Filebeat+Kafka+ELK日志采集(四)——Logstash
1、Logstash概述
Logstash和Filebeat一样也是日志收集工具,支持复杂的日志过滤分析,功能更加全面,但相比Filebeat需要更多的运行内存,比较笨重。在使用方面通常搭配轻量级的日志收集工具组合使用。
2、快速开始
2.1、下载、安装、配置、启动:
先以最简模型快速开始再讲原理及细节。
1、下载
wget https://artifacts.elastic.co/downloads/logstash/logstash-8.3.2-linux-x86_64.tar.gz
2、解压
tar -xzvf logstash-8.3.2-linux-x86_64.tar.gz
3、启动
进入Logstash /bin目录下执行一下命令:
./logstash -e "input { stdin {} } output { stdout {} }"
如上,设置数据来源为控制台输入stdin {},输出为控制台输出stdout {}。

如图所示,启动成功后分别输入"hello"和"test logstash"。
4、配置
进入/config目录,修改或创建logstash.conf配置文件,配置信息如下:
input {
stdin{}
}
output {
stdout{}
}
指定配置文件启动:
./logstash -f ./config/logstash.conf
logstash.conf中配置的也是控制台输入输出,效果同./logstash -e "input { stdin {} } output { stdout {} }" 一样。
下面章节讲解从Kafka获取输入数据,将数据过滤筛选,输出至Elasticsearch的详细配置。
3、Logstash详细使用说明
3.1、Logstash工作流程图
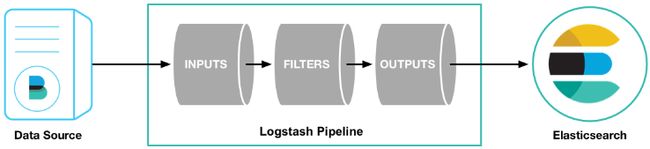
如上图所示,Logstash主要包含三部分:
- 输入:input,设置数据来源,logstash支持数种输入,本文使用Kafka作为数据来源,更多输入配置见官网: Logstash 输入。
- 过滤:filter,对数据进行筛选、过滤、分析分类,转换等操作。
- 输出:output,对处理过的数据输出配置,常用Elasticsearch作为输出。
以上三部分组成一种管道pipeline,可配置多个管道pipeline。
以Kafka作为输入,解析过滤Java日志,Elasticsearch作为输出,logstash.conf配置如下:
input {
kafka {
bootstrap_servers => ['localhost:9092']
# 设置分组
#group_id => 'gateway'
#以上配置中加入了group_id参数,group_id是一个的字符串,唯一标识一个group,具有相同group_id的consumer构成了一个consumer group,这样启动多个logstash进程,只需要保证group_id一致就能达到logstash高可用的目#的,一个logstash>挂掉同一Group内的logstash可以继续消
# 多个客户端同时消费需要设置不同的client_id,注意同一分组的客户端数量≤kafka分区数量
#client_id => 'elk-dev'
# 正则匹配topic
topics => ["testTopic","testGateway"]
codec => "json"
#默认为false,只有为true的时候才会获取到元数据
decorate_events => true
security_protocol => "SASL_PLAINTEXT"
sasl_mechanism => "PLAIN"
sasl_jaas_config => "org.apache.kafka.common.security.plain.PlainLoginModule required username='admin' password='password';"
}
}
filter {
grok {
# 筛选过滤
match => [
#2022-08-16 15:23:09.699 [main] [com.dimpt.netctl.mec.RestUiApplication] \nINFO : Started RestUiApplication in 20.523 seconds (JVM running for 21.161)
"message", "%{TIMESTAMP_ISO8601:time}\s*\[%{DATA:thread}\]\s*\[%{DATA:class}\]\s*\n%{LOGLEVEL:level}\s*:\s*%{GREEDYDATA:msg}"
]
# remove_field => ["message","@timestamp","@metadata","tags","log","@version"]
}
grok {
match =>[
"[log][file][path]", "(?([^/]+)(?=/[^/]+/?$))/(?([^/]+)(?=.log$))"
]
}
date {
match => ["message","UNIX_MS"]
target => "@timestamp"
}
ruby {
code => "event.set('timestamp', event.get('@timestamp').time.localtime + 8*60*60)"
}
ruby {
code => "event.set('@timestamp',event.get('timestamp'))"
}
mutate {
remove_field => ["timestamp"]
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "%{[fields][project]}-%{+YYYY.MM.dd}"
#user => "elastic"
#password => "changeme"
}
#控制台输出,方便调试
stdout {}
}
3.2、输入配置
input {
kafka {
bootstrap_servers => ['192.168.1.1:9092','192.168.1.2:9092','192.168.1.3:9092']
# 设置分组
#group_id => 'gateway'
#以上配置中加入了group_id参数,group_id是一个的字符串,唯一标识一个group,具有相同group_id的consumer构成了一个consumer group,这样启动多个logstash进程,只需要保证group_id一致就能达到logstash高可用的目#的,一个logstash>挂掉同一Group内的logstash可以继续消
# 多个客户端同时消费需要设置不同的client_id,注意同一分组的客户端数量≤kafka分区数量
#client_id => 'elk-dev'
# 正则匹配topic
topics => ["testTopic","testGateway"]
codec => "json"
#默认为false,只有为true的时候才会获取到元数据
decorate_events => true
#连接kafka时设置username和password
security_protocol => "SASL_PLAINTEXT"
sasl_mechanism => "PLAIN"
sasl_jaas_config => "org.apache.kafka.common.security.plain.PlainLoginModule required username='username' password='password';"
}
}
以Kafka作为输入,配置如上
bootstrap_servers => ['192.168.1.1:9092','192.168.1.2:9092','192.168.1.3:9092']设置kakfa连接信息
topics => ["testTopic","testGateway"]设置消费topic
3.3、过滤配置
以Java日志为例,日志信息为:2022-08-16 15:23:09.699 [main] [com.dimpt.netctl.mec.RestUiApplication] \nINFO : Started RestUiApplication in 20.523 seconds (JVM running for 21.161)
filter {
grok {
# 筛选过滤
match => [
1、#2022-08-16 15:23:09.699 [main] [com.dimpt.netctl.mec.RestUiApplication] \nINFO : Started RestUiApplication in 20.523 seconds (JVM running for 21.161)
"message", "%{TIMESTAMP_ISO8601:time}\s*\[%{DATA:thread}\]\s*\[%{DATA:class}\]\s*\n%{LOGLEVEL:level}\s*:\s*%{GREEDYDATA:msg}"
#2、java中括号日期开头类型日志解析:
#[2018-11-24 08:33:43,253][ERROR][http-nio-8080-exec-4][com.hh.test.logs.LogsApplication][code:200,msg:测试录入错误日志,param:{}]
"message", "(?\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2},\d{3})\]\[(?[A-Z]{4,5})\]\[(?[A-Za-z0-9/-]{4,40})\]\[(?[A-Za-z0-9/.]{4,40})\]\[(?.*)" ,
#3、只获取时间和日志级别
"message", "%{TIMESTAMP_ISO8601:time}(?.*)\n%{LOGLEVEL:level}"
]
#需要移除的字段
# remove_field => ["message","@timestamp","@metadata","tags","log","@version"]
}
#filebeat采集的日志,log.file.path字段为日志文件的完整路径如:/var/log/projectName/moduleName.log
#获取项目名称和模块名称,分别赋值给project和module字段。
grok {
match =>[
"[log][file][path]", "(?([^/]+)(?=/[^/]+/?$))/(?([^/]+)(?=.log$))"
]
}
#日志中时间time替换采集时间@timestamp,@timestamp固定为国际标准时间,替换后自动减8小时
date {
match => ["time", "yyyy-MM-dd HH:mm:ss.SSS"]
#match => ["message","UNIX_MS"]
target => "@timestamp"
}
#转换为东八区时间:加8个小时
ruby {
code => "event.set('timestamp', event.get('@timestamp').time.localtime + 8*60*60)"
}
ruby {
code => "event.set('@timestamp',event.get('timestamp'))"
}
mutate {
remove_field => ["timestamp"]
}
}
使用grok匹配过滤message字段:
match => [
"message", "%{TIMESTAMP_ISO8601:time}\s*\[%{DATA:thread}\]\s*\[%{DATA:class}\]\s*\n%{LOGLEVEL:level}\s*:\s*%{GREEDYDATA:msg}"
]
表达式含义为对message字段进行正则匹配,使用语法为%{grok内置正则表达式:结果字段}。
以上表达式结果为新增5个字段:
日志时间time:2022-08-16 15:23:09.699
所属线程thread:mian
所属类class:com.dimpt.netctl.mec.RestUiApplication
日志级别level:INFO
日志详情msg:Started RestUiApplication in 20.523 seconds (JVM running for 21.161)
以上使用了grop内置的正则表达式,也可以自定义正则表达式,
自定义表达式格式为(?<结果字段名>正则表达式),示例如下:
match => [
#1、java日期开头类型日志解析: grok预定义正则表达式:https://blog.csdn.net/qq_25854057/article/details/121522310
#2022-01-07 14:21:04.157 [main] [o.springframework.boot.actuate.endpoint.EndpointId] WARN : Endpoint ID 'nacos-config' contains invalid characters, please migrate to a valid format.
"message", "(?\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}.\d{3})\s\[(?[A-Za-z0-9/.]{4,40})\]\s\s\[(?[A-Za-z0-9/.]{4,100})\]\s\n(?[A-Z]{4,5})(\s: |: )(?.*)" ,
#2、java中括号日期开头类型日志解析:
#[2018-11-24 08:33:43,253][ERROR][http-nio-8080-exec-4][com.hh.test.logs.LogsApplication][code:200,msg:测试录入错误日志,param:{}]
"message", "(?\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2},\d{3})\]\[(?[A-Z]{4,5})\]\[(?[A-Za-z0-9/-]{4,40})\]\[(?[A-Za-z0-9/.]{4,40})\]\[(?.*)" ,
#3、只获取时间和日志级别
"message", "%{TIMESTAMP_ISO8601:time}(?.*)\n%{LOGLEVEL:level}"
]
如上所示使用自定义的正则表达式匹配添加字段;可使用多个正则表达式,以逗号隔开,自上而下匹配。
grok表达式
grok内置表达式:
USERNAME [a-zA-Z0-9._-]+
USER %{USERNAME}
EMAILLOCALPART [a-zA-Z][a-zA-Z0-9_.+-=:]+
EMAILADDRESS %{EMAILLOCALPART}@%{HOSTNAME}
INT (?:[+-]?(?:[0-9]+))
BASE10NUM (?<![0-9.+-])(?>[+-]?(?:(?:[0-9]+(?:\.[0-9]+)?)|(?:\.[0-9]+)))
NUMBER (?:%{BASE10NUM})
BASE16NUM (?<![0-9A-Fa-f])(?:[+-]?(?:0x)?(?:[0-9A-Fa-f]+))
BASE16FLOAT \b(?<![0-9A-Fa-f.])(?:[+-]?(?:0x)?(?:(?:[0-9A-Fa-f]+(?:\.[0-9A-Fa-f]*)?)|(?:\.[0-9A-Fa-f]+)))\b
POSINT \b(?:[1-9][0-9]*)\b
NONNEGINT \b(?:[0-9]+)\b
WORD \b\w+\b
NOTSPACE \S+
SPACE \s*
DATA .*?
GREEDYDATA .*
QUOTEDSTRING (?>(?<!\\)(?>"(?>\\.|[^\\"]+)+"|""|(?>'(?>\\.|[^\\']+)+')|''|(?>`(?>\\.|[^\\`]+)+`)|``))
UUID [A-Fa-f0-9]{8}-(?:[A-Fa-f0-9]{4}-){3}[A-Fa-f0-9]{12}
# URN, allowing use of RFC 2141 section 2.3 reserved characters
URN urn:[0-9A-Za-z][0-9A-Za-z-]{0,31}:(?:%[0-9a-fA-F]{2}|[0-9A-Za-z()+,.:=@;$_!*'/?#-])+
# Networking
MAC (?:%{CISCOMAC}|%{WINDOWSMAC}|%{COMMONMAC})
CISCOMAC (?:(?:[A-Fa-f0-9]{4}\.){2}[A-Fa-f0-9]{4})
WINDOWSMAC (?:(?:[A-Fa-f0-9]{2}-){5}[A-Fa-f0-9]{2})
COMMONMAC (?:(?:[A-Fa-f0-9]{2}:){5}[A-Fa-f0-9]{2})
IPV6 ((([0-9A-Fa-f]{1,4}:){7}([0-9A-Fa-f]{1,4}|:))|(([0-9A-Fa-f]{1,4}:){6}(:[0-9A-Fa-f]{1,4}|((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3})|:))|(([0-9A-Fa-f]{1,4}:){5}(((:[0-9A-Fa-f]{1,4}){1,2})|:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3})|:))|(([0-9A-Fa-f]{1,4}:){4}(((:[0-9A-Fa-f]{1,4}){1,3})|((:[0-9A-Fa-f]{1,4})?:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){3}(((:[0-9A-Fa-f]{1,4}){1,4})|((:[0-9A-Fa-f]{1,4}){0,2}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){2}(((:[0-9A-Fa-f]{1,4}){1,5})|((:[0-9A-Fa-f]{1,4}){0,3}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){1}(((:[0-9A-Fa-f]{1,4}){1,6})|((:[0-9A-Fa-f]{1,4}){0,4}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(:(((:[0-9A-Fa-f]{1,4}){1,7})|((:[0-9A-Fa-f]{1,4}){0,5}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:)))(%.+)?
IPV4 (?<[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oxyXELPe-1664515069810)(?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5])][.](?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5])[.](?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5]))(?![0-9])
IP (?:%{IPV6}|%{IPV4})
HOSTNAME \b(?:[0-9A-Za-z][0-9A-Za-z-]{0,62})(?:\.(?:[0-9A-Za-z][0-9A-Za-z-]{0,62}))*(\.?|\b)
IPORHOST (?:%{IP}|%{HOSTNAME})
HOSTPORT %{IPORHOST}:%{POSINT}
# paths
PATH (?:%{UNIXPATH}|%{WINPATH})
UNIXPATH (/([\w_%!$@:.,+~-]+|\\.)*)+
TTY (?:/dev/(pts|tty([pq])?)(\w+)?/?(?:[0-9]+))
WINPATH (?>[A-Za-z]+:|\\)(?:\\[^\\?*]*)+
URIPROTO [A-Za-z]([A-Za-z0-9+\-.]+)+
URIHOST %{IPORHOST}(?::%{POSINT:port})?
# uripath comes loosely from RFC1738, but mostly from what Firefox
# doesn't turn into %XX
URIPATH (?:/[A-Za-z0-9$.+!*'(){},~:;=@#%&_\-]*)+
#URIPARAM \?(?:[A-Za-z0-9]+(?:=(?:[^&]*))?(?:&(?:[A-Za-z0-9]+(?:=(?:[^&]*))?)?)*)?
URIPARAM \?[A-Za-z0-9$.+!*'|(){},~@#%&/=:;_?\-\[\]<>]*
URIPATHPARAM %{URIPATH}(?:%{URIPARAM})?
URI %{URIPROTO}://(?:%{USER}(?::[^@]*)?@)?(?:%{URIHOST})?(?:%{URIPATHPARAM})?
# Months: January, Feb, 3, 03, 12, December
MONTH \b(?:[Jj]an(?:uary|uar)?|[Ff]eb(?:ruary|ruar)?|[Mm](?:a|ä)?r(?:ch|z)?|[Aa]pr(?:il)?|[Mm]a(?:y|i)?|[Jj]un(?:e|i)?|[Jj]ul(?:y)?|[Aa]ug(?:ust)?|[Ss]ep(?:tember)?|[Oo](?:c|k)?t(?:ober)?|[Nn]ov(?:ember)?|[Dd]e(?:c|z)(?:ember)?)\b
MONTHNUM (?:0?[1-9]|1[0-2])
MONTHNUM2 (?:0[1-9]|1[0-2])
MONTHDAY (?:(?:0[1-9])|(?:[12][0-9])|(?:3[01])|[1-9])
# Days: Monday, Tue, Thu, etc...
DAY (?:Mon(?:day)?|Tue(?:sday)?|Wed(?:nesday)?|Thu(?:rsday)?|Fri(?:day)?|Sat(?:urday)?|Sun(?:day)?)
# Years?
YEAR (?>\d\d){1,2}
HOUR (?:2[0123]|[01]?[0-9])
MINUTE (?:[0-5][0-9])
# '60' is a leap second in most time standards and thus is valid.
SECOND (?:(?:[0-5]?[0-9]|60)(?:[:.,][0-9]+)?)
TIME (?!<[0-9])%{HOUR}:%{MINUTE}(?::%{SECOND})(?![0-9])
# datestamp is YYYY/MM/DD-HH:MM:SS.UUUU (or something like it)
DATE_US %{MONTHNUM}[/-]%{MONTHDAY}[/-]%{YEAR}
DATE_EU %{MONTHDAY}[./-]%{MONTHNUM}[./-]%{YEAR}
ISO8601_TIMEZONE (?:Z|[+-]%{HOUR}(?::?%{MINUTE}))
ISO8601_SECOND (?:%{SECOND}|60)
TIMESTAMP_ISO8601 %{YEAR}-%{MONTHNUM}-%{MONTHDAY}[T ]%{HOUR}:?%{MINUTE}(?::?%{SECOND})?%{ISO8601_TIMEZONE}?
DATE %{DATE_US}|%{DATE_EU}
DATESTAMP %{DATE}[- ]%{TIME}
TZ (?:[APMCE][SD]T|UTC)
DATESTAMP_RFC822 %{DAY} %{MONTH} %{MONTHDAY} %{YEAR} %{TIME} %{TZ}
DATESTAMP_RFC2822 %{DAY}, %{MONTHDAY} %{MONTH} %{YEAR} %{TIME} %{ISO8601_TIMEZONE}
DATESTAMP_OTHER %{DAY} %{MONTH} %{MONTHDAY} %{TIME} %{TZ} %{YEAR}
DATESTAMP_EVENTLOG %{YEAR}%{MONTHNUM2}%{MONTHDAY}%{HOUR}%{MINUTE}%{SECOND}
# Syslog Dates: Month Day HH:MM:SS
SYSLOGTIMESTAMP %{MONTH} +%{MONTHDAY} %{TIME}
PROG [\x21-\x5a\x5c\x5e-\x7e]+
SYSLOGPROG %{PROG:program}(?:\[%{POSINT:pid}\])?
SYSLOGHOST %{IPORHOST}
SYSLOGFACILITY <%{NONNEGINT:facility}.%{NONNEGINT:priority}>
HTTPDATE %{MONTHDAY}/%{MONTH}/%{YEAR}:%{TIME} %{INT}
# Shortcuts
QS %{QUOTEDSTRING}
# Log formats
SYSLOGBASE %{SYSLOGTIMESTAMP:timestamp} (?:%{SYSLOGFACILITY} )?%{SYSLOGHOST:logsource} %{SYSLOGPROG}:
# Log Levels
LOGLEVEL ([Aa]lert|ALERT|[Tt]race|TRACE|[Dd]ebug|DEBUG|[Nn]otice|NOTICE|[Ii]nfo|INFO|[Ww]arn?(?:ing)?|WARN?(?:ING)?|[Ee]rr?(?:or)?|ERR?(?:OR)?|[Cc]rit?(?:ical)?|CRIT?(?:ICAL)?|[Ff]atal|FATAL|[Ss]evere|SEVERE|EMERG(?:ENCY)?|[Ee]merg(?:ency)?)
官方提供的表达式:https://github.com/elastic/logstash/blob/v1.4.2/patterns/grok-patterns
语法解释:
%{HOSTNAME:xxx},匹配请求的主机名
%{TIMESTAMP_ISO8601:xxx},代表时间戳
%{LOGLEVEL:xxx},代表日志级别
%{URIPATHPARAM:xxx},代表请求路径
%{INT:xxx},代表字符串整数数字大小
%{NUMBER:xxx}, 可以匹配整数或者小数
%{UUID:xxx},匹配类似091ece39-5444-44a1-9f1e-019a17286b48
%{IP:xxx}, 匹配ip
%{WORD:xxx}, 匹配请求的方式
%{GREEDYDATA:xxx},匹配所有剩余的数据
(?([\S+]*)),自定义正则
\s*或者\s+,代表多个空格
\S+或者\S*,代表匹配多个字符
\w+或者\w*,代表匹配多个字母
大括号里面:xxx,相当于起别名
内置正则表达式说明参考:https://www.cnblogs.com/zhangan/p/11395056.html
时间问题处理
filebeat采集会有一个采集时间@timeStamp,日志中也有一个日志时间,根据grok解析出设置为time字段,这两个时间会有存在差异。
@timestamp为采集时间,不是日志产生的真实时间。
@timestamp为日期类型,在Kibana中可以根据该字段排序,但解析出的time为字符串类型,无法排序。
@timestamp为国际标准时间,中国采用东八区时间,要保持一致需将@timestamp时间加上八个小时。
为了在Kibana中根据日志实际时间排序,将time替换@timestamp,但@timestamp为东八区类型,替换后自动减8小时,所以需要再加8小时:
#日志中时间time替换采集时间@timestamp,@timestamp固定为国际标准时间,替换后自动减8小时
date {
match => ["time", "yyyy-MM-dd HH:mm:ss.SSS"]
#match => ["message","UNIX_MS"]
target => "@timestamp"
}
#转换为东八区时间:加8个小时
ruby {
code => "event.set('timestamp', event.get('@timestamp').time.localtime + 8*60*60)"
}
ruby {
code => "event.set('@timestamp',event.get('timestamp'))"
}
mutate {
remove_field => ["timestamp"]
}
或者再kibana中设置时区,将自动转换时间无需手动加8小时,根据实际自行选择,Kibana中设置时区如下图:
3.4、输出配置
使用Elasticsearch作为输出,配置如下:
output {
elasticsearch {
hosts => ["192.168.1.1:9200","192.168.1.2:9200","192.168.1.2:9200"]
index => "%{[fields][project]}-%{+YYYY.MM.dd}"
#user => "elastic"
#password => "******"
}
#测试时控制台输出,方便调试
stdout {}
}
配置如上,每天新建一个索引,索引名为项目名称-日期,使用%{+YYYY.MM.dd}自动获取时间则必须保留@timestamp字段,否则获取不到时间。
4、K8S部署
k8s部署Logstash:
---
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
k8s.kuboard.cn/displayName: logstash-log-collection
labels:
k8s.kuboard.cn/name: logstash-log-collection
name: logstash-log-collection
namespace: log-collect-test
resourceVersion: '22063161'
spec:
progressDeadlineSeconds: 600
replicas: 0
revisionHistoryLimit: 10
selector:
matchLabels:
k8s.kuboard.cn/name: logstash-log-collection
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
annotations:
kubectl.kubernetes.io/restartedAt: '2022-09-02T15:46:04+08:00'
creationTimestamp: null
labels:
k8s.kuboard.cn/name: logstash-log-collection
spec:
containers:
- image: 'docker.elastic.co/logstash/logstash:8.3.2'
imagePullPolicy: IfNotPresent
name: logstash
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /usr/share/logstash/config
name: config
- mountPath: /usr/share/logstash/pipeline
name: pipeline
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
volumes:
- configMap:
defaultMode: 420
items:
- key: logstash.conf
path: logstash.conf
name: logstash-config
name: pipeline
使用configMap作为数据卷挂载配置文件。
注意: Logstash在虚机中与在k8s容器中目录结构不一样!!!
虚机中配置文件路径/config/logstash.conf
k8s容器中配置文件路径/pileline/logstash.conf。