix)
fit=lmFit(exp_matrix, design)
contrast.matrix=makeContrasts(TC_ControlVSTC_AD=TC_Control-TC_AD,levels=design)
fit2 = contrasts.fit(fit, contrast.matrix)
fit2 = eBayes(fit2)
results <- decideTests(fit2)
vennDiagram(results)
diff1 = topTreat(fit2, coef=1,p.value=0.05, n=Inf, adjust.method='BH')
write.table(diff1, "diff.TC_ControlVSTC_AD.GSE6834.txt",sep = '\t',quote = F)